Recognition: no theorem link
Design Your Ad: Personalized Advertising Image and Text Generation with Unified Autoregressive Models
Pith reviewed 2026-05-13 07:31 UTC · model grok-4.3
The pith
A single autoregressive model jointly generates personalized advertising images and texts from historical user clicks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Uni-AdGen employs a single autoregressive framework to produce both advertising images and texts, enhanced by a foreground perception module and instruction tuning for realism, together with a coarse-to-fine preference understanding module that captures user interests from noisy multimodal historical behaviors to drive personalized generation, and extensive experiments show it outperforms baselines on the PAd1M dataset using the Product Background Similarity metric.
What carries the argument
Uni-AdGen: unified autoregressive model with foreground perception module, instruction tuning, and coarse-to-fine preference understanding module that conditions generation on user click history.
If this is right
- Image and text ads can be generated jointly in one pass while remaining consistent with user-specific interests.
- Preference extraction from multimodal click history replaces reliance on average CTR signals.
- The PAd1M dataset enables large-scale supervised training for personalized ad tasks.
- The Product Background Similarity metric supports direct evaluation of how well generated ads match product contexts.
Where Pith is reading between the lines
- The same unified autoregressive structure could be tested on other multimodal content tasks such as personalized product descriptions or social posts.
- Streaming click data could be fed into the preference module for near-real-time ad adaptation if latency allows.
- Direct integration with existing recommender systems would let click signals flow straight into ad generation without intermediate CTR averaging.
Load-bearing premise
Historical click behaviors supply a reliable signal of individual preferences that the coarse-to-fine module extracts without bias from noise.
What would settle it
An A/B test in which ads produced by the model receive no higher click-through rates than those from separate baseline systems would falsify the personalization advantage.
Figures









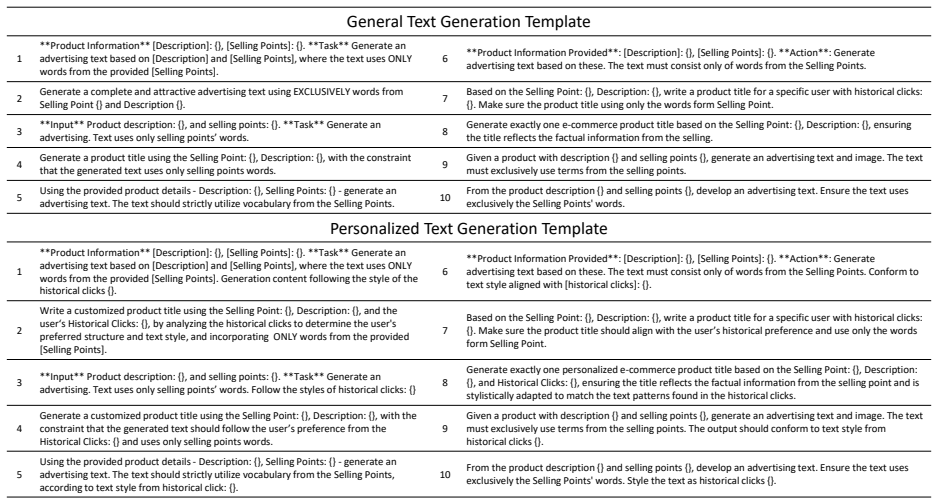





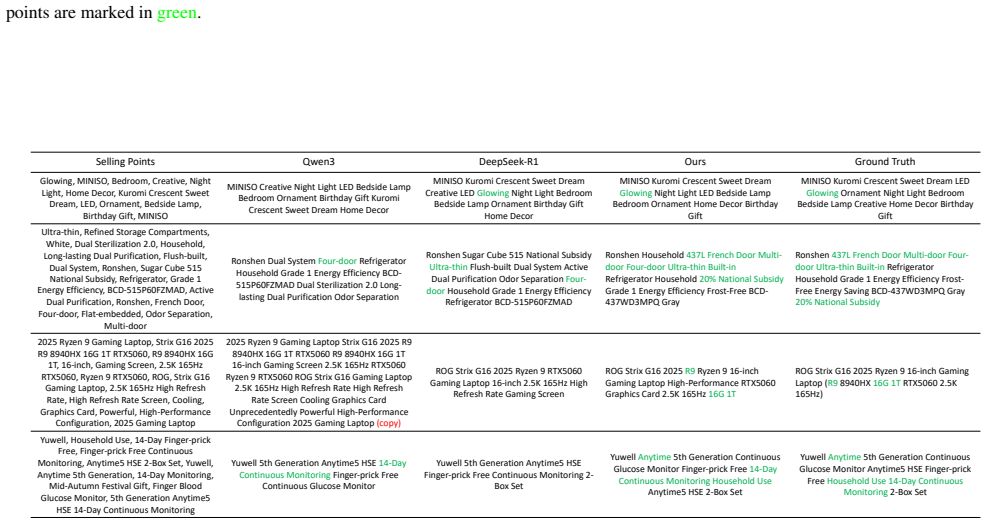


read the original abstract
Generating realistic and user-preferred advertisements is a key challenge in e-commerce. Existing approaches utilize multiple independent models driven by click-through-rate (CTR) to controllably create attractive image or text advertisements. However, their pipelines lack cross-modal perception and rely on CTR that only reflects average preferences. Therefore, we explore jointly generating personalized image-text advertisements from historical click behaviors. We first design a Unified Advertisement Generative model (Uni-AdGen) that employs a single autoregressive framework to produce both advertising images and texts. By incorporating a foreground perception