Recognition: 2 theorem links
· Lean TheoremKamonBench: A Grammar-Based Dataset for Evaluating Compositional Factor Recovery in Vision-Language Models
Pith reviewed 2026-05-14 19:35 UTC · model grok-4.3
The pith
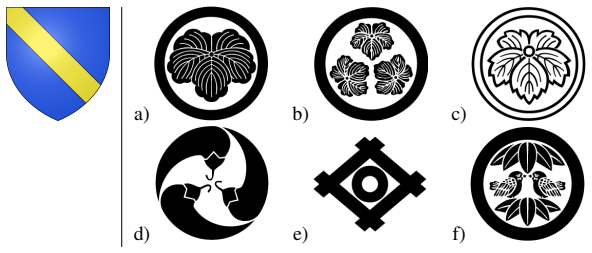
KamonBench supplies 20,000 grammar-generated crest images whose explicit container, modifier, and motif factors let models be scored directly on compositional recovery rather than caption match alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
KamonBench therefore provides a controlled testbed for sparse compositional visual recognition and factor recovery in vision-language models by generating each composite crest from explicit, known factors (container, modifier, motif) and pairing it with multiple aligned representations that support direct factor-level metrics.
What carries the argument
Grammar-based synthetic image generation that produces each crest from known container, modifier, and motif factors together with aligned program-code representations.
Load-bearing premise
The grammar rules and synthetic generation process produce images whose factor structure mirrors the compositional challenges present in natural images and real-world visual recognition tasks.
What would settle it
If models that achieve high factor-recovery scores on KamonBench show no corresponding improvement on natural-image compositional tasks that share the same sparsity and recombination properties, the benchmark would fail to serve as a reliable proxy.
Figures





read the original abstract
Kamon (family crests) are an important part of Japanese culture and a natural test case for compositional visual recognition: each crest combines a small number of symbolic choices, but the space of possible descriptions is sparse. We introduce KamonBench, a grammar-based image-to-structure benchmark with 20,000 synthetic composite crests and auxiliary component examples. Each composite crest is paired with a formal kamon description language - "kamon y\=ogo" - description, a segmented Japanese analysis, an English translation, and a non-linguistic program code. Because each synthetic crest is generated from known factors, namely container, modifier, and motif, KamonBench supports evaluation beyond caption-level accuracy: direct program-code factor metrics, controlled factor-pair recombination splits, counterfactual motif-sensitivity groups under fixed container-modifier contexts, and linear probes of factor accessibility. We include baseline results for a ViT encoder/Transformer decoder and two VGG n-gram decoders, with and without learned positional masks. KamonBench therefore provides a controlled testbed for sparse compositional visual recognition and factor recovery in vision-language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces KamonBench, a grammar-based synthetic dataset of 20,000 kamon crests generated from explicit container/modifier/motif factors. Each image is paired with a formal kamon yōgo description, segmented Japanese analysis, English translation, and program code. The benchmark supports factor recovery evaluation via program-code metrics, recombination splits, counterfactual groups, and linear probes, with baselines from a ViT/Transformer model and VGG n-gram decoders.
Significance. If the synthetic generation process produces factor structures and recognition difficulties comparable to natural kamon, the dataset would supply a valuable controlled testbed for compositional factor recovery in vision-language models, enabling precise evaluation beyond caption accuracy and addressing sparsity challenges in visual recognition.
major comments (2)
- [§3] §3 (Dataset Generation): The central claim that KamonBench provides a controlled testbed mirroring natural compositional challenges (Abstract) rests on the grammar and rendering producing images with equivalent sparsity, ambiguity, occlusion, and co-occurrence statistics to real crests; no quantitative validation (e.g., factor distribution comparisons or human recognition accuracy on real vs. synthetic images) is reported, undermining transferability of the metrics.
- [§4] §4 (Baselines and Metrics): The program-code factor metrics and counterfactual splits are presented without ablations showing they cannot be solved via trivial dataset biases (e.g., frequent factor combinations in the synthetic grammar) rather than true compositional recovery; this is load-bearing for claims of evaluating factor accessibility.
minor comments (1)
- [Abstract] Abstract: The notation 'kamon y=ogo' contains a likely LaTeX rendering error and should be corrected to 'kamon yōgo' for clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important aspects of validating the synthetic dataset's relevance and ensuring the metrics capture true compositional recovery. We address each major comment below, indicating the revisions we will incorporate in the next version of the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Dataset Generation): The central claim that KamonBench provides a controlled testbed mirroring natural compositional challenges (Abstract) rests on the grammar and rendering producing images with equivalent sparsity, ambiguity, occlusion, and co-occurrence statistics to real crests; no quantitative validation (e.g., factor distribution comparisons or human recognition accuracy on real vs. synthetic images) is reported, undermining transferability of the metrics.
