ChipMATE: Multi-Agent Training via Reinforcement Learning for Enhanced RTL Generation
Pith reviewed 2026-06-30 21:56 UTC · model grok-4.3
The pith
A multi-agent system trains a Verilog agent and a Python reference model agent to mutually verify each other and generate correct RTL code without golden oracles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
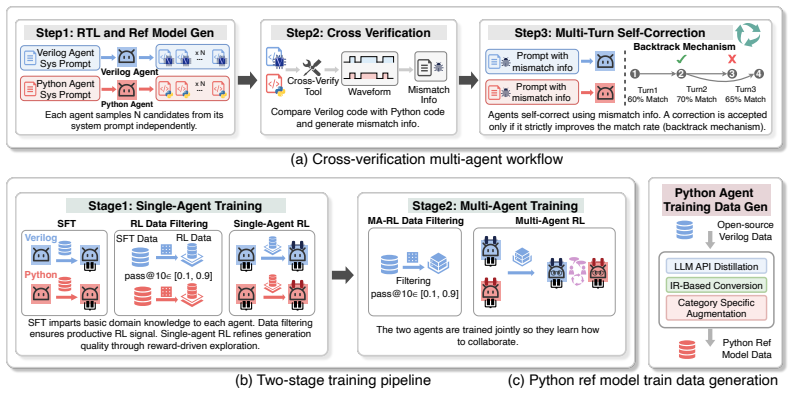
ChipMATE shows that correctness in RTL generation can arise from mutual verification between a Verilog agent and a Python reference-model agent without any golden oracle. The framework pairs the agents in a backtrack-based workflow, builds 64.4K reference model samples through hybrid generation, and applies a two-stage pipeline of individual saturation followed by joint team training to produce effective collaboration.
What carries the argument
Mutual verification between the Verilog agent and the Python reference-model agent, which replaces external testbenches as the source of correctness signals during both training and inference.
If this is right
- RTL generation becomes feasible inside air-gapped environments using only proprietary internal data.
- Verification can be embedded inside the generation loop rather than applied afterward.
- Backtracking during inference prevents error accumulation across multiple agent turns.
- Joint training after individual preparation improves collaboration beyond what separate agents achieve alone.
- Smaller base models reach competitive accuracy on RTL benchmarks through this collaborative training.
Where Pith is reading between the lines
- Similar mutual verification between agents in different representations could apply to other code generation domains that involve cross-language checks.
- The staged training plus backtrack workflow may generalize to other multi-turn agent tasks where early errors compound.
- Embedding cross-verification practices from industry directly into model training loops could improve how AI systems handle real deployment constraints.
Load-bearing premise
Mutual verification between an independently written Verilog module and a Python reference model is sufficient to produce correct RTL without a golden oracle or external testbench.
What would settle it
An independent functional test or simulation that finds Verilog code accepted by the mutual verification process but still incorrect would show the verification method does not guarantee correctness.
