Video-Zero: Self-Evolution Video Understanding
Pith reviewed 2026-06-30 21:30 UTC · model grok-4.3
The pith
Video-Zero improves video VLMs through evidence-centered self-evolution without annotations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
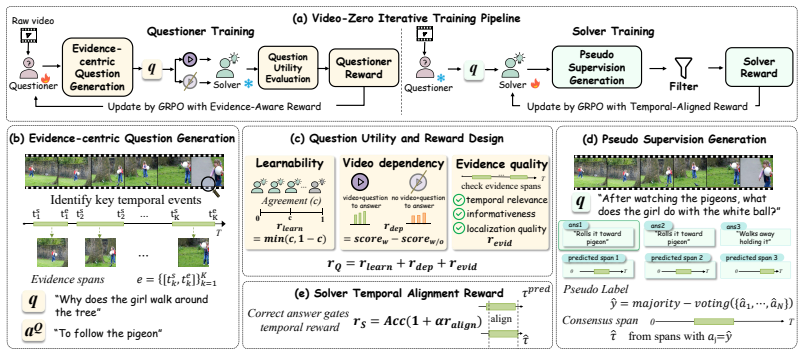
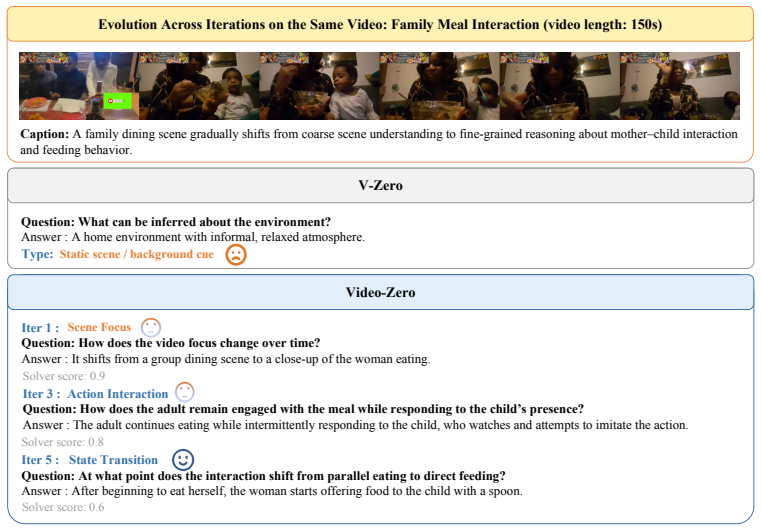
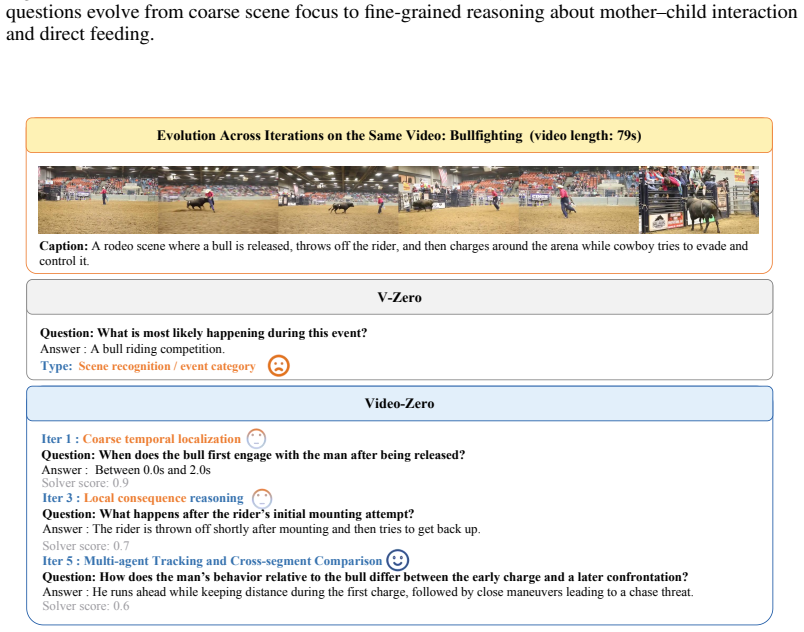
Video-Zero is an annotation-free Questioner-Solver co-evolution framework that centers self-evolution on temporally localized evidence. The Questioner discovers informative evidence segments and generates evidence-grounded questions, while the Solver learns to answer and align its predictions with the supporting evidence, closing an iterative loop of evidence discovery, grounded supervision, and evidence-aligned learning.
