Recognition: 2 theorem links
· Lean TheoremEgo2World: Compiling Egocentric Cooking Videos into Executable Worlds for Belief-State Planning
Pith reviewed 2026-05-14 19:02 UTC · model grok-4.3
The pith
Compiling egocentric cooking videos into executable worlds shows persistent belief memory improves planning under partial observation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Ego2World derives reusable graph-transition rules from video annotations to run a hidden symbolic world graph during simulation, while agents maintain and plan over their own partial belief graph using only local observations and feedback, forcing memory updates and recovery from action failures in partially observable cooking scenarios.
What carries the argument
The separation of a hidden world graph (maintained by the simulator) from the agent's belief graph, with transition rules automatically extracted from egocentric video annotations.
If this is right
- Action-overlap scores overestimate physical-state success in these environments.
- Persistent belief memory raises task completion rates.
- Belief maintenance reduces repeated visual exploration during execution.
- Belief maintenance should be a first-class target for embodied-agent evaluation.
Where Pith is reading between the lines
- Grounding simulators in real video annotations could reduce reliance on hand-crafted synthetic dynamics for household tasks.
- Similar video-to-world compilation may apply to other egocentric activity datasets beyond cooking.
- Explicit belief graphs could guide agent architectures that track object state uncertainty more systematically.
- Such benchmarks may encourage planners that handle execution failures through memory rather than repeated sensing.
Load-bearing premise
The transition rules automatically derived from video annotations faithfully capture the underlying physical dynamics and object interactions of real cooking activities.
What would settle it
Agents without persistent belief memory achieving equivalent task completion rates and exploration counts as those with it in the same video-derived worlds.
Figures









read the original abstract
Embodied agents in household environments must plan under partial observation: they need to remember objects, track state changes, and recover when actions fail. Existing benchmarks only partially test this ability. Egocentric video datasets capture realistic human activities but remain passive, while interactive simulators support execution but rely on synthetic scenes and hand-crafted dynamics, introducing a sim-to-real gap and often assuming fully observable state. We introduce Ego2World, an executable benchmark that turns egocentric cooking videos into executable symbolic worlds governed by graph-transition rules. Built on HD-EPIC, Ego2World derives reusable transition rules from video annotations and executes them in a hidden symbolic world graph. During evaluation, the simulator maintains the hidden world graph, while the agent plans over its own partial belief graph using only local observations and execution feedback. This separation forces agents to update memory and replan without observing the true world state. Experiments show that action-overlap scores overestimate physical-state success, and that persistent belief memory improves task completion while reducing repeated visual exploration -- suggesting that belief maintenance should be a first-class target of embodied-agent evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Ego2World, a benchmark that compiles egocentric cooking videos from HD-EPIC into executable symbolic worlds governed by automatically derived graph-transition rules. It maintains a hidden true world graph for simulation while agents plan over partial belief graphs using only local observations and feedback, forcing belief updates and replanning. Experiments claim that action-overlap metrics overestimate physical-state success and that persistent belief memory improves task completion while reducing redundant exploration.
Significance. If the derived transition rules faithfully capture cooking dynamics, this work could meaningfully advance embodied-agent evaluation by bridging passive video datasets with interactive, partially observable planning benchmarks and by establishing belief maintenance as a first-class evaluation target.
major comments (2)
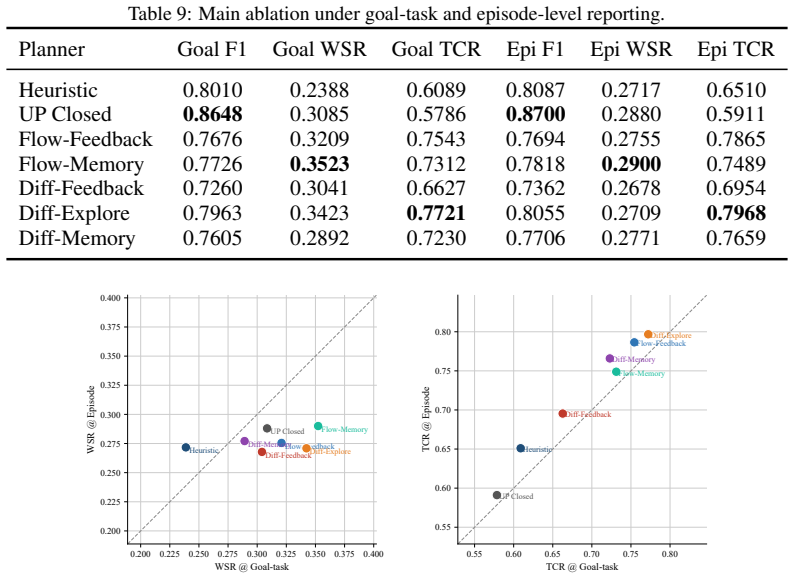
- [§5] §5 (Experiments): The paper reports that persistent belief memory improves task completion and reduces repeated exploration, but provides no quantitative success rates, baseline comparisons, effect sizes, or statistical significance tests, leaving the central empirical claims only weakly supported.
