Recognition: 2 theorem links
· Lean TheoremR2R2: Robust Representation for Intensive Experience Reuse via Redundancy Reduction in Self-Predictive Learning
Pith reviewed 2026-05-15 05:36 UTC · model grok-4.3
The pith
A non-centered objective in self-predictive learning resolves zero-centering conflicts to stabilize representations under intensive experience reuse.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
R2R2 identifies a conflict between standard zero-centering and the spectral properties of self-predictive learning, then replaces it with a non-centered objective that reduces representation redundancy and thereby mitigates overfitting during high-ratio experience reuse.
What carries the argument
Non-centered regularization objective within self-predictive learning that aligns with spectral properties to reduce redundancy in representations.
Load-bearing premise
The conflict between zero-centering and SPL spectral properties is the primary driver of representation instability, and the non-centered objective is what produces the observed performance gains.
What would settle it
An experiment that changes only the centering term in the SPL objective and measures no improvement in performance or stability at UTD ratio 20 would falsify the central claim.
Figures









read the original abstract
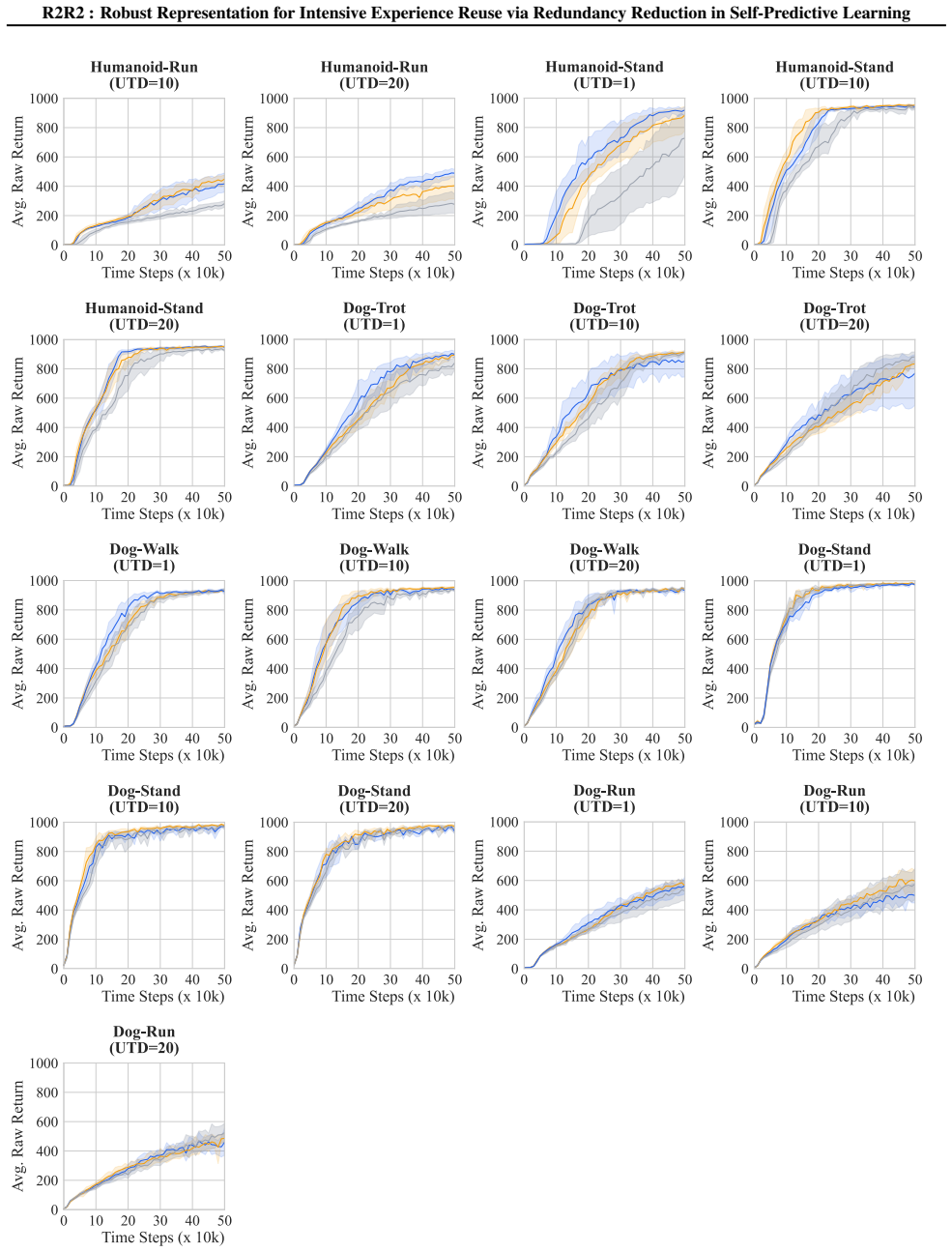
For reinforcement learning in data-scarce domains like real-world robotics, intensive data reuse enhances efficiency but induces overfitting. While prior works focus on critic bias, representation-level instability in Self-Predictive Learning (SPL) under high Update-to-Data (UTD) regimes remains underexplored. To bridge this gap, we propose Robust Representation via Redundancy Reduction (R2R2), a regularization method within SPL. We theoretically identify that standard zero-centering conflicts with SPL's spectral properties and design a non-centered objective accordingly. We verify R2R2 on SPL-native algorithms like TD7. Furthermore, to demonstrate its orthogonality to prior advancements, we extend the state-of-the-art SimbaV2, which originally lacks SPL, by integrating a tailored SPL module, termed SimbaV2-SPL. Experiments across 11 continuous control tasks confirm that R2R2 effectively mitigates overfitting; specifically, at a UTD ratio of 20, it improves TD7 by ~22% and provides additional gains on top of SimbaV2-SPL, which itself establishes a new state-of-the-art. The code can be found at: https://github.com/songsang7/R2R2