What carries the argument
The Questioner--Solver co-evolution framework that centers self-evolution on temporally localized evidence.
If this is right
- Improves performance on temporal grounding benchmarks.
- Enhances long-video understanding capabilities.
- Boosts video reasoning tasks across multiple video VLM backbones.
- Shows transferability of the evidence-centered approach.
Where Pith is reading between the lines
- Similar evidence-centered loops could be tested in other dynamic domains like audio or 3D video.
- If the Questioner fails to find truly temporal evidence, performance gains would likely disappear.
- Extending the framework to generate even more diverse evidence segments might further improve generalization.
Load-bearing premise
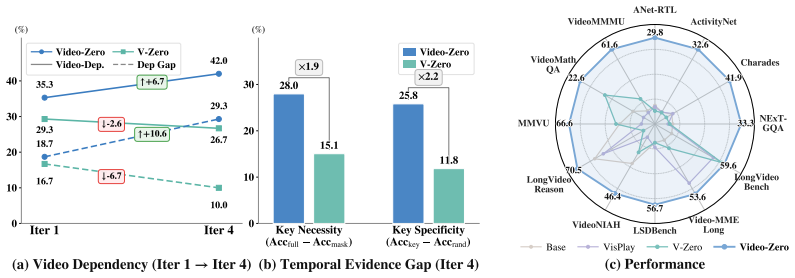
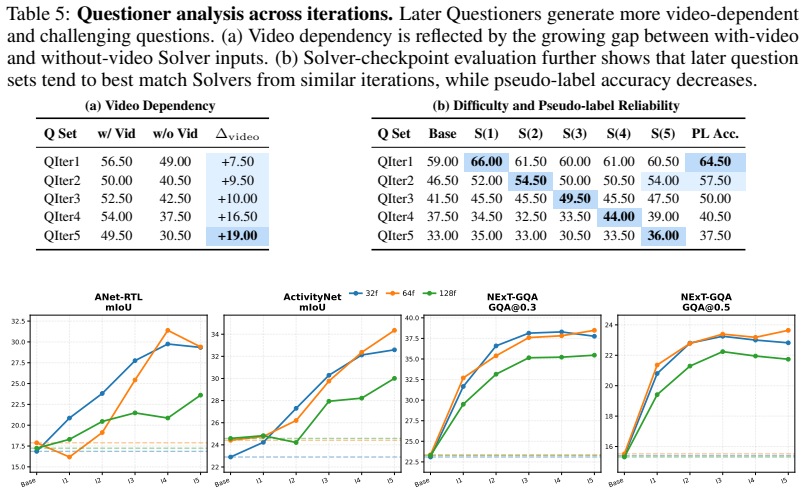
The key bottleneck of video self-evolution is grounding rather than difficulty alone, and that the Questioner can discover informative evidence segments that produce supervision truly grounded in temporal evidence rather than static cues or language priors.
What would settle it
Running Video-Zero and a naive full-video question generation method on the same backbones and observing no difference in performance on temporal grounding benchmarks would falsify the claim that grounding is the key bottleneck.
Figures




read the original abstract
Self-evolution offers a promising path for improving reasoning models without relying on intensive human annotation. However, extending this paradigm to video understanding remains underexplored and challenging: videos are long, dynamic, and redundant, while the evidence needed for reasoning is often sparse and temporally localized. Naively generating difficult question-answer pairs from full videos can therefore produce supervision that appears challenging but is weakly grounded, relying on static cues or language priors rather than temporal evidence. In this work, we argue that the key bottleneck of video self-evolution is not difficulty alone, but grounding. We propose Video-Zero, an annotation-free Questioner--Solver co-evolution framework that centers self-evolution on temporally localized evidence. The Questioner discovers informative evidence segments and generates evidence-grounded questions, while the Solver learns to answer and align its predictions with the supporting evidence. This closes an iterative loop of evidence discovery, grounded supervision, and evidence-aligned learning. Across 13 benchmarks spanning temporal grounding, long-video understanding, and video reasoning, Video-Zero consistently improves multiple video VLM backbones, demonstrating the effectiveness and transferability of evidence-centered self-evolution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the key bottleneck in video self-evolution is grounding (not difficulty alone), and introduces Video-Zero: an annotation-free Questioner-Solver co-evolution framework in which the Questioner discovers temporally localized evidence segments and generates evidence-grounded QA pairs while the Solver learns to answer and align predictions to that evidence. This iterative loop is reported to yield consistent gains across 13 benchmarks covering temporal grounding, long-video understanding, and video reasoning when applied to multiple video VLM backbones.