module and instruction tuning, Uni-AdGen enhances the realism of the generated content. To further personalize advertisements, we equip Uni-AdGen with a coarse-to-fine preference understanding module that effectively captures user interests from noisy multimodal historical behaviors to drive personalized generation. Additionally, we construct the first large-scale Personalized Advertising image-text dataset (PAd1M) and introduce a Product Background Similarity (PBS) metric to facilitate training and evaluation. Extensive experiments show that our method outperforms baselines in general and personalized advertisement generation. Our project is available at https://github.com/JD-GenX/Uni-AdGen.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Uni-AdGen, a single autoregressive model for jointly generating personalized advertising images and texts from historical click behaviors. It incorporates a foreground perception module with instruction tuning for realism and a coarse-to-fine preference understanding module to extract user interests from noisy multimodal data. The authors also release the PAd1M dataset and propose the Product Background Similarity (PBS) metric, claiming that extensive experiments demonstrate outperformance over baselines in both general and personalized ad generation tasks.
Significance. If the results hold, the work offers a practical advance in unified multimodal generation for e-commerce advertising by moving beyond separate CTR-driven pipelines to a single model conditioned on individual user history. The release of a large-scale personalized ad dataset would be a useful community resource, though its impact depends on whether the proposed PBS metric and preference module demonstrably improve perceived ad quality beyond existing metrics.
major comments (3)
- [§4.2] §4.2: PBS is introduced as the primary evaluation metric for background similarity between generated and reference product images, yet the manuscript provides no ablation, correlation analysis, or validation against human judgments, FID, CLIPScore, or CTR. Without evidence that PBS aligns with ad quality or user preference, the central claim of outperformance over baselines rests on an unverified metric and cannot be assessed.
- [Experiments] Experiments section: The abstract and main claims assert quantitative outperformance, but no specific metrics, baselines, dataset statistics, error bars, or ablation results are supplied in the provided text. This prevents verification of the reported gains and leaves the soundness of the empirical evaluation unclear.
- [Coarse-to-fine preference understanding module] Coarse-to-fine preference module: The assumption that historical click behaviors yield reliable personalized signals is load-bearing for the personalization contribution, but no analysis of noise robustness, bias introduction, or comparison to simpler conditioning methods is presented.
minor comments (2)
- [§3] The notation for the unified autoregressive framework and module interfaces could be clarified with an explicit diagram or pseudocode to aid reproducibility.