Figures


read the original abstract
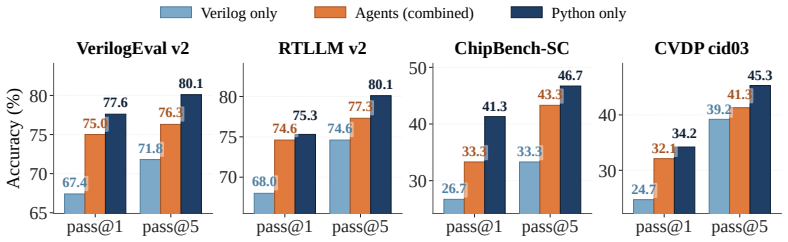
Existing API-based agentic systems for RTL code generation are fundamentally misaligned with industrial practice: they assume a golden testbench is available at generation time, rely on closed-source APIs incompatible with chip vendors' air-gapped security requirements, and cannot be trained on vendors' proprietary RTL codebases, leaving valuable internal data unused. Recent self-trained models address the deployment constraint but remain single-turn generators that overlook the critical role of verification in real industrial flows. To bridge these gaps, we present ChipMATE, the first self-trained multi-agent framework for RTL generation. Inspired by industrial practice where correctness emerges from cross-comparison between independently written RTL modules and reference models, ChipMATE pairs a Verilog agent with a Python reference-model agent that mutually verify each other's outputs without any golden oracle. We design a backtrack-based inference workflow to prevent error propagation across turns, and a two-stage training pipeline that first trains each agent individually to saturate its code-generation capability, then trains the team jointly to collaborate effectively. To support the training, we further build a hybrid data-generation framework that produces 64.4K high-quality reference model training samples. ChipMATE achieves 75.0\% and 80.1\% pass@1 on VerilogEval V2 with 4B and 9B base models, outperforming all existing self-trained models and even DeepSeek V4 with 1600B parameters. Our code and model weights are publicly available in https://github.com/zhongkaiyu/ChipMATE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ChipMATE, a self-trained multi-agent RL framework for RTL generation. A Verilog agent is paired with a Python reference-model agent that mutually verify outputs without a golden oracle or external testbench; a backtrack-based inference workflow prevents error propagation, and a two-stage training pipeline first saturates individual code-generation capability before joint collaboration training. A hybrid data-generation process yields 64.4K reference-model samples. On VerilogEval V2 the method reports 75.0% and 80.1% pass@1 with 4B and 9B base models, outperforming prior self-trained systems and even DeepSeek V4 (1600B parameters). Code and weights are released publicly.
Significance. If the mutual-verification signal proves reliable, the work would be significant for enabling air-gapped, proprietary-data-compatible RTL agents that align with industrial constraints. The public release of code, weights, and the 64.4K-sample dataset is a clear strength supporting reproducibility and further research.
major comments (3)
- [§3] The central performance claims rest on the claim that mutual verification between the Verilog and Python agents supplies a reliable correctness signal without an oracle (abstract and §3). The manuscript provides no experiment or analysis testing robustness when the two agents share correlated misconceptions of the specification (e.g., identical mishandling of an edge case or timing semantics); such a test is load-bearing because agreement could reinforce rather than correct errors.
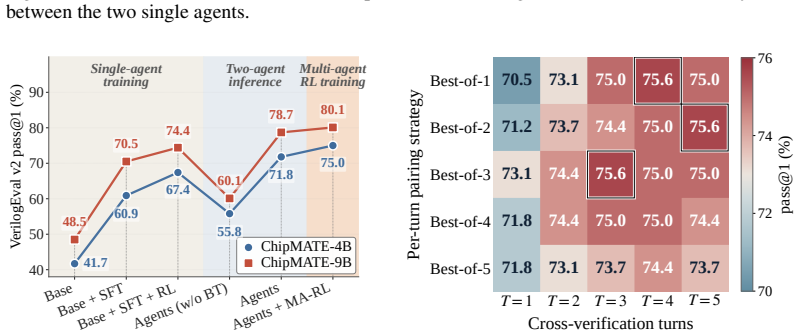
- [§5] §5 (results) and the associated tables report pass@1 figures but supply no ablation isolating the contribution of the backtrack workflow or the joint-training stage versus the individual-training stage alone; without these controls it is impossible to determine whether the two-stage pipeline is responsible for the reported gains over single-turn baselines.
- [§5] The experimental protocol (number of evaluation runs, temperature settings, exact definition of pass@1 on VerilogEval V2, and statistical significance of the 75.0%/80.1% figures versus DeepSeek V4) is not stated with sufficient detail to allow independent verification of the headline numbers.
minor comments (2)
- [§3] Notation for the two agents and the reward formulation in the RL objective should be introduced once with consistent symbols across sections.
- Figure captions should explicitly state the base-model sizes and whether results are averaged over multiple seeds.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of the mutual-verification approach, add necessary ablations, and clarify the experimental protocol.
read point-by-point responses
-
Referee: [§3] The central performance claims rest on the claim that mutual verification between the Verilog and Python agents supplies a reliable correctness signal without an oracle (abstract and §3). The manuscript provides no experiment or analysis testing robustness when the two agents share correlated misconceptions of the specification (e.g., identical mishandling of an edge case or timing semantics); such a test is load-bearing because agreement could reinforce rather than correct errors.
