Recognition: 2 theorem links
· Lean TheoremWhen Looking Is Not Enough: Visual Attention Structure Reveals Hallucination in MLLMs
Pith reviewed 2026-05-13 01:51 UTC · model grok-4.3
The pith
The high-frequency structure of visual attention, measured by layer-wise Laplacian energy, reveals where hallucinated preferences emerge in MLLMs and supports a training-free decoding fix.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We show that the high-frequency structure of visual attention, measured by layer-wise Laplacian energy, reveals both the layer where hallucinated preferences emerge and the layer where the ground-truth answer transiently recovers. Building on this finding, we propose LaSCD, a training-free decoding strategy that selects informative layers via Laplacian energy and remaps next-token logits in closed form.
What carries the argument
LaSCD (Laplacian-Spectral Contrastive Decoding), which selects layers by their Laplacian energy on attention maps and performs closed-form logit remapping to favor ground-truth tokens.
If this is right
- LaSCD lowers hallucination rates on visual question answering and captioning benchmarks.
- The method leaves general multimodal capabilities unchanged.
- No model training or parameter updates are required for deployment.
- Layer selection happens dynamically during generation based on attention structure.
Where Pith is reading between the lines
- The same energy-based layer monitoring could diagnose other forms of internal inconsistency in multimodal generation.
- Dynamic use of spectral attention signals might enable real-time correction in deployed vision-language systems.
- Attention-structure diagnostics could extend to single-modality language models for factual error detection.
Load-bearing premise
Laplacian energy of attention maps serves as a reliable signal for choosing layers that, when used for logit adjustment, reduce hallucinations without introducing new errors or harming non-hallucination performance.
What would settle it
An experiment in which LaSCD applied to layers chosen by high Laplacian energy produces higher hallucination rates or lower accuracy on non-hallucination tasks than standard decoding.
Figures









read the original abstract
Multimodal large language models (MLLMs) have become a key interface for visual reasoning and grounded question answering, yet they remain vulnerable to visual hallucinations, where generated responses contradict image content or mention nonexistent objects. A central challenge is that hallucination is not always caused by a simple lack of visual attention: the model may still assign substantial attention mass to image tokens while internally drifting toward an incorrect answer. In this paper, we show that the high-frequency structure of visual attention, measured by layer-wise Laplacian energy, reveals both the layer where hallucinated preferences emerge and the layer where the ground-truth answer transiently recovers. Building on this finding, we propose LaSCD (Laplacian-Spectral Contrastive Decoding), a training-free decoding strategy that selects informative layers via Laplacian energy and remaps next-token logits in closed form. Experiments on hallucination and general multimodal benchmarks show that LaSCD consistently reduces hallucination while preserving general capabilities, highlighting its potential as a faithful decoding paradigm. The code is available at https://github.com/macovaseas/LaSCD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in MLLMs the high-frequency structure of visual attention, quantified via layer-wise Laplacian energy of attention maps, identifies both the layers at which hallucinated answer preferences emerge and the layers at which ground-truth answers transiently recover. Building on this observation, the authors introduce LaSCD, a training-free decoding procedure that selects informative layers according to Laplacian energy and performs closed-form remapping of next-token logits, reporting reduced hallucination rates on standard benchmarks while preserving general multimodal performance.
Significance. If the central mechanistic claim and the effectiveness of the resulting decoder are substantiated, the work supplies a concrete, interpretable signal for locating hallucination dynamics inside the model and delivers a practical, parameter-free mitigation technique that does not require retraining. The public release of code further strengthens the contribution by enabling direct reproduction and extension.
major comments (2)
- [Experiments] The manuscript demonstrates correlation between Laplacian energy peaks and hallucination/recovery layers through visualizations and reports LaSCD performance gains, yet it does not include controlled ablations that isolate Laplacian energy from other attention statistics (entropy, total mass, or layer index). Without such comparisons it remains unclear whether the high-frequency structure is the causally relevant signal for layer selection or merely a proxy, directly weakening the justification for the specific choice of Laplacian energy in the LaSCD procedure.