- [Dataset] Dataset construction details for PAd1M (e.g., filtering criteria, user count, click distribution) are referenced but not fully tabulated, which would help readers assess its scale and diversity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point-by-point below and will incorporate revisions to strengthen the empirical validation and analysis in the next version of the manuscript.
read point-by-point responses
-
Referee: [§4.2] §4.2: PBS is introduced as the primary evaluation metric for background similarity between generated and reference product images, yet the manuscript provides no ablation, correlation analysis, or validation against human judgments, FID, CLIPScore, or CTR. Without evidence that PBS aligns with ad quality or user preference, the central claim of outperformance over baselines rests on an unverified metric and cannot be assessed.
Authors: We agree that additional validation for PBS is necessary. PBS was introduced to specifically quantify background similarity for product-centric ads, complementing general metrics like FID. In the revised manuscript, we will add an ablation study removing PBS from training/evaluation, Pearson/Spearman correlations with human preference ratings on ad quality, and direct comparisons against FID, CLIPScore, and CTR on the PAd1M test set to demonstrate alignment with user-perceived ad effectiveness. revision: yes
-
Referee: Experiments section: The abstract and main claims assert quantitative outperformance, but no specific metrics, baselines, dataset statistics, error bars, or ablation results are supplied in the provided text. This prevents verification of the reported gains and leaves the soundness of the empirical evaluation unclear.
Authors: The full manuscript contains these details (PBS, FID, CLIPScore, human study scores; baselines including separate CTR-driven image/text models and multimodal generators; PAd1M statistics with 1M image-text pairs; error bars from 3 runs; ablations on foreground perception, instruction tuning, and coarse-to-fine modules). We will reorganize the Experiments section for clearer presentation with additional tables summarizing all numbers and statistical significance tests in the revision. revision: partial
-
Referee: Coarse-to-fine preference module: The assumption that historical click behaviors yield reliable personalized signals is load-bearing for the personalization contribution, but no analysis of noise robustness, bias introduction, or comparison to simpler conditioning methods is presented.
Authors: We will add this analysis in the revision. New experiments will include: (1) controlled noise injection into click histories (random clicks, missing modalities) and resulting performance degradation curves; (2) bias checks via demographic subgroup analysis on PAd1M; (3) direct comparisons to simpler baselines such as mean-pooled history embeddings or single-stage conditioning. These results will quantify the module's robustness and incremental benefit. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an autoregressive model trained end-to-end on historical click data and a newly constructed PAd1M dataset, with evaluation using both standard metrics and the introduced PBS background-similarity score. No mathematical derivations, predictions, or first-principles results are presented that reduce by construction to fitted parameters or self-referential definitions. The central claims rest on empirical outperformance on held-out data rather than any self-definitional loop, fitted-input-as-prediction, or load-bearing self-citation chain. The PBS metric is an auxiliary evaluation tool whose correlation with human preference is not proven, but this is a validity concern rather than circularity in the derivation.
Axiom & Free-Parameter Ledger
free parameters (1)
- model hyperparameters
axioms (1)
- domain assumption Autoregressive models can jointly model image and text distributions when conditioned on user history