Authors: We agree this is a substantive concern. The two-stage pipeline (individual saturation followed by joint training) and the use of distinct languages (Verilog vs. Python) are intended to reduce error correlation, but we did not explicitly quantify robustness to shared misconceptions. In the revision we will add a dedicated paragraph in §3 analyzing failure modes on VerilogEval V2 where both agents produce identical incorrect outputs, report the frequency of such cases relative to single-agent baselines, and discuss implications for the reliability of the mutual-verification signal. revision: yes
-
Referee: [§5] §5 (results) and the associated tables report pass@1 figures but supply no ablation isolating the contribution of the backtrack workflow or the joint-training stage versus the individual-training stage alone; without these controls it is impossible to determine whether the two-stage pipeline is responsible for the reported gains over single-turn baselines.
Authors: We acknowledge the absence of these controls limits interpretability. We will add an ablation table in §5 reporting pass@1 for (i) individual training only, (ii) joint training without backtrack, and (iii) the full two-stage pipeline with backtrack, using the same 4B and 9B models and evaluation settings. This will isolate the incremental benefit of each component. revision: yes
-
Referee: [§5] The experimental protocol (number of evaluation runs, temperature settings, exact definition of pass@1 on VerilogEval V2, and statistical significance of the 75.0%/80.1% figures versus DeepSeek V4) is not stated with sufficient detail to allow independent verification of the headline numbers.
Authors: We agree the protocol description is insufficient. In the revised §5 we will specify: 5 independent evaluation runs with temperature 0.2 and top-p 0.95; pass@1 defined exactly as in the VerilogEval V2 benchmark (first sample must pass all tests); and a note that the DeepSeek V4 comparison uses the numbers reported in its original paper (no direct re-evaluation performed). We will also report standard deviation across the 5 runs for our results. revision: yes
Circularity Check
No significant circularity; results on external benchmark
full rationale
The paper reports pass@1 metrics on the independent public benchmark VerilogEval V2 rather than on any internally fitted or self-defined quantities. The mutual-verification mechanism is a component of the proposed training/inference workflow, but the correctness signal used for final claims is supplied by the external benchmark's test cases. No equations, self-citations, or parameter-fitting steps are described that would reduce the headline performance numbers to the method's own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mutual verification between independently generated Verilog and Python models can substitute for a golden oracle in RTL correctness checking
invented entities (1)
-
Backtrack-based inference workflow
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Evaluating large language models trained on code, 2021
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harrison Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code, 2021
2021
-
[2]
SiliconMind-V1: Multi-agent distillation and debug-reasoning workflows for Verilog code generation, 2026
Mu-Chi Chen et al. SiliconMind-V1: Multi-agent distillation and debug-reasoning workflows for Verilog code generation, 2026
2026
-
[3]
Teaching large language models to self-debug, 2023
Xinyun Chen, Maxwell Lin, Nathanael Schärli, and Denny Zhou. Teaching large language models to self-debug, 2023
2023
-
[4]
ChipSeek-R1: Generating human-surpassing RTL with LLM via hierarchical reward-driven reinforcement learning, 2025
Zhirong Chen, Ying Wang, et al. ChipSeek-R1: Generating human-surpassing RTL with LLM via hierarchical reward-driven reinforcement learning, 2025
2025
-
[5]
AutoVCoder: A systematic framework for automated Verilog code generation using LLMs, 2024
Mingzhe Gao, Jieru Zhao, Zhe Lin, Wenchao Ding, Xiaofeng Hou, Yu Feng, Chao Li, and Minyi Guo. AutoVCoder: A systematic framework for automated Verilog code generation using LLMs, 2024
2024
-
[6]
DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning, 2025
