Recognition: unknown
Differences in Text Generated by Diffusion and Autoregressive Language Models
Pith reviewed 2026-05-14 20:55 UTC · model grok-4.3
The pith
Diffusion language models generate text with higher semantic coherence and diversity than autoregressive models due to bidirectional context in training, while lower entropy stems from their decoding algorithms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
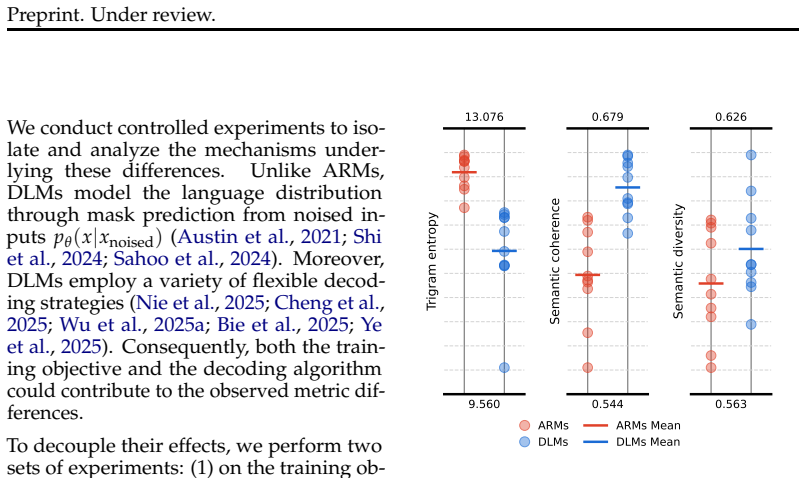
Off-the-shelf diffusion language models exhibit lower n-gram entropy, higher semantic coherence, and higher semantic diversity compared to autoregressive models. Controlled experiments that decouple training objectives from decoding algorithms show the DLM training objective, driven primarily by bidirectional context, accounts for the coherence and diversity increases while exerting only minor influence on entropy. The entropy drop arises chiefly from DLMs' decoding algorithms, especially confidence-based remasking strategies, which receive a theoretical explanation.
What carries the argument
Controlled experiments that isolate training-objective effects from decoding-algorithm effects, highlighting bidirectional context and confidence-based remasking.
Load-bearing premise
The controlled experiments cleanly separate training-objective contributions from decoding-algorithm contributions without confounding from implementation details or data choices.
What would settle it
Training a DLM with unidirectional instead of bidirectional context and observing no rise in semantic coherence relative to autoregressive models would undermine the claim that bidirectional context drives the coherence difference.
Figures











read the original abstract
Diffusion language models (DLMs) are promising alternatives to autoregressive language models (ARMs), yet the intrinsic differences in their generated text remain underexplored. We first find empirically that off-the-shelf DLMs exhibit lower $n$-gram entropy, higher semantic coherence, and higher semantic diversity. To understand the cause, we conduct controlled experiments that decouple the effects of training objectives and decoding algorithms. Results suggest that the DLM training objective contributes to the increases in semantic coherence and semantic diversity, but has a minor influence on entropy. These differences are primarily driven by the bidirectional context; other components in the training objective, such as input masking, label masking, and the weighting function, have a much weaker influence. Further, our experiments demonstrate that the reduction in entropy stems from DLMs' decoding algorithms, particularly confidence-based remasking strategies. We provide a theoretical understanding for this entropy reduction phenomenon. Together, our work uncovers key mechanisms underlying the differences between DLMs and ARMs in text generation, and informs future design of training objectives and decoding algorithms in DLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper empirically shows that off-the-shelf diffusion language models (DLMs) generate text with lower n-gram entropy, higher semantic coherence, and higher semantic diversity than autoregressive language models (ARMs). It performs controlled experiments to isolate the contributions of the DLM training objective (particularly bidirectional context) versus decoding algorithms (especially confidence-based remasking), concluding that the training objective drives the coherence and diversity gains while decoding drives the entropy reduction, and supplies a theoretical account of the latter.
Significance. If the decoupling holds, the work supplies a useful mechanistic account of why DLMs and ARMs differ in generation statistics, directly informing the design of training objectives and decoding procedures for diffusion-based text models. The attempt to separate objective effects from decoding effects and the inclusion of a theoretical explanation for entropy reduction are constructive elements that strengthen the paper's potential contribution.
major comments (2)
- [Controlled experiments section] Controlled experiments section: the manuscript provides no quantitative description of how model size, optimizer state, data selection, batch statistics, or exact masking/attention schedules are equalized when bidirectional context is introduced into otherwise autoregressive training setups. This omission leaves the central causal attribution (bidirectional context as the primary driver of coherence/diversity gains) vulnerable to implementation confounds.
