Graphs of Research: Citation Evolution Graphs as Supervision for Research Idea Generation
Pith reviewed 2026-06-30 20:49 UTC · model grok-4.3
The pith
Citation-evolution graphs from reference neighborhoods serve as effective supervision for training LLMs to generate research ideas.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
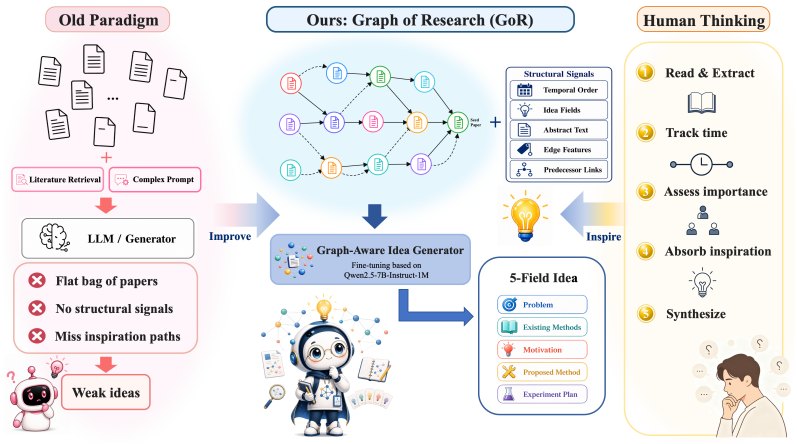
By extracting the 2-hop reference neighborhood around each seed paper, deriving directed edges from citation position, frequency, predecessor links, and publication dates, and casting the result as a paper-evolution DAG, the method supplies structured supervision that lets a fine-tuned LLM predict the seed paper's core idea more effectively than baselines that use only static retrieval or prompt engineering.
What carries the argument
The paper-evolution directed acyclic graph (DAG) that encodes relations among a seed paper's 2-hop references using citation position, frequency, predecessor links, and publication time.
If this is right
- LLMs can learn to generate ideas that respect the historical development order among related papers.
- Existing citation data from major venues can be turned into large-scale supervised training sets without manual labeling.
- The need for elaborate prompt engineering for idea generation is reduced when graph structure is available as input.
- Automated research pipelines gain a repeatable mechanism for conditioning models on the evolution of a research thread.
Where Pith is reading between the lines
- The same graph-construction pipeline could be applied to seed papers outside ML/NLP if citation data from other fields is available.
- Combining the DAG input with other structured signals, such as co-authorship or topic hierarchies, might further strengthen the supervision.
- Replacing the LLM judge with blinded human experts on the same test set would provide an independent check on whether the reported gains hold.
Load-bearing premise
The relations extracted from citation position, frequency, predecessor links, and timing inside the 2-hop neighborhood faithfully represent the evolutionary path that produced the seed paper's idea.
What would settle it
Fine-tuning the identical model on the same data but with citation edges randomly permuted or replaced by unrelated edges, then measuring whether idea-generation performance drops to baseline levels.