- [Method (LaSCD derivation)] The closed-form logit remapping step in LaSCD is presented as selecting layers via Laplacian energy and then adjusting logits, but the exact algebraic form of the remapping (including any scaling or contrastive terms) is not supplied with sufficient detail to verify that the operation is truly closed-form, free of additional fitted parameters, and guaranteed not to degrade non-hallucination tasks.
minor comments (1)
- [Abstract] The abstract asserts that LaSCD 'consistently reduces hallucination' without quoting numerical deltas or naming the precise benchmarks and baselines; adding these figures would improve immediate readability.
Simulated Author's Rebuttal
We thank the referee for the insightful comments and the recommendation for major revision. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments] The manuscript demonstrates correlation between Laplacian energy peaks and hallucination/recovery layers through visualizations and reports LaSCD performance gains, yet it does not include controlled ablations that isolate Laplacian energy from other attention statistics (entropy, total mass, or layer index). Without such comparisons it remains unclear whether the high-frequency structure is the causally relevant signal for layer selection or merely a proxy, directly weakening the justification for the specific choice of Laplacian energy in the LaSCD procedure.
Authors: We thank the referee for pointing this out. While our visualizations and performance results support the use of Laplacian energy, we agree that controlled ablations are necessary to isolate its contribution. In the revised version, we will add experiments ablating the layer selection criterion, comparing Laplacian energy against attention entropy, total mass, and fixed layer indices. These will show that Laplacian energy uniquely identifies the relevant layers for hallucination mitigation without degrading other metrics. revision: yes
-
Referee: [Method (LaSCD derivation)] The closed-form logit remapping step in LaSCD is presented as selecting layers via Laplacian energy and then adjusting logits, but the exact algebraic form of the remapping (including any scaling or contrastive terms) is not supplied with sufficient detail to verify that the operation is truly closed-form, free of additional fitted parameters, and guaranteed not to degrade non-hallucination tasks.
Authors: We agree that more detail is needed. In the revised manuscript, we will supply the complete algebraic expression for the closed-form logit remapping, including all scaling and contrastive terms. We will also include a derivation demonstrating that the procedure is parameter-free and closed-form, along with empirical results showing it does not degrade performance on non-hallucination tasks. revision: yes
Circularity Check
Derivation chain is self-contained; no circular reductions identified
full rationale
The paper empirically measures layer-wise Laplacian energy on visual attention maps to identify hallucination emergence and transient recovery layers, then introduces LaSCD as a training-free logit remapping procedure that selects layers according to this energy signal. This sequence relies on direct observation and benchmark validation rather than any self-definitional loop, fitted parameter presented as a prediction, or load-bearing self-citation; the decoding rule is constructed from the reported attention structure and tested independently on hallucination and general multimodal tasks without reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Layer-wise Laplacian energy of visual attention maps is a reliable indicator of where hallucinated preferences emerge in MLLMs