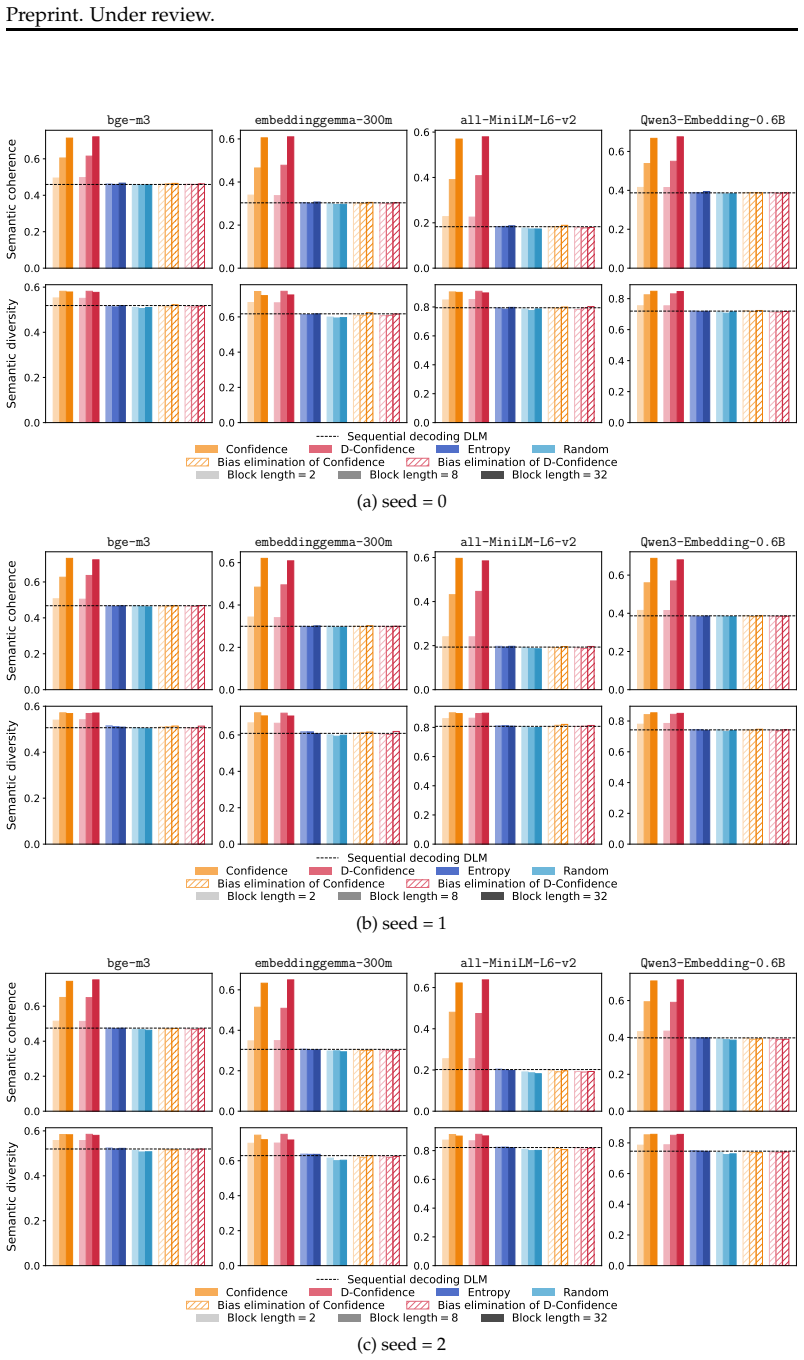
- [Results on entropy reduction] Results on entropy reduction: while the paper attributes lower entropy to confidence-based remasking, the supporting experiments do not report ablation controls that hold the training objective fixed while varying only the remasking strategy against standard autoregressive sampling; without these, the claim that decoding algorithms are the dominant factor remains under-supported.
minor comments (2)
- [Abstract] Abstract: no numerical values, effect sizes, or statistical tests are supplied to quantify the reported differences in entropy, coherence, or diversity, reducing the reader's ability to gauge practical magnitude.
- [Metrics definitions] Notation: the precise definitions of the semantic coherence and semantic diversity metrics (e.g., embedding model, aggregation method) should be stated explicitly in the main text rather than deferred to appendices.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and commit to revisions that strengthen the clarity and rigor of our controlled experiments and supporting analyses.
read point-by-point responses
-
Referee: Controlled experiments section: the manuscript provides no quantitative description of how model size, optimizer state, data selection, batch statistics, or exact masking/attention schedules are equalized when bidirectional context is introduced into otherwise autoregressive training setups. This omission leaves the central causal attribution (bidirectional context as the primary driver of coherence/diversity gains) vulnerable to implementation confounds.