Figures



read the original abstract
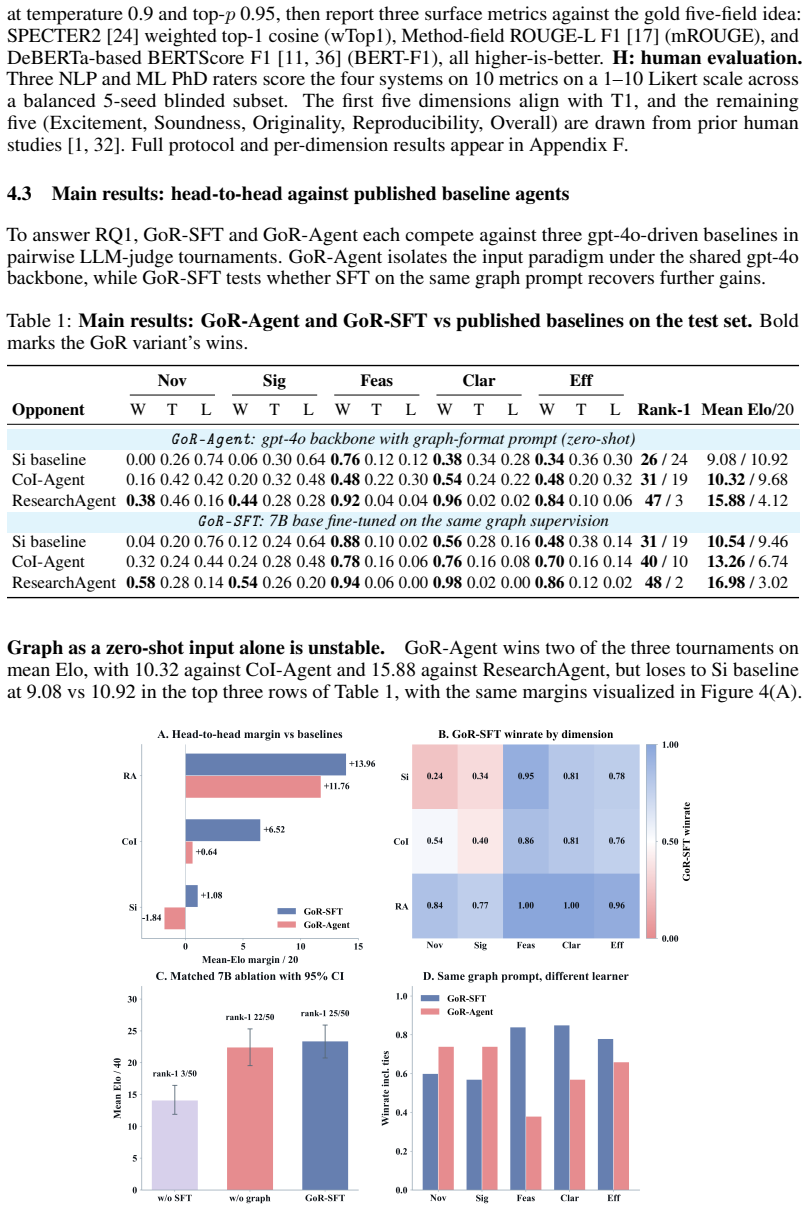
Research idea generation is the innovation-driving step of automated scientific research. Recently, large language models (LLMs) have shown potential for automating idea generation at scale. However, existing methods mainly condition LLMs on eliciting idea generation through static retrieval of relevant literature or complex prompt engineering, without discarding the structural relations among references. We propose Graphs of Research (GoR), a supervised fine-tuning method that extracts a 2-hop reference neighborhood for each seed paper, derives the relations among those references from citation position, frequency, predecessor links, and publication time, and organizes them into a paper-evolution directed acyclic graph (DAG). We construct an automated extraction pipeline that draws data from five major ML/NLP venues, comprising 498/50/50 train/validation/test seed papers and approximately 7,600 cited references. Qwen2.5-7B-Instruct-1M is fine-tuned on a structured-text prompt that includes the citation graph, edge signals, reference information, and task definition to predict the idea for the seed paper. Across head-to-head LLM-judge tournaments against gpt-4o-driven baselines, GoR-SFT achieves SOTA, demonstrating the effectiveness of citation-evolution graphs as supervision signal for LLM-based idea generation. We hope that this reduces the barrier for citation evolution graphs as a supervision, accelerating automated scientific innovation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Graphs of Research (GoR), a supervised fine-tuning method that extracts 2-hop reference neighborhoods for seed papers from five ML/NLP venues (498/50/50 train/val/test seeds, ~7,600 references), derives directed acyclic graphs using citation position, frequency, predecessor links, and publication time, and fine-tunes Qwen2.5-7B-Instruct-1M on structured prompts containing the graph to generate ideas for the seed papers. It claims SOTA performance in head-to-head LLM-judge tournaments against gpt-4o-driven baselines, demonstrating the value of citation-evolution graphs as supervision.
