SceneParser: Hierarchical Scene Parsing for Visual Semantics Understanding
Pith reviewed 2026-06-30 20:50 UTC · model grok-4.3
The pith
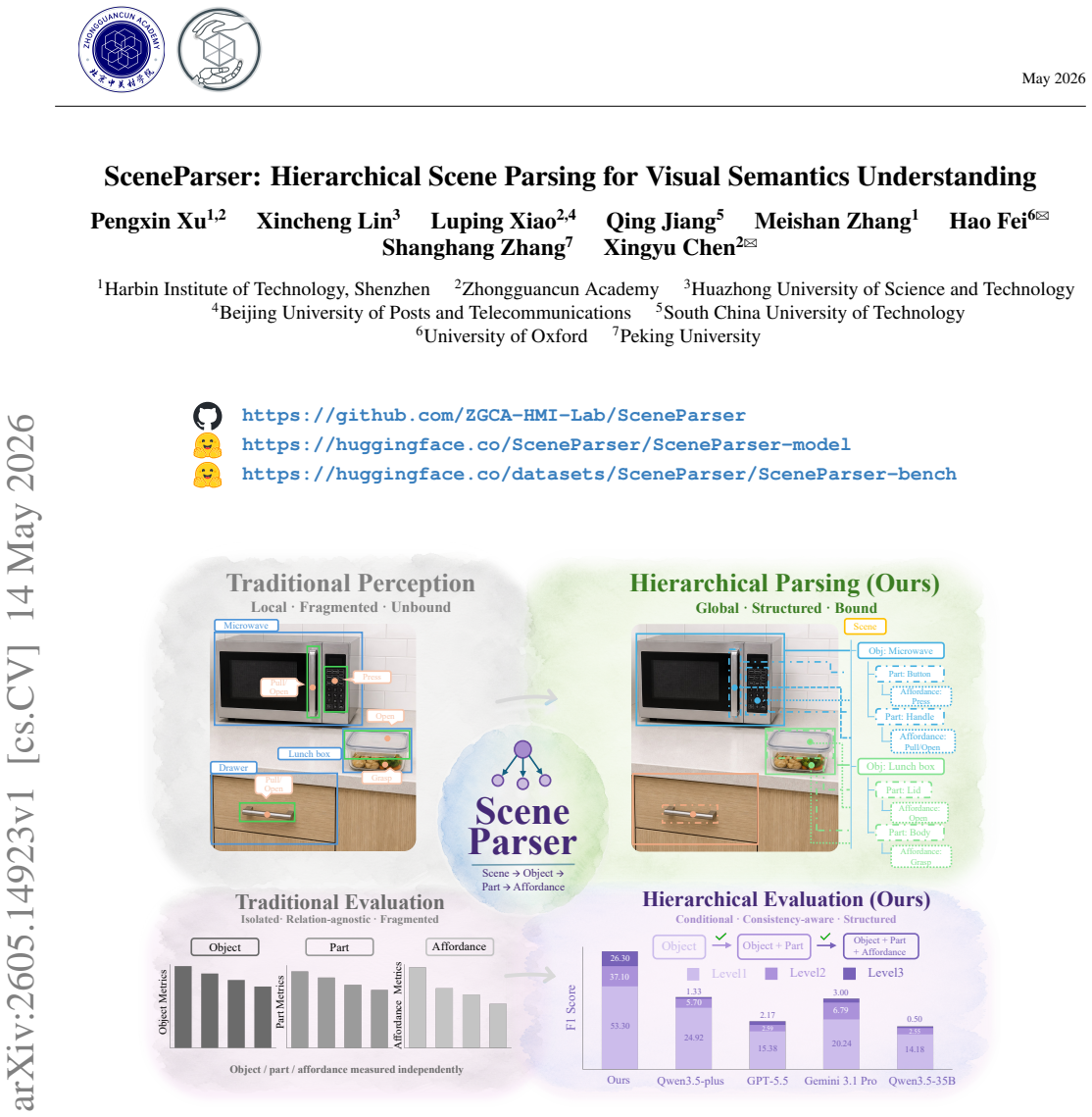
SceneParser generates explicit scene-object-part-affordance hierarchies with cross-level bindings in one unified pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
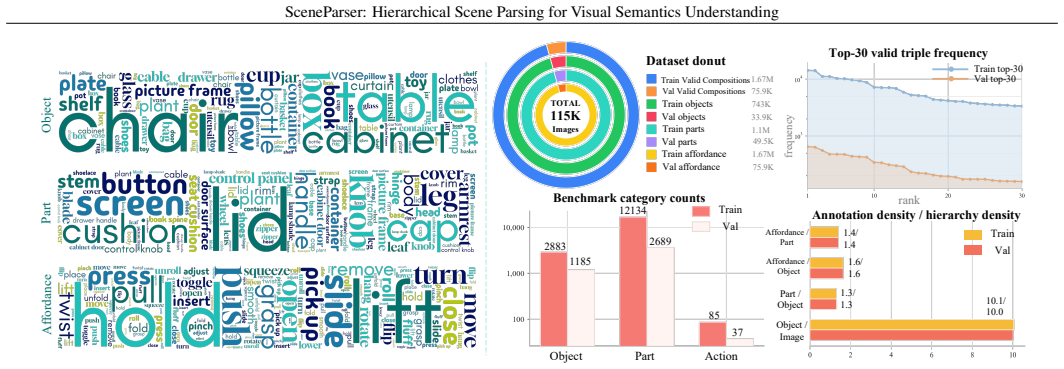
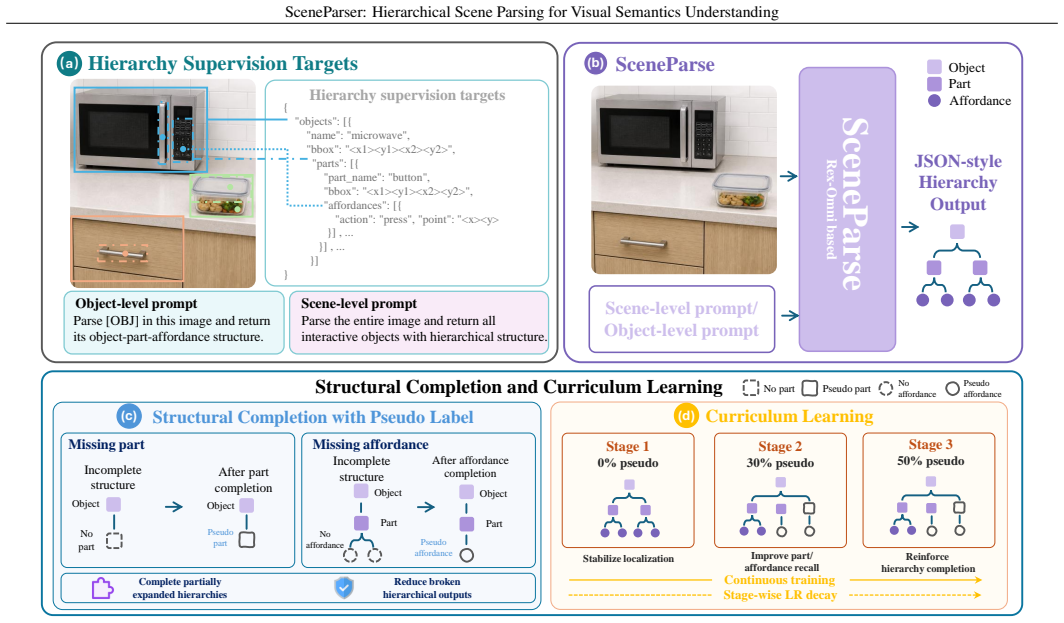
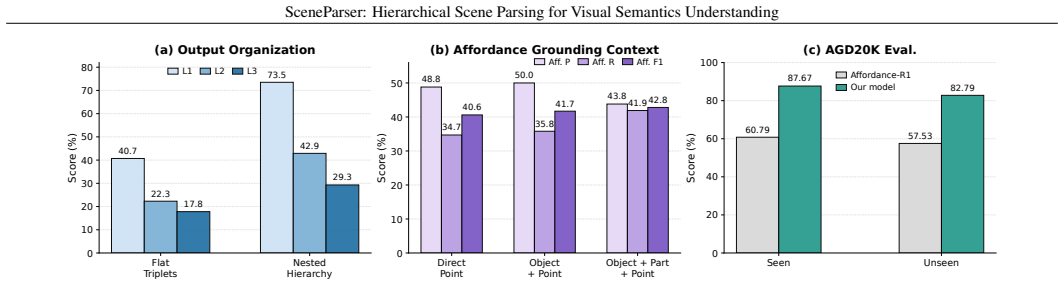
SceneParser is a VLM-based parser trained for unified hierarchical generation of scene-to-object-to-part-to-affordance structures. It relies on structural-completion pseudo labels produced by a scalable data engine together with curriculum learning, and it is evaluated with Level-1 to Level-3 conditional metrics plus ParseRate that separately score localization, cross-level binding, and hierarchical completeness. On the resulting SceneParser-Bench the model outperforms existing MLLMs and perception-stitching pipelines while also transferring to COCO and AGD20K and supporting downstream planning.
What carries the argument
unified hierarchical generation driven by structural-completion pseudo labels and curriculum learning
If this is right
- SceneParser produces stronger localization, binding, and completeness scores than existing MLLMs on the SceneParser-Bench.
- The same model remains compatible with conventional object detection and affordance tasks on COCO and AGD20K.