Authors: We agree that additional quantitative details on the controlled setup are warranted to rule out confounds. In the experiments, we matched model sizes (both variants used 1.3B parameters with identical layer counts and hidden dimensions), optimizer (AdamW with the same learning rate schedule and weight decay), training data (identical subsets of the pretraining corpus), and batch statistics (same batch size and gradient accumulation steps). The sole systematic change was the attention mask enabling bidirectional context in the DLM variant while keeping all other hyperparameters fixed. We will add a dedicated paragraph and table in the revised Controlled Experiments section that explicitly lists these matched values along with the exact masking ratios and attention schedule differences. revision: yes
-
Referee: Results on entropy reduction: while the paper attributes lower entropy to confidence-based remasking, the supporting experiments do not report ablation controls that hold the training objective fixed while varying only the remasking strategy against standard autoregressive sampling; without these, the claim that decoding algorithms are the dominant factor remains under-supported.
Authors: We appreciate this point on the need for clearer isolation of decoding effects. Our current experiments already apply multiple decoding strategies (including confidence-based remasking versus standard sampling) to models trained under the same objective, but we acknowledge that the presentation could more explicitly highlight the fixed-objective ablations against autoregressive baselines. We will expand the Results section with additional ablation tables that hold the training objective constant and directly compare remasking variants to AR sampling, thereby providing stronger quantitative support for the claim that decoding drives the observed entropy reduction. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central claims rest on described controlled experiments that attempt to isolate training-objective effects (bidirectional context, masking, weighting) from decoding algorithms, plus a separate theoretical argument for entropy reduction. No load-bearing step reduces by construction to a fitted parameter renamed as prediction, a self-defined quantity, or a self-citation chain. The experiments and theory are presented as independent of the paper's own output quantities, making the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Training objectives and decoding algorithms can be independently varied in controlled experiments
Reference graph
Works this paper leans on
-
[1]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Abdelrahman Abouelenin, Atabak Ashfaq, Adam Atkinson, Hany Awadalla, Nguyen Bach, Jianmin Bao, Alon Benhaim, Martin Cai, Vishrav Chaudhary, Congcong Chen, et al. Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture-of-loras.arXiv preprint arXiv:2503.01743,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv preprint arXiv:2503.09573 , year=
Marianne Arriola, Aaron Gokaslan, Justin T Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and Volodymyr Kuleshov. Block diffusion: Interpolating between autoregressive and diffusion language models.arXiv preprint arXiv:2503.09573,
-
[3]
Heli Ben-Hamu, Itai Gat, Daniel Severo, Niklas Nolte, and Brian Karrer. Accelerated sampling from masked diffusion models via entropy bounded unmasking.arXiv preprint arXiv:2505.24857,
-
[4]
Tiwei Bie, Maosong Cao, Kun Chen, Lun Du, Mingliang Gong, Zhuochen Gong, Yanmei Gu, Jiaqi Hu, Zenan Huang, Zhenzhong Lan, et al. Llada2. 0: Scaling up diffusion language models to 100b.arXiv preprint arXiv:2512.15745,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation.arXiv preprint arXiv:2402.03216, 4(5),
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Shuang Cheng, Yihan Bian, Dawei Liu, Linfeng Zhang, Qian Yao, Zhongbo Tian, Wen- hai Wang, Qipeng Guo, Kai Chen, Biqing Qi, et al. Sdar: A synergistic diffusion- autoregression paradigm for scalable sequence generation.arXiv preprint arXiv:2510.06303,
-
[7]
Tinystories: How small can language models be and still speak coherent english?