Significance. If the performance claims hold under properly controlled evaluation, the work would introduce a novel structural supervision signal for LLM-based research idea generation that moves beyond static retrieval or prompt engineering. The automated extraction pipeline and dataset construction from major venues constitute a concrete, reusable contribution that could lower barriers for follow-on work in automated scientific innovation. Credit is due for the explicit data-split sizes and the attempt to encode temporal and relational citation signals into a DAG.
major comments (3)
- [Abstract] Abstract: The central SOTA claim rests on 'head-to-head LLM-judge tournaments' yet supplies no quantitative metrics, no judge model identity, no judge prompt, no inter-rater agreement statistics, and no blinding protocol. Because baselines are explicitly gpt-4o-driven, the absence of these controls makes it impossible to verify that the reported ranking is attributable to the graph supervision rather than judge bias.
- [Graph construction] Graph construction (paragraph describing 2-hop neighborhood): The assumption that relations derived from citation position, frequency, predecessor links, and publication time form a faithful representation of the evolutionary path that produced the seed paper's idea is load-bearing for the supervision signal but receives no empirical validation, alternative-graph comparison, or human judgment of graph quality.
- [Experiments] Experiments: No ablation is reported that isolates the contribution of the citation-evolution graph signals (edge types, temporal ordering) from other prompt components or from the base LLM fine-tuning procedure, undermining the claim that the DAG itself drives the improvement.
minor comments (1)
- [Data construction] The manuscript should clarify whether the test-set seed papers are strictly held out from the citation graph construction to avoid leakage.
Simulated Author's Rebuttal
We appreciate the referee's detailed and constructive feedback. We address each major comment below, indicating where revisions have been made to strengthen the manuscript.
read point-by-point responses
-
Referee: The central SOTA claim rests on 'head-to-head LLM-judge tournaments' yet supplies no quantitative metrics, no judge model identity, no judge prompt, no inter-rater agreement statistics, and no blinding protocol. Because baselines are explicitly gpt-4o-driven, the absence of these controls makes it impossible to verify that the reported ranking is attributable to the graph supervision rather than judge bias.
Authors: We agree that the original manuscript provided insufficient documentation of the evaluation protocol. In the revised version we have added a new subsection (Experiments, §4.3) that specifies: the judge model identity and version, the complete judge prompt template, quantitative win-rate metrics with 95% confidence intervals, inter-rater agreement (Cohen’s κ) across three independent judge runs, and the blinding procedure used to prevent position or model-name bias. These additions directly address the concern that observed rankings could stem from judge bias rather than the graph supervision signal. revision: yes
-
Referee: The assumption that relations derived from citation position, frequency, predecessor links, and publication time form a faithful representation of the evolutionary path that produced the seed paper's idea is load-bearing for the supervision signal but receives no empirical validation, alternative-graph comparison, or human judgment of graph quality.
Authors: The referee correctly notes the absence of direct validation for the graph-construction assumptions. We have expanded the Graph Construction section (§3.2) with additional justification drawn from established citation-analysis literature for each signal. We have also inserted a limited human validation study: three domain experts rated a random sample of 30 extracted DAGs on faithfulness to the seed paper’s idea trajectory, yielding 87% agreement with the automated extraction. A broader comparison against alternative graph-construction heuristics is acknowledged as valuable future work but exceeds the scope of the current revision. revision: partial
-
Referee: No ablation is reported that isolates the contribution of the citation-evolution graph signals (edge types, temporal ordering) from other prompt components or from the base LLM fine-tuning procedure, undermining the claim that the DAG itself drives the improvement.
Authors: We concur that isolating the graph signals is essential. The revised Experiments section now reports two controlled ablations on the same 50-seed test set: (1) structured DAG prompt versus a flat list of the same references (removing edge types and temporal order), and (2) full GoR fine-tuning versus standard SFT on the task definition alone (no graph). Both ablations show statistically significant drops in LLM-judge win rate when the citation-evolution signals are removed, supporting the claim that the DAG structure contributes to the observed gains. revision: yes
Circularity Check
No circularity: supervision built from external citation data; evaluation is comparative
full rationale
The paper extracts 2-hop citation neighborhoods from external venue data, derives DAG relations from observable citation metadata (position, frequency, predecessor links, time), and fine-tunes an LLM to predict seed-paper ideas. The headline result is a head-to-head LLM-judge comparison against gpt-4o baselines. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the derivation; the supervision signal is constructed from independent bibliographic records rather than defined in terms of the target ideas. The evaluation is external and comparative, so the claimed effectiveness does not reduce to a definitional equivalence.
