Herculean: An Agentic Benchmark for Financial Intelligence
Pith reviewed 2026-06-30 21:04 UTC · model grok-4.3
The pith
Frontier AI agents handle trading and market insights but struggle with hedging and auditing due to needs for long-horizon coordination.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
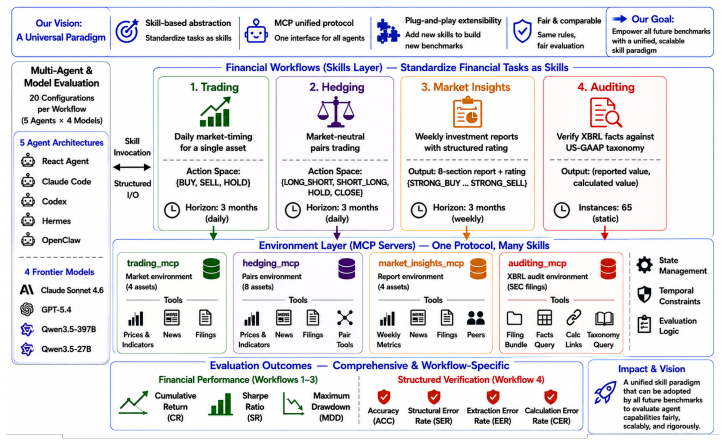
Herculean is introduced as the first skilled benchmark for agentic financial intelligence, instantiated through four MCP-based skill environments for Trading, Hedging, Market Insights, and Auditing. Each environment supplies its own tools, interaction dynamics, constraints, and success criteria to support consistent end-to-end evaluation of heterogeneous agent systems. Across tested frontier agents, performance is relatively strong on Trading and Market Insights but substantially weaker on Hedging and Auditing, where long-horizon coordination, state consistency, and structured verification prove critical. The results indicate a persistent gap in converting financial reasoning into dependable
What carries the argument
Herculean benchmark consisting of four MCP-based skill environments, each equipped with workflow-specific tools, interaction rules, constraints, and measurable success criteria.
If this is right
- Current frontier agents remain limited in tasks that require maintaining consistent state and verification over multiple steps.
- Workflow execution benchmarks should prioritize long-horizon coordination rather than isolated static competencies.
- Agent development should target improvements in structured verification mechanisms for auditing-style workflows.
- Trading and market insight tasks may be closer to deployment readiness than hedging or auditing tasks.
Where Pith is reading between the lines
- The identified gaps could inform the design of hybrid human-AI systems for high-stakes financial compliance roles.
- Extending the benchmark to incorporate live market feeds might expose additional coordination failures not visible in static setups.
- Success on this benchmark could serve as a proxy for readiness in other regulated professional domains requiring sequential decision-making.
Load-bearing premise
The four MCP-based skill environments accurately capture the interaction dynamics, constraints, and success criteria of real financial professional work.
What would settle it
A direct comparison showing that agents scoring low on Hedging or Auditing within the Herculean environments perform at similar levels when applied to equivalent real-world financial hedging or auditing assignments outside the benchmark.
Figures
read the original abstract
As AI agents improve, the central question is no longer whether they can solve isolated well-defined financial tasks, but whether they can reliably carry out financial professional work. Existing financial benchmarks offer only a partial view of this ability, as they primarily evaluate static competencies such as question answering, retrieval, summarization, and classification. We introduce Herculean, the first skilled benchmark for agentic financial intelligence spanning four representative workflows, including Trading, Hedging, Market Insights, and Auditing. Each workflow is instantiated as a standardized MCP-based skill environment with its own tools, interaction dynamics, constraints, and success criteria, enabling consistent end-to-end assessment of heterogeneous agent systems. Across frontier agents, we find agents perform relatively well on Trading and Market Insights, but struggle substantially on Hedging and Auditing, where long-horizon coordination, state consistency, and structured verification are critical. Overall, our results point to a key gap in current agents in turning financial reasoning into dependable workflow execution in high-stakes financial workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Herculean as the first agentic benchmark for financial intelligence, consisting of four standardized MCP-based skill environments (Trading, Hedging, Market Insights, Auditing) each with defined tools, interaction dynamics, constraints, and success criteria. Frontier agents are evaluated end-to-end, with results showing relatively strong performance on Trading and Market Insights but substantial struggles on Hedging and Auditing, attributed to requirements for long-horizon coordination, state consistency, and structured verification. The work concludes that current agents exhibit a gap in converting financial reasoning into dependable high-stakes workflow execution.