10 Preprint. Under review. Ronen Eldan and Yuanzhi Li. Tinystories: How small can language models be and still speak coherent english?arXiv preprint arXiv:2305.07759,
-
[8]
Theoretical benefit and limitation of diffusion language model.arXiv preprint arXiv:2502.09622,
Guhao Feng, Yihan Geng, Jian Guan, Wei Wu, Liwei Wang, and Di He. Theoretical benefit and limitation of diffusion language model.arXiv preprint arXiv:2502.09622,
-
[9]
What makes diffusion language models super data learners?arXiv preprint arXiv:2510.04071,
Zitian Gao, Haoming Luo, Lynx Chen, Jason Klein Liu, Ran Tao, Joey Zhou, and Bryan Dai. What makes diffusion language models super data learners?arXiv preprint arXiv:2510.04071,
-
[10]
A Comparative analysis of Layer-wise Representational Capacity in AR and Diffusion LLMs
Raghavv Goel, Risheek Garrepalli, Sudhanshu Agrawal, Chris Lott, Mingu Lee, and Fatih Porikli. Skip to the good part: Representation structure & inference-time layer skipping in diffusion vs. autoregressive llms.arXiv preprint arXiv:2603.07475,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Scaling diffusion language models via adaptation from autoregressive models
Shansan Gong, Shivam Agarwal, Yizhe Zhang, Jiacheng Ye, Lin Zheng, Mukai Li, Chenxin An, Peilin Zhao, Wei Bi, Jiawei Han, et al. Scaling diffusion language models via adapta- tion from autoregressive models.arXiv preprint arXiv:2410.17891,
-
[12]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Albert Qiaochu Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Deven- dra Singh Chaplot, Diego de Las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, L ´elio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timoth´ee Lacroix, and William El Sayed. Mistral 7b.ArXiv, abs/23...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Haozhe Jiang, Nika Haghtalab, and Lijie Chen
URL https://api.semanticscholar.org/ CorpusID:263830494. Haozhe Jiang, Nika Haghtalab, and Lijie Chen. Diffusion language models are provably optimal parallel samplers.arXiv preprint arXiv:2512.25014,
-
[16]
Jaeyeon Kim, Kulin Shah, Vasilis Kontonis, Sham Kakade, and Sitan Chen. Train for the worst, plan for the best: Understanding token ordering in masked diffusions.arXiv preprint arXiv:2502.06768,
-
[17]
Robert Kirk, Ishita Mediratta, Christoforos Nalmpantis, Jelena Luketina, Eric Hambro, Edward Grefenstette, and Roberta Raileanu. Understanding the effects of rlhf on llm generalisation and diversity.arXiv preprint arXiv:2310.06452,
-
[18]
Gen Li and Changxiao Cai. Breaking ar’s sampling bottleneck: Provable acceleration via diffusion language models.arXiv preprint arXiv:2505.21400,
-
[19]
Diffusion Language Models Know the Answer Before Decoding
Pengxiang Li, Yefan Zhou, Dilxat Muhtar, Lu Yin, Shilin Yan, Li Shen, Soroush Vosoughi, and Shiwei Liu. Diffusion language models know the answer before decoding.arXiv preprint arXiv:2508.19982, 2025a. Tianyi Li, Mingda Chen, Bowei Guo, and Zhiqiang Shen. A survey on diffusion language models.arXiv preprint arXiv:2508.10875, 2025b. 11 Preprint. Under revi...
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution.arXiv preprint arXiv:2310.16834,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Diffusion language models are super data learners.arXiv preprint arXiv:2511.03276,
Jinjie Ni, Qian Liu, Longxu Dou, Chao Du, Zili Wang, Hang Yan, Tianyu Pang, and Michael Qizhe Shieh. Diffusion language models are super data learners.arXiv preprint arXiv:2511.03276,
-
[23]
Zanlin Ni, Shenzhi Wang, Yang Yue, Tianyu Yu, Weilin Zhao, Yeguo Hua, Tianyi Chen, Jun Song, Cheng Yu, Bo Zheng, et al. The flexibility trap: Why arbitrary order limits reasoning potential in diffusion language models.arXiv preprint arXiv:2601.15165,
-
[24]
Scaling up masked diffusion models on text.arXiv preprint arXiv:2410.18514,
Shen Nie, Fengqi Zhu, Chao Du, Tianyu Pang, Qian Liu, Guangtao Zeng, Min Lin, and Chongxuan Li. Scaling up masked diffusion models on text.arXiv preprint arXiv:2410.18514,
-
[25]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models.arXiv preprint arXiv:2502.09992,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
arXiv preprint arXiv:2406.03736 , year=
Jingyang Ou, Shen Nie, Kaiwen Xue, Fengqi Zhu, Jiacheng Sun, Zhenguo Li, and Chongxuan Li. Your absorbing discrete diffusion secretly models the conditional distributions of clean data.arXiv preprint arXiv:2406.03736,
-
[27]
Diffusion beats autoregressive in data-constrained settings.arXiv preprint arXiv:2507.15857,
Mihir Prabhudesai, Mengning Wu, Amir Zadeh, Katerina Fragkiadaki, and Deepak Pathak. Diffusion beats autoregressive in data-constrained settings.arXiv preprint arXiv:2507.15857,
-
[28]
Step-wise refusal dynamics in autoregressive and diffusion language models
Eliron Rahimi, Elad Hirshel, Rom Himelstein, Amit LeVi, Avi Mendelson, and Chaim Baskin. Step-wise refusal dynamics in autoregressive and diffusion language models. arXiv preprint arXiv:2602.02600,
-
[29]
A Theoretical Analysis of Why Masked Diffusion Models Mitigate the Reversal Curse
Sangwoo Shin, BumJun Kim, Kyelim Lee, Moongyu Jeon, and Albert No. Understanding the reversal curse mitigation in masked diffusion models through attention and training dynamics.arXiv preprint arXiv:2602.02133,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Yuxuan Song, Zheng Zhang, Cheng Luo, Pengyang Gao, Fan Xia, Hao Luo, Zheng Li, Yuehang Yang, Hongli Yu, Xingwei Qu, et al. Seed diffusion: A large-scale diffusion language model with high-speed inference.arXiv preprint arXiv:2508.02193,
-
[31]
URLhttps://arxiv.org/abs/2503.19786. Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth´ee Lacroix, Baptiste Rozi `ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023a. 13 Preprint. Under review. Hugo Touvron, Louis Martin, Ke...