invented entities (2)
-
foreground perception module
no independent evidence
-
coarse-to-fine preference understanding module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 1, 4, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Improving image generation with better captions.Computer Science
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, et al. Improving image generation with better captions.Computer Science. https://cdn. openai. com/papers/dall-e-3. pdf, 2(3):8, 2023. 1, 2
work page 2023
-
[4]
Ke Cao, Jing Wang, Ao Ma, Jiasong Feng, Zhanjie Zhang, Xuanhua He, Shanyuan Liu, Bo Cheng, Dawei Leng, Yuhui Yin, et al. Relactrl: Relevance-guided efficient control for diffusion transformers.arXiv preprint arXiv:2502.14377,
-
[5]
Tingfeng Cao, Junsheng Kong, Xue Zhao, Wenqing Yao, Junwei Ding, Jinhui Zhu, and Jiandong Zhang. Prod- uct2img: Prompt-free e-commerce product background gen- eration with diffusion model and self-improved lmm. InPro- ceedings of the 32nd ACM International Conference on Mul- timedia, pages 10774–10783, 2024. 1, 2
work page 2024
-
[6]
Maxmin-rlhf: Towards equitable alignment of large language models with diverse human preferences
Souradip Chakraborty, Jiahao Qiu, Hui Yuan, Alec Koppel, Furong Huang, Dinesh Manocha, Amrit Bedi, and Mengdi Wang. Maxmin-rlhf: Towards equitable alignment of large language models with diverse human preferences. InICML 2024 Workshop on Models of Human Feedback for AI Align- ment, 2024. 4
work page 2024
-
[7]
Hongyu Chen, Yiqi Gao, Min Zhou, Peng Wang, Xubin Li, Tiezheng Ge, and Bo Zheng. Enhancing prompt following with visual control through training-free mask-guided diffu- sion.arXiv preprint arXiv:2404.14768, 2024. 2
-
[8]
Hongyu Chen, Min Zhou, Jing Jiang, Jiale Chen, Yang Lu, Zihang Lin, Bo Xiao, Tiezheng Ge, and Bo Zheng. T-stars- poster: A framework for product-centric advertising image design.arXiv preprint arXiv:2501.14316, 2025. 1, 2
-
[9]
Junyi Chen, Lu Chi, Siliang Xu, Shiwei Ran, Bingyue Peng, and Zehuan Yuan. Hllm-creator: Hierarchical llm- based personalized creative generation.arXiv preprint arXiv:2508.18118, 2025. 2, 3
-
[10]
Enhancing uncertainty modeling with semantic graph for hallucination detection
Kedi Chen, Qin Chen, Jie Zhou, Xinqi Tao, Bowen Ding, Jingwen Xie, Mingchen Xie, Peilong Li, and Zheng Feng. Enhancing uncertainty modeling with semantic graph for hallucination detection. InProceedings of the AAAI Con- ference on Artificial Intelligence, pages 23586–23594, 2025. 2
work page 2025
-
[11]
Pog: personalized outfit generation for fashion recommendation at alibaba ifashion
Wen Chen, Pipei Huang, Jiaming Xu, Xin Guo, Cheng Guo, Fei Sun, Chao Li, Andreas Pfadler, Huan Zhao, and Bin- qiang Zhao. Pog: personalized outfit generation for fashion recommendation at alibaba ifashion. InProceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, pages 2662–2670, 2019. 4
work page 2019
-
[12]
An empirical study of training self-supervised vision transformers
Xinlei Chen, Saining Xie, and Kaiming He. An empirical study of training self-supervised vision transformers. InPro- ceedings of the IEEE/CVF international conference on com- puter vision, pages 9640–9649, 2021. 4
work page 2021
-
[13]
Ctr-driven advertising image generation with multimodal large language models
Xingye Chen, Wei Feng, Zhenbang Du, Weizhen Wang, Yanyin Chen, Haohan Wang, Linkai Liu, Yaoyu Li, Jinyuan Zhao, Yu Li, et al. Ctr-driven advertising image generation with multimodal large language models. InProceedings of the ACM on Web Conference 2025, pages 2262–2275, 2025. 1, 2, 4
work page 2025
-
[14]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus- pro: Unified multimodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Yixiao Chen, Zhiyuan Ma, Guoli Jia, Che Jiang, Jianjun Li, and Bowen Zhou. Context-aware autoregressive mod- els for multi-conditional image generation.arXiv preprint arXiv:2505.12274, 2025. 3
-
[16]
Ctr-driven ad text generation via online feedback preference optimization