Authors: We agree that quantitative validation against real kamon would strengthen claims of mirroring natural challenges. The grammar was constructed from traditional kamon yōgo structures and expert descriptions to reproduce sparsity and factor composition, but direct comparisons were omitted because no large-scale, factor-annotated real kamon dataset exists for statistical matching. In revision we will add a dedicated paragraph in §3 describing the grammar design rationale drawn from kamon literature, report factor-frequency histograms for KamonBench, and include a small curated set of real crest examples with qualitative side-by-side analysis. We will also explicitly list the absence of human recognition accuracy studies as a limitation and suggest it as future work. This provides a partial but substantive response without overstating equivalence. revision: partial
-
Referee: [§4] §4 (Baselines and Metrics): The program-code factor metrics and counterfactual splits are presented without ablations showing they cannot be solved via trivial dataset biases (e.g., frequent factor combinations in the synthetic grammar) rather than true compositional recovery; this is load-bearing for claims of evaluating factor accessibility.
Authors: We concur that ablations are necessary to confirm the metrics evaluate compositional recovery rather than grammar-induced biases. In the revised manuscript we will expand §4 with three new ablation experiments: (1) a random-factor baseline that assigns factors independently of image content, (2) training and evaluation on fully shuffled factor-label pairs within the same splits, and (3) comparison of the VGG n-gram decoder against a version that receives explicit co-occurrence priors. Results will be reported alongside the existing baselines to demonstrate that performance drops substantially under these controls, supporting the claim that the metrics require genuine factor accessibility. revision: yes
Circularity Check
No circularity: dataset construction is transparent and non-reductive
full rationale
The paper's core contribution is the creation of KamonBench, a synthetic dataset generated from an explicit grammar defining container/modifier/motif factors. All evaluation protocols (program-code factor metrics, recombination splits, counterfactual groups) follow directly from this known-factor generation process by design. No derivations, fitted parameters renamed as predictions, or self-citation chains are present; the abstract and full text describe the grammar and rendering as the source of ground truth without reducing claims to prior inputs or external benchmarks. This is standard honest synthetic-data construction with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The grammar rules for combining container, modifier, and motif accurately represent compositional structure in kamon.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
KamonBench therefore provides a controlled testbed for sparse compositional visual recognition and factor recovery in vision-language models.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
each composite crest is generated from known factors, namely container, modifier, and motif
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Understanding intermediate layers using linear classi- fier probes
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classi- fier probes. In5th International Conference on Learning Representations, Workshop Track Proceedings, 2017. URLhttps://openreview.net/forum?id=HJ4-rAVtl
work page 2017
-
[2]
Computational Linguistics , year =
Yonatan Belinkov. Probing classifiers: Promises, shortcomings, and advances.Computational Linguistics, 48(1):207–219, 2022. doi: 10.1162/coli_a_00422. URL https://aclanthology. org/2022.cl-1.7/
work page internal anchor Pith review doi:10.1162/coli_a_00422 2022
-
[3]
Kadokawa Shoten (角川書店), Tokyo, 1993
Shigeru Chikano.Nihon Kamon S ¯okan (日本家紋総鑑). Kadokawa Shoten (角川書店), Tokyo, 1993
work page 1993
-
[4]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR, 2021. URLhttps://arxiv.org/abs/2010.11929
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
John Weatherhill, New York, 1971
John Dower.The Elements of Japanese Design. John Weatherhill, New York, 1971
work page 1971
-
[6]
Dodge Publishing, New York, 1909
Arthur Charles Fox-Davies.A Complete Guide to Heraldry. Dodge Publishing, New York, 1909
work page 1909
-
[7]
Stephen Friar and John Ferguson.Basic Heraldry. Herbert Press, London, 1993
work page 1993
-
[8]
John Hewitt and Christopher D. Manning. A structural probe for finding syntax in word representations. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 4129–4138, Minneapolis, Minnesota, 2019. Association for Computational...
-
[9]
β-V AE: Learning basic visual concepts with a constrained variational framework
Irina Higgins, Loic Matthey, Arka Pal, Christopher Burgess, Xavier Glorot, Matthew Botvinick, Shakir Mohamed, and Alexander Lerchner. β-V AE: Learning basic visual concepts with a constrained variational framework. InInternational Conference on Learning Representations, 2017.https://openreview.net/forum?id=Sy2fzU9gl
work page 2017
-
[10]
Towards a Definition of Disentangled Representations
Irina Higgins, David Amos, David Pfau, Sebastien Racaniere, Loic Matthey, Danilo Rezende, and Alexander Lerchner. Towards a definition of disentangled representations, 2018. URL https://arxiv.org/abs/1812.02230
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Dieuwke Hupkes, Verna Dankers, Mathijs Mul, and Elia Bruni. Compositionality decomposed: How do neural networks generalise?Journal of Artificial Intelligence Research, 67:757– 795, 2020. doi: 10.1613/jair.1.11674. URL https://www.jair.org/index.php/jair/ article/view/11674
-
[12]
Lawrence Zit- nick, and Ross Girshick
Justin Johnson, Bharath Hariharan, Laurens van der Maaten, Li Fei-Fei, C. Lawrence Zit- nick, and Ross Girshick. CLEVR: A diagnostic dataset for compositional language and elementary visual reasoning. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2901–2910, July 2017. URL https://openaccess.thecvf.com/ content_cvpr_2...