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to identify a conflict between standard zero-centering and SPL spectral properties, introduces R2R2 as a non-centered regularization within Self-Predictive Learning to mitigate representation instability under high Update-to-Data ratios, and reports empirical gains including ~22% improvement on TD7 at UTD=20 plus additional benefits when extending SimbaV2 to SimbaV2-SPL, establishing a new state-of-the-art across 11 continuous control tasks.
Significance. If the performance gains can be causally attributed to the non-centered objective through controlled experiments, this would represent a targeted and practical advance in representation learning for data-scarce RL settings such as robotics, where intensive experience reuse is essential. The claimed orthogonality to prior methods like SimbaV2 and the public code release are positive factors for adoption and verification.
major comments (2)
- Abstract: The theoretical identification of the zero-centering/SPL spectral conflict is asserted without derivation steps or supporting equations, leaving the motivation for the non-centered objective difficult to evaluate independently.
- Experiments section: No ablations are presented that toggle only the centering term while holding fixed all other factors (network architecture, optimizer, replay buffer sampling, etc.), so the ~22% TD7 lift at UTD=20 cannot yet be attributed specifically to R2R2 rather than other implementation choices.
minor comments (1)
- The notation for the R2R2 objective could be presented more explicitly with a dedicated equation block to clarify the redundancy-reduction term.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to improve clarity on the theoretical motivation and to strengthen causal attribution of the reported gains.
read point-by-point responses
-
Referee: Abstract: The theoretical identification of the zero-centering/SPL spectral conflict is asserted without derivation steps or supporting equations, leaving the motivation for the non-centered objective difficult to evaluate independently.
Authors: We agree the abstract states the conflict without inline derivation. Section 3.1 of the manuscript contains the spectral analysis (showing that zero-centering forces negative eigenvalues incompatible with the positive semi-definite requirement of the SPL loss), but the steps are not summarized in the abstract. In revision we will insert a concise derivation sketch and the key equations into the abstract or a new paragraph in the introduction, with a pointer to the full proof in Section 3. revision: yes
-
Referee: Experiments section: No ablations are presented that toggle only the centering term while holding fixed all other factors (network architecture, optimizer, replay buffer sampling, etc.), so the ~22% TD7 lift at UTD=20 cannot yet be attributed specifically to R2R2 rather than other implementation choices.