- The generated hierarchies supply an actionable representation that improves performance in a downstream visual planning probe.
- Level-1 to Level-3 conditional metrics together with ParseRate isolate the separate contributions of localization and cross-level structure.
Where Pith is reading between the lines
- Robotic systems could use the explicit chains to plan multi-step interactions without separately querying each perception module.
- The hierarchical data engine could be reused to annotate other scene-understanding datasets that currently lack part-affordance links.
- Training on full hierarchies may reduce error propagation in longer visual-reasoning chains compared with post-hoc stitching of separate models.
Load-bearing premise
The structural-completion pseudo labels produced by the hierarchical data engine correctly capture real-world cross-level bindings and affordances without systematic labeling errors.
What would settle it
If retraining SceneParser on the same images but with randomly shuffled or human-corrected object-part-affordance chains yields identical scores on the Level-1 to Level-3 metrics and ParseRate, the contribution of the pseudo-label engine would be falsified.
Figures



read the original abstract
General scene perception has progressed from object recognition toward open-vocabulary grounding, part localization, and affordance prediction. Yet these capabilities are often realized as isolated predictions that localize objects, parts, or interaction points without capturing the structured dependencies needed for interaction-oriented scene understanding. To address this gap, we introduce Hierarchical Scene Parsing, an interaction-oriented parsing task that represents physical scenes as explicit scene -> object -> part -> affordance hierarchies with cross-level bindings. We instantiate this task with SceneParser, a VLM-based parser trained for unified hierarchical generation with structural-completion pseudo labels and curriculum learning. To support training and evaluation, we construct SceneParser-Bench, a large-scale benchmark built with a scalable hierarchical data engine, containing 110K training images, a 5K validation split, 777K objects, 1.14M parts, 1.74M affordance annotations, and 1.74M valid object-part-affordance chain instances. We further introduce Level-1 to Level-3 conditional metrics and ParseRate to evaluate localization, cross-level binding, and hierarchical completeness. Experiments show that existing MLLMs and perception-stitching pipelines struggle with hierarchical parsing on our SceneParser-Bench, while SceneParser achieves stronger structure-aware performance. Besides, ablations, evaluations on COCO and AGD20K, and a downstream planning probe demonstrate that our SceneParser is compatible with conventional tasks and provides an actionable representation for visual understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Hierarchical Scene Parsing as a task that represents scenes via explicit scene→object→part→affordance hierarchies with cross-level bindings. It presents SceneParser, a VLM trained with structural-completion pseudo labels and curriculum learning, and constructs SceneParser-Bench (110K training images, 5K validation split, 777K objects, 1.14M parts, 1.74M affordance annotations) via a scalable hierarchical data engine. Experiments claim that existing MLLMs and perception-stitching pipelines underperform on Level-1/Level-2/Level-3 conditional metrics and ParseRate, while SceneParser shows stronger structure-aware results; additional ablations, COCO/AGD20K evaluations, and a downstream planning probe are reported to show compatibility with conventional tasks.
Significance. If the gains on SceneParser-Bench reflect improved capture of real physical structure rather than replication of the data engine, the work could advance interaction-oriented scene representations for robotics and planning. The scale of the introduced benchmark and the new hierarchical metrics constitute a concrete contribution, and the external evaluations plus planning probe provide some grounding beyond the synthetic data.
major comments (2)
- [Abstract; SceneParser-Bench construction] Abstract (benchmark construction paragraph) and § on SceneParser-Bench: both the 110K training images and the 5K validation split are generated by the same 'scalable hierarchical data engine' that supplies the structural-completion pseudo labels used for training. No independent human ground truth is described for cross-level bindings or affordance chains. This makes the reported superiority on Level-1/2/3 metrics and ParseRate potentially circular, as higher scores may indicate better mimicry of the engine's labeling distribution rather than superior modeling of real-world scene structure.
- [Abstract; experimental results] Abstract (experiments paragraph): the central claim that 'SceneParser achieves stronger structure-aware performance' rests on comparisons whose quantitative values, baseline implementations, error bars, and ablation tables are not supplied in the abstract and must be verified against the full experimental section to confirm they are not driven by the shared data-generation process.
minor comments (1)
- [Abstract] The abstract states performance improvements without any numerical values, making the strength of the result difficult to gauge from the summary alone.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment below, indicating where revisions will be made to improve clarity and transparency.
read point-by-point responses
-
Referee: [Abstract; SceneParser-Bench construction] Abstract (benchmark construction paragraph) and § on SceneParser-Bench: both the 110K training images and the 5K validation split are generated by the same 'scalable hierarchical data engine' that supplies the structural-completion pseudo labels used for training. No independent human ground truth is described for cross-level bindings or affordance chains. This makes the reported superiority on Level-1/2/3 metrics and ParseRate potentially circular, as higher scores may indicate better mimicry of the engine's labeling distribution rather than superior modeling of real-world scene structure.