Significance. If the grounding mechanism is shown to be effective and the gains are demonstrably attributable to evidence-centered supervision rather than generic self-training or language priors, the work would offer a practical, annotation-free route to improving video VLMs with transferability across backbones; the emphasis on sparse temporal evidence addresses a recognized challenge in long-video reasoning.
major comments (2)
- [Abstract / method description] Abstract and method overview: the central claim that Video-Zero's gains arise from evidence-centered self-evolution (rather than standard self-training or language priors) requires a verification step ensuring generated QA pairs are unsolvable without the exact localized temporal window; no such control, metric, or ablation is described that would confirm the Questioner produces supervision truly dependent on the discovered segment versus static frames or full-video cues.
- [Abstract] The weakest assumption (that grounding, not difficulty, is the bottleneck) is load-bearing for the framework design, yet the provided description supplies no quantitative evidence (e.g., comparison of performance when questions are generated from localized vs. unlocalized segments, or controls that isolate temporal evidence use) to support that the iterative loop enforces grounding.
minor comments (1)
- [Abstract] The abstract states improvements on 13 benchmarks but does not name the specific backbones, datasets, or metrics used for temporal evidence alignment; adding these details would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive comments. We address the major comments point-by-point below, proposing revisions to strengthen the manuscript where needed.
read point-by-point responses
-
Referee: [Abstract / method description] Abstract and method overview: the central claim that Video-Zero's gains arise from evidence-centered self-evolution (rather than standard self-training or language priors) requires a verification step ensuring generated QA pairs are unsolvable without the exact localized temporal window; no such control, metric, or ablation is described that would confirm the Questioner produces supervision truly dependent on the discovered segment versus static frames or full-video cues.
Authors: We agree that a direct verification of the dependency on localized temporal evidence would better substantiate our claim. In the revised manuscript, we will add a new ablation study. Specifically, we will generate QA pairs using the Questioner with localized segments and compare against versions where segments are not localized (e.g., full video or random frames). We will also measure the Solver's performance drop when the evidence window is masked or removed during inference, providing quantitative evidence that the supervision is indeed evidence-dependent. revision: yes
-
Referee: [Abstract] The weakest assumption (that grounding, not difficulty, is the bottleneck) is load-bearing for the framework design, yet the provided description supplies no quantitative evidence (e.g., comparison of performance when questions are generated from localized vs. unlocalized segments, or controls that isolate temporal evidence use) to support that the iterative loop enforces grounding.
Authors: The framework is designed such that the Questioner focuses on discovering temporally localized evidence to generate questions, which by construction emphasizes grounding over mere difficulty. However, we acknowledge the lack of explicit quantitative comparison in the current version. We will include in the revision a direct comparison of the full Video-Zero pipeline against a variant where the Questioner generates questions from unlocalized (full-video) segments, demonstrating the importance of the grounding mechanism through performance differences across the benchmarks. revision: yes
Circularity Check
No circularity: framework described without equations or self-referential reductions
full rationale
The paper presents Video-Zero as an iterative Questioner-Solver loop for evidence-centered self-evolution in video VLMs. No equations, fitted parameters, or mathematical derivations are described in the abstract or provided text. The central claim rests on empirical benchmark gains rather than any derivation that reduces by construction to its inputs. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked. This matches the default case of a self-contained empirical method with no detectable circularity in its claimed chain.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Videos are long, dynamic, and redundant, with evidence needed for reasoning often sparse and temporally localized.
- domain assumption Naively generating difficult question-answer pairs from full videos produces supervision that relies on static cues or language priors rather than temporal evidence.