Authors: We acknowledge that the current results compare complete R2R2-augmented agents against baselines without an isolated centering ablation. In the revised version we will add a controlled experiment on TD7 at UTD=20 that differs solely in the centering term (standard zero-centering vs. the non-centered R2R2 objective), with all other factors (architecture, optimizer, replay buffer, and sampling) held fixed. This will directly quantify the contribution of the non-centered regularization. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper derives the non-centered objective from a theoretical identification of conflict between zero-centering and SPL spectral properties, presented as an independent analysis within the SPL framework. No steps reduce by construction to fitted parameters, self-citations, or prior ansatzes by the authors. Empirical gains on TD7 and SimbaV2-SPL are reported as verification results, not as inputs to the derivation. The chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard zero-centering conflicts with SPL's spectral properties
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
zero-centering operation H eliminates the projection of Φ* onto the constant vector u1 (corresponding to the dominant mode), i.e., ∥HΦ*_proj,u1∥2 = 0
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
non-centered inner product form ... LRR = 1/d(d-1) Σ i≠j ([C(Z)]ij)^2 where [C(Z)]ij = 1/(N-1) Σ zb,i zb,j
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Timothy P. Lillicrap and Jonathan J. Hunt and Alexander Pritzel and Nicolas Heess and Tom Erez and Yuval Tassa and David Silver and Daan Wierstra , editor =. Continuous control with deep reinforcement learning , booktitle =. 2016 , url =
work page 2016
-
[2]
9th International Conference on Learning Representations,
Denis Yarats and Ilya Kostrikov and Rob Fergus , title =. 9th International Conference on Learning Representations,. 2021 , url =
work page 2021
-
[3]
Tuomas Haarnoja and Aurick Zhou and Pieter Abbeel and Sergey Levine , editor =. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor , booktitle =. 2018 , url =
work page 2018
-
[4]
Soft Actor-Critic Algorithms and Applications
Tuomas Haarnoja and Aurick Zhou and Kristian Hartikainen and George Tucker and Sehoon Ha and Jie Tan and Vikash Kumar and Henry Zhu and Abhishek Gupta and Pieter Abbeel and Sergey Levine , title =. CoRR , volume =. 2018 , url =. 1812.05905 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
Forty-second International Conference on Machine Learning,
Hojoon Lee and Youngdo Lee and Takuma Seno and Donghu Kim and Peter Stone and Jaegul Choo , title =. Forty-second International Conference on Machine Learning,. 2025 , url =
work page 2025
- [6]
-
[7]
Max Schwarzer and Ankesh Anand and Rishab Goel and R. Devon Hjelm and Aaron C. Courville and Philip Bachman , title =. 9th International Conference on Learning Representations,. 2021 , url =
work page 2021
-
[8]
Jha and Toshisada Mariyama and Daniel Nikovski , title =
Kei Ota and Tomoaki Oiki and Devesh K. Jha and Toshisada Mariyama and Daniel Nikovski , title =. Proceedings of the 37th International Conference on Machine Learning,. 2020 , url =
work page 2020
-
[9]
Addressing Function Approximation Error in Actor-Critic Methods , booktitle =
Scott Fujimoto and Herke van Hoof and David Meger , editor =. Addressing Function Approximation Error in Actor-Critic Methods , booktitle =. 2018 , url =
work page 2018
-
[10]
Scott Fujimoto and Wei. For. Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023 , year =
work page 2023
-
[11]
Bridging State and History Representations: Understanding Self-Predictive