Authors: We agree that both the training and validation portions of SceneParser-Bench are produced by the same hierarchical data engine used to generate pseudo labels, and that the manuscript does not describe independent human ground truth for the cross-level bindings or affordance chains. This creates a legitimate risk that performance gains reflect fidelity to the engine's labeling process rather than improved modeling of physical scene structure. We will revise the benchmark section and results discussion to explicitly acknowledge this limitation, describe the design principles of the data engine, and note that future work should include human validation. revision_made = 'yes'. revision: yes
-
Referee: [Abstract; experimental results] Abstract (experiments paragraph): the central claim that 'SceneParser achieves stronger structure-aware performance' rests on comparisons whose quantitative values, baseline implementations, error bars, and ablation tables are not supplied in the abstract and must be verified against the full experimental section to confirm they are not driven by the shared data-generation process.
Authors: The abstract provides only a high-level summary of the experimental outcomes. All quantitative results, baseline details, error bars, ablation studies, COCO/AGD20K evaluations, and the planning probe are reported in the full experimental section. The manuscript already contains the supporting tables and analysis needed to substantiate the claims. No changes to the abstract are necessary, though we can add a cross-reference if desired. revision_made = 'no'. revision: no
- Absence of independent human ground-truth annotations for cross-level bindings and affordance chains in SceneParser-Bench; addressing this would require a separate large-scale human annotation campaign outside the current scope.
Circularity Check
No significant circularity; empirical evaluation on synthetic benchmark with external dataset support
full rationale
The paper describes an empirical VLM-based model trained with structural-completion pseudo labels from a hierarchical data engine and evaluated on SceneParser-Bench constructed from the same engine, plus ablations and results on external datasets COCO and AGD20K. No equations, fitted parameters, derivations, or self-citation chains are present in the abstract or described claims. Performance is presented as direct comparison rather than any reduction of outputs to inputs by construction. This is a standard empirical ML setup with no load-bearing circular steps matching the enumerated patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The pascal visual object classes (voc) challenge.IJCV, 2010
Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge.IJCV, 2010
2010
-
[2]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InECCV, 2014
2014
-
[3]
Scene parsing through ade20k dataset
Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ade20k dataset. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition(CVPR), 2017
2017
-
[4]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control, 2023.URL https://arxiv. org/abs/2307.15818, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Openeqa: Embodied question answering in the era of foundation models
Arjun Majumdar, Anurag Ajay, Xiaohan Zhang, Pranav Putta, Sriram Yenamandra, Mikael Henaff, Sneha Silwal, Paul Mcvay, Oleksandr Maksymets, Sergio Arnaud, et al. Openeqa: Embodied question answering in the era of foundation models. InProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition(CVPR), 2024
2024
-
[6]
Embodiedscan: A holistic multi-modal 3d perception suite towards embodied ai
Tai Wang, Xiaohan Mao, Chenming Zhu, Runsen Xu, Ruiyuan Lyu, Peisen Li, Xiao Chen, Wenwei Zhang, Kai Chen, Tianfan Xue, et al. Embodiedscan: A holistic multi-modal 3d perception suite towards embodied ai. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), 2024
2024
-
[7]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuropean conference on computer vision(ECCV), 2024
2024
-
[8]
Tianhe Ren, Qing Jiang, Shilong Liu, Zhaoyang Zeng, Wenlong Liu, Han Gao, Hongjie Huang, Zhengyu Ma, Xi- aoke Jiang, Yihao Chen, et al. Grounding dino 1.5: Advance the edge of open-set object detection.arXiv preprint arXiv:2405.10300, 2024
-
[9]
Yolo-world: Real-time open- vocabulary object detection
Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xinggang Wang, and Ying Shan. Yolo-world: Real-time open- vocabulary object detection. InProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recogni- tion(CVPR), 2024
2024
-
[10]