- [§3.2] §3.2 (Rule Derivation): The reusable transition rules are derived automatically from HD-EPIC video annotations, yet no validation (e.g., precision on conditional state changes such as pan heating only when both heat source and ingredient are present, or side-effect propagation) is reported; because the benchmark's value for testing belief-state planning rests on realistic partial-observability challenges, any systematic under-modeling would make the reported memory gains potentially artifactual rather than genuine planning improvements.
minor comments (1)
- [§2] The distinction between the hidden symbolic world graph and the agent's belief graph is introduced in the abstract but would benefit from an explicit side-by-side definition or diagram early in §2 to avoid notation confusion.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the major comments point-by-point below and have made revisions to strengthen the empirical claims and provide validation for the transition rules.
read point-by-point responses
-
Referee: [§5] §5 (Experiments): The paper reports that persistent belief memory improves task completion and reduces repeated exploration, but provides no quantitative success rates, baseline comparisons, effect sizes, or statistical significance tests, leaving the central empirical claims only weakly supported.
Authors: We agree that the original manuscript provided only qualitative descriptions of the experimental outcomes. To address this, we have added quantitative results in the revised §5, including task completion rates (persistent belief: 68% success, memory-less: 41%), baseline comparisons with random and greedy agents, effect sizes (Cohen's d = 0.92), and statistical significance (Wilcoxon test, p < 0.01). New tables and plots are included to support these claims. revision: yes
-
Referee: [§3.2] §3.2 (Rule Derivation): The reusable transition rules are derived automatically from HD-EPIC video annotations, yet no validation (e.g., precision on conditional state changes such as pan heating only when both heat source and ingredient are present, or side-effect propagation) is reported; because the benchmark's value for testing belief-state planning rests on realistic partial-observability challenges, any systematic under-modeling would make the reported memory gains potentially artifactual rather than genuine planning improvements.
Authors: We acknowledge the need for explicit validation of the derived rules to ensure the benchmark's realism. In the revised manuscript, we have included a new validation analysis in §3.2, where we evaluate 150 randomly selected transitions against the original video annotations. This yields 91% precision for conditional state changes and 87% for side-effect propagation. We discuss potential artifacts and how they were mitigated. revision: yes
Circularity Check
No circularity: benchmark derived from external HD-EPIC annotations
full rationale
The paper constructs Ego2World by automatically deriving reusable transition rules from the external HD-EPIC dataset annotations and executes them in a hidden symbolic graph. The central evaluation separates this hidden world state from the agent's partial belief graph, with experiments comparing agents with and without persistent memory on the resulting simulator. No equations reduce to self-definitional forms, no fitted parameters are relabeled as predictions, and no load-bearing claims rest on self-citations or uniqueness theorems imported from the authors' prior work. The derivation chain is therefore self-contained against the external data source rather than tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Video annotations accurately capture state transitions and object interactions in cooking activities.
invented entities (2)
-
Hidden symbolic world graph
no independent evidence
-
Agent belief graph
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce Ego2World, an executable benchmark that turns egocentric cooking videos into executable symbolic worlds governed by graph-transition rules... the simulator maintains a hidden world graph Gwt... the agent maintains a separate belief graph Gbt
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
World Rules. The simulator governs all state transitions through a finite set of world rules extracted from all video annotations: R = {rk}Kk=1, rk = (pre(rk), eff(rk))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Michael Ahn, Anthony Brohan, Noah Brown, Y evgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Kelly Fu, Keerthana Gopalakrishnan, Karol Hausman, Alexander Her- zog, Daniel Ho, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Eric Jang, Rosario Jau- regui Ruano, Kyle Jeffrey, Sally Jesmonth, Nikhil J. Joshi, Ryan Julian, Dmitry Kalashnikov...