Reference graph
Works this paper leans on
-
[1]
Self-Rewarding Language Models
Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. Self-rewarding language models.CoRR, abs/2401.10020, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah D. Goodman. Star: Bootstrapping reasoning with reasoning. InNeurIPS, 2022
2022
-
[3]
A survey on self-evolution of large language models
Zhengwei Tao, Ting-En Lin, Xiancai Chen, Hangyu Li, Yuchuan Wu, Yongbin Li, Zhi Jin, Fei Huang, Dacheng Tao, and Jingren Zhou. A survey on self-evolution of large language models. CoRR, abs/2404.14387, 2024
-
[4]
Self-play fine-tuning converts weak language models to strong language models
Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, and Quanquan Gu. Self-play fine-tuning converts weak language models to strong language models. InICML, Proceedings of Machine Learning Research, pages 6621–6642. PMLR / OpenReview.net, 2024
2024
-
[5]
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Yang Yue, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, and Gao Huang. Absolute zero: Reinforced self-play reasoning with zero data.CoRR, abs/2505.03335, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
R-Zero: Self-Evolving Reasoning LLM from Zero Data
Chengsong Huang, Wenhao Yu, Xiaoyang Wang, Hongming Zhang, Zongxia Li, Ruosen Li, Jiaxin Huang, Haitao Mi, and Dong Yu. R-zero: Self-evolving reasoning LLM from zero data. CoRR, abs/2508.05004, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
V-zero: Self-improving multimodal reasoning with zero annotation.CoRR, abs/2601.10094, 2026
Han Wang, Yi Yang, Jingyuan Hu, Minfeng Zhu, and Wei Chen. V-zero: Self-improving multimodal reasoning with zero annotation.CoRR, abs/2601.10094, 2026
-
[8]
Mm-zero: Self-evolving multi-model vision language models from zero data.CoRR, abs/2603.09206, 2026
Zongxia Li, Hongyang Du, Chengsong Huang, Xiyang Wu, Lantao Yu, Yicheng He, Jing Xie, Xiaomin Wu, Zhichao Liu, Jiarui Zhang, and Fuxiao Liu. Mm-zero: Self-evolving multi-model vision language models from zero data.CoRR, abs/2603.09206, 2026
-
[9]
Video-R1: Reinforcing Video Reasoning in MLLMs
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Benyou Wang, and Xiangyu Yue. Video-r1: Reinforcing video reasoning in mllms.CoRR, abs/2503.21776, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
VideoChat-R1: Enhancing Spatio-Temporal Perception via Reinforcement Fine-Tuning
Xinhao Li, Ziang Yan, Desen Meng, Lu Dong, Xiangyu Zeng, Yinan He, Yali Wang, Yu Qiao, Yi Wang, and Limin Wang. Videochat-r1: Enhancing spatio-temporal perception via reinforce- ment fine-tuning.CoRR, abs/2504.06958, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
OneThinker: All-in-one Reasoning Model for Image and Video
Kaituo Feng, Manyuan Zhang, Hongyu Li, Kaixuan Fan, Shuang Chen, Yilei Jiang, Dian Zheng, Peiwen Sun, Yiyuan Zhang, Haoze Sun, Yan Feng, Peng Pei, Xunliang Cai, and Xiangyu Yue. Onethinker: All-in-one reasoning model for image and video.CoRR, abs/2512.03043, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Grounded-videollm: Sharpening fine-grained temporal grounding in video large language models