Florence-2: Advancing a unified representation for a variety of vision tasks
Bin Xiao, Haiping Wu, Weijian Xu, Xiyang Dai, Houdong Hu, Yumao Lu, Michael Zeng, Ce Liu, and Lu Yuan. Florence-2: Advancing a unified representation for a variety of vision tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), 2024
2024
-
[11]
Llmdet: Learning strong open-vocabulary object detectors under the supervision of large language models
Shenghao Fu, Qize Yang, Qijie Mo, Junkai Yan, Xihan Wei, Jingke Meng, Xiaohua Xie, and Wei-Shi Zheng. Llmdet: Learning strong open-vocabulary object detectors under the supervision of large language models. InProceedings of the Computer Vision and Pattern Recognition Conference, 2025
2025
-
[12]
Towards visual grounding: A survey
Linhui Xiao, Xiaoshan Yang, Xiangyuan Lan, Yaowei Wang, and Changsheng Xu. Towards visual grounding: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence(TPAMI), 2025
2025
-
[13]
Grounded language-image pre-training
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, et al. Grounded language-image pre-training. InProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition(CVPR), 2022
2022
-
[14]
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. Shikra: Unleashing multimodal llm’s referential dialogue magic.arXiv preprint arXiv:2306.15195, 2023. 11 SceneParser: Hierarchical Scene Parsing for Visual Semantics Understanding
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Haotian Zhang, Haoxuan You, Philipp Dufter, Bowen Zhang, Chen Chen, Hong-You Chen, Tsu-Jui Fu, William Yang Wang, Shih-Fu Chang, Zhe Gan, et al. Ferret-v2: An improved baseline for referring and grounding with large language models.arXiv preprint arXiv:2404.07973, 2024
-
[16]
Groma: Localized visual tokenization for grounding multimodal large language models
Chuofan Ma, Yi Jiang, Jiannan Wu, Zehuan Yuan, and Xiaojuan Qi. Groma: Localized visual tokenization for grounding multimodal large language models. InEuropean Conference on Computer Vision(ECCV), 2024
2024
-
[17]
Qing Jiang, Gen Luo, Yuqin Yang, Yuda Xiong, Yihao Chen, Zhaoyang Zeng, Tianhe Ren, and Lei Zhang. Chatrex: Taming multimodal llm for joint perception and understanding.arXiv preprint arXiv:2411.18363, 2024
-
[18]
Detect anything via next point prediction.arXiv preprint arXiv:2510.12798, 2025
Qing Jiang, Junan Huo, Xingyu Chen, Yuda Xiong, Zhaoyang Zeng, Yihao Chen, Tianhe Ren, Junzhi Yu, and Lei Zhang. Detect anything via next point prediction.arXiv preprint arXiv:2510.12798, 2025
-
[19]
VGR: Visual Grounded Reasoning
Jiacong Wang, Zijian Kang, Haochen Wang, Haiyong Jiang, Jiawen Li, Bohong Wu, Ya Wang, Jiao Ran, Xiao Liang, Chao Feng, et al. Vgr: Visual grounded reasoning.arXiv preprint arXiv:2506.11991, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Partimagenet: A large, high-quality dataset of parts
Ju He, Shuo Yang, Shaokang Yang, Adam Kortylewski, Xiaoding Yuan, Jie-Neng Chen, Shuai Liu, Cheng Yang, Qihang Yu, and Alan Yuille. Partimagenet: A large, high-quality dataset of parts. InEuropean Conference on Computer Vision(ECCV), 2022
2022
-
[21]
Paco: Parts and attributes of common objects
Vignesh Ramanathan, Anmol Kalia, Vladan Petrovic, Yi Wen, Baixue Zheng, Baishan Guo, Rui Wang, Aaron Marquez, Rama Kovvuri, Abhishek Kadian, et al. Paco: Parts and attributes of common objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), 2023
2023
-
[22]
Learning affordance grounding from exocentric images
Hongchen Luo, Wei Zhai, Jing Zhang, Yang Cao, and Dacheng Tao. Learning affordance grounding from exocentric images. InProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, 2022
2022
-
[23]
Affordancellm: Grounding affordance from vision language models
Shengyi Qian, Weifeng Chen, Min Bai, Xiong Zhou, Zhuowen Tu, and Li Erran Li. Affordancellm: Grounding affordance from vision language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), 2024
2024
-
[24]
Wentao Yuan, Jiafei Duan, Valts Blukis, Wilbert Pumacay, Ranjay Krishna, Adithyavairavan Murali, Arsalan Mousavian, and Dieter Fox. Robopoint: A vision-language model for spatial affordance prediction for robotics.arXiv preprint arXiv:2406.10721, 2024
-
[25]
Affordance-r1: Reinforcement learning for generalizable affordance reasoning in multimodal large language models
Hanqing Wang, Shaoyang Wang, Yiming Zhong, Zemin Yang, Jiamin Wang, Zhiqing Cui, Jiahao Yuan, Yifan Han, Mingyu Liu, and Yuexin Ma. Affordance-r1: Reinforcement learning for generalizable affordance reasoning in multimodal large language models. InProceedings of the AAAI Conference on Artificial Intelligence(AAAI), 2026
2026
-
[26]
