Recognition: 2 theorem links
· Lean TheoremA Comparative analysis of Layer-wise Representational Capacity in AR and Diffusion LLMs
Pith reviewed 2026-05-15 14:57 UTC · model grok-4.3
The pith
Diffusion language models build redundant early-layer representations that allow skipping up to 18.75% of layers with over 90% performance retention on reasoning tasks, unlike autoregressive models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Native diffusion language models exhibit substantial early-layer redundancy induced by the full-sequence denoising objective, resulting in higher inter-layer cosine similarities and less recency bias compared to autoregressive models. This allows for static skipping of up to 18.75% of layers at inference while retaining over 90% performance on math-reasoning and coding benchmarks, in contrast to AR models which collapse under identical skipping strategies. AR-initialized dLLMs retain AR-like dynamics, confirming that the objective rather than architecture alone drives the redundancy.
What carries the argument
Layer-wise and token-wise cosine similarity combined with static inference-time layer-skipping as a probe for representational redundancy between diffusion and autoregressive objectives.
If this is right
- Native dLLMs achieve up to 18.75% FLOPs reduction with over 90% retained performance on math and coding benchmarks.
- AR models experience sharp performance collapse under the same layer-skipping regime.
- AR-initialized dLLMs maintain AR-like layer dynamics and recency bias despite diffusion training.
- Diffusion objectives produce more global representations with early-layer redundancy and reduced recency bias.
Where Pith is reading between the lines
- This indicates potential for developing hybrid training methods that combine AR and diffusion to balance performance and efficiency.
- Dynamic, input-dependent layer skipping could further optimize inference in dLLMs based on task complexity.
- The findings suggest that representational analysis via skipping could be applied to other modalities like vision or multimodal models.
Load-bearing premise
That skipping fixed layers at inference time accurately measures inherent representational redundancy without creating model-type-specific artifacts.
What would settle it
Measuring performance retention on the same math-reasoning benchmarks after skipping equivalent early layers in a newly trained native dLLM versus an AR model of similar size.
Figures








read the original abstract
Autoregressive (AR) language models build representations incrementally via left-to-right prediction, while diffusion language models (dLLMs) are trained through full-sequence denoising. Although recent dLLMs match AR performance, whether diffusion objectives fundamentally reshape internal representations remains unclear. We perform the first layer- and token-wise representational analysis comparing native dLLMs (LLaDA), native AR models (Qwen2.5), and AR-initialized dLLMs (Dream-7B), using cosine similarity across layers and tokens alongside static inference-time layer-skipping as an analytical probe of redundancy. We find that diffusion objectives produce more global representations with substantial early-layer redundancy and reduced recency bias, while AR objectives yield tightly coupled, locally structured representations. AR-initialized dLLMs retain AR-like dynamics despite diffusion training, revealing persistent initialization bias. Leveraging this redundancy, native dLLMs absorb up to 18.75% FLOPs reduction while retaining over 90% performance on math-reasoning and coding benchmarks, whereas AR models collapse under identical skipping, revealing that diffusion objectives, rather than architecture alone, induce depth redundancy that enables principled compression.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper performs a comparative layer- and token-wise analysis of native diffusion LLMs (LLaDA), native autoregressive models (Qwen2.5), and AR-initialized diffusion models (Dream-7B) using cosine similarity metrics and static inference-time layer skipping. It claims that diffusion training produces more global representations with early-layer redundancy and reduced recency bias, while AR training yields locally coupled representations. AR-initialized dLLMs retain AR-like dynamics. The key empirical result is that native dLLMs tolerate up to 18.75% FLOPs reduction via layer skipping while retaining >90% performance on math-reasoning and coding benchmarks, whereas AR models collapse under the same regime, attributing the redundancy to the diffusion objective rather than architecture.
Significance. If the central attribution holds, the work provides the first direct evidence that training objective (diffusion vs. AR) induces measurable depth redundancy exploitable for inference compression, with concrete FLOPs savings on standard benchmarks. The inclusion of the AR-initialized control (Dream-7B) is a strength that helps isolate objective effects from architectural ones. This has clear implications for efficient deployment of dLLMs and for understanding how denoising objectives reshape representation reuse.
major comments (2)
- [Abstract and §4 (layer-skipping experiments)] Abstract and layer-skipping results: The headline claim that diffusion objectives induce depth redundancy (enabling 18.75% FLOPs reduction with >90% retention) rests on static layer skipping as a probe. However, the paper does not report a direct check that identical skip patterns produce equivalent representational disruption (measured by the paper's own cosine-similarity metric) under dLLM full-sequence denoising versus AR left-to-right generation. Without this, procedure-specific artifacts cannot be ruled out.