Haibo Wang, Zhiyang Xu, Yu Cheng, Shizhe Diao, Yufan Zhou, Yixin Cao, Qifan Wang, Weifeng Ge, and Lifu Huang. Grounded-videollm: Sharpening fine-grained temporal grounding in video large language models. InEMNLP (Findings), pages 959–975. Association for Computational Linguistics, 2025
2025
-
[13]
Visplay: Self-evolving vision-language models from images.CoRR, abs/2511.15661, 2025
Yicheng He, Chengsong Huang, Zongxia Li, Jiaxin Huang, and Yonghui Yang. Visplay: Self-evolving vision-language models from images.CoRR, abs/2511.15661, 2025. 10
-
[14]
Smith, Daniel Khashabi, and Hannaneh Hajishirzi
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instruc- tions. InACL (1), pages 13484–13508. Association for Computational Linguistics, 2023
2023
-
[15]
SPICE: self-play in corpus environments improves reasoning.CoRR, abs/2510.24684, 2025
Bo Liu, Chuanyang Jin, Seungone Kim, Weizhe Yuan, Wenting Zhao, Ilia Kulikov, Xian Li, Sainbayar Sukhbaatar, Jack Lanchantin, and Jason Weston. SPICE: self-play in corpus environments improves reasoning.CoRR, abs/2510.24684, 2025
-
[16]
Ziyi Yang, Weizhou Shen, Ruijun Chen, Chenliang Li, Fanqi Wan, Ming Yan, Xiaojun Quan, and Fei Huang. SPELL: self-play reinforcement learning for evolving long-context language models.CoRR, abs/2509.23863, 2025
-
[17]
DARC: decoupled asymmetric reasoning curriculum for LLM evolution.CoRR, abs/2601.13761, 2026
Shengda Fan, Xuyan Ye, and Yankai Lin. DARC: decoupled asymmetric reasoning curriculum for LLM evolution.CoRR, abs/2601.13761, 2026
-
[18]
Qinsi Wang, Bo Liu, Tianyi Zhou, Jing Shi, Yueqian Lin, Yiran Chen, Hai Helen Li, Kun Wan, and Wentian Zhao. Vision-zero: Scalable VLM self-improvement via strategic gamified self-play.CoRR, abs/2509.25541, 2025
-
[19]
Jinghan He, Junfeng Fang, Feng Xiong, Zijun Yao, Fei Shen, Haiyun Guo, Jinqiao Wang, and Tat-Seng Chua. Active zero: Self-evolving vision-language models through active environment exploration.CoRR, abs/2602.11241, 2026
-
[20]
Time-R1: Post-Training Large Vision Language Model for Temporal Video Grounding
Ye Wang, Ziheng Wang, Boshen Xu, Yang Du, Kejun Lin, Zihan Xiao, Zihao Yue, Jianzhong Ju, Liang Zhang, Dingyi Yang, Xiangnan Fang, Zewen He, Zhenbo Luo, Wenxuan Wang, Junqi Lin, Jian Luan, and Qin Jin. Time-r1: Post-training large vision language model for temporal video grounding.arXiv preprint arXiv:2503.13377, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Yang Ding, Yizhen Zhang, Xin Lai, Ruihang Chu, and Yujiu Yang. Videozoomer: Reinforcement-learned temporal focusing for long video reasoning.CoRR, abs/2512.22315, 2025
-
[22]
Jiahao Meng, Xiangtai Li, Haochen Wang, Yue Tan, Tao Zhang, Lingdong Kong, Yunhai Tong, Anran Wang, Zhiyang Teng, Yujing Wang, and Zhuochen Wang. Open-o3 video: Grounded video reasoning with explicit spatio-temporal evidence.CoRR, abs/2510.20579, 2025
-
[23]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.CoRR, abs/2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Mimo-vl technical report.CoRR, abs/2506.03569, 2025
Zihao Yue, Zhenru Lin, Yifan Song, Weikun Wang, Shuhuai Ren, Shuhao Gu, Shicheng Li, Peidian Li, Liang Zhao, Lei Li, Kainan Bao, Hao Tian, Hailin Zhang, Xiao-Gang Wang, Dawei Zhu, Cici, Chenhong He, Bowen Ye, Bowen Shen, Zihan Zhang, Zihan Jiang, Zhixian Zheng, Zhichao Song, Zhenbo Luo, Yue Yu, Yudong Wang, Yuanyuan Tian, Yu Tu, Yihan Yan, Yi Huang, Xu Wa...