Yanda Chen, Zihui Ren, Qixiang Gao, Jiale Chen, Si Chen, Xubin Li, Tiezheng Ge, and Bo Zheng. Ctr-driven ad text generation via online feedback preference optimization. arXiv preprint arXiv:2507.20227, 2025. 1, 2, 3
-
[17]
Reproducible scal- ing laws for contrastive language-image learning
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuh- mann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scal- ing laws for contrastive language-image learning. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2818–2829, 2023. 4
work page 2023
-
[18]
Towards reliable advertising image generation us- ing human feedback
Zhenbang Du, Wei Feng, Haohan Wang, Yaoyu Li, Jingsen Wang, Jian Li, Zheng Zhang, Jingjing Lv, Xin Zhu, Junsheng Jin, et al. Towards reliable advertising image generation us- ing human feedback. InEuropean Conference on Computer Vision, pages 399–415. Springer, 2024. 1, 4, 7, 3
work page 2024
-
[19]
Scaling recti- fied flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling recti- fied flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning,
-
[20]
Jiahao Fan, Yuxin Qin, Wei Feng, Yanyin Chen, Yaoyu Li, Ao Ma, Yixiu Li, Li Zhuang, Haoyi Bian, Zheng Zhang, et al. Autopp: Towards automated product poster generation and optimization.arXiv preprint arXiv:2512.21921, 2025. 2
-
[21]
Postermaker: Towards 9 high-quality product poster generation with accurate text rendering
Yifan Gao, Zihang Lin, Chuanbin Liu, Min Zhou, Tiezheng Ge, Bo Zheng, and Hongtao Xie. Postermaker: Towards 9 high-quality product poster generation with accurate text rendering. InProceedings of the Computer Vision and Pat- tern Recognition Conference, pages 8083–8093, 2025. 1, 2, 4, 7, 3
work page 2025
-
[22]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 1, 2, 3, 7, 8, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Feng Han, Yang Jiao, Shaoxiang Chen, Junhao Xu, Jingjing Chen, and Yu-Gang Jiang. Controlthinker: Unveiling latent semantics for controllable image generation through visual reasoning.arXiv preprint arXiv:2506.03596, 2025. 3
-
[24]
F Maxwell Harper and Joseph A Konstan. The movielens datasets: History and context.Acm transactions on interac- tive intelligent systems (tiis), 5(4):1–19, 2015. 4
work page 2015
-
[25]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022. 7
work page 2022
-
[26]
Daniel R Jiang, Alex Nikulkov, Yu-Chia Chen, Yang Bai, and Zheqing Zhu. Improving generative ad text on facebook using reinforcement learning.arXiv preprint arXiv:2507.21983, 2025. 2, 3
-
[27]
Yiping Jin, Akshay Bhatia, Dittaya Wanvarie, and Phu TV Le. Towards improving coherence and diversity of slogan generation.Natural Language Engineering, 29(2):254–286,
-
[28]
Yashal Shakti Kanungo, Gyanendra Das, Pooja A, and Sumit Negi. Cobart: controlled, optimized, bidirectional and auto- regressive transformer for ad headline generation. InPro- ceedings of the 28th ACM SIGKDD conference on knowl- edge discovery and data mining, pages 3127–3136, 2022. 2
work page 2022
-
[29]
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Ma- tiana, Joe Penna, and Omer Levy. Pick-a-pic: An open dataset of user preferences for text-to-image generation.Ad- vances in neural information processing systems, 36:36652– 36663, 2023. 7
work page 2023
-
[30]
Flux.https://github.com/ black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/ black-forest-labs/flux, 2024. 1, 2, 4, 7, 3
work page 2024
-
[31]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dock- horn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742,
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Relation-aware diffusion model for controllable poster layout generation
Fengheng Li, An Liu, Wei Feng, Honghe Zhu, Yaoyu Li, Zheng Zhang, Jingjing Lv, Xin Zhu, Junjie Shen, Zhangang Lin, et al. Relation-aware diffusion model for controllable poster layout generation. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management, pages 1249–1258, 2023. 2