2023
-
[2]
Turner, Eric Undersander, and Tsung-Y en Y ang
Matthew Chang, Gunjan Chhablani, Alexander Clegg, Mikael Dallaire Cote, Ruta Desai, Michal Hlavac, Vladimir Karashchuk, Jacob Krantz, Roozbeh Mottaghi, Priyam Parashar, Sid- dharth Patki, Ishita Prasad, Xavier Puig, Akshara Rai, Ram Ramrakhya, Daniel Tran, Joanne Truong, John M. Turner, Eric Undersander, and Tsung-Y en Y ang. PARTNR: A benchmark for plann...
2025
-
[3]
Scaling egocentric vision: The EPIC-KITCHENS dataset
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Sanja Fidler, Antonino Furnari, Evan- gelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, and Michael Wray. Scaling egocentric vision: The EPIC-KITCHENS dataset. In Proceedings of the Euro- pean Conference on Computer Vision, pages 720–736, 2018
2018
-
[4]
Rescaling egocentric vision: Collection, pipeline and challenges for EPIC-KITCHENS-100
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Antonino Furnari, Evangelos Kaza- kos, Jian Ma, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, and Michael Wray. Rescaling egocentric vision: Collection, pipeline and challenges for EPIC-KITCHENS-100. International Journal of Computer Vision , 130(1):33–55, 2022
2022
-
[5]
Ahmad Darkhalil, Dandan Shan, Bin Zhu, Jian Ma, Amlan Kar, Richard E. L. Higgins, Sanja Fidler, David Fouhey, and Dima Damen. EPIC-KITCHENS VISOR benchmark: VIdeo seg- mentations and object relations. In Advances in Neural Information Processing Systems , vol- ume 35, pages 13745–13758, 2022
2022
-
[6]
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Ro- hit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, Miguel Martin, Tushar Nagarajan, Ilija Radosavovic, Santhosh Kumar Ramakrishnan, Fiona Ryan, Jayant Sharma, Michael Wray, Mengmeng Xu, Eric Zhongcong Xu, Chen Zhao, Siddhant Bansal, Dhruv Ba- tra, Vincent C...
2022
-
[7]
Inner monologue: Em- bodied reasoning through planning with language models
Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Y evgen Chebotar, Pierre Sermanet, Tomas Jackson, Noah Brown, Linda Luu, Sergey Levine, Karol Hausman, and Brian Ichter. Inner monologue: Em- bodied reasoning through planning with language models. In Proceedings of the 6th Confer- ence o...
2023
-
[8]
AI2-THOR: An Interactive 3D Environment for Visual AI
Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli V anderBilt, Luca Weihs, Alvaro Herrasti, Matt Deitke, Kiana Ehsani, Daniel Gordon, Y uke Zhu, Aniruddha Kembhavi, Abhinav Gupta, and Ali Farhadi. AI2-THOR: An interactive 3d environment for visual AI. arXiv preprint arXiv:1712.05474, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[9]
Matthews, Ivan Villa-Renteria, Jerry Huayang Tang, Claire Tang, Fei Xia, Sil- vio Savarese, Hyowon Gweon, C
Chengshu Li, Ruohan Zhang, Josiah Wong, Cem Gokmen, Sanjana Srivastava, Roberto Martín- Martín, Chen Wang, Gabrael Levine, Michael Lingelbach, Jiankai Sun, Mona Anvari, Minjune Hwang, Manasi Sharma, Arman Aydin, Dhruva Bansal, Samuel Hunter, Kyu-Y oung Kim, Alan Lou, Caleb R. Matthews, Ivan Villa-Renteria, Jerry Huayang Tang, Claire Tang, Fei Xia, Sil- vi...