-
[26]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Lita: Language instructed temporal-localization assistant
De-An Huang, Shijia Liao, Subhashree Radhakrishnan, Hongxu Yin, Pavlo Molchanov, Zhiding Yu, and Jan Kautz. Lita: Language instructed temporal-localization assistant. InEuropean Conference on Computer Vision, pages 202–218. Springer, 2024
2024
-
[28]
Dense- captioning events in videos
Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, and Juan Carlos Niebles. Dense- captioning events in videos. InProceedings of the IEEE international conference on computer vision, pages 706–715, 2017
2017
-
[29]
Tall: Temporal activity localization via language query
Jiyang Gao, Chen Sun, Zhenheng Yang, and Ram Nevatia. Tall: Temporal activity localization via language query. InProceedings of the IEEE international conference on computer vision, pages 5267–5275, 2017
2017
-
[30]
Can i trust your answer? visually grounded video question answering
Junbin Xiao, Angela Yao, Yicong Li, and Tat-Seng Chua. Can i trust your answer? visually grounded video question answering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13204–13214, 2024
2024
-
[31]
Longvideobench: A benchmark for long- context interleaved video-language understanding.Advances in Neural Information Processing Systems, 37:28828–28857, 2024
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. Longvideobench: A benchmark for long- context interleaved video-language understanding.Advances in Neural Information Processing Systems, 37:28828–28857, 2024
2024
-
[32]
MLVU: Benchmarking Multi-task Long Video Understanding
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Zhengyang Liang, Shitao Xiao, Minghao Qin, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng Liu. Mlvu: Benchmarking multi-task long video understanding.arXiv preprint arXiv:2406.04264, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24108–24118, 2025
2025
-
[34]
Tianyuan Qu, Longxiang Tang, Bohao Peng, Senqiao Yang, Bei Yu, and Jiaya Jia. Does your vision-language model get lost in the long video sampling dilemma?arXiv preprint arXiv:2503.12496, 2025
-
[35]
Zijia Zhao, Haoyu Lu, Yuqi Huo, Yifan Du, Tongtian Yue, Longteng Guo, Bingning Wang, Weipeng Chen, and Jing Liu. Needle in a video haystack: A scalable synthetic evaluator for video mllms.arXiv preprint arXiv:2406.09367, 2024
-
[36]
Scaling RL to long videos.CoRR, abs/2507.07966, 2025
Yukang Chen, Wei Huang, Baifeng Shi, Qinghao Hu, Hanrong Ye, Ligeng Zhu, Zhijian Liu, Pavlo Molchanov, Jan Kautz, Xiaojuan Qi, Sifei Liu, Hongxu Yin, Yao Lu, and Song Han. Scaling RL to long videos.CoRR, abs/2507.07966, 2025
-
[37]
Mmvu: Measuring expert-level multi-discipline video understanding
Yilun Zhao, Haowei Zhang, Lujing Xie, Tongyan Hu, Guo Gan, Yitao Long, Zhiyuan Hu, Weiyuan Chen, Chuhan Li, Zhijian Xu, et al. Mmvu: Measuring expert-level multi-discipline video understanding. InProceedings of the Computer Vision and Pattern Recognition Confer- ence, pages 8475–8489, 2025
2025
-
[38]
Hanoona Rasheed, Abdelrahman Shaker, Anqi Tang, Muhammad Maaz, Ming-Hsuan Yang, Salman Khan, and Fahad Shahbaz Khan. Videomathqa: Benchmarking mathematical reasoning via multimodal understanding in videos.arXiv preprint arXiv:2506.05349, 2025
-
[39]
Video-MMMU: Evaluating Knowledge Acquisition from Multi-Discipline Professional Videos
Kairui Hu, Penghao Wu, Fanyi Pu, Wang Xiao, Yuanhan Zhang, Xiang Yue, Bo Li, and Ziwei Liu. Video-mmmu: Evaluating knowledge acquisition from multi-discipline professional videos. arXiv preprint arXiv:2501.13826, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
EvoLMM: Self-Evolving Large Multimodal Models with Continuous Rewards
Omkar Thawakar, Shravan Venkatraman, Ritesh Thawkar, Abdelrahman Shaker, Hisham Cholakkal, Rao Muhammad Anwer, Salman Khan, and Fahad Khan. Evolmm: Self-evolving large multimodal models with continuous rewards.arXiv preprint arXiv:2511.16672, 2025. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