Jianhua Sun and Cewu Lu. Digital gene: Learning about the physical world through analytic concepts.arXiv preprint arXiv:2504.04170, 2025
-
[27]
Yadong Lu, Jianwei Yang, Yelong Shen, and Ahmed Awadallah. Omniparser for pure vision based gui agent.arXiv preprint arXiv:2408.00203, 2024
-
[28]
Jiacheng Hua, Yishu Yin, Yuhang Wu, Tai Wang, Yifei Huang, and Miao Liu. Unleashing spatial reasoning in multimodal large language models via textual representation guided reasoning.arXiv preprint arXiv:2603.23404, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Thinking with visual primitives
Ruijie Lu, Yiyang Ma, Xiaokang Chen, Lingxiao Luo, Zhiyu Wu, Zizheng Pan, Xingchao Liu, Yutong Lin, Hao Li, Wen Liu, Zhewen Hao, Xi Gao, Shaoheng Nie, Yixuan Wei, Zhenda Xie, Ting Chen, and Gang Zeng. Thinking with visual primitives. https://github.com/deepseek-ai/Thinking-with-Visual-Primitives , 2026. Technical report
2026
-
[30]
You only look once: Unified, real-time object detection
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition(CVPR), 2016. 12 SceneParser: Hierarchical Scene Parsing for Visual Semantics Understanding
2016
-
[31]
Faster r-cnn: Towards real-time object detection with region proposal networks.Advances in Neural Information Processing Systems, 2015
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks.Advances in Neural Information Processing Systems, 2015
2015
-
[32]
End-to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. InEuropean conference on computer vision(ECCV), 2020
2020
-
[33]
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M Ni, and Heung-Yeung Shum. Dino: Detr with improved denoising anchor boxes for end-to-end object detection.arXiv preprint arXiv:2203.03605, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[34]
Tianhe Ren, Yihao Chen, Qing Jiang, Zhaoyang Zeng, Yuda Xiong, Wenlong Liu, Zhengyu Ma, Junyi Shen, Yuan Gao, Xiaoke Jiang, et al. Dino-x: A unified vision model for open-world object detection and understanding.arXiv preprint arXiv:2411.14347, 2024
-
[35]
Yoloe: Real-time seeing anything
Ao Wang, Lihao Liu, Hui Chen, Zijia Lin, Jungong Han, and Guiguang Ding. Yoloe: Real-time seeing anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision(ICCV), 2025
2025
-
[36]
T-rex2: Towards generic object detection via text-visual prompt synergy
Qing Jiang, Feng Li, Zhaoyang Zeng, Tianhe Ren, Shilong Liu, and Lei Zhang. T-rex2: Towards generic object detection via text-visual prompt synergy. InEuropean Conference on Computer Vision(ECCV), 2024
2024
-
[37]
Scaling open-vocabulary object detection.Advances in Neural Information Processing Systems(NeuIPS), 2023
Matthias Minderer, Alexey Gritsenko, and Neil Houlsby. Scaling open-vocabulary object detection.Advances in Neural Information Processing Systems(NeuIPS), 2023
2023
-
[38]
Language-conditioned detection transformer
Jang Hyun Cho and Philipp Krähenbühl. Language-conditioned detection transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), 2024
2024
-
[39]
arXiv preprint arXiv:2109.10852 , year=
Ting Chen, Saurabh Saxena, Lala Li, David J Fleet, and Geoffrey Hinton. Pix2seq: A language modeling framework for object detection.arXiv preprint arXiv:2109.10852, 2021
-
[40]
Kosmos-2: Grounding Multimodal Large Language Models to the World
Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Grounding multimodal large language models to the world.arXiv preprint arXiv:2306.14824, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Ferret: Refer and Ground Anything Anywhere at Any Granularity
Haoxuan You, Haotian Zhang, Zhe Gan, Xianzhi Du, Bowen Zhang, Zirui Wang, Liangliang Cao, Shih-Fu Chang, and Yinfei Yang. Ferret: Refer and ground anything anywhere at any granularity.arXiv preprint arXiv:2310.07704, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Glamm: Pixel grounding large multimodal model
Hanoona Rasheed, Muhammad Maaz, Sahal Shaji, Abdelrahman Shaker, Salman Khan, Hisham Cholakkal, Rao M Anwer, Eric Xing, Ming-Hsuan Yang, and Fahad S Khan. Glamm: Pixel grounding large multimodal model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), 2024
2024
-
[43]
Lisa: Reasoning segmentation via large language model
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia. Lisa: Reasoning segmentation via large language model. InProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition(CVPR), 2024
2024
-
[44]
Detect what you can: Detecting and representing objects using holistic models and body parts
Xianjie Chen, Roozbeh Mottaghi, Xiaobai Liu, Sanja Fidler, Raquel Urtasun, and Alan Yuille. Detect what you can: Detecting and representing objects using holistic models and body parts. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2014