- [§4.2 (control experiments)] §4.2 (control experiments): The AR-initialized dLLM (Dream-7B) retains AR-like dynamics, supporting initialization bias. Yet the manuscript provides no ablation confirming that the skipping procedure interacts with the diffusion sampling schedule in a manner comparable to AR decoding; this leaves the attribution to training objective under-supported for the compression result.
minor comments (2)
- [Abstract] Abstract: The phrase 'native dLLMs absorb up to 18.75% FLOPs reduction' should specify the exact skipping schedule and number of layers skipped for reproducibility.
- [Results] Presentation: The manuscript would benefit from explicit error bars or multiple random seeds on the performance-retention numbers in the skipping experiments, as the current description leaves the stability of the >90% retention claim unclear.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for acknowledging the value of the AR-initialized control (Dream-7B). We address the two major comments below, clarifying our experimental design while agreeing to strengthen the manuscript with additional analyses.
read point-by-point responses
-
Referee: [Abstract and §4 (layer-skipping experiments)] Abstract and layer-skipping results: The headline claim that diffusion objectives induce depth redundancy (enabling 18.75% FLOPs reduction with >90% retention) rests on static layer skipping as a probe. However, the paper does not report a direct check that identical skip patterns produce equivalent representational disruption (measured by the paper's own cosine-similarity metric) under dLLM full-sequence denoising versus AR left-to-right generation. Without this, procedure-specific artifacts cannot be ruled out.
Authors: We agree that explicitly comparing representational disruption under each model's native inference procedure would further isolate objective-driven effects. Cosine similarities in the manuscript are already measured on activations produced during the respective processes (full-sequence denoising steps for dLLMs; left-to-right token generation for AR models). The static skip is applied identically by layer index in both cases. In the revision we will add a direct side-by-side analysis of the cosine-similarity change induced by the same skip masks, evaluated at matched points in each generation trajectory. This will confirm that the observed early-layer redundancy in native dLLMs is not an artifact of the denoising schedule. revision: yes
-
Referee: [§4.2 (control experiments)] §4.2 (control experiments): The AR-initialized dLLM (Dream-7B) retains AR-like dynamics, supporting initialization bias. Yet the manuscript provides no ablation confirming that the skipping procedure interacts with the diffusion sampling schedule in a manner comparable to AR decoding; this leaves the attribution to training objective under-supported for the compression result.
Authors: The uniform layer-index skipping is already applied across every denoising step for dLLMs and every decoding step for AR models, and Dream-7B's retention of AR-like skipping intolerance under the diffusion schedule already provides evidence that inference procedure alone does not explain the redundancy difference. Nevertheless, to address the interaction concern directly we will add a targeted ablation in the revision that varies skip application across early, middle, and late stages of the diffusion schedule while holding the AR decoding schedule fixed for comparison. This will further support that the compression benefit is attributable to the training objective. revision: partial
Circularity Check
No circularity; empirical comparisons and direct measurements
full rationale
The paper's claims rest on direct empirical observations: cosine-similarity computations across layers/tokens and static inference-time layer-skipping experiments performed on native dLLMs (LLaDA), native AR models (Qwen2.5), and AR-initialized dLLMs (Dream-7B). The 18.75% FLOPs reduction with >90% retention on math/coding tasks is reported as a measured outcome of applying the same skipping procedure, not a fitted parameter renamed as a prediction or a quantity derived by construction from the inputs. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps; the comparative controls (including persistent AR-like behavior in Dream-7B) provide independent contrast without reducing the central attribution to diffusion objectives to a definitional equivalence. The analysis is self-contained against external benchmarks and contains no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Representational similarity can be measured via cosine similarity of activations
Lean theorems connected to this paper
-
Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We track the cosine similarity between consecutive layer representations hℓ and hℓ+1 ... sim(h(i)ℓ,h(i)ℓ+1) = ... aggregate ... layer-wise similarity profile.