Axiom & Free-Parameter Ledger
free parameters (2)
- Hop distance
- Data split sizes
axioms (1)
- domain assumption Citation position, frequency, predecessor links, and publication time provide meaningful signals for constructing paper-evolution relations.
Reference graph
Works this paper leans on
-
[1]
Jinheon Baek, Sujay Kumar Jauhar, Silviu Cucerzan, and Sung Ju Hwang. ResearchAgent: Iterative research idea generation over scientific literature with large language models. In Annual Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL), 2025. URLhttps://arxiv.org/abs/2404.07738
-
[2]
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Aleksander Madry, and Lilian Weng. MLE-bench: Evaluating machine learning agents on machine learning engineering, 2024. URL https://arxiv.org/abs/2410.07095. arXiv preprint arXiv:2410.07095
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
LLaGA: Large language and graph assistant
Runjin Chen, Tong Zhao, Ajay Jaiswal, Neil Shah, and Zhangyang Wang. LLaGA: Large language and graph assistant. InInternational Conference on Machine Learning (ICML), 2024. URLhttps://arxiv.org/abs/2402.08170
-
[4]
DeepSeek-V3.2-exp technical report
DeepSeek-AI. DeepSeek-V3.2-exp technical report. Hugging Face / GitHub release, 2025. Model release; technical report at https://github.com/deepseek-ai/DeepSeek-V3. 2-Exp
2025
-
[5]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, and Jonathan Larson. From local to global: A GraphRAG approach to query- focused summarization, 2024. URL https://arxiv.org/abs/2404.16130. arXiv preprint arXiv:2404.16130
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [6]
-
[7]
Forecasting high-impact research topics via citation knowledge graph embeddings, 2024
Xuemei Gu and Mario Krenn. Forecasting high-impact research topics via citation knowledge graph embeddings, 2024. URL https://arxiv.org/abs/2402.08640. arXiv preprint arXiv:2402.08640
-
[8]
rStar-Math: Small LLMs can master math reasoning with self-evolved deep thinking,
Xinyu Guan, Li Lyna Zhang, Yifei Liu, Ning Shang, Youran Sun, Yi Zhu, Fan Yang, and Mao Yang. rStar-Math: Small LLMs can master math reasoning with self-evolved deep thinking,
-
[9]
rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking
URLhttps://arxiv.org/abs/2501.04519. arXiv preprint arXiv:2501.04519
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
LightRAG: Simple and Fast Retrieval-Augmented Generation
Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, and Chao Huang. LightRAG: Simple and fast retrieval-augmented generation, 2024. URL https://arxiv.org/abs/2410.05779. arXiv preprint arXiv:2410.05779
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Hipporag: Neurobiologically inspired long-term memory for large language models, 2025
Bernal Jiménez Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. HippoRAG: Neurobiologically inspired long-term memory for large language models. InConference on Neural Information Processing Systems (NeurIPS), 2024. URL https://arxiv.org/abs/ 2405.14831. 10
-
[12]
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. DeBERTa: Decoding-enhanced BERT with disentangled attention. InInternational Conference on Learning Representations (ICLR), 2021. URLhttps://arxiv.org/abs/2006.03654
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
Liger-kernel: Efficient triton kernels for LLM training, 2024
Pin-Lun Hsu, Yun Dai, Vignesh Kothapalli, Qingquan Song, Shao Tang, Siyu Zhu, Steven Shimizu, Shivam Sahni, Haowen Ning, and Yanning Chen. Liger-kernel: Efficient triton kernels for LLM training, 2024. URLhttps://arxiv.org/abs/2410.10989. arXiv preprint arXiv:2410.10989
-
[14]
Xiang Hu, Hongyu Fu, Jinge Wang, Yifeng Wang, Zhikun Li, Renjun Xu, Yuhao Lu, Yaochu Jin, Lili Pan, and Zhenzhong Lan. Nova: An iterative planning and search approach to enhance novelty and diversity of LLM generated ideas, 2024. URL https://arxiv.org/abs/2410. 14255. arXiv preprint arXiv:2410.14255
-
[15]
Rodney Kinney, Chloe Anastasiades, Russell Authur, Iz Beltagy, Jonathan Bragg, Alexandra Buraczynski, Isabel Cachola, Stefan Candra, Yoganand Chandrasekhar, Arman Cohan, Miles Crawford, Doug Downey, Jason Dunkelberger, Oren Etzioni, Rob Evans, Sergey Feldman, Joseph Gorney, David Graham, Fangzhou Hu, Regan Huff, Daniel King, Sebastian Kohlmeier, Bailey Ku...