2014
-
[45]
Going denser with open- vocabulary part segmentation
Peize Sun, Shoufa Chen, Chenchen Zhu, Fanyi Xiao, Ping Luo, Saining Xie, and Zhicheng Yan. Going denser with open- vocabulary part segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision(ICCV), 2023
2023
-
[46]
Understanding multi-granularity for open- vocabulary part segmentation.Advances in Neural Information Processing Systems, 2024
Jiho Choi, Seonho Lee, Seungho Lee, Minhyun Lee, and Hyunjung Shim. Understanding multi-granularity for open- vocabulary part segmentation.Advances in Neural Information Processing Systems, 2024
2024
-
[47]
Partglee: A foundation model for recognizing and parsing any objects
Junyi Li, Junfeng Wu, Weizhi Zhao, Song Bai, and Xiang Bai. Partglee: A foundation model for recognizing and parsing any objects. InEuropean Conference on Computer Vision(ECCV), 2024. 13 SceneParser: Hierarchical Scene Parsing for Visual Semantics Understanding
2024
-
[48]
Instructpart: Task-oriented part segmentation with instruction reasoning
Zifu Wan, Yaqi Xie, Ce Zhang, Zhiqiu Lin, Zihan Wang, Simon Stepputtis, Deva Ramanan, and Katia P Sycara. Instructpart: Task-oriented part segmentation with instruction reasoning. InProceedings of the Meeting of the Association for Computational Linguistics, 2025
2025
-
[49]
Affordance detection of tool parts from geometric features
Austin Myers, Ching L Teo, Cornelia Fermüller, and Yiannis Aloimonos. Affordance detection of tool parts from geometric features. InIEEE international conference on robotics and automation(ICRA), 2015
2015
-
[50]
Object-based affordances detection with convolutional neural networks and dense conditional random fields
Anh Nguyen, Dimitrios Kanoulas, Darwin G Caldwell, and Nikos G Tsagarakis. Object-based affordances detection with convolutional neural networks and dense conditional random fields. InIEEE/RSJ International Conference on Intelligent Robots and Systems(IROS), 2017
2017
-
[51]
Maskprompt: open-vocabulary affordance segmentation with object shape mask prompts
Dongpan Chen, Dehui Kong, Jinghua Li, and Baocai Yin. Maskprompt: open-vocabulary affordance segmentation with object shape mask prompts. InProceedings of the AAAI Conference on Artificial Intelligence(AAAI), 2025
2025
-
[52]
Affordgrasp: In-context affordance reasoning for open-vocabulary task-oriented grasping in clutter
Yingbo Tang, Shuaike Zhang, Xiaoshuai Hao, Pengwei Wang, Jianlong Wu, Zhongyuan Wang, and Shanghang Zhang. Affordgrasp: In-context affordance reasoning for open-vocabulary task-oriented grasping in clutter. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems(IROS), 2025
2025
-
[53]
Xiaoshuai Hao, Yingbo Tang, Lingfeng Zhang, Yanbiao Ma, Yunfeng Diao, Ziyu Jia, Wenbo Ding, Hangjun Ye, and Long Chen. Roboafford++: A generative ai-enhanced dataset for multimodal affordance learning in robotic manipulation and navigation.arXiv preprint arXiv:2511.12436, 2025
-
[54]
Robobrain: A unified brain model for robotic manipulation from abstract to concrete
Yuheng Ji, Huajie Tan, Jiayu Shi, Xiaoshuai Hao, Yuan Zhang, Hengyuan Zhang, Pengwei Wang, Mengdi Zhao, Yao Mu, Pengju An, et al. Robobrain: A unified brain model for robotic manipulation from abstract to concrete. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), 2025
2025
-
[55]
Zixin Zhang, Kanghao Chen, Hanqing Wang, Hongfei Zhang, Harold Haodong Chen, Chenfei Liao, Litao Guo, and Ying-Cong Chen. A4-agent: An agentic framework for zero-shot affordance reasoning.arXiv preprint arXiv:2512.14442, 2025
-
[56]
Teli Ma, Jia Zheng, Zifan Wang, Ziyao Gao, Jiaming Zhou, and Junwei Liang. Glover++: Unleashing the potential of affordance learning from human behaviors for robotic manipulation.arXiv preprint arXiv:2505.11865, 2025
-
[57]
Hengshuo Chu, Xiang Deng, Qi Lv, Xiaoyang Chen, Yinchuan Li, Jianye Hao, and Liqiang Nie. 3d-affordancellm: Har- nessing large language models for open-vocabulary affordance detection in 3d worlds.arXiv preprint arXiv:2502.20041, 2025
-
[58]
Learning precise affordances from egocentric videos for robotic manipulation
Gen Li, Nikolaos Tsagkas, Jifei Song, Ruaridh Mon-Williams, Sethu Vijayakumar, Kun Shao, and Laura Sevilla- Lara. Learning precise affordances from egocentric videos for robotic manipulation. InProceedings of the IEEE/CVF International Conference on Computer Vision(ICCV), 2025
2025
-
[59]
Junha Lee, Eunha Park, Chunghyun Park, Dahyun Kang, and Minsu Cho. Affogato: Learning open-vocabulary affordance grounding with automated data generation at scale.arXiv preprint arXiv:2506.12009, 2025