Significance. If the environments faithfully represent professional financial workflows, the benchmark provides a useful standardized framework for assessing agent reliability beyond static QA tasks, and the performance gap could usefully direct research toward better long-horizon and verification capabilities in financial agents.
major comments (2)
- [Abstract; §3 (Environment Construction)] The central empirical claim (stronger performance on Trading/Market Insights vs. struggles on Hedging/Auditing) is load-bearing on the fidelity of the four MCP environments. The manuscript provides no evidence of how tools, state transitions, or success metrics were derived from real financial workflows, nor any validation (expert review, comparison to production systems, or sensitivity analysis).
- [§4 (Results)] §4 (Results) and the discussion of long-horizon coordination/state consistency as the cause of poor Hedging/Auditing performance assumes the benchmark's success criteria match regulatory/market realities; without grounding data this risks the gap being an artifact of the proxy definitions rather than a demonstrated agent limitation.
minor comments (2)
- Define MCP on first use and clarify whether the environments are open-sourced with reproducible code.
- Add a limitations section explicitly discussing the scope of the four workflows relative to the full range of financial professional tasks.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. We appreciate the acknowledgment of the benchmark's potential value and agree that stronger documentation of environment fidelity is needed to support the central claims. Below we respond point-by-point to the major comments and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract; §3 (Environment Construction)] The central empirical claim (stronger performance on Trading/Market Insights vs. struggles on Hedging/Auditing) is load-bearing on the fidelity of the four MCP environments. The manuscript provides no evidence of how tools, state transitions, or success metrics were derived from real financial workflows, nor any validation (expert review, comparison to production systems, or sensitivity analysis).
Authors: We acknowledge this is a valid concern and that the current manuscript lacks explicit traceability for environment construction. In the revised version we will add a new subsection to §3 that maps each workflow's tools, state transitions, constraints, and success criteria to publicly documented financial practices drawn from regulatory sources (e.g., SEC Rule 15c3-1, Basel III operational risk guidelines) and standard references in financial engineering literature. We will also include a high-level sensitivity discussion and note the absence of formal expert review or production-system comparison as a limitation. These additions will make the derivation process transparent without overstating the current grounding. revision: yes
-
Referee: [§4 (Results)] §4 (Results) and the discussion of long-horizon coordination/state consistency as the cause of poor Hedging/Auditing performance assumes the benchmark's success criteria match regulatory/market realities; without grounding data this risks the gap being an artifact of the proxy definitions rather than a demonstrated agent limitation.
Authors: We agree that the interpretation of the performance gap rests on the assumption that the success criteria reflect meaningful real-world requirements. In the revision we will expand the §4 discussion and add an appendix that explicitly links the Hedging and Auditing criteria (state consistency, multi-step verification) to documented professional standards. We will also qualify the claims by noting that the observed gap demonstrates limitations under these proxy definitions and that further validation against live workflows would be valuable. This addresses the risk of artifact while preserving the core observation that current agents struggle with long-horizon coordination tasks. revision: yes
Circularity Check
No circularity: empirical benchmark with no derivations or fitted predictions
full rationale
The paper presents a new benchmark (Herculean) consisting of four MCP-based skill environments and reports empirical agent performance across workflows. No equations, derivations, parameter fitting, or first-principles predictions appear in the text. The observed performance gaps (stronger on Trading/Market Insights, weaker on Hedging/Auditing) are direct measurements on the constructed environments rather than quantities derived from or equivalent to the inputs by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked. The work is self-contained as an empirical benchmark introduction.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 3 Pith papers
-
Can LLMs Be CEOs? Benchmarking Strategic Resource Reallocation with Multi-Role Agent Simulation
CEO-Bench evaluates LLMs on CEO-level strategic resource reallocation via multi-role agent simulations, showing high structural validity but sharp divergence on strategic calibration across five frontier models on 13 ...
-
AuditFraudBench: Benchmarking Audit Judgment in Detecting Fraudulent Misstatements
AuditFraudBench is a new enforcement-grounded benchmark with three tasks for testing whether LLMs can detect fraudulent misstatements by reasoning over financial figures, disclosure framing, and known manipulation patterns.