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Diffusion language models generation can be halted early.arXiv preprint arXiv:2305.10818,
Sofia Maria Lo Cicero Vaina, Nikita Balagansky, and Daniil Gavrilov. Diffusion language models generation can be halted early.arXiv preprint arXiv:2305.10818,
-
[33]
arXiv preprint arXiv:2509.20354 (2025) 6
Henrique Schechter Vera, Sahil Dua, Biao Zhang, Daniel Salz, Ryan Mullins, Sindhu Raghu- ram Panyam, Sara Smoot, Iftekhar Naim, Joe Zou, Feiyang Chen, et al. Embeddinggemma: Powerful and lightweight text representations.arXiv preprint arXiv:2509.20354,
-
[34]
Zihang Wang, Siyue Zhang, Yilun Zhao, Jingyi Yang, Tingyu Song, Anh Tuan Luu, and Chen Zhao. Analyzing diffusion and autoregressive vision language models in multimodal embedding space.arXiv preprint arXiv:2602.06056,
-
[35]
Zichen Wen, Jiashu Qu, Zhaorun Chen, Xiaoya Lu, Dongrui Liu, Zhiyuan Liu, Ruixi Wu, Yicun Yang, Xiangqi Jin, Haoyun Xu, et al. The devil behind the mask: An emergent safety vulnerability of diffusion llms.arXiv preprint arXiv:2507.11097,
-
[36]
Fast-dllm v2: Efficient block-diffusion llm.arXiv preprint arXiv:2509.26328, 2025a
Chengyue Wu, Hao Zhang, Shuchen Xue, Shizhe Diao, Yonggan Fu, Zhijian Liu, Pavlo Molchanov, Ping Luo, Song Han, and Enze Xie. Fast-dllm v2: Efficient block-diffusion llm.arXiv preprint arXiv:2509.26328, 2025a. Chengyue Wu, Hao Zhang, Shuchen Xue, Zhijian Liu, Shizhe Diao, Ligeng Zhu, Ping Luo, Song Han, and Enze Xie. Fast-dllm: Training-free acceleration ...
-
[37]
Zhen Xiong, Yujun Cai, Zhecheng Li, and Yiwei Wang. Unveiling the potential of diffusion large language model in controllable generation.arXiv preprint arXiv:2507.04504,
-
[38]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, Mei Li, Mingfeng ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Siyue Zhang, Yilun Zhao, Liyuan Geng, Arman Cohan, Luu Anh Tuan, and Chen Zhao. Dif- fusion vs. autoregressive language models: A text embedding perspective. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 4273–4303, 2025a. Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Continue the following text in approximately 500 words: [PROMPT]
15 Preprint. Under review. A Evaluation details of off-the-shelf models We collect a dataset of texts generated by off-the-shelf DLMs and ARMs for evaluation. Generation configuration.We randomly sample 1000 examples from the FineWeb dataset (Penedo et al., 2024). For each example, we use its first 30 tokens as a prompt and generate 20 continuations using...
work page 2024
-
[41]
+· · ·+H(X L |X 1:L−1 ). (14) It is sufficient to show that for every position i and possible prefix sequence x1:i−1, we have ∀k, k ∑ c=1 pdlcr(Xi =c|X 1:i−1 =x 1:i−1 )≥ k ∑ c=1 qi c. (15) This is a majorization relation (Marshall et al., 1979). Since the entropy function is Schur- concave, the majorization implies H(X i |X 1:i−1 =x 1:i−1 )≤ H(q i) =H(p i...
work page 1979
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.