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
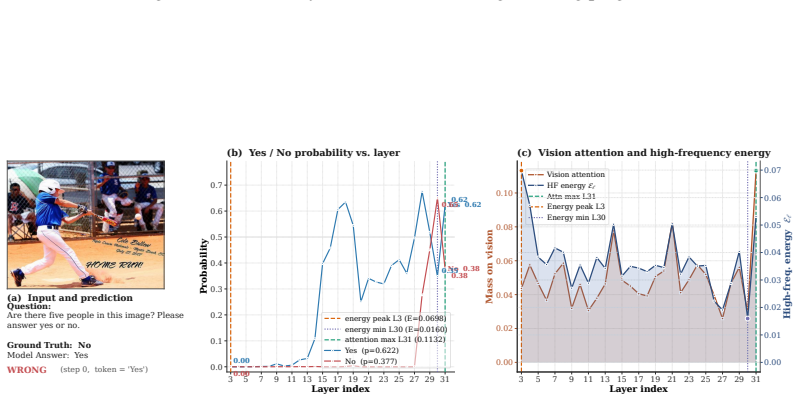
we compute a Laplacian energy on the last-query attention slice over visual tokens... E(l) = 1/H ∑ ||K_Δ * A(l,h)_2D||_F
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the layer with peak energy often marks the onset of the hallucinated preference
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in Neural Information Processing Systems, 35:23716–23736, 2022
work page 2022
-
[2]
Visual instruction tuning.Advances in Neural Information Processing Systems, 36, 2024
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[3]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities.arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Llavanext: Improved reasoning, ocr, and world knowledge, 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llavanext: Improved reasoning, ocr, and world knowledge, 2024
work page 2024
-
[5]
Visual hallucinations of multi-modal large language models.arXiv preprint arXiv:2402.14683, 2024
Wen Huang, Hongbin Liu, Minxin Guo, and Neil Zhenqiang Gong. Visual hallucinations of multi-modal large language models.arXiv preprint arXiv:2402.14683, 2024
-
[6]
Kening Zheng, Junkai Chen, Yibo Yan, Xin Zou, and Xuming Hu. Reefknot: A comprehensive benchmark for relation hallucination evaluation, analysis and mitigation in multimodal large language models.arXiv preprint arXiv:2408.09429, 2024
-
[7]
Yuanhuiyi Lyu, Xu Zheng, Lutao Jiang, Yibo Yan, Xin Zou, Huiyu Zhou, Linfeng Zhang, and Xuming Hu. Realrag: Retrieval-augmented realistic image generation via self-reflective contrastive learning.arXiv preprint arXiv:2502.00848, 2025
-
[8]
Qika Lin, Yifan Zhu, Xin Mei, Ling Huang, Jingying Ma, Kai He, Zhen Peng, Erik Cambria, and Mengling Feng. Has multimodal learning delivered universal intelligence in healthcare? a comprehensive survey.arXiv preprint arXiv:2408.12880, 2024
-
[9]
Holistic autonomous driving understanding by bird’s-eye-view injected multi-modal large models
Xinpeng Ding, Jianhua Han, Hang Xu, Xiaodan Liang, Wei Zhang, and Xiaomeng Li. Holistic autonomous driving understanding by bird’s-eye-view injected multi-modal large models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13668–13677, 2024
work page 2024
-
[10]
Xiaoye Qu, Qiyuan Chen, Wei Wei, Jishuo Sun, and Jianfeng Dong. Alleviating halluci- nation in large vision-language models with active retrieval augmentation.arXiv preprint arXiv:2408.00555, 2024
-
[11]
Im-rag: Multi-round retrieval-augmented generation through learning inner monologues
Diji Yang, Jinmeng Rao, Kezhen Chen, Xiaoyuan Guo, Yawen Zhang, Jie Yang, and Yi Zhang. Im-rag: Multi-round retrieval-augmented generation through learning inner monologues. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 730–740, 2024
work page 2024
-
[12]
Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, et al. Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13807–13816, 2024. 10
work page 2024
-
[13]
Mitigat- ing hallucination in large multi-modal models via robust instruction tuning
Fuxiao Liu, Kevin Lin, Linjie Li, Jianfeng Wang, Yaser Yacoob, and Lijuan Wang. Mitigat- ing hallucination in large multi-modal models via robust instruction tuning. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[14]
Qidong Huang, Xiaoyi Dong, Pan Zhang, Bin Wang, Conghui He, Jiaqi Wang, Dahua Lin, Weiming Zhang, and Nenghai Yu. Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13418–13427, 2024
