Recognition: 2 theorem links
· Lean TheoremEmergent Communication between Heterogeneous Visual Agents through Decentralized Learning
Pith reviewed 2026-05-13 06:31 UTC · model grok-4.3
The pith
Agents with mismatched visual encoders develop shared descriptive token sequences through local acceptance-rejection exchanges alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the Metropolis-Hastings Captioning Game, two agents with frozen but heterogeneous visual encoders exchange proposed token sequences; each listener accepts or rejects a proposal by evaluating it against its private visual features via an MH-style criterion. Starting from random text modules, the agents converge on shared sequences that carry visual information, as measured by improved cross-agent alignment, visual-feature prediction, and image-text retrieval over a no-communication baseline. Moderate encoder mismatch reduces the number of shared sequences while preserving their per-sequence visual specificity; stronger mismatch produces fewer, coarser, and more asymmetric sequences. Ablgtl
What carries the argument
The Metropolis-Hastings Captioning Game (MHCG), in which a speaker proposes discrete token sequences and a listener accepts or rejects each proposal using an MH criterion computed solely from its own visual features.
If this is right
- Shared token sequences outperform a no-communication baseline on cross-agent alignment, visual-feature prediction, and image-text retrieval tasks.
- All cross-agent performance metrics decline monotonically as visual-encoder mismatch increases.
- Moderate encoder heterogeneity reduces the total number of shared sequences while preserving their visual specificity.
- Stronger encoder heterogeneity yields fewer, coarser-grained, and more asymmetric sequences.
- Listener-side MH acceptance is required to avoid degenerate token formation.
Where Pith is reading between the lines
- The same local-acceptance mechanism could be tested in multi-agent groups where each pair has a different degree of visual mismatch.
- If representational similarity controls language symmetry, then deliberately aligning low-level visual features across agents should increase the symmetry of the resulting token sequences.
- Under high heterogeneity the emergent language may become limited to coarse scene-level descriptions, suggesting a natural trade-off between shared vocabulary size and descriptive precision.
- The approach could be extended to sequential decision tasks where agents must coordinate actions using only the shared tokens they have already converged upon.
Load-bearing premise
Listener-side Metropolis-Hastings acceptance is sufficient to prevent degenerate token formation and to ground symbols in private visual features without any shared perceptual access.
What would settle it
If cross-agent alignment, feature-prediction, and retrieval metrics remain flat or improve as the visual encoders are made increasingly dissimilar, or if removing the listener-side MH acceptance step still yields non-degenerate shared sequences.
Figures









read the original abstract
Symbols are shared, but perception is private. We study emergent communication between heterogeneous visual agents through decentralized learning, asking what visual information can become shareable when agents have different visual representations. Instead of optimizing messages through a shared external communicative objective, our agents exchange only discrete token sequences and update their own models using local perceptual evidence. This setting focuses on an underexplored aspect of emergent communication, examining whether common symbols can arise without shared perceptual access, and how the similarity between private visual spaces constrains the content and symmetry of the resulting language. We instantiate this setting in the Metropolis-Hastings Captioning Game (MHCG), where two agents collaboratively form shared captions by exchanging proposed token sequences that a listener accepts or rejects using an MH-style criterion evaluated against its own visual features. We compare three pairings of frozen visual encoders, with agents starting from randomly initialized text modules. Experiments on MS-COCO show that MHCG produces visually informative shared token sequences that outperform a no-communication baseline in cross-agent alignment, visual-feature prediction, and image-text retrieval; all cross-agent metrics decline as encoder mismatch increases. Moderate encoder heterogeneity reduces the number of shared sequences while preserving per-sequence visual specificity, whereas stronger encoder heterogeneity yields fewer, coarser, and more asymmetric sequences. Ablations show that listener-side MH acceptance is critical for avoiding degenerate token formation. These results suggest that shared symbols can arise from local perceptual evaluation alone, with visual representational similarity across encoders shaping both the content and symmetry of the resulting language.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Metropolis-Hastings Captioning Game (MHCG), a decentralized protocol in which two agents with heterogeneous frozen visual encoders exchange discrete token sequences and accept or reject proposals according to a listener-side Metropolis-Hastings criterion evaluated solely on the listener’s private visual features. Starting from random text modules, the agents are shown to produce shared captions on MS-COCO that outperform a no-communication baseline on cross-agent alignment, visual-feature prediction, and image-text retrieval; all metrics decline monotonically with increasing encoder mismatch. Moderate heterogeneity reduces the number of shared sequences while preserving per-sequence specificity, whereas stronger mismatch yields fewer, coarser, and more asymmetric sequences. Ablations indicate that the MH acceptance rule is necessary to avoid degenerate token formation.