-
Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
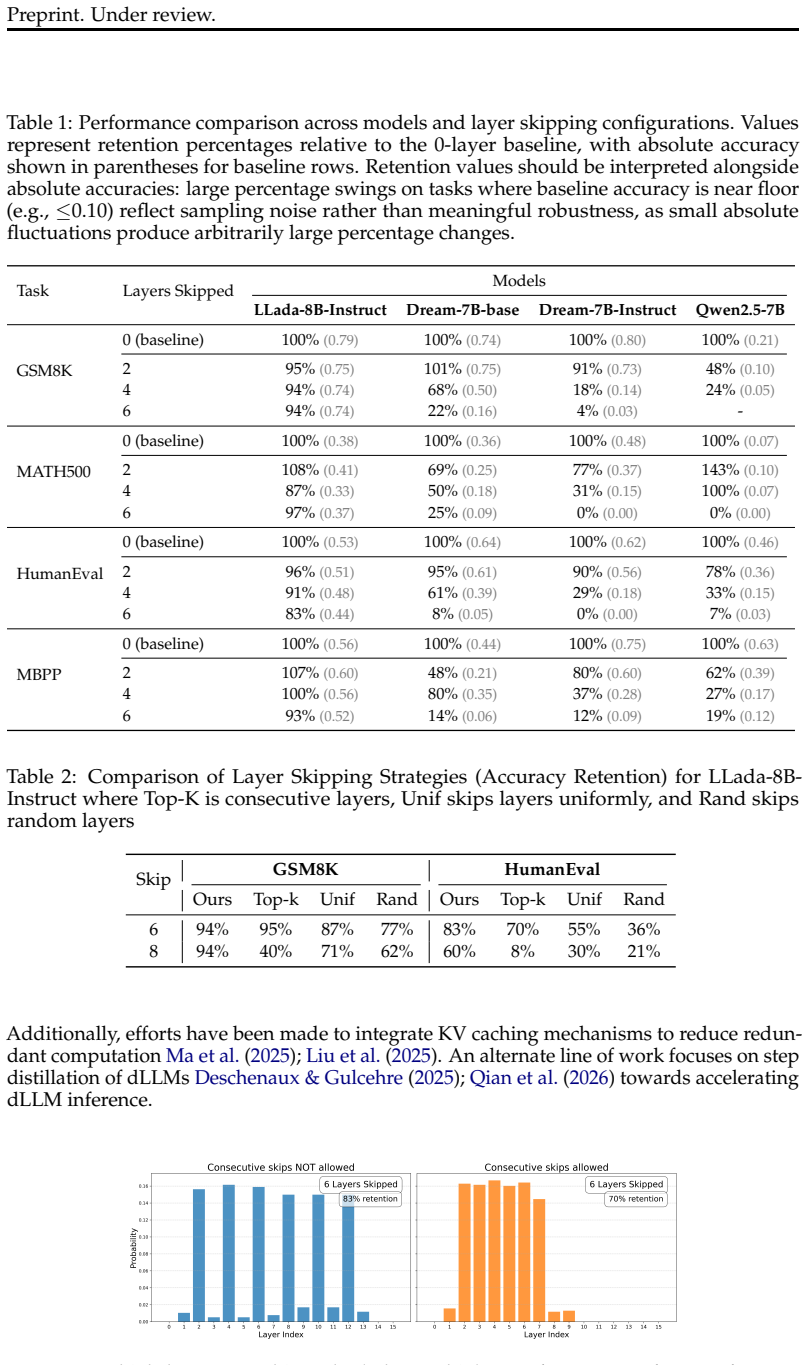
skipping 6 layers (18.75% FLOPs reduction) preserves 93–97% of baseline performance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
Steering Without Breaking: Mechanistically Informed Interventions for Discrete Diffusion Language Models
Adaptive scheduling of interventions in discrete diffusion language models, timed to attribute-specific commitment schedules discovered with sparse autoencoders, delivers precise multi-attribute steering up to 93% str...
-
Continuous Latent Diffusion Language Model
Cola DLM proposes a hierarchical latent diffusion model that learns a text-to-latent mapping, fits a global semantic prior in continuous space with a block-causal DiT, and performs conditional decoding, establishing l...