work page 2024
-
[15]
Mitigating object hallucinations in large vision-language models through visual contrastive decoding
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Lidong Bing. Mitigating object hallucinations in large vision-language models through visual contrastive decoding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13872–13882, 2024
work page 2024
-
[16]
Contrastive decoding: Open-ended text generation as optimization
Xiang Lisa Li, Ari Holtzman, Daniel Fried, Percy Liang, Jason Eisner, Tatsunori Hashimoto, Luke Zettlemoyer, and Mike Lewis. Contrastive decoding: Open-ended text generation as optimization. InThe 61st Annual Meeting Of The Association For Computational Linguistics, 2023
work page 2023
-
[17]
Trusting your evidence: Hallucinate less with context-aware decoding
Weijia Shi, Xiaochuang Han, Mike Lewis, Yulia Tsvetkov, Luke Zettlemoyer, and Wen-tau Yih. Trusting your evidence: Hallucinate less with context-aware decoding. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers), pages 783–791, 2024
work page 2024
-
[18]
Paying more attention to image: A training-free method for alleviating hallucination in lvlms
Shi Liu, Kecheng Zheng, and Wei Chen. Paying more attention to image: A training-free method for alleviating hallucination in lvlms. InEuropean Conference on Computer Vision, pages 125–140. Springer, 2024
work page 2024
-
[19]
Xin Zou, Yizhou Wang, Yibo Yan, Yuanhuiyi Lyu, Kening Zheng, Sirui Huang, Junkai Chen, Peijie Jiang, Jia Liu, Chang Tang, and Xuming Hu. Look twice before you answer: Memory- space visual retracing for hallucination mitigation in multimodal large language models.Forty- second International Conference on Machine Learning (ICML), 2025
work page 2025
-
[20]
A survey on multimodal large language models.arXiv preprint arXiv:2306.13549, 2023
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models.arXiv preprint arXiv:2306.13549, 2023
-
[21]
Hallucination of Multimodal Large Language Models: A Survey
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, and Mike Zheng Shou. Hallucination of multimodal large language models: A survey.arXiv preprint arXiv:2404.18930, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Detecting and preventing hallucinations in large vision language models
Anisha Gunjal, Jihan Yin, and Erhan Bas. Detecting and preventing hallucinations in large vision language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 18135–18143, 2024
work page 2024
-
[23]
Analyzing and mitigating object hallucination in large vision-language models
Yiyang Zhou, Chenhang Cui, Jaehong Yoon, Linjun Zhang, Zhun Deng, Chelsea Finn, Mohit Bansal, and Huaxiu Yao. Analyzing and mitigating object hallucination in large vision-language models. InInternational Conference on Learning Representations, 2024
work page 2024
-
[24]
Xiaofeng Zhang, Yihao Quan, Chaochen Gu, Chen Shen, Xiaosong Yuan, Shaotian Yan, Hao Cheng, Kaijie Wu, and Jieping Ye. Seeing clearly by layer two: Enhancing attention heads to alleviate hallucination in lvlms.arXiv preprint arXiv:2411.09968, 2024
-
[25]
Yun Xing, Yiheng Li, Ivan Laptev, and Shijian Lu. Mitigating object hallucination via concentric causal attention.arXiv preprint arXiv:2410.15926, 2024
-
[26]
Xinhao Xu, Hui Chen, Mengyao Lyu, Sicheng Zhao, Yizhe Xiong, Zijia Lin, Jungong Han, and Guiguang Ding. Mitigating hallucinations in multi-modal large language models via image token attention-guided decoding. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors, Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association f...