Tianwei Ni and Benjamin Eysenbach and Erfan Seyedsalehi and Michel Ma and Clement Gehring and Aditya Mahajan and Pierre. Bridging State and History Representations: Understanding Self-Predictive. The Twelfth International Conference on Learning Representations,. 2024 , url =
work page 2024
-
[12]
Xinlei Chen and Kaiming He , title =. 2021 , url =. doi:10.1109/CVPR46437.2021.01549 , timestamp =
-
[13]
Jean. Bootstrap Your Own Latent -. Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual , year =
work page 2020
-
[14]
The Tenth International Conference on Learning Representations,
Adrien Bardes and Jean Ponce and Yann LeCun , title =. The Tenth International Conference on Learning Representations,. 2022 , url =
work page 2022
-
[15]
Understanding Self-Predictive Learning for Reinforcement Learning , booktitle =
Yunhao Tang and Zhaohan Daniel Guo and Pierre Harvey Richemond and Bernardo. Understanding Self-Predictive Learning for Reinforcement Learning , booktitle =. 2023 , url =
work page 2023
-
[16]
Volodymyr Mnih and Koray Kavukcuoglu and David Silver and Andrei A. Rusu and Joel Veness and Marc G. Bellemare and Alex Graves and Martin A. Riedmiller and Andreas Fidjeland and Georg Ostrovski and Stig Petersen and Charles Beattie and Amir Sadik and Ioannis Antonoglou and Helen King and Dharshan Kumaran and Daan Wierstra and Shane Legg and Demis Hassabis...
-
[17]
When to Trust Your Model: Model-Based Policy Optimization , booktitle =
Michael Janner and Justin Fu and Marvin Zhang and Sergey Levine , editor =. When to Trust Your Model: Model-Based Policy Optimization , booktitle =. 2019 , url =
work page 2019
-
[18]
Richard S. Sutton , editor =. Integrated Architectures for Learning, Planning, and Reacting Based on Approximating Dynamic Programming , booktitle =. 1990 , url =. doi:10.1016/B978-1-55860-141-3.50030-4 , timestamp =
-
[19]
Recurrent World Models Facilitate Policy Evolution , booktitle =
David Ha and J. Recurrent World Models Facilitate Policy Evolution , booktitle =. 2018 , url =
work page 2018
-
[20]
Xinyue Chen and Che Wang and Zijian Zhou and Keith W. Ross , title =. 9th International Conference on Learning Representations,. 2021 , url =
work page 2021
-
[21]
The Twelfth International Conference on Learning Representations,
Aditya Bhatt and Daniel Palenicek and Boris Belousov and Max Argus and Artemij Amiranashvili and Thomas Brox and Jan Peters , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
work page 2024
-
[22]
Wurman and Jaegul Choo and Peter Stone and Takuma Seno , title =
Hojoon Lee and Dongyoon Hwang and Donghu Kim and Hyunseung Kim and Jun Jet Tai and Kaushik Subramanian and Peter R. Wurman and Jaegul Choo and Peter Stone and Takuma Seno , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
work page 2025
-
[23]
Proceedings of the 38th International Conference on Machine Learning,
Jure Zbontar and Li Jing and Ishan Misra and Yann LeCun and St. Proceedings of the 38th International Conference on Machine Learning,. 2021 , url =
work page 2021
-
[24]
Sensory communication , volume=
Possible principles underlying the transformation of sensory messages , author=. Sensory communication , volume=. 1961 , publisher=
work page 1961
-
[25]
Emanuel Todorov and Tom Erez and Yuval Tassa , title =. 2012. 2012 , url =. doi:10.1109/IROS.2012.6386109 , timestamp =
-
[26]
Greg Brockman and Vicki Cheung and Ludwig Pettersson and Jonas Schneider and John Schulman and Jie Tang and Wojciech Zaremba , title =. CoRR , volume =. 2016 , url =. 1606.01540 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[27]
Yuval Tassa and Yotam Doron and Alistair Muldal and Tom Erez and Yazhe Li and Diego de Las Casas and David Budden and Abbas Abdolmaleki and Josh Merel and Andrew Lefrancq and Timothy P. Lillicrap and Martin A. Riedmiller , title =. CoRR , volume =. 2018 , url =. 1801.00690 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[28]