-
[60]
Gpt-5 system card.https://openai.com/index/gpt-5-system-card/, 2025
OpenAI. Gpt-5 system card.https://openai.com/index/gpt-5-system-card/, 2025
2025
-
[61]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman Rädle, Triantafyllos Afouras, Effrosyni Mavroudi, Katherine Xu, Tsung-Han Wu, Yu Zhou, Liliane ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
Egoobjects: A large-scale egocentric dataset for fine-grained object understanding
Chenchen Zhu, Fanyi Xiao, Andrés Alvarado, Yasmine Babaei, Jiabo Hu, Hichem El-Mohri, Sean Culatana, Roshan Sumbaly, and Zhicheng Yan. Egoobjects: A large-scale egocentric dataset for fine-grained object understanding. In Proceedings of the IEEE/CVF international conference on computer vision(ICCV), 2023
2023
-
[63]
Curriculum learning
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. InProceedings of the International Conference on Machine Learning, 2009
2009
-
[64]
Self-paced learning for latent variable models.Advances in Neural Information Processing Systems(NeuIPS), 2010
M Kumar, Benjamin Packer, and Daphne Koller. Self-paced learning for latent variable models.Advances in Neural Information Processing Systems(NeuIPS), 2010
2010
-
[65]
Competence-based curriculum learning for neural machine translation
Emmanouil Antonios Platanios, Otilia Stretcu, Graham Neubig, Barnabas Poczos, and Tom Mitchell. Competence-based curriculum learning for neural machine translation. InProceedings of the conference of the North American chapter of the association for computational linguistics, 2019
2019
-
[66]
Llava-med: Training a large language-and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems(NeuIPS), 2023
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language-and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems(NeuIPS), 2023
2023
-
[67]
Curriculum learning with quality-driven data selection.arXiv preprint arXiv:2407.00102, 2024
Biao Wu and Ling Chen. Curriculum learning with quality-driven data selection.arXiv preprint arXiv:2407.00102, 2024
-
[68]
Gemini 3.1 pro model card
Google DeepMind. Gemini 3.1 pro model card. https://deepmind.google/models/model-cards/ gemini-3-1-pro/, 2026
2026
-
[69]
Qwen3.5: Towards native multimodal agents.https://qwen.ai/blog?id=qwen3.5, 2026
Qwen Team. Qwen3.5: Towards native multimodal agents.https://qwen.ai/blog?id=qwen3.5, 2026
2026
-
[70]
Shuai Bai, Keqin Chen, Xuejing Liu, et al. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[71]
Qwen Team. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[72]
Seed2.0 model card: Towards intelligence frontier for real-world complexity
ByteDance Seed Team. Seed2.0 model card: Towards intelligence frontier for real-world complexity. ByteDance Seed technical report, 2026
2026
-
[73]
Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jiawei Wang, et al. Seed1.5-vl technical report.arXiv preprint arXiv:2505.07062, 2025. 15 SceneParser: Hierarchical Scene Parsing for Visual Semantics Understanding A Formal Definition of Evaluation Metrics Overview.We provide the formal definition of ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
door”: “white door
Scene - level Object Grounding 1. Scene - level Object Description (GPT5) Scene - level object noun and referring expressions • “door”: “white door” • “ cookto p ” : “black cooktop” • “ socket ” : “white socket” • “ counte r ” : “kitchen counter with drawer” 2 . Object Grounding& Merging 2 . Object - level Part Parsing Object Bounding Box 3. Object Croppi...
-
[75]
whisk handl e
Affordance Parsing 7. Affordance Region D escription (GPT5) • “ whisk handl e ” • “ door handl e ” • “ rim of the bowl ” • “ s ocket button ” 8 . Affordance Segmentation (SAM3) Hierarchical Scene Scene | -- Object: Socket | | -- Bbox | | -- Part: Button | | | -- Bbox | | | -- Affordance | | | -- Action | | | -- Point | | -- Part: Button | | -- Bbox | | --...
-
[76]
Parse all visible interactive objects
-
[77]
If no valid object, return {"objects":[]}
-
[78]
Always include parts and affordances arrays (empty if none)
-
[79]
Do not output extra keys or explanations
-
[80]
string",
No placeholder literals like "string", "object", "part", "action". 19 SceneParser: Hierarchical Scene Parsing for Visual Semantics Understanding F Qualitative Visualization GT obj:glaves obj:stove part:stovetop part:stovetop part:handel obj:basket obj:bag obj:bottle obj:drawer obj:cupboard obj:drawer obj:spatula obj:rag obj:bowl obj:ladle obj:mixer part:h...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.