Recognition: 2 theorem links
· Lean TheoremTransferable Delay-Aware Reinforcement Learning via Implicit Causal Graph Modeling
Pith reviewed 2026-05-13 06:57 UTC · model grok-4.3
The pith
By modeling implicit causal graphs in observations, a new reinforcement learning method learns delay-robust policies that transfer across tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
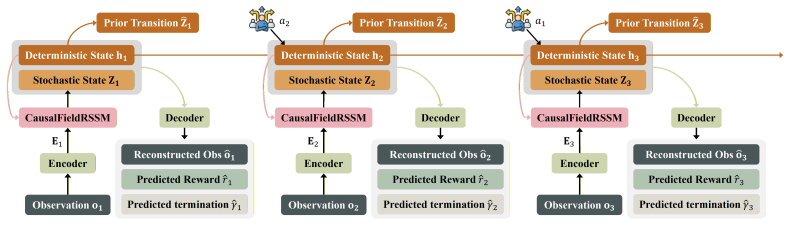
The paper claims that representing observations as latent states with node-level semantics and using message passing to capture their dynamic causal dependencies produces structured, transferable knowledge of environment dynamics. This knowledge then drives imagination-based behavior learning and planning in the latent space, yielding policies that remain effective under random delays and adapt rapidly when task objectives or rewards are altered.
What carries the argument
The field-node encoder paired with a message-passing mechanism, which extracts node semantics from observations and models evolving causal dependencies among nodes to support latent-space planning.
If this is right
- Policies optimized via latent imagination remain effective when action effects arrive after unpredictable delays.
- Learned node representations and causal dynamics transfer to new tasks, reducing the number of environment steps needed for adaptation.
- Cross-task experiments confirm faster policy learning when both the encoder and dynamics model are reused.
- The method outperforms standard baselines on delayed versions of DMC continuous-control benchmarks.
Where Pith is reading between the lines
- The same node-and-message structure could be tested in partially observable or multi-agent settings where timing mismatches are common.
- If the extracted causal dependencies prove stable, the approach might combine with explicit causal discovery tools to improve interpretability of learned policies.
- A natural next check is whether the latent planning step still accelerates adaptation when delays vary during training rather than staying fixed.
Load-bearing premise
A field-node encoder combined with message passing can reliably pull out node-level semantics and causal dependencies from high-dimensional observations that remain useful even when delays are random and task goals or rewards change.
What would settle it
Run the method and a non-causal baseline on a continuous-control task with injected random delays, then switch to a new reward function; if the proposed method shows no measurable speedup in adaptation steps or success rate, the central claim does not hold.
Figures







read the original abstract
Random delays weaken the temporal correspondence between actions and subsequent state feedback, making it difficult for agents to identify the true propagation process of action effects. In cross-task scenarios, changes in task objectives and reward formulations further reduce the reusability of previously acquired task knowledge. To address this problem, this paper proposes a transferable delay-aware reinforcement learning method based on implicit causal graph modeling. The proposed method uses a field-node encoder to represent high-dimensional observations as latent states with node-level semantics, and employs a message-passing mechanism to characterize dynamic causal dependencies among nodes, thereby learning transferable structured representations and environment dynamics knowledge. On this basis, imagination-driven behavior learning and planning are incorporated to optimize policies in the latent space, enabling cross-task knowledge transfer and rapid adaptation. Experimental results show that the proposed method outperforms baseline methods on DMC continuous control tasks with random delays. Cross-task transfer experiments further demonstrate that the learned structured representations and dynamics knowledge can be effectively transferred to new tasks and significantly accelerate policy adaptation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a transferable delay-aware RL method via implicit causal graph modeling. A field-node encoder maps high-dimensional observations to latent states carrying node-level semantics; message passing then captures dynamic causal dependencies among nodes. These structured representations and learned dynamics support imagination-driven behavior learning and planning in latent space, enabling cross-task knowledge transfer despite random delays and reward changes. Experiments on DMC continuous-control tasks report outperformance over baselines under random delays, with additional cross-task transfer results showing accelerated policy adaptation.
Significance. If the central claims hold, the work would offer a concrete mechanism for learning reusable causal structures in delayed and multi-objective RL settings, potentially improving sample efficiency when transferring across tasks whose rewards differ. The integration of implicit graph modeling with model-based planning addresses a practically relevant gap between standard RL assumptions and real-world temporal asynchrony.
major comments (2)
- [Abstract] Abstract: the claim that the field-node encoder plus message-passing layer yields node-level semantics and dynamic causal dependencies that remain stable under reward changes is load-bearing for the transfer results, yet the manuscript supplies no invariance loss, causal-identifiability constraint, or ablation that isolates message passing from the encoder alone.
- [Experimental Results] Experimental section: the reported outperformance and transfer acceleration are presented without statistical significance tests, number of independent runs, or ablation tables comparing the full model against an encoder-only variant; this leaves open whether the gains derive from the implicit causal graph or from other implementation choices.
minor comments (1)
- [Abstract] Abstract: a short statement of the concrete baselines and the magnitude of the reported gains would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the field-node encoder plus message-passing layer yields node-level semantics and dynamic causal dependencies that remain stable under reward changes is load-bearing for the transfer results, yet the manuscript supplies no invariance loss, causal-identifiability constraint, or ablation that isolates message passing from the encoder alone.
Authors: We acknowledge the absence of an explicit invariance loss or causal-identifiability constraint. The message-passing layer is intended to model environment dynamics (state transitions), which are independent of task-specific rewards, while the field-node encoder supplies the node semantics; this separation is inherent to the model-based formulation. To strengthen the claim, we will add an ablation comparing the full model against an encoder-only variant and include a short discussion of the dynamics-reward separation. We will not introduce a new invariance loss, as it is not required by the current architecture. revision: partial
-
Referee: [Experimental Results] Experimental section: the reported outperformance and transfer acceleration are presented without statistical significance tests, number of independent runs, or ablation tables comparing the full model against an encoder-only variant; this leaves open whether the gains derive from the implicit causal graph or from other implementation choices.