work page 2023
-
[33]
Culg: Commer- cial universal language generation
Haonan Li, Yameng Huang, Yeyun Gong, Jian Jiao, Ruofei Zhang, Timothy Baldwin, and Nan Duan. Culg: Commer- cial universal language generation. InProceedings of the 2022 Conference of the North American Chapter of the As- sociation for Computational Linguistics: Human Language Technologies: Industry Track, pages 112–120, 2022. 1, 2
work page 2022
-
[34]
Xiang Li, Kai Qiu, Hao Chen, Jason Kuen, Zhe Lin, Rita Singh, and Bhiksha Raj. Controlvar: Exploring con- trollable visual autoregressive modeling.arXiv preprint arXiv:2406.09750, 2024. 3
-
[35]
Zhaochen Li, Fengheng Li, Wei Feng, Honghe Zhu, Yaoyu Li, Zheng Zhang, Jingjing Lv, Junjie Shen, Zhangang Lin, Jingping Shao, et al. Planning and rendering: Towards prod- uct poster generation with diffusion models.arXiv preprint arXiv:2312.08822, 2023. 1, 2
-
[36]
Zongming Li, Tianheng Cheng, Shoufa Chen, Peize Sun, Haocheng Shen, Longjin Ran, Xiaoxin Chen, Wenyu Liu, and Xinggang Wang. Controlar: Controllable image generation with autoregressive models.arXiv preprint arXiv:2410.02705, 2024. 1, 3
-
[37]
Rouge: A package for automatic evaluation of summaries
Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. InText summarization branches out, pages 74–81, 2004. 4, 7
work page 2004
-
[38]
Autoposter: A highly automatic and content-aware design system for ad- vertising poster generation
Jinpeng Lin, Min Zhou, Ye Ma, Yifan Gao, Chenxi Fei, Yangjian Chen, Zhang Yu, and Tiezheng Ge. Autoposter: A highly automatic and content-aware design system for ad- vertising poster generation. InProceedings of the 31st ACM International Conference on Multimedia, pages 1250–1260,
-
[39]
Run Ling, Wenji Wang, Yuting Liu, Guibing Guo, Haowei Liu, Jian Lu, Quanwei Zhang, Yexing Xu, Shuo Lu, Yun Wang, et al. Ragar: retrieval augmented personalized im- age generation guided by recommendation.arXiv preprint arXiv:2505.01657, 2025. 4
-
[40]
Ser30k: A large-scale dataset for sticker emotion recognition
Shengzhe Liu, Xin Zhang, and Jufeng Yang. Ser30k: A large-scale dataset for sticker emotion recognition. InPro- ceedings of the 30th ACM International Conference on Mul- timedia, pages 33–41, 2022. 4
work page 2022
-
[41]
Uni-layout: Integrating human feedback in unified layout generation and evaluation
Shuo Lu, Yanyin Chen, Wei Feng, Jiahao Fan, Fengheng Li, Zheng Zhang, Jingjing Lv, Junjie Shen, Ching Law, and Jian Liang. Uni-layout: Integrating human feedback in unified layout generation and evaluation. InProceedings of the 33rd ACM International Conference on Multimedia, pages 7709– 7718, 2025. 2
work page 2025
-
[42]
Shuo Lu, Haohan Wang, Wei Feng, Weizhen Wang, Shen Zhang, Yaoyu Li, Ao Ma, Zheng Zhang, Jingjing Lv, Junjie Shen, et al. One size, many fits: Aligning diverse group-wise click preferences in large-scale advertising image generation. arXiv preprint arXiv:2602.02033, 2026. 2
-
[43]
Lay2story: extending diffu- sion transformers for layout-togglable story generation
Ao Ma, Jiasong Feng, Ke Cao, Jing Wang, Yun Wang, Quan- wei Zhang, and Zhanjie Zhang. Lay2story: extending diffu- sion transformers for layout-togglable story generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 16102–16111, 2025. 4
work page 2025
-
[44]
Soichiro Murakami, Peinan Zhang, Hidetaka Kamigaito, Hi- roya Takamura, and Manabu Okumura. Adparaphrase: Para- phrase dataset for analyzing linguistic features toward gen- erating attractive ad texts.arXiv preprint arXiv:2502.04674,
-
[45]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 6 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318,
-
[47]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion mod- els for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023. 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Qwen2.5 technical report, 2025
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Jun- yang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao L...