Significance. If the reported effects are reproducible, the work provides concrete evidence that grounded, non-degenerate symbols can emerge from purely local perceptual evaluation without any shared perceptual access or external communicative loss. The systematic dependence of language content and symmetry on encoder similarity offers a falsifiable prediction for heterogeneous multi-agent systems and strengthens the case that decentralized learning suffices for visual grounding.
major comments (2)
- [§4.2] §4.2 and Table 2: the claim that MH acceptance is critical for avoiding degeneracy rests on a single ablation; without quantitative results for the always-accept and random-accept controls (including token entropy, cross-agent alignment scores, and retrieval R@1), it is impossible to isolate the contribution of the MH criterion from the mere presence of any acceptance rule.
- [§3.3] §3.3: the acceptance probability is defined using the listener’s own visual features, yet no derivation or bound is given showing that this rule guarantees convergence to a non-degenerate equilibrium; the experimental results therefore remain the sole support for the grounding claim.
minor comments (3)
- [§4.1] The abstract and §4.1 omit vocabulary size, training schedule, and number of independent runs; these details are required to assess statistical significance of the reported metric declines.
- [Figure 3] Figure 3 caption should state the exact encoder pairs and the quantitative mismatch measure used on the x-axis.
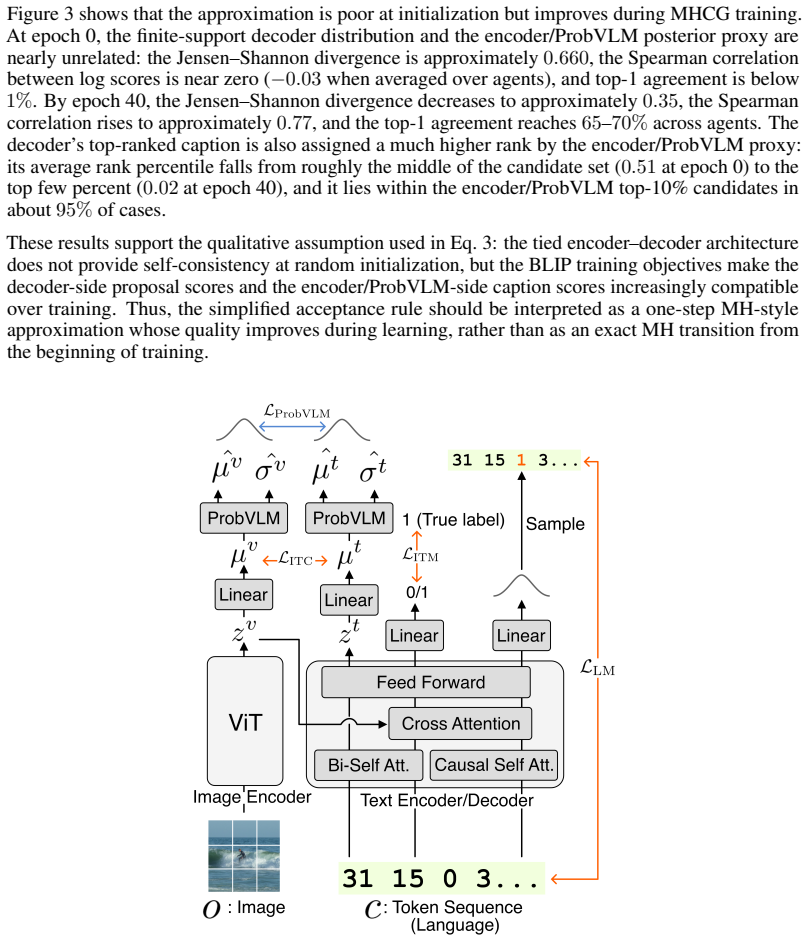
- [§3.2] Notation for the proposal distribution q(·) and the acceptance ratio is introduced without an explicit equation number; adding Eq. (X) would improve readability.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and constructive comments. We address each major point below and have revised the manuscript to strengthen the presentation of the ablation results and clarify the empirical scope of the work.
read point-by-point responses
-
Referee: [§4.2] §4.2 and Table 2: the claim that MH acceptance is critical for avoiding degeneracy rests on a single ablation; without quantitative results for the always-accept and random-accept controls (including token entropy, cross-agent alignment scores, and retrieval R@1), it is impossible to isolate the contribution of the MH criterion from the mere presence of any acceptance rule.