Authors: We thank the referee for highlighting this gap. In the revised manuscript we will report the number of independent runs (five random seeds), add statistical significance tests (paired t-tests with p-values), and include ablation tables that explicitly compare the full model to an encoder-only variant as well as other controls. These additions will clarify that performance and transfer gains are attributable to the implicit causal graph modeling. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper proposes an architecture combining a field-node encoder with message passing to learn latent node semantics and causal dependencies for delay-aware RL, then uses imagination-driven planning in that space. No equations, fitted parameters, or self-citations are shown that reduce any claimed prediction or transfer result to a tautology or input by construction. The central claims rest on experimental outcomes on DMC tasks rather than on any self-referential definition or renamed known result. The method description builds on standard GNN and model-based RL components without importing uniqueness theorems or ansatzes from prior author work that would force the outcome.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption High-dimensional observations can be represented as latent states possessing node-level semantics whose dynamic causal dependencies are recoverable by message passing.
Reference graph
Works this paper leans on
- [1]
-
[2]
Dream to Control: Learning Behaviors by Latent Imagination
D. Hafner, T. Lillicrap, J. Ba, M. Norouzi, Dream to control: Learning behaviors by latent imagination, arXiv preprint arXiv:1912.01603 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[3]
Mastering Atari with Discrete World Models
D. Hafner, T. Lillicrap, M. Norouzi, J. Ba, Mastering atari with discrete world models, arXiv preprint arXiv:2010.02193 (2020)
work page internal anchor Pith review arXiv 2010
-
[4]
Mastering Diverse Domains through World Models
D. Hafner, J. Pasukonis, J. Ba, T. Lillicrap, Mastering diverse domains through world models, arXiv preprint arXiv:2301.04104 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
H. Gao, T. Xu, T. Zhang, Y . Guo, C. Zhao, J. Ren, Y . Jiang, S. Guo, F. Chen, Causal dreamer for partially observable model-based reinforcement learning, Neurocomputing (2025) 131012
work page 2025
- [6]
-
[7]
Z. Hao, H. Zhu, W. Chen, R. Cai, Latent causal dynamics model for model- based reinforcement learning, in: International Conference on Neural Infor- mation Processing, Springer, 2023, pp. 219–230. 36
work page 2023
-
[8]
S. Tunyasuvunakool, A. Muldal, Y . Doron, S. Liu, S. Bohez, J. Merel, T. Erez, T. Lillicrap, N. Heess, Y . Tassa, Dm_control: Software and tasks for continu- ous control, Software Impacts 6 (2020) 100022
work page 2020
- [9]
-
[10]
T. Haarnoja, A. Zhou, P. Abbeel, S. Levine, Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor, in: International Conference on Machine Learning, Pmlr, 2018, pp. 1861–1870
work page 2018
- [11]
- [12]
-
[13]
V . Micheli, E. Alonso, F. Fleuret, Efficient world models with context-aware tokenization, arXiv preprint arXiv:2406.19320 (2024)
-
[14]
S. Ramasubramanian, B. Freed, A. Capone, J. Schneider, Improving model- based reinforcement learning by converging to flatter minima, in: Annual Conference on Neural Information Processing Systems, V ol. 38, 2025, p. 114981–115007
work page 2025
- [15]
-
[16]
W. Zhang, A. Jelley, T. McInroe, A. Storkey, Objects matter: Object-centric world models improve reinforcement learning in visually complex environ- ments, arXiv preprint arXiv:2501.16443 (2025)
-
[17]
B. Frauenknecht, D. Subhasish, F. Solowjow, S. Trimpe, On rollouts in model- based reinforcement learning, arXiv preprint arXiv:2501.16918 (2025)
-
[18]
WIMLE: Uncertainty-Aware World Models with IMLE for Sample-Efficient Continuous Control
M. Aghabozorgi, A. Moazeni, Y . Zhang, K. Li, WIMLE: Uncertainty-aware world models with IMLE for sample-efficient continuous control, arXiv preprint arXiv:2602.14351 (2026). 37
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [19]
- [20]
- [21]
-
[22]
J. Lv, Y . Feng, C. Zhang, S. Zhao, L. Shao, C. Lu, SAM-RL: Sensing- aware model-based reinforcement learning via differentiable physics-based simulation and rendering, The International Journal of Robotics Research 44 (10-11) (2025) 1767–1783
work page 2025
- [23]
- [24]
- [25]
- [26]
-
[27]
H. Lin, W. Ding, J. Chen, L. Shi, J. Zhu, B. Li, D. Zhao, Because: Bilinear causal representation for generalizable offline model-based reinforcement learning, in: Advances in Neural Information Processing Systems, V ol. 37, 2024, pp. 114510–114552
work page 2024
- [28]
-
[29]
M. Hong, Z. Qi, Y . Xu, Model-based reinforcement learning for confounded POMDPs, in: International Conference on Machine Learning, V ol. 235, 2024, pp. 18668–18710
work page 2024
-
[30]
N. Venkatesh, A. A. Malikopoulos, Model-based reinforcement learning under confounding, arXiv preprint arXiv:2512.07528 (2025)
- [31]
-
[32]
Y . Tassa, Y . Doron, A. Muldal, T. Erez, Y . Li, D. d. L. Casas, D. Budden, A. Abdolmaleki, J. Merel, A. Lefrancq, et al., Deepmind control suite, arXiv preprint arXiv:1801.00690 (2018). 39
work page internal anchor Pith review arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.