-
AUDITFLOW: Executable Symbolic Environments for Structured Financial Reporting Verification
AuditFlow combines a graph-grounded symbolic environment with a multi-agent LLM setup to reach 82.09% joint audit accuracy on structured financial reports, 14.93 points above the strongest baseline.
Reference graph
Works this paper leans on
-
[1]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Toolformer: language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessí, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: language models can teach themselves to use tools. InProceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY , USA, 2023. Curran Associates Inc
2023
-
[3]
Princeton University Press, 2017
Andrew Lo.Adaptive markets: Financial evolution at the speed of thought. Princeton University Press, 2017
2017
-
[4]
Xueqing Peng, Lingfei Qian, Yan Wang, Ruoyu Xiang, Yueru He, Yang Ren, Mingyang Jiang, Vincent Jim Zhang, Yuqing Guo, Jeff Zhao, Huan He, Yi Han, Yun Feng, Yuechen Jiang, Yupeng Cao, Haohang Li, Yangyang Yu, Xiaoyu Wang, Penglei Gao, Shengyuan Lin, Keyi Wang, Shanshan Yang, Yilun Zhao, Zhiwei Liu, Peng Lu, Jerry Huang, Suyuchen Wang, Triantafillos Papadop...
-
[5]
FinAuditing: A Financial Taxonomy-Structured Multi-Document Benchmark for Evaluating LLMs
Yan Wang, Keyi Wang, Shanshan Yang, Jaisal Patel, Jeff Zhao, Fengran Mo, Xueqing Peng, Lingfei Qian, Jimin Huang, Guojun Xiong, Yankai Chen, Víctor Gutiérrez-Basulto, Xiao-Yang Liu, Xue Liu, and Jian-Yun Nie. Finauditing: A financial taxonomy-structured multi-document benchmark for evaluating llms, 2026. URLhttps://arxiv.org/abs/2510.08886
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Pixiu: A comprehensive benchmark, instruction dataset and large language model for finance.Advances in Neural Information Processing Systems, 36:33469–33484, 2023
Qianqian Xie, Weiguang Han, Xiao Zhang, Yanzhao Lai, Min Peng, Alejandro Lopez-Lira, and Jimin Huang. Pixiu: A comprehensive benchmark, instruction dataset and large language model for finance.Advances in Neural Information Processing Systems, 36:33469–33484, 2023
2023
-
[7]
Finben: A holistic finan- cial benchmark for large language models
Qianqian Xie, Weiguang Han, Zhengyu Chen, Ruoyu Xiang, Xiao Zhang, Yueru He, Mengxi Xiao, Dong Li, Yongfu Dai, Duanyu Feng, Yijing Xu, Haoqiang Kang, Ziyan Kuang, Chenhan Yuan, Kailai Yang, Zheheng Luo, Tianlin Zhang, Zhiwei Liu, Guojun Xiong, Zhiyang Deng, Yuechen Jiang, Zhiyuan Yao, Haohang Li, Yangyang Yu, Gang Hu, Jiajia Huang, Xiao-Yang Liu, Alejandr...
-
[8]
Investorbench: A benchmark for financial decision-making tasks with llm-based agent
Haohang Li, Yupeng Cao, Yangyang Yu, Shashidhar Reddy Javaji, Zhiyang Deng, Yueru He, Yuechen Jiang, Zining Zhu, Kp Subbalakshmi, Jimin Huang, et al. Investorbench: A benchmark for financial decision-making tasks with llm-based agent. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2...