-
[16]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with PagedAttention. InACM Symposium on Operating Systems Principles (SOSP), 2023. URLhttps://arxiv.org/abs/2309.06180
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Chain of ideas: Revolutionizing research in idea development with LLM agents
Long Li, Weiwen Xu, Jiayan Guo, Ruochen Zhao, Xinxuan Li, Yuqian Yuan, Boqiang Zhang, Yuming Jiang, Yifei Xin, Ronghao Dang, Yu Rong, Deli Zhao, Tian Xu, and Lidong Bing. Chain of ideas: Revolutionizing research in idea development with LLM agents. InInternational Conference on Learning Representations (ICLR), 2025. URL https://arxiv.org/abs/ 2410.13185
-
[18]
ROUGE: A package for automatic evaluation of summaries
Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. InText Summariza- tion Branches Out (Workshop at ACL), pages 74–81, 2004
2004
-
[19]
KAN: Kolmogorov-Arnold Networks
Ziming Liu, Yixuan Wang, Sachin Vaidya, Fabian Ruehle, James Halverson, Marin Soljaˇci´c, Thomas Y . Hou, and Max Tegmark. KAN: Kolmogorov-Arnold networks, 2024. URLhttps: //arxiv.org/abs/2404.19756. arXiv preprint arXiv:2404.19756
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Patrice Lopez. GROBID: Combining automatic bibliographic data recognition and term extrac- tion for scholarship publications. InResearch and Advanced Technology for Digital Libraries (ECDL), pages 473–474. Springer, 2009. doi: 10.1007/978-3-642-04346-8\_62. Software: https://github.com/kermitt2/grobid
-
[21]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The AI scientist: Towards fully automated open-ended scientific discovery, 2024. URL https: //arxiv.org/abs/2408.06292. arXiv preprint arXiv:2408.06292
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
SWE-Lancer: Can frontier LLMs earn $1 million from real-world freelance software engineering?, 2025
Samuel Miserendino, Michele Wang, Tejal Patwardhan, and Johannes Heidecke. SWE-Lancer: Can frontier LLMs earn $1 million from real-world freelance software engineering?, 2025. URL https://arxiv.org/abs/2502.12115. arXiv preprint arXiv:2502.12115
-
[23]
Agent Laboratory: Using LLM Agents as Research Assistants
Samuel Schmidgall, Yusheng Su, Ze Wang, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Michael Moor, Zicheng Liu, and Emad Barsoum. Agent laboratory: Using LLM agents as research assistants, 2025. URL https://arxiv.org/abs/2501.04227. arXiv preprint arXiv:2501.04227. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Can LLMs generate novel research ideas? A large-scale human study with 100+ NLP researchers
Chenglei Si, Diyi Yang, and Tatsunori Hashimoto. Can LLMs generate novel research ideas? A large-scale human study with 100+ NLP researchers. InInternational Conference on Learning Representations (ICLR), 2025. URL https://arxiv.org/abs/2409.04109. arXiv preprint arXiv:2409.04109, 2024
-
[25]
SciRepE- val: A multi-format benchmark for scientific document representations
Amanpreet Singh, Mike D’Arcy, Arman Cohan, Doug Downey, and Sergey Feldman. SciRepE- val: A multi-format benchmark for scientific document representations. InConference on Empirical Methods in Natural Language Processing (EMNLP), 2023. URL https: //arxiv.org/abs/2211.13308. Introduces SPECTER2 embedding family
-
[26]
Haoyang Su, Renqi Chen, Shixiang Tang, Xinzhe Zheng, Jingzhi Li, Zhenfei Yin, Wanli Ouyang, and Nanqing Dong. Two heads are better than one: A multi-agent system has the potential to improve scientific idea generation, 2024. URL https://arxiv.org/abs/2410.09403. arXiv preprint arXiv:2410.09403
-
[27]
Don R. Swanson. Fish oil, Raynaud’s syndrome, and undiscovered public knowledge.Perspec- tives in Biology and Medicine, 30(1):7–18, 1986