Ting Chen and Simon Kornblith and Mohammad Norouzi and Geoffrey E. Hinton , title =. Proceedings of the 37th International Conference on Machine Learning,. 2020 , url =
work page 2020
-
[29]
Marlos C. Machado and Marc G. Bellemare and Erik Talvitie and Joel Veness and Matthew J. Hausknecht and Michael Bowling , editor =. Revisiting the Arcade Learning Environment: Evaluation Protocols and Open Problems for General Agents (Extended Abstract) , booktitle =. 2018 , url =. doi:10.24963/IJCAI.2018/787 , timestamp =
-
[30]
Proceedings of the 37th International Conference on Machine Learning,
Michael Laskin and Aravind Srinivas and Pieter Abbeel , title =. Proceedings of the 37th International Conference on Machine Learning,. 2020 , url =
work page 2020
-
[31]
Leibo and David Silver and Koray Kavukcuoglu , title =
Max Jaderberg and Volodymyr Mnih and Wojciech Marian Czarnecki and Tom Schaul and Joel Z. Leibo and David Silver and Koray Kavukcuoglu , title =. 5th International Conference on Learning Representations,. 2017 , url =
work page 2017
-
[32]
Denis Yarats and Amy Zhang and Ilya Kostrikov and Brandon Amos and Joelle Pineau and Rob Fergus , title =. Thirty-Fifth. 2021 , url =. doi:10.1609/AAAI.V35I12.17276 , timestamp =
-
[33]
Representation Learning with Contrastive Predictive Coding
A. Representation Learning with Contrastive Predictive Coding , journal =. 2018 , url =. 1807.03748 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[34]
Lei Jimmy Ba and Jamie Ryan Kiros and Geoffrey E. Hinton , title =. CoRR , volume =. 2016 , url =. 1607.06450 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[35]
The Thirteenth International Conference on Learning Representations,
Claas Voelcker and Marcel Hussing and Eric Eaton and Amir. The Thirteenth International Conference on Learning Representations,. 2025 , url =
work page 2025
-
[36]
Michal Nauman and Mateusz Ostaszewski and Krzysztof Jankowski and Piotr Milos and Marek Cygan , editor =. Bigger, Regularized, Optimistic: scaling for compute and sample efficient continuous control , booktitle =. 2024 , url =
work page 2024
-
[37]
Hinton and Alex Krizhevsky and Ilya Sutskever and Ruslan Salakhutdinov , title =
Nitish Srivastava and Geoffrey E. Hinton and Alex Krizhevsky and Ilya Sutskever and Ruslan Salakhutdinov , title =. J. Mach. Learn. Res. , volume =. 2014 , url =. doi:10.5555/2627435.2670313 , timestamp =
-
[38]
Sergey Ioffe and Christian Szegedy , editor =. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift , booktitle =. 2015 , url =
work page 2015
-
[39]
Adam Paszke and Sam Gross and Francisco Massa and Adam Lerer and James Bradbury and Gregory Chanan and Trevor Killeen and Zeming Lin and Natalia Gimelshein and Luca Antiga and Alban Desmaison and Andreas K. Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 20...
work page 2019
-
[40]
James Bradbury and Roy Frostig and Peter Hawkins and Matthew James Johnson and Chris Leary and Dougal Maclaurin and George Necula and Adam Paszke and Jake Vander
-
[41]
Lillicrap and Nicolas Heess , title =
Yuval Tassa and Saran Tunyasuvunakool and Alistair Muldal and Yotam Doron and Siqi Liu and Steven Bohez and Josh Merel and Tom Erez and Timothy P. Lillicrap and Nicolas Heess , title =. CoRR , volume =. 2020 , url =. 2006.12983 , timestamp =
-
[42]
Rishabh Agarwal and Max Schwarzer and Pablo Samuel Castro and Aaron C. Courville and Marc G. Bellemare , editor =. Deep Reinforcement Learning at the Edge of the Statistical Precipice , booktitle =. 2021 , url =
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.