work page 2025
-
[49]
Language models are unsu- pervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsu- pervised multitask learners.OpenAI blog, 1(8):9, 2019. 1
work page 2019
-
[50]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image gener- ation with clip latents.arXiv preprint arXiv:2204.06125, 1 (2):3, 2022. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[51]
Shyam Sundhar Ramesh, Yifan Hu, Iason Chaimalas, Viraj Mehta, Pier Giuseppe Sessa, Haitham Bou Ammar, and Ilija Bogunovic. Group robust preference optimization in reward- free rlhf.Advances in Neural Information Processing Sys- tems, 37:37100–37137, 2024. 4
work page 2024
-
[52]
Grounded sam: Assembling open-world models for diverse visual tasks,
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kun- chang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, Zhaoyang Zeng, Hao Zhang, Feng Li, Jie Yang, Hongyang Li, Qing Jiang, and Lei Zhang. Grounded sam: Assembling open-world models for diverse visual tasks,
-
[53]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 2
work page 2022
-
[54]
Clip+mlp aesthetic score pre- dictor
Christoph Schuhmann. Clip+mlp aesthetic score pre- dictor. https://github.com/christophschuhmann/improved- aesthetic-predictor., 2022. 7
work page 2022
-
[55]
Controllable and diverse text generation in e-commerce
Huajie Shao, Jun Wang, Haohong Lin, Xuezhou Zhang, As- ton Zhang, Heng Ji, and Tarek Abdelzaher. Controllable and diverse text generation in e-commerce. InProceedings of the Web Conference 2021, pages 2392–2401, 2021. 1, 2
work page 2021
-
[56]
Autoprompt: Eliciting knowledge from lan- guage models with automatically generated prompts,
Taylor Shin, Yasaman Razeghi, Robert L Logan IV , Eric Wallace, and Sameer Singh. Autoprompt: Eliciting knowl- edge from language models with automatically generated prompts.arXiv preprint arXiv:2010.15980, 2020. 1
-
[57]
Oriane Sim ´eoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104, 2025. 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, and Zehuan Yuan. Autoregressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525, 2024. 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[59]
Shikun Sun, Min Zhou, Zixuan Wang, Xubin Li, Tiezheng Ge, Zijie Ye, Xiaoyu Qin, Junliang Xing, Bo Zheng, and Jia Jia. Minimal impact controlnet: Advancing multi-controlnet integration.arXiv preprint arXiv:2506.01672, 2025. 2
-
[60]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 6
work page 2017
-
[61]
Beyond quality: Unlocking diver- sity in ad headline generation with large language models
Chang Wang, Siyu Yan, Depeng Yuan, Yuqi Chen, Yan- hua Huang, Yuanhang Zheng, Shuhao Li, Yinqi Zhang, Kedi Chen, Mingrui Zhu, et al. Beyond quality: Unlocking diver- sity in ad headline generation with large language models. arXiv preprint arXiv:2508.18739, 2025. 1, 2, 3
-
[62]
Haohan Wang, Wei Feng, Yaoyu Li, Zheng Zhang, Jingjing Lv, Junjie Shen, Zhangang Lin, and Jingping Shao. Gen- erate e-commerce product background by integrating cate- gory commonality and personalized style. InICASSP 2025- 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2025. 2
work page 2025
-
[63]
arXiv preprint arXiv:2503.08153 (2025) 6, 1
Jing Wang, Ao Ma, Ke Cao, Jun Zheng, Zhanjie Zhang, Jiasong Feng, Shanyuan Liu, Yuhang Ma, Bo Cheng, Dawei Leng, et al. Wisa: World simulator assistant for physics-aware text-to-video generation.arXiv preprint arXiv:2503.08153, 2025. 4
-
[64]
Imagen editor and editbench: Advancing and evaluating text-guided im- age inpainting
Su Wang, Chitwan Saharia, Ceslee Montgomery, Jordi Pont- Tuset, Shai Noy, Stefano Pellegrini, Yasumasa Onoe, Sarah Laszlo, David J Fleet, Radu Soricut, et al. Imagen editor and editbench: Advancing and evaluating text-guided im- age inpainting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18359– 18369, 2023. 1, 2
work page 2023
-
[65]
Yun Wang, Kunhong Li, Longguang Wang, Junjie Hu, Dapeng Oliver Wu, and Yulan Guo. Adstereo: Efficient stereo matching with adaptive downsampling and disparity alignment.IEEE Transactions on Image Processing, 2025. 4
work page 2025