Authors: We agree that the original ablation was insufficiently detailed to fully isolate the MH criterion. In the revised manuscript we have expanded §4.2 and Table 2 to report full quantitative results for always-accept and random-accept controls, including token entropy, cross-agent alignment scores, and image-text retrieval R@1. These additional metrics show that both alternative rules produce high-entropy, low-alignment outputs, confirming that the Metropolis-Hastings acceptance step is necessary to avoid degeneracy. revision: yes
-
Referee: [§3.3] §3.3: the acceptance probability is defined using the listener’s own visual features, yet no derivation or bound is given showing that this rule guarantees convergence to a non-degenerate equilibrium; the experimental results therefore remain the sole support for the grounding claim.
Authors: The manuscript is explicitly empirical and does not claim a theoretical convergence guarantee. The listener-side MH rule is introduced as a local sampling mechanism that conditions proposals on the listener’s private visual features; no derivation of global convergence is provided because proving such a bound for heterogeneous, decentralized agents is beyond the scope of the present study. We have added a short paragraph in the discussion clarifying that the grounding evidence rests on the reported experiments and that formal analysis remains future work. revision: partial
Circularity Check
No significant circularity
full rationale
The paper's central results consist of empirical comparisons between MHCG agents and a no-communication baseline on MS-COCO, with metrics (cross-agent alignment, feature prediction, retrieval) measured directly from held-out data rather than defined in terms of the acceptance criterion or any fitted parameter. Ablations confirm the role of listener-side MH acceptance but do not reduce the reported performance deltas to the acceptance rule itself. No self-citation chain, ansatz smuggling, or uniqueness theorem is invoked to derive the observed degradation with encoder mismatch; the claims rest on observable experimental outcomes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Agents update their own models using only local perceptual evidence without shared access to the other agent's visual features
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The listener accepts or rejects the speaker’s proposed token sequence through a likelihood ratio evaluated against its own visual features... r = min(1, p(ĥLi,v | λ̂Li,t(c*)) / p(ĥLi,v | λ̂Li,t(c)))
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We compare three pairings of frozen visual encoders... all cross-agent metrics decline as encoder mismatch increases.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
H. H. Clark.Using language. Cambridge university press, 1996
work page 1996
-
[2]
H. H. Clark and S. E. Brennan. Grounding in communication. In L. B. Resnick, J. M. Levine, and S. D. Teasley, editors,Perspectives on Socially Shared Cognition, pages 127–149. American Psychological Association, 1991. 9
work page 1991
-
[3]
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An Image is Worth 16x16 Words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021. URLhttps://openreview.net/forum?id=YicbFdNTTy
work page 2021
-
[4]
K. Friston. The free-energy principle: a unified brain theory?Nature Reviews Neuroscience, 11:127–138, 2010. doi: 10.1038/nrn2787
-
[5]
K. J. Friston and C. D. Frith. Active inference, communication and hermeneutics.Cortex, 68: 129–143, 2015. doi: 10.1016/j.cortex.2015.03.025
-
[6]
K. J. Friston, T. Parr, C. Heins, A. Constant, D. Friedman, T. Isomura, C. Fields, T. Verbelen, M. Ramstead, J. Clippinger, and C. D. Frith. Federated inference and belief sharing.Neuro- science & Biobehavioral Reviews, 156:105500, 2024. doi: 10.1016/j.neubiorev.2023.105500
-
[7]
S. Havrylov and I. Titov. Emergence of language with multi-agent games: Learning to com- municate with sequences of symbols. InAdvances in Neural Information Processing Systems,
-
[8]
Emergence of Language with Multi-agent Games: Learning to Communicate with Sequences of Symbols
doi: 10.48550/arXiv.1705.11192. URL https://proceedings.neurips.cc/paper_ files/paper/2017/hash/70222949cc0db89ab32c9969754d4758-Abstract.html
-
[9]
K. He, X. Chen, S. Xie, Y . Li, P. Dollár, and R. Girshick. Masked autoencoders are scal- able vision learners. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16000–16009, 2022. doi: 10.1109/CVPR52688.2022. 01553. URLhttps://openaccess.thecvf.com/content/CVPR2022/html/He_Masked_ Autoencoders_Are_Scalable_...