Daya Guo, Dejian Yang, Haowei Zhang, et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning, 2025
2025
-
[7]
OriGen: Enhancing RTL code generation with code- to-code augmentation and self-reflection
Fan He, Jiahui Zhao, Peiyu Shi, et al. OriGen: Enhancing RTL code generation with code- to-code augmentation and self-reflection. InProceedings of the IEEE/ACM International Conference on Computer-Aided Design (ICCAD), 2024
2024
-
[8]
VerilogCoder: Autonomous Verilog coding agents with graph-based planning and abstract syntax tree (AST)-based waveform tracing tool
Yu-Ching Ho, Mark Haoxing Ren, and Brucek Khailany. VerilogCoder: Autonomous Verilog coding agents with graph-based planning and abstract syntax tree (AST)-based waveform tracing tool. InProceedings of the AAAI Conference on Artificial Intelligence, 2025
2025
-
[9]
MetaGPT: Meta program- ming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. MetaGPT: Meta program- ming for a multi-agent collaborative framework. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[10]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models, 2021. 10
2021
-
[11]
AIvril: AI-driven RTL generation with verification in-the-loop, 2024
Mubashir ul Islam, Humza Sami, and Pierre-Emmanuel Gaillardon. AIvril: AI-driven RTL generation with verification in-the-loop, 2024
2024
-
[12]
CraftRTL: High-quality synthetic data generation for Verilog code models with correct-by-construction non-textual representations and targeted code repair, 2024
Mingjie Liu, Yun-Da Tsai, et al. CraftRTL: High-quality synthetic data generation for Verilog code models with correct-by-construction non-textual representations and targeted code repair, 2024
2024
-
[13]
Shang Liu, Wenji Fang, Yao Lu, Qijun Zhang, Hongce Zhang, and Zhiyao Zhang. RTL- Coder: Fully open-source and efficient LLM-assisted RTL code generation technique.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 44(4):1448–1461, 2025
2025
-
[14]
OpenLLM-RTL: Open dataset and benchmark for LLM-aided design RTL generation
Shang Liu, Yao Lu, Wenji Fang, Mengming Li, and Zhiyao Xie. OpenLLM-RTL: Open dataset and benchmark for LLM-aided design RTL generation. In2024 IEEE/ACM International Conference on Computer Aided Design (ICCAD). IEEE, 2024. Includes RTLLM v2.0 with 50 hand-crafted designs
2024
-
[15]
Multi-agent actor-critic for mixed cooperative-competitive environments
Ryan Lowe, Yi Wu, Aviv Tamar, Jean Harb, Pieter Abbeel, and Igor Mordatch. Multi-agent actor-critic for mixed cooperative-competitive environments. InAdvances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[16]
Self-refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[17]
CoopetitiveV: Leveraging LLM-powered coopetitive multi-agent prompting for high-quality Verilog generation, 2024
Zhendong Mi, Renming Zheng, and Haowen Zhong. CoopetitiveV: Leveraging LLM-powered coopetitive multi-agent prompting for high-quality Verilog generation, 2024
2024
-
[18]
BetterV: Controlled Verilog generation with discriminative guidance
Zehua Pei, Hui-Ling Zhen, Mingxuan Li, Jianye Hao, and Mingzhi Yuan. BetterV: Controlled Verilog generation with discriminative guidance. InProceedings of the International Conference on Machine Learning (ICML), 2024
2024
-
[19]
Nathaniel Pinckney, Christopher Batten, Mingjie Liu, Haoxing Ren, and Brucek Khailany. Revisiting VerilogEval: A year of improvements in large-language models for hardware code generation.arXiv preprint arXiv:2408.11053, 2024
-
[20]
Nathaniel Pinckney, Chenhui Deng, Chia-Tung Ho, Yun-Da Tsai, Mingjie Liu, Wenfei Zhou, Brucek Khailany, and Haoxing Ren. Comprehensive Verilog design problems: A next-generation benchmark dataset for evaluating large language models and agents on RTL design and verifica- tion.arXiv preprint arXiv:2506.14074, 2025
-
[21]
ChatDev: Communicative agents for software development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, et al. ChatDev: Communicative agents for software development. InProceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), 2024
2024
-
[22]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y .K. Li, Y . Wu, et al. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models, 2024