2025
-
[9]
When agents trade: Live multi-market trading benchmark for llm agents, 2025
Lingfei Qian, Xueqing Peng, Yan Wang, Vincent Jim Zhang, Huan He, Hanley Smith, Yi Han, Yueru He, Haohang Li, Yupeng Cao, Yangyang Yu, Alejandro Lopez-Lira, Peng Lu, Jian-Yun Nie, Guojun Xiong, Jimin Huang, and Sophia Ananiadou. When agents trade: Live multi-market trading benchmark for llm agents, 2025. URLhttps://arxiv.org/abs/2510.11695
-
[10]
Moira: Language-driven Hierarchical Reinforcement Learning for Pair Trading
Polydoros Giannouris, Yuechen Jiang, Lingfei Qian, Yuyan Wang, Xueqing Peng, Jimin Huang, Guojun Xiong, and Sophia Ananiadou. Moira: Language-driven hierarchical reinforcement learning for pair trading, 2026. URLhttps://arxiv.org/abs/2605.01954
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Tianyu Fan, Yuhao Yang, Yangqin Jiang, Yifei Zhang, Yuxuan Chen, and Chao Huang. Ai- trader: Benchmarking autonomous agents in real-time financial markets.arXiv preprint arXiv:2512.10971, 2025
-
[12]
Haofei Yu, Fenghai Li, and Jiaxuan You. Livetradebench: Seeking real-world alpha with large language models.arXiv preprint arXiv:2511.03628, 2025
-
[13]
Jonathan Bragg, Mike D’Arcy, Nishant Balepur, Dan Bareket, Bhavana Dalvi, Sergey Feldman, Dany Haddad, Jena D. Hwang, Peter Jansen, Varsha Kishore, Bodhisattwa Prasad Majumder, Aakanksha Naik, Sigal Rahamimov, Kyle Richardson, Amanpreet Singh, Harshit Surana, Aryeh Tiktinsky, Rosni Vasu, Guy Wiener, Chloe Anastasiades, Stefan Candra, Jason Dunkelberger, D...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Elron Bandel, Asaf Yehudai, Lilach Eden, Yehoshua Sagron, Yotam Perlitz, Elad Venezian, Natalia Razinkov, Natan Ergas, Shlomit Shachor Ifergan, Segev Shlomov, Michal Jacovi, Leshem Choshen, Liat Ein-Dor, Yoav Katz, and Michal Shmueli-Scheuer. General agent evaluation, 2026. URLhttps://arxiv.org/abs/2602.22953
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Finretrieval: A benchmark for financial data retrieval by ai agents.Technical Report, 2026
Jie Huang Kim.Y . Finretrieval: A benchmark for financial data retrieval by ai agents.Technical Report, 2026. URL https://raw.githubusercontent.com/daloopa/finretrieval/ main/docs/finretrieval.pdf. 11
2026
-
[16]
Finmcp-bench: Benchmarking llm agents for real-world financial tool use under the model context protocol
Jie Zhu, Yimin Tian, Boyang Li, Kehao Wu, Zhongzhi Liang, Junhui Li, Xianyin Zhang, Lifan Guo, Feng Chen, Yong Liu, and Chi Zhang. Finmcp-bench: Benchmarking llm agents for real-world financial tool use under the model context protocol. InProceedings of ICASSP, 2026
2026
-
[17]
Finance Agent Benchmark: Benchmarking LLMs on Real-world Financial Research Tasks
Antoine Bigeard, Langston Nashold, Rayan Krishnan, and Shirley Wu. Finance agent benchmark: Benchmarking llms on real-world financial research tasks, 2025. URL https: //arxiv.org/abs/2508.00828
-
[18]
Findeepresearch: Evaluating deep research agents in rigorous financial analysis,
Fengbin Zhu, Xiang Yao Ng, Ziyang Liu, Chang Liu, Xianwei Zeng, Chao Wang, Tianhui Tan, Xuan Yao, Pengyang Shao, Min Xu, Zixuan Wang, Jing Wang, Xin Lin, Junfeng Li, Jingxian Zhu, Yang Zhang, Wenjie Wang, Fuli Feng, Richang Hong, Huanbo Luan, Ke-Wei Huang, and Tat-Seng Chua. Findeepresearch: Evaluating deep research agents in rigorous financial analysis,
- [19]
-
[20]
Xiangyu Li, Xuan Yao, Guohao Qi, Fengbin Zhu, Kelvin J. L. Koa, Xiang Yao Ng, Ziyang Liu, Xingyu Ni, Chang Liu, Yonghui Yang, Yang Zhang, Wenjie Wang, Fuli Feng, Chao Wang, Huanbo Luan, Xiaofen Xing, Xiangmin Xu, Tat-Seng Chua, and Ke-Wei Huang. Findeepfore- cast: A live multi-agent system for benchmarking deep research agents in financial forecasting,
- [21]
-
[22]
Finch: Benchmarking finance & accounting across spreadsheet- centric enterprise workflows
Haoyu Dong, Pengkun Zhang, Yan Gao, Xuanyu Dong, Yilin Cheng, Mingzhe Lu, Adina Yakefu, and Shuxin Zheng. Finch: Benchmarking finance & accounting across spreadsheet- centric enterprise workflows. InThe 2nd Workshop on Advances in Financial AI Workshop: Towards Agentic and Responsible Systems, 2026. URL https://openreview.net/forum? id=8y6OZBqaCl