-
[10]
N. L. Hoang, Y . Matsui, Y . Hagiwara, A. Taniguchi, and T. Taniguchi. Compositionality and generalization in emergent communication using metropolis–hastings naming game. In IEEE International Conference on Development and Learning (ICDL), pages 1–7, 2024. doi: 10.1109/ICDL61372.2024.10644635. URL https://doi.org/10.1109/ICDL61372.2024. 10644635
-
[12]
J. Inukai, T. Taniguchi, A. Taniguchi, and Y . Hagiwara. Recursive metropolis- hastings naming game: Symbol emergence in a multi-agent system based on prob- abilistic generative models.Frontiers in Artificial Intelligence, 6:1229127, 2023. doi: 10.3389/frai.2023.1229127. URL https://www.frontiersin.org/journals/ artificial-intelligence/articles/10.3389/fr...
-
[13]
N. Kriegeskorte, M. Mur, and P. A. Bandettini. Representational similarity analysis – con- necting the branches of systems neuroscience.Frontiers in Systems Neuroscience, 2:4,
-
[14]
URLhttps://doi.org/10.3389/neuro.06.004.2008
doi: 10.3389/neuro.06.004.2008. URL https://www.frontiersin.org/journals/ systems-neuroscience/articles/10.3389/neuro.06.004.2008/full
-
[15]
A. Lazaridou and M. Baroni. Emergent multi-agent communication in the deep learning era.arXiv preprint arXiv:2006.02419, 2020. doi: 10.48550/arXiv.2006.02419. URL https: //arxiv.org/abs/2006.02419
-
[16]
A. Lazaridou, K. M. Hermann, K. Tuyls, and S. Clark. Emergence of linguistic communication from referential games with symbolic and pixel input. InInternational Conference on Learning Representations, 2018. URLhttps://openreview.net/forum?id=HJGv1Z-AW
work page 2018
-
[17]
J. Li, D. Li, C. Xiong, and S. Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InProceedings of the 39th International Conference on Machine Learning, volume 162 ofProceedings of Machine Learning Research, pages 12888–12900, 2022. URLhttps://proceedings.mlr.press/v162/li22n.html. 10
work page 2022
-
[18]
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick. Microsoft coco: Common objects in context. InProceedings of ECCV, pages 740–755, 2014. doi: 10.1007/978-3-319-10602-1_48. URL https://www.ri.cmu.edu/publications/ microsoft-coco-common-objects-in-context/
-
[19]
I. Loshchilov and F. Hutter. Decoupled weight decay regularization. InProceedings of ICLR,
-
[20]
URLhttps://openreview.net/forum?id=Bkg6RiCqY7
- [21]
-
[22]
URLhttps://openreview.net/forum?id=8L3khbpUJL
-
[23]
Y . Matsui, R. Yamaki, R. Ueda, S. Shinagawa, and T. Taniguchi. Metropolis-hastings captioning game: Knowledge fusion of vision language models via decentralized bayesian inference. arXiv preprint arXiv:2504.09620, 2025. doi: 10.48550/arXiv.2504.09620. URL https: //arxiv.org/abs/2504.09620
- [24]
-
[25]
I. Mordatch and P. Abbeel. Emergence of grounded compositional language in multi-agent populations. InProceedings of the AAAI conference on artificial intelligence, volume 32, pages 1495–1502, 2018. doi: 10.1609/aaai.v32i1.11492. URL https://ojs.aaai.org/index. php/AAAI/article/view/11492
-
[26]
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski. Dinov2: Learning robust visual features without super...