2024
-
[23]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. HybridFlow: A flexible and efficient RLHF framework. arXiv preprint arXiv:2409.19256, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Re- flexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Re- flexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[25]
Pyverilog: A python-based hardware design processing toolkit for Verilog HDL
Shinya Takamaeda-Yamazaki. Pyverilog: A python-based hardware design processing toolkit for Verilog HDL. InInternational Symposium on Applied Reconfigurable Computing (ARC), volume 9040 ofLecture Notes in Computer Science, pages 451–460. Springer, 2015
2015
-
[26]
Qwen3.5: More intelligence, less compute, 2026
Qwen Team. Qwen3.5: More intelligence, less compute, 2026. https://huggingface.co/ Qwen/Qwen3.5-9B. 11
2026
-
[27]
AutoChip: Automating HDL generation using LLM feedback, 2023
Shailja Thakur, Baleegh Ahmad, Zhenxing Fan, Hammond Pearce, Benjamin Tan, Ramesh Karri, Brendan Dolan-Gavitt, and Siddharth Garg. AutoChip: Automating HDL generation using LLM feedback, 2023
2023
-
[28]
VeriReason: Reinforcement learning with testbench feedback for reasoning- enhanced Verilog generation, 2025
Yiting Wang et al. VeriReason: Reinforcement learning with testbench feedback for reasoning- enhanced Verilog generation, 2025
2025
-
[29]
Chain-of-thought prompting elicits reasoning in large language models, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models, 2022
2022
-
[30]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. SWE-agent: Agent-computer interfaces enable automated software engineering. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[31]
Tree of thoughts: Deliberate problem solving with large language models.Ad- vances in neural information processing systems, 36:11809–11822, 2023
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Ad- vances in neural information processing systems, 36:11809–11822, 2023
2023
-
[32]
Zhongkai Yu, Chenyang Zhou, Yichen Lin, Hejia Zhang, Haotian Ye, Junxia Cui, Zaifeng Pan, Jishen Zhao, and Yufei Ding. ChipBench: A next-step benchmark for evaluating LLM performance in AI-aided chip design.arXiv preprint arXiv:2601.21448, 2026
-
[33]
RTLSeek: Boosting the LLM-based RTL generation with multi-stage diversity-oriented reinforcement learning, 2026
Xinyu Zhang et al. RTLSeek: Boosting the LLM-based RTL generation with multi-stage diversity-oriented reinforcement learning, 2026
2026
-
[34]
Stronger-MAS: Multi-agent reinforcement learning for collaborative LLMs, 2025
Yujie Zhao, Lanxiang Hu, Yang Wang, Minmin Hou, Hao Zhang, Ke Ding, and Jishen Zhao. Stronger-MAS: Multi-agent reinforcement learning for collaborative LLMs, 2025
2025
-
[35]
MAGE: A multi-agent engine for automated RTL code generation, 2024
Yujie Zhao, Hejia Zhang, Hanxian Huang, Zhongming Yu, and Jishen Zhao. MAGE: A multi-agent engine for automated RTL code generation, 2024
2024
-
[36]
LlamaFactory: Unified efficient fine-tuning of 100+ language models
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, and Zheyan Luo. LlamaFactory: Unified efficient fine-tuning of 100+ language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), pages 400–410, Bangkok, Thailand, 2024. Association for Computational Linguistics
2024
-
[37]
Yaoyu Zhu, Di Huang, Hanqi Lyu, Xiaoyun Zhang, Chongxiao Li, Wenxuan Shi, Yutong Wu, Jianan Mu, Jinghua Wang, Yang Zhao, Pengwei Jin, Shuyao Cheng, Shengwen Liang, Xishan Zhang, Rui Zhang, Zidong Du, Qi Guo, Xing Hu, and Yunji Chen. QiMeng-CodeV-R1: Reasoning-enhanced Verilog generation.arXiv preprint arXiv:2505.24183, 2025. A Agent Prompt Templates We li...
-
[38]
Stage 1: Compute a + b and c - d, and store the value of d. 13
-
[39]
Stage 2: Compute the sum of the results from Stage 1
-
[40]
a", 0) & 0x3FF b = inputs.get(
Stage 3: Compute the product of the result from Stage 2 and the stored value of d. The ALU should use pipelining to ensure that each stage operates independently, and the final result should be available at the output F. This Python class, named alu_op, has the interface designed in a port table (signal name, direction, width, description) for each of a, ...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.