SyncLoop: A Multimodal Dual-Loop Framework for Self-Improving Mathematical Reasoning
Xiuwei Chen, Wentao Hu, Hanhui Li, Jun Zhou, Zisheng Chen, Meng Cao, Yihan Zeng, Kui Zhang, Yu-Jie Yuan, Jianhua Han, Hang Xu, and Xiaodan Liang. C2-evo: Co-evolving multimodal data and model for self-improving reasoning.CoRR, abs/2507.16518, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, et al. Videollama 3: Frontier multimodal foundation models for image and video understanding.arXiv preprint arXiv:2501.13106, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
InternVideo2.5: Empowering Video MLLMs with Long and Rich Context Modeling
Yi Wang, Xinhao Li, Ziang Yan, Yinan He, Jiashuo Yu, Xiangyu Zeng, Chenting Wang, Changlian Ma, Haian Huang, Jianfei Gao, et al. Internvideo2. 5: Empowering video mllms with long and rich context modeling.arXiv preprint arXiv:2501.12386, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Canhui Tang, Zifan Han, Hongbo Sun, Sanping Zhou, Xuchong Zhang, Xin Wei, Ye Yuan, Jinglin Xu, and Hao Sun. Tspo: Temporal sampling policy optimization for long-form video language understanding.arXiv preprint arXiv:2508.04369, 2025
-
[45]
Trace: Temporal grounding video llm via causal event modeling,
Yongxin Guo, Jingyu Liu, Mingda Li, Qingbin Liu, Xi Chen, and Xiaoying Tang. TRACE: Temporal Grounding Video LLM via Causal Event Modeling.arXiv preprint arXiv:2410.05643, 2024
-
[46]
Shijian Wang, Jiarui Jin, Xingjian Wang, Linxin Song, Runhao Fu, Hecheng Wang, Zongyuan Ge, Yuan Lu, and Xuelian Cheng. Video-thinker: Sparking "thinking with videos" via reinforce- ment learning.CoRR, abs/2510.23473, 2025
-
[47]
MUSEG: Reinforcing Video Temporal Understanding via Timestamp-Aware Multi-Segment Grounding
Fuwen Luo, Shengfeng Lou, Chi Chen, Ziyue Wang, Chenliang Li, Weizhou Shen, Jiyue Guo, Peng Li, Ming Yan, Ji Zhang, Fei Huang, and Yang Liu. MUSEG: reinforcing video temporal understanding via timestamp-aware multi-segment grounding.CoRR, abs/2505.20715, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
TALL: Temporal Activity Localiza- tion via Language Query
Jiyang Gao, Chen Sun, Zhenheng Yang, and Ram Nevatia. TALL: Temporal Activity Localiza- tion via Language Query. InProceedings of the IEEE international conference on computer vision, pages 5267–5275, 2017
2017
-
[49]
Vtimellm: Empower llm to grasp video moments
Bin Huang, Xin Wang, Hong Chen, Zihan Song, and Wenwu Zhu. Vtimellm: Empower llm to grasp video moments. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14271–14280, 2024
2024
-
[50]
Haibo Wang, Zhiyang Xu, Yu Cheng, Shizhe Diao, Yufan Zhou, Yixin Cao, Qifan Wang, Weifeng Ge, and Lifu Huang. Grounded-videollm: Sharpening fine-grained temporal grounding in video large language models.arXiv preprint arXiv:2410.03290, 2024
-
[51]
Timesuite: Improving mllms for long video understanding via grounded tuning,
Xiangyu Zeng, Kunchang Li, Chenting Wang, Xinhao Li, Tianxiang Jiang, Ziang Yan, Songze Li, Yansong Shi, Zhengrong Yue, Yi Wang, et al. Timesuite: Improving mllms for long video understanding via grounded tuning.arXiv preprint arXiv:2410.19702, 2024
-
[52]
Beyond the individual: Introducing group intention forecasting with SHOT dataset
Ruixu Zhang, Yuran Wang, Xinyi Hu, Chaoyu Mai, Wenxuan Liu, Danni Xu, Xian Zhong, and Zheng Wang. Beyond the individual: Introducing group intention forecasting with SHOT dataset. InProceedings of the ACM International Conference on Multimedia, pages 13002–13008. ACM, 2025
2025
-
[53]
Vlmevalkit: An open-source toolkit for evaluating large multi-modality models
Haodong Duan, Junming Yang, Yuxuan Qiao, Xinyu Fang, Lin Chen, Yuan Liu, Xiaoyi Dong, Yuhang Zang, Pan Zhang, Jiaqi Wang, et al. Vlmevalkit: An open-source toolkit for evaluating large multi-modality models. InProceedings of the 32nd ACM International Conference on Multimedia, pages 11198–11201, 2024. 13 A Appendix Overview This appendix provides more sup...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.