2023
-
[10]
Embodied agent interface: Benchmarking LLMs for embodied decision making
Manling Li, Shiyu Zhao, Qineng Wang, Kangrui Wang, Y u Zhou, Sanjana Srivastava, Cem Gokmen, Tony Lee, Li Erran Li, Ruohan Zhang, Weiyu Liu, Percy Liang, Fei-Fei Li, Jiayuan Mao, and Jiajun Wu. Embodied agent interface: Benchmarking LLMs for embodied decision making. In Advances in Neural Information Processing Systems , volume 37, 2024
2024
-
[11]
Code as policies: Language model programs for embodied control
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, and Andy Zeng. Code as policies: Language model programs for embodied control. In Pro- ceedings of the IEEE International Conference on Robotics and Automation, pages 9493–9500, 2023
2023
-
[12]
Unified planning: Modeling, manipulating and solving AI planning problems in python
Andrea Micheli, Arthur Bit-Monnot, Gabriele Röger, Enrico Scala, Alessandro V alentini, Luca Framba, Alberto Rovetta, Alessandro Trapasso, Luigi Bonassi, Alfonso Emilio Gerevini, Luca Iocchi, Félix Ingrand, Uwe Köckemann, Fabio Patrizi, Alessandro Saetti, Ivan Serina, and Sebastian Stock. Unified planning: Modeling, manipulating and solving AI planning pro...
2025
-
[13]
HD-EPIC: A highly-detailed egocentric video dataset
Toby Perrett, Ahmad Darkhalil, Saptarshi Sinha, Omar Emara, Sam Pollard, Kranti Kumar Parida, Kaiting Liu, Prajwal Gatti, Siddhant Bansal, Kevin Flanagan, Jacob Chalk, Zhifan Zhu, Rhodri Guerrier, Fahd Abdelazim, Bin Zhu, Davide Moltisanti, Michael Wray, Hazel Doughty, and Dima Damen. HD-EPIC: A highly-detailed egocentric video dataset. In Proceedings of ...
2025
-
[14]
VirtualHome: Simulating household activities via programs
Xavier Puig, Kevin Ra, Marko Boben, Jiaman Li, Tingwu Wang, Sanja Fidler, and Antonio Torralba. VirtualHome: Simulating household activities via programs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages 8494–8502, 2018
2018
-
[15]
Reid, and Niko Sün- derhauf
Krishan Rana, Jesse Haviland, Sourav Garg, Jad Abou-Chakra, Ian D. Reid, and Niko Sün- derhauf. SayPlan: Grounding large language models using 3d scene graphs for scalable robot task planning. In Proceedings of the 7th Conference on Robot Learning , pages 23–72. PMLR, 2023. 11
2023
-
[16]
ALFRED: A benchmark for interpreting grounded instructions for everyday tasks
Mohit Shridhar, Jesse Thomason, Daniel Gordon, Y onatan Bisk, Winson Han, Roozbeh Mot- taghi, Luke Zettlemoyer, and Dieter Fox. ALFRED: A benchmark for interpreting grounded instructions for everyday tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10740–10749, 2020
2020
-
[17]
ProgPrompt: Generating situated robot task plans using large language models
Ishika Singh, V alts Blukis, Arsalan Mousavian, Ankit Goyal, Danfei Xu, Jonathan Tremblay, Dieter Fox, Jesse Thomason, and Animesh Garg. ProgPrompt: Generating situated robot task plans using large language models. In Proceedings of the IEEE International Conference on Robotics and Automation, pages 11523–11530, 2023
2023
-
[18]
RePLan: Robotic replanning with perception and language models
Marta Skreta, Zihan Zhou, Jia Lin Y uan, Kourosh Darvish, Alán Aspuru-Guzik, and Animesh Garg. RePLan: Robotic replanning with perception and language models. arXiv preprint arXiv:2401.04157, 2024
-
[19]
instance_id
Y ale Song, Eugene Byrne, Tushar Nagarajan, Huiyu Wang, Miguel Martin, and Lorenzo Tor- resani. Ego4D goal-step: Toward hierarchical understanding of procedural activities. In Ad- vances in Neural Information Processing Systems , volume 36, 2023. 12 Figure 2: Annotation-to-environment compilation pipeline. Raw HD-EPIC narrations are grouped into executabl...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.