2026
-
[23]
URLhttps://github.com/QF-Bench/QuantitativeFinance-Bench
Quantitativefinance-bench: A state-aware interactive benchmark for financial agent tasks, 2026. URLhttps://github.com/QF-Bench/QuantitativeFinance-Bench
2026
-
[24]
Deep direct reinforce- ment learning for financial signal representation and trading.IEEE Transactions on Neural Networks and Learning Systems, 28:653–664, 2017
Yue Deng, Feng Bao, Youyong Kong, Zhiquan Ren, and Qionghai Dai. Deep direct reinforce- ment learning for financial signal representation and trading.IEEE Transactions on Neural Networks and Learning Systems, 28:653–664, 2017. URL https://api.semanticscholar. org/CorpusID:9398383
2017
-
[25]
John Moody, Lizhong Wu, Yuansong Liao, and Matthew Saffell. Performance functions and reinforcement learning for trading systems and portfolios.Journal of Forecasting, 17 (5-6):441–470, 1998. doi: https://doi.org/10.1002/(SICI)1099-131X(1998090)17:5/6<441:: AID-FOR707>3.0.CO;2-\#. URL https://onlinelibrary.wiley.com/doi/abs/10. 1002/%28SICI%291099-131X%28...
-
[26]
Giving content to investor sentiment: The role of media in the stock market
Paul C Tetlock. Giving content to investor sentiment: The role of media in the stock market. The Journal of finance, 62(3):1139–1168, 2007
2007
-
[27]
Securities and Exchange Commission
U.S. Securities and Exchange Commission. Structured data (xbrl). https://www.sec.gov/ structureddata, n.d.. Accessed: 2026-03-17
2026
-
[28]
yfinance: Download market data from yahoo! finance’s api
Ran Aroussi. yfinance: Download market data from yahoo! finance’s api. https://github. com/ranaroussi/yfinance, 2026
2026
-
[29]
Securities and Exchange Commission
U.S. Securities and Exchange Commission. Form 10-k and form 10-q. https://www.sec. gov/answers/form10k.htm, n.d.. Accessed: 2026-03-17
2026
-
[30]
Deepseek-v4-flash
DeepSeek-AI. Deepseek-v4-flash. https://huggingface.co/deepseek-ai/ DeepSeek-V4-Flash, 2026
2026
-
[31]
Qwen3.5-397b-a17b
Qwen Team. Qwen3.5-397b-a17b. https://huggingface.co/Qwen/Qwen3.5-397B-A17B, 2026
2026
-
[32]
Qwen3.5-27b.https://huggingface.co/Qwen/Qwen3.5-27B, 2026
Qwen Team. Qwen3.5-27b.https://huggingface.co/Qwen/Qwen3.5-27B, 2026
2026
- [34]
-
[35]
Docfinqa: A long-context financial reasoning dataset
Varshini Reddy, Rik Koncel-Kedziorski, Viet Dac Lai, Michael Krumdick, Charles Lovering, and Chris Tanner. Docfinqa: A long-context financial reasoning dataset. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 445–458, 2024
2024
-
[36]
FinanceBench: A New Benchmark for Financial Question Answering
Pranab Islam, Anand Kannappan, Douwe Kiela, Rebecca Qian, Nino Scherrer, and Bertie Vidgen. Financebench: A new benchmark for financial question answering, 2023. URL https://arxiv.org/abs/2311.11944
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
FinChain: A Symbolic Benchmark for Verifiable Chain-of-Thought Financial Reasoning
Zhuohan Xie, Daniil Orel, Rushil Thareja, Dhruv Sahnan, Hachem Madmoun, Fan Zhang, Debopriyo Banerjee, Georgi Georgiev, Xueqing Peng, Lingfei Qian, et al. Finchain: A symbolic benchmark for verifiable chain-of-thought financial reasoning.arXiv preprint arXiv:2506.02515, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Fino1: On the transferability of reasoning enhanced llms to finance.arXiv e-prints, pages arXiv–2502, 2025
Lingfei Qian, Weipeng Zhou, Yan Wang, Xueqing Peng, Jimin Huang, and Qianqian Xie. Fino1: On the transferability of reasoning enhanced llms to finance.arXiv e-prints, pages arXiv–2502, 2025
2025
-
[39]
Jimin Huang, Mengxi Xiao, Dong Li, Zihao Jiang, Yuzhe Yang, Yifei Zhang, Lingfei Qian, Yan Wang, Xueqing Peng, Yang Ren, Ruoyu Xiang, Zhengyu Chen, Xiao Zhang, Yueru He, Weiguang Han, Shunian Chen, Lihang Shen, Daniel Kim, Yangyang Yu, Yupeng Cao, Zhiyang Deng, Haohang Li, Duanyu Feng, Yongfu Dai, VijayaSai Somasundaram, Peng Lu, Guojun Xiong, Zhiwei Liu,...