-
Differences in Text Generated by Diffusion and Autoregressive Language Models
DLMs exhibit lower n-gram entropy, higher semantic coherence, and higher semantic diversity than ARMs, primarily due to bidirectional context and remasking decoding strategies.
Reference graph
Works this paper leans on
-
[1]
Tiwei Bie, Maosong Cao, Kun Chen, Lun Du, Mingliang Gong, Zhuochen Gong, Yanmei Gu, Jiaqi Hu, Zenan Huang, Zhenzhong Lan, et al. Llada2. 0: Scaling up diffusion language models to 100b.arXiv preprint arXiv:2512.15745,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Evaluating Large Language Models Trained on Code
URLhttps://arxiv.org/abs/2107.03374. Introduces HumanEval and Codex. Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Training Verifiers to Solve Math Word Problems
URL https://arxiv.org/abs/2110.14168. Introduces the GSM8K benchmark. Justin Deschenaux and Caglar Gulcehre. Beyond autoregression: Fast LLMs via self- distillation through time. InThe Thirteenth International Conference on Learning Representa- tions,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
URLhttps://arxiv.org/abs/2506.20639. Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset.NeurIPS Datasets and Benchmarks,
-
[5]
Measuring Mathematical Problem Solving With the MATH Dataset
URL https://arxiv.org/abs/2103.03874. We use the 500-problem test subset commonly referred to as “MATH-500”. Ganesh Jawahar, Benoˆıt Sagot, and Djam´e Seddah. What does bert learn about the struc- ture of language? InACL 2019-57th Annual Meeting of the Association for Computational Linguistics,
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[6]
Jiachen Jiang, Jinxin Zhou, and Zhihui Zhu. Tracing representation progression: Analyzing and enhancing layer-wise similarity.arXiv preprint arXiv:2406.14479,
-
[7]
Zhiyuan Liu, Yicun Yang, Yaojie Zhang, Junjie Chen, Chang Zou, Qingyuan Wei, Shaobo Wang, and Linfeng Zhang. dllm-cache: Accelerating diffusion large language models with adaptive caching.arXiv preprint arXiv:2506.06295,
-
[8]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution.arXiv preprint arXiv:2310.16834,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
dkv-cache: The cache for diffusion language models.arXiv preprint arXiv:2505.15781,
Xinyin Ma, Runpeng Yu, Gongfan Fang, and Xinchao Wang. dkv-cache: The cache for diffusion language models.arXiv preprint arXiv:2505.15781,
-
[10]
11 Preprint. Under review. Xin Men, Mingyu Xu, Qingyu Zhang, Qianhao Yuan, Bingning Wang, Hongyu Lin, Yaojie Lu, Xianpei Han, and Weipeng Chen. Shortgpt: Layers in large language models are more redundant than you expect. InFindings of the Association for Computational Linguistics: ACL 2025, pp. 20192–20204,
work page 2025
-
[11]
Large Language Diffusion Models
URL https://arxiv.org/abs/2502.09992. Yu-Yang Qian, Junda Su, Lanxiang Hu, Peiyuan Zhang, Zhijie Deng, Peng Zhao, and Hao Zhang. d3llm: Ultra-fast diffusion llm using pseudo-trajectory distillation.arXiv preprint arXiv:2601.07568,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Attention sinks in diffusion language models.arXiv preprint arXiv:2510.15731,
Maximo Eduardo Rulli, Simone Petruzzi, Edoardo Michielon, Fabrizio Silvestri, Simone Scardapane, and Alessio Devoto. Attention sinks in diffusion language models.arXiv preprint arXiv:2510.15731,
-
[13]
Layer by Layer: Uncovering Hidden Representations in Language Models
Oscar Skean, Md Rifat Arefin, Dan Zhao, Niket Patel, Jalal Naghiyev, Yann LeCun, and Ravid Shwartz-Ziv. Layer by layer: Uncovering hidden representations in language models.arXiv preprint arXiv:2502.02013,
work page internal anchor Pith review arXiv
-
[14]
URLhttps://arxiv.org/abs/2412.15115. Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models, 2025a. URL https://arxiv. org/abs/2508.15487. Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b, 2025b. URLhttps://hku...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.