work page 2025
-
[27]
Jianghao Yin, Qin Chen, Kedi Chen, Jie Zhou, Xingjiao Wu, and Liang He. Dynamic multi- modal activation steering for hallucination mitigation in large vision-language models. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[28]
Dola: Decoding by contrasting layers improves factuality in large language models
Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James R Glass, and Pengcheng He. Dola: Decoding by contrasting layers improves factuality in large language models. InThe Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[29]
Xintong Wang, Jingheng Pan, Liang Ding, and Chris Biemann. Mitigating hallucinations in large vision-language models with instruction contrastive decoding.arXiv preprint arXiv:2403.18715, 2024
-
[30]
Halc: Object hallucination reduction via adaptive focal-contrast decoding
Zhaorun Chen, Zhuokai Zhao, Hongyin Luo, Huaxiu Yao, Bo Li, and Jiawei Zhou. Halc: Object hallucination reduction via adaptive focal-contrast decoding. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[31]
Dexter Neo and Tsuhan Chen. V ord: Visual ordinal calibration for mitigating object hallucina- tions in large vision-language models.arXiv preprint arXiv:2412.15739, 2024
-
[32]
Ascd: Attention-steerable contrastive decoding for reducing hallucination in mllm
Yujun Wang, Jinhe Bi, Soren Pirk, Yunpu Ma, et al. Ascd: Attention-steerable contrastive decoding for reducing hallucination in mllm. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 10306–10314, 2026
work page 2026
-
[33]
Shezheng Song, Shasha Li, and Jie Yu. Seeing right but saying wrong: Inter-and intra-layer refinement in mllms without training.arXiv preprint arXiv:2601.07359, 2026
-
[34]
Lingfeng Ren, Weihao Yu, Runpeng Yu, and Xinchao Wang. Nolan: Mitigating object hallu- cinations in large vision-language models via dynamic suppression of language priors.arXiv preprint arXiv:2602.22144, 2026
-
[35]
Xingyu Zhu, Kesen Zhao, Liang Yi, Shuo Wang, Zhicai Wang, Beier Zhu, Hanwang Zhang, and Xiangnan He. Look carefully: Adaptive visual reinforcements in multimodal large language models for hallucination mitigation. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[36]
MLLM can see? dynamic correction decoding for hallucination mitigation
Chenxi Wang, Xiang Chen, Ningyu Zhang, Bozhong Tian, Haoming Xu, Shumin Deng, and Huajun Chen. MLLM can see? dynamic correction decoding for hallucination mitigation. In The Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[37]
Detecting contextual hallucinations in llms with frequency-aware attention
Siya Qi, Yudong Chen, Runcong Zhao, Qinglin Zhu, Zhanghao Hu, Wei Liu, Yulan He, Zheng Yuan, and Lin Gui. Detecting contextual hallucinations in llms with frequency-aware attention. arXiv preprint arXiv:2602.18145, 2026
-
[38]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational Conference on Machine Learning, pages 19730–19742. PMLR, 2023
work page 2023
-
[39]
Improved Baselines with Visual Instruction Tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning.arXiv preprint arXiv:2310.03744, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Team Glm, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Dan Zhang, Diego Rojas, Guanyu Feng, Hanlin Zhao, et al. Chatglm: A family of large language models from glm-130b to glm-4 all tools.arXiv preprint arXiv:2406.12793, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Video-LLaV A: Learning united visual representation by alignment before projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-LLaV A: Learning united visual representation by alignment before projection. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 5971–5984, Miami, Florida, USA, November
work page 2024
-
[42]
Association for Computational Linguistics
-
[43]
Self-introspective decoding: Alleviating hallucinations for large vision-language models
Fushuo Huo, Wenchao Xu, Zhong Zhang, Haozhao Wang, Zhicheng Chen, and Peilin Zhao. Self-introspective decoding: Alleviating hallucinations for large vision-language models. In ICLR, 2024. 12
work page 2024
-
[44]
Yuxuan Wang, Yueqian Wang, Dongyan Zhao, Cihang Xie, and Zilong Zheng. Videohallucer: Evaluating intrinsic and extrinsic hallucinations in large video-language models.arxiv, 2024
work page 2024
-
[45]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InThe 2023 Conference on Empirical Methods in Natural Language Processing, 2023
work page 2023
-
[46]
Object hallucination in image captioning
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. Object hallucination in image captioning. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4035–4045, 2018
work page 2018
-
[47]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. Mme: A comprehensive evaluation benchmark for multimodal large language models.arXiv preprint arXiv:2306.13394, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Mm-vet: Evaluating large multimodal models for integrated capabilities
Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities. In Forty-first International Conference on Machine Learning, 2024
work page 2024
-
[49]
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, et al. Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pag...
work page 2024
-
[50]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InProceedings of the European Conference on Computer Vision (ECCV), 2014
work page 2014
-
[51]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019. 13 A Theoretical Analysis This section gives a lightweight geometric justi...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.