-
[40]
XFinBench: Benchmarking LLMs in complex financial problem solving and reasoning
Zhihan Zhang, Yixin Cao, and Lizi Liao. XFinBench: Benchmarking LLMs in complex financial problem solving and reasoning. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Computational Linguistics: ACL 2025, pages 8715–8758, Vienna, Austria, July 2025. Association for Computational Ling...
-
[41]
Gta: A benchmark for general tool agents
Jize Wang, Zerun Ma, Yining Li, Songyang Zhang, Cailian Chen, Kai Chen, and Xinyi Le. Gta: A benchmark for general tool agents. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 75749–75790. Curran Associates, Inc., 2024. doi: 10.52202/079017-24...
-
[42]
Benchmark test-time scaling of general llm agents, 2026
Xiaochuan Li, Ryan Ming, Pranav Setlur, Abhijay Paladugu, Andy Tang, Hao Kang, Shuai Shao, Rong Jin, and Chenyan Xiong. Benchmark test-time scaling of general llm agents, 2026. URLhttps://arxiv.org/abs/2602.18998
-
[43]
GAIA: a benchmark for general AI assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: a benchmark for general AI assistants. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=fibxvahvs3
2024
-
[44]
Association for Computing Machinery, New York, NY , USA, 2025
Chanyeol Choi, Jihoon Kwon, Alejandro Lopez-Lira, Chaewoon Kim, Minjae Kim, Juneha Hwang, Jaeseon Ha, Hojun Choi, Suyeol Yun, Yongjin Kim, and Yongjae Lee.FinAgentBench: A Benchmark Dataset for Agentic Retrieval in Financial Question Answering, page 632–637. Association for Computing Machinery, New York, NY , USA, 2025. ISBN 9798400722202. URLhttps://doi....
-
[45]
–” indicates that the agent failed to produce a valid executable result after five attempts; “—
Yanxu Chen, Zijun Yao, Yantao Liu, Jin Ye, Jianing Yu, Lei Hou, and Juanzi Li. Stockbench: Can llm agents trade stocks profitably in real-world markets?arXiv preprint arXiv:2510.02209, 2025. 13 A Related Work Financial LLM benchmarks.A large body of work evaluates the capability of large language mod- els on financial tasks. These benchmarks typically foc...
-
[46]
**Positive Rubrics**: Excellence indicators and fundamental requirements that distinguish superior, highly-detailed responses
-
[47]
Yes/No" or require extracting an exact
**Negative Rubrics**: Critical flaws or active mistakes that definitively degrade the quality of a report (Focus on clear failure modes, not just the absence of excellence). # Core Guidelines & Methodologies You must strictly adhere to the following principles when extracting and generating rubrics: ### 1. Discriminative Power & Methodology - **Consensus ...
2023
-
[48]
Points are awarded proportionally at the criterion level and the dimension total is rounded to the nearest integer
Report Structure: This dimension assesses whether the report follows the required format required in report generation skill. Points are awarded proportionally at the criterion level and the dimension total is rounded to the nearest integer
-
[49]
Content Accuracy: This dimension assesses whether the report’s metadata, dates, and key content fields are factually correct against the parquet data
-
[50]
It comprises three sub-dimensions
Evidence Fidelity: This dimension assesses whether the report’s quantitative metrics and qualitative content are grounded in the parquet data. It comprises three sub-dimensions
-
[51]
Reasoning Quality: This dimension assesses the analytical quality of the report holistically, which consists of rating-evidence consistency, thesis distinctness, risk specificity, Outlook concreteness, and cross-section coherence. In practice, our implementation instantiates this scaling process by independently generating baseline reports for a specific ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.