-
[66]
Dualnet: Ro- bust self-supervised stereo matching with pseudo-label su- pervision
Yun Wang, Jiahao Zheng, Chenghao Zhang, Zhanjie Zhang, Kunhong Li, Yongjian Zhang, and Junjie Hu. Dualnet: Ro- bust self-supervised stereo matching with pseudo-label su- pervision. InProceedings of the AAAI Conference on Artifi- cial Intelligence, pages 8178–8186, 2025. 4
work page 2025
-
[67]
Penghui Wei, Xuanhua Yang, Shaoguo Liu, Liang Wang, and Bo Zheng. Creater: Ctr-driven advertising text genera- tion with controlled pre-training and contrastive fine-tuning. arXiv preprint arXiv:2205.08943, 2022. 1, 2
-
[68]
Janus: Decoupling visual encod- ing for unified multimodal understanding and generation
Chengyue Wu, Xiaokang Chen, Zhiyu Wu, Yiyang Ma, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, Chong Ruan, et al. Janus: Decoupling visual encod- ing for unified multimodal understanding and generation. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 12966–12977, 2025. 1, 5
work page 2025
-
[69]
Lumina-mgpt 2.0: Stand-alone autoregressive image modeling.arXiv preprint arXiv:2507.17801, 2025
Yi Xin, Juncheng Yan, Qi Qin, Zhen Li, Dongyang Liu, Shicheng Li, Victor Shea-Jay Huang, Yupeng Zhou, Ren- 11 rui Zhang, Le Zhuo, et al. Lumina-mgpt 2.0: Stand- alone autoregressive image modeling.arXiv preprint arXiv:2507.17801, 2025. 3
-
[70]
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagere- ward: Learning and evaluating human preferences for text- to-image generation.Advances in Neural Information Pro- cessing Systems, 36:15903–15935, 2023. 7
work page 2023
-
[71]
Scalar: Scale-wise controllable visual autoregressive learning.arXiv preprint arXiv:2507.19946, 2025
Ryan Xu, Dongyang Jin, Yancheng Bai, Rui Lan, Xu Duan, Lei Sun, and Xiangxiang Chu. Scalar: Scale-wise controllable visual autoregressive learning.arXiv preprint arXiv:2507.19946, 2025. 3
-
[72]
Personalized image generation with large multimodal models
Yiyan Xu, Wenjie Wang, Yang Zhang, Biao Tang, Peng Yan, Fuli Feng, and Xiangnan He. Personalized image generation with large multimodal models. InProceedings of the ACM on Web Conference 2025, pages 264–274, 2025. 8, 4
work page 2025
-
[73]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 1, 2, 3, 7, 8, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
A new creative generation pipeline for click- through rate with stable diffusion model
Hao Yang, Jianxin Yuan, Shuai Yang, Linhe Xu, Shuo Yuan, and Yifan Zeng. A new creative generation pipeline for click- through rate with stable diffusion model. InCompanion Pro- ceedings of the ACM Web Conference 2024, pages 180–189,
work page 2024
-
[75]
Car: Controllable autoregressive modeling for visual generation
Ziyu Yao, Jialin Li, Yifeng Zhou, Yong Liu, Xi Jiang, Chengjie Wang, Feng Zheng, Yuexian Zou, and Lei Li. Car: Controllable autoregressive modeling for visual generation. arXiv preprint arXiv:2410.04671, 2024. 3
-
[76]
Dian Yu, Zhou Yu, and Kenji Sagae. Attribute alignment: Controlling text generation from pre-trained language mod- els.arXiv preprint arXiv:2103.11070, 2021. 1
-
[77]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023. 1, 2, 3
work page 2023
-
[78]
Zhanjie Zhang, Ao Ma, Ke Cao, Jing Wang, Shanyuan Liu, Yuhang Ma, Bo Cheng, Dawei Leng, and Yuhui Yin. U- stydit: Ultra-high quality artistic style transfer using diffu- sion transformers.arXiv preprint arXiv:2503.08157, 2025. 4
-
[79]
Dreampainter: Image background inpainting for e-commerce scenarios.arXiv preprint arXiv:2508.02155,
Sijie Zhao, Jing Cheng, Yaoyao Wu, Hao Xu, and Shao- hui Jiao. Dreampainter: Image background inpainting for e-commerce scenarios.arXiv preprint arXiv:2508.02155,
-
[80]
2 12 Design Your Ad: Personalized Advertising Image and Text Generation with Unified Autoregressive Models Appendix This appendix details the design for human evaluation met- rics in Sec. 7. Section 9 provides comprehensive visual com- parisons with baseline methods under both personalized and non- personalized settings. To justify our model configuration...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.