work page 2017
-
[13]
Brenden Lake and Marco Baroni. Generalization without systematicity: On the composi- tional skills of sequence-to-sequence recurrent networks. In Jennifer Dy and Andreas Krause (eds.),Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pp. 2873–2882. PMLR, 10–15 Jul 2018. URL https:/...
work page 2018
-
[14]
Challenging common assumptions in the unsupervised learning of disentangled representations
Francesco Locatello, Stefan Bauer, Mario Lucic, Gunnar Raetsch, Sylvain Gelly, Bernhard Schölkopf, and Olivier Bachem. Challenging common assumptions in the unsupervised learning of disentangled representations. In Kamalika Chaudhuri and Ruslan Salakhutdinov (eds.), Proceedings of the 36th International Conference on Machine Learning, volume 97 ofPro- cee...
work page 2019
-
[15]
Disentangling factors of variations using few labels
Francesco Locatello, Michael Tschannen, Stefan Bauer, Gunnar Rätsch, Bernhard Schölkopf, and Olivier Bachem. Disentangling factors of variations using few labels. InInternational Conference on Learning Representations, 2020. URL https://openreview.net/forum? id=SygagpEKwB
work page 2020
-
[16]
Mayank Mishra, Tanupriya Choudhury, and Tanmay Sarkar. CNN based efficient image classification system for smartphone device.Electronic Letters on Computer Vision and Image Analysis, pp. 1–7, 2021
work page 2021
-
[17]
Keiichi Morimoto.Onnamon (女紋). Morimoto Dyeing, Kyoto, 2006
work page 2006
-
[18]
Nihon Jitsugy ¯o Publishers (日本実業出版社), Tokyo, 2013
Y¯uya Morimoto.Nihon no Kamon Daijiten ( 日本の家紋大事典). Nihon Jitsugy ¯o Publishers (日本実業出版社), Tokyo, 2013
work page 2013
-
[19]
Flag Heritage Foundation, Danvers, MA, 2018
David Phillips.Japanese Heraldry and Heraldic Flags. Flag Heritage Foundation, Danvers, MA, 2018
work page 2018
-
[20]
Toward causal representation learning.Proceedings of the IEEE, 109(5):612–634, 2021
Bernhard Schölkopf, Francesco Locatello, Stefan Bauer, Nan Rosemary Ke, Nal Kalchbrenner, Anirudh Goyal, and Yoshua Bengio. Toward causal representation learning.Proceedings of the IEEE, 109(5):612–634, 2021. doi: 10.1109/JPROC.2021.3058954. URL https://doi.org/ 10.1109/JPROC.2021.3058954
-
[21]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition, 2015.https://arxiv.org/abs/1409.1556
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[22]
Stephen Slater.The Complete Book of Heraldry. Lorenz Books, London, 2002
work page 2002
-
[23]
Springer Nature, Cham, Switzerland, 2023
Richard Sproat.Symbols: An Evolutionary History from the Stone Age to the Future. Springer Nature, Cham, Switzerland, 2023
work page 2023
-
[24]
家紋—画像·テキストの新たなチャレンジ (Kamon: Gaz ¯o/tekisuto no aratana charenji)
Richard Sproat. 家紋—画像·テキストの新たなチャレンジ (Kamon: Gaz ¯o/tekisuto no aratana charenji). InANLP, Utsunomiya, March 2026
work page 2026
-
[25]
Hugo Gerard Ströhl.Japanisches Wappenbuch “Nihon Moncho”. Verlag von Anton Schroll, Wien, 1906
work page 1906
-
[26]
Tokyodo Publishers, Tokyo, 2008
Hitoshi Takasawa.Kamon no Jiten (家紋の事典). Tokyodo Publishers, Tokyo, 2008
work page 2008
-
[27]
Tokyodo Publishers, Tokyo, 2021
Hitoshi Takasawa.Kamon Daijiten (家紋大事典). Tokyodo Publishers, Tokyo, 2021. 11 A Appendix A.1 Background and related work KamonBench is designed around three labeled factors of variation per crest: container C, modifier R, and motif M. It provides a suite of factor-aware diagnostics defined in Section 4. This section positions those design choices relative ...
work page 2021
-
[28]
(description 1)2. (description 2)3. (description 3) (etc.) A.8 Few-shot multimodal LLM performance Table 14 shows the 20 sampled synthetic examples used for the Japanese LLM prompt, with VGG and ViT outputs where the sampled image is present in the test predictions, and two large language models, Claude Opus 4.7 Max and GPT 5.4 xhigh. The prompt given to ...
- [29]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.