work page 2024
-
[27]
J. Peters, C. Waubert de Puiseau, H. Tercan, A. Gopikrishnan, G. A. L. De Carvalho, C. Bitter, and T. Meisen. Emergent language: a survey and taxonomy.Autonomous Agents and Multi- Agent Systems, 39(1):18, 2025. doi: 10.1007/s10458-025-09691-y. URL https://doi.org/ 10.1007/s10458-025-09691-y
-
[28]
N. Pitzer and D. Mihai. Learning to communicate across modalities: Perceptual heterogeneity in multi-agent systems.arXiv preprint arXiv:2601.22041, 2026. doi: 10.48550/arXiv.2601.22041. URLhttps://arxiv.org/abs/2601.22041
-
[29]
M. Rita, F. Strub, J.-B. Grill, O. Pietquin, and E. Dupoux. On the role of population heterogeneity in emergent communication. InProceedings of ICLR, 2022
work page 2022
-
[30]
I. Sucholutsky, L. Muttenthaler, A. Weller, A. Peng, A. Bobu, P. de Haan, J. S. Bowers, and N. Kriegeskorte. Getting aligned on representational alignment.Transactions on Machine Learning Research, 2025. URLhttps://openreview.net/forum?id=Hiq7lUh4Yn
work page 2025
-
[31]
T. Taniguchi. Collective predictive coding hypothesis: Symbol emergence as decentralized bayesian inference.Frontiers in Robotics and AI, 11:1353870, 2024. doi: 10.3389/frobt. 2024.1353870. URL https://www.frontiersin.org/journals/robotics-and-ai/ articles/10.3389/frobt.2024.1353870/full
-
[32]
T. Taniguchi, Y . Yoshida, Y . Matsui, N. Le Hoang, A. Taniguchi, and Y . Hagiwara. Emer- gent communication through metropolis-hastings naming game with deep generative models. Advanced Robotics, 37(19):1266–1282, 2023. doi: 10.1080/01691864.2023.2260856. URL https://www.tandfonline.com/doi/full/10.1080/01691864.2023.2260856
-
[33]
T. Taniguchi, M. Oizumi, N. Saji, T. Horii, and N. Tsuchiya. Constructive approach to bidirectional influence between qualia structure and language emergence.Philosophy and the Mind Sciences, 6, 2025. doi: 10.33735/phimisci.2025.11765. 11
-
[34]
T. Taniguchi, S. Takagi, J. Otsuka, Y . Hayashi, and H. T. Hamada. Collective predictive coding as model of science: Formalizing scientific activities towards generative science.Royal Society Open Science, 12(6), 2025
work page 2025
-
[35]
T. Taniguchi, R. Ueda, T. Nakamura, M. Suzuki, and A. Taniguchi. Generative emergent commu- nication: Large language model is a collective world model.arXiv preprint arXiv:2501.00226,
-
[36]
doi: 10.48550/arXiv.2501.00226. URLhttps://arxiv.org/abs/2501.00226
-
[37]
Well-read students learn better: The impact of student initialization on knowledge distillation
I. Turc, M.-W. Chang, K. Lee, and K. Toutanova. Well-read students learn better: On the importance of pre-training compact models.arXiv preprint arXiv:1908.08962, 2019. doi: 10.48550/arXiv.1908.08962. URLhttps://github.com/google-research/bert
-
[38]
J. v. Uexküll.A foray into the worlds of animals and humans: With a theory of meaning, volume 12. University of Minnesota Press, 2013. URL https://www.upress.umn.edu/ book-division/books/a-foray-into-the-worlds-of-animals-and-humans
work page 2013
-
[39]
U. Upadhyay, S. Karthik, M. Mancini, and Z. Akata. Probvlm: Probabilistic adapter for frozen vision-language models. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 1899–1910, 2023. doi: 10.1109/ICCV51070.2023.00182. URL https://openaccess.thecvf.com/content/ICCV2023/html/Upadhyay_ProbVLM_ Probabilistic_Adapter_for_...
-
[40]
Representation Learning with Contrastive Predictive Coding
A. van den Oord, Y . Li, and O. Vinyals. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018. doi: 10.48550/arXiv.1807.03748. URL https://arxiv.org/abs/1807.03748. 12 A Correspondence between BLIP Training Losses and the Approximate M-step We relate the MHCG training procedure to a Monte Carlo EM-like update fo...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1807.03748 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.