1986
-
[28]
AGATHA: Automatic graph mining and transformer based hypothesis generation approach
Justin Sybrandt, Ilya Tyagin, Michael Shtutman, and Ilya Safro. AGATHA: Automatic graph mining and transformer based hypothesis generation approach. InACM Interna- tional Conference on Information and Knowledge Management (CIKM), 2020. URL https: //arxiv.org/abs/2002.05635
-
[29]
GraphGPT: Graph instruction tuning for large language models
Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, and Chao Huang. GraphGPT: Graph instruction tuning for large language models. InACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), 2024. URL https://arxiv.org/abs/2310.13023
-
[30]
AI-researcher: Autonomous scientific innovation, 2025
Jiabin Tang, Lianghao Xia, Zhonghang Li, and Chao Huang. AI-researcher: Autonomous scientific innovation, 2025. URL https://arxiv.org/abs/2505.18705. arXiv preprint arXiv:2505.18705
-
[31]
SciMON: Scientific inspiration machines optimized for novelty
Qingyun Wang, Doug Downey, Heng Ji, and Tom Hope. SciMON: Scientific inspiration machines optimized for novelty. InAnnual Meeting of the Association for Computational Linguistics (ACL), 2024. URLhttps://arxiv.org/abs/2305.14259
-
[32]
FlowPIE: Test-time scientific idea evolution with flow-guided literature exploration
Qiyao Wang, Hongbo Wang, Longze Chen, Zhihao Yang, Guhong Chen, Hamid Alinejad- Rokny, Hui Li, Yuan Lin, and Min Yang. FlowPIE: Test-time scientific idea evolution with flow-guided literature exploration. arXiv preprint arXiv:2603.29557, 2026. URL https: //arxiv.org/abs/2603.29557
-
[33]
CycleResearcher: Improving automated research via automated review, 2025
Yixuan Weng, Minjun Zhu, Guangsheng Bao, Hongbo Zhang, Jindong Wang, Yue Zhang, and Linyi Yang. CycleResearcher: Improving automated research via automated review, 2025. URL https://arxiv.org/abs/2411.00816. arXiv preprint arXiv:2411.00816
-
[34]
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. The AI scientist-v2: Workshop-level automated scientific discovery via agentic tree search, 2025. URL https://arxiv.org/abs/2504.08066. arXiv preprint arXiv:2504.08066
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2.5 technical report, 2024. URL https://arxiv.org/abs/2412.15115. arXiv preprint arXiv:2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model?arXiv preprint arXiv:2504.13837, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
BERTScore: Evaluating Text Generation with BERT
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. BERTScore: Evaluating text generation with BERT. InInternational Conference on Learning Representations (ICLR), 2020. URLhttps://arxiv.org/abs/1904.09675. 12
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[38]
AbGen: Evaluating large language models in ablation study design and evaluation for scientific research
Yilun Zhao, Weiyuan Chen, Zhijian Xu, Manasi Patwardhan, Chengye Wang, Yixin Liu, Lovekesh Vig, and Arman Cohan. AbGen: Evaluating large language models in ablation study design and evaluation for scientific research. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL, Volume 1: Long Papers), pages 12479–12491, 2025
2025
-
[39]
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
Terry Yue Zhuo, Minh Chien Vu, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, Imam Nur Bani Yusuf, Haolan Zhan, Junda He, Indraneil Paul, Simon Brunner, Chen Gong, Thong Hoang, Armel Randy Zebaze, Xiaoheng Hong, Wen-Ding Li, Jean Kaddour, Ming Xu, Zhihan Zhang, Prateek Yadav, Naman Jain, Alex Gu, Zhoujun Cheng, Jiawei Liu, Qian Liu, Zijian Wang, Davi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.