Octopus: History-Free Gradient Orthogonalization for Continual Learning in Multimodal Large Language Models
Pith reviewed 2026-06-30 20:54 UTC · model grok-4.3
The pith
Octopus achieves continual learning in multimodal LLMs by enforcing gradient orthogonality without historical data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
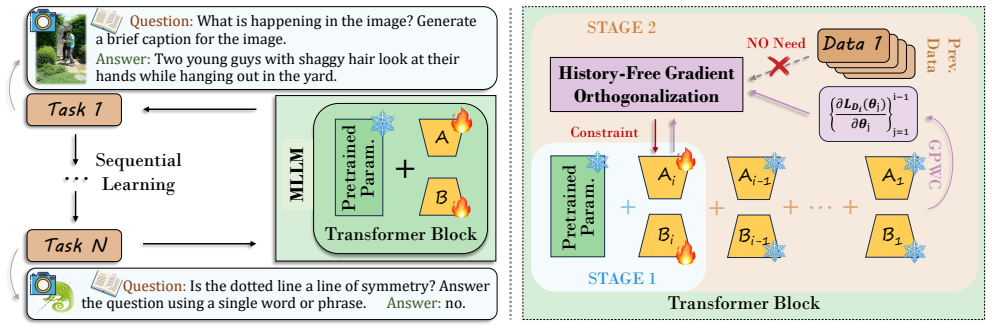
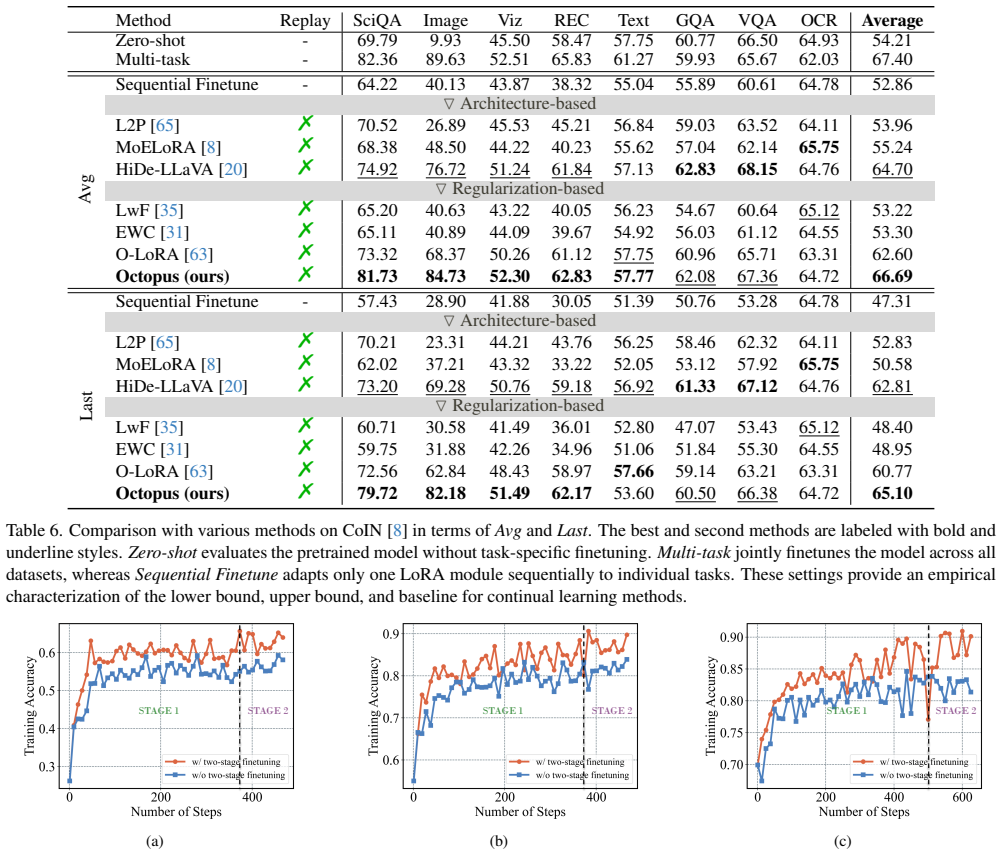
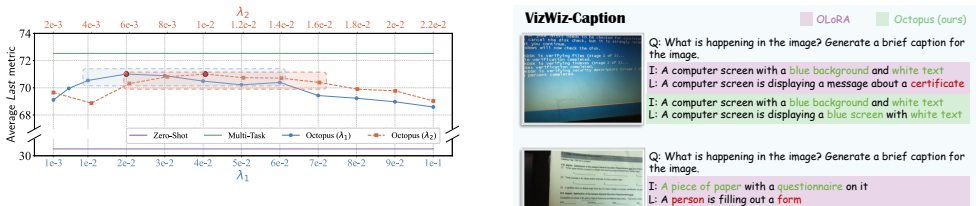
Octopus establishes that a two-stage finetuning strategy based on History-Free Gradient Orthogonalization (HiFGO) can enforce gradient-level orthogonality without historical task data, decoupling task adaptation from regularization to achieve a balance between plasticity and stability in multimodal large language models, leading to state-of-the-art performance on UCIT with improvements of 2.14% in average and 6.82% in last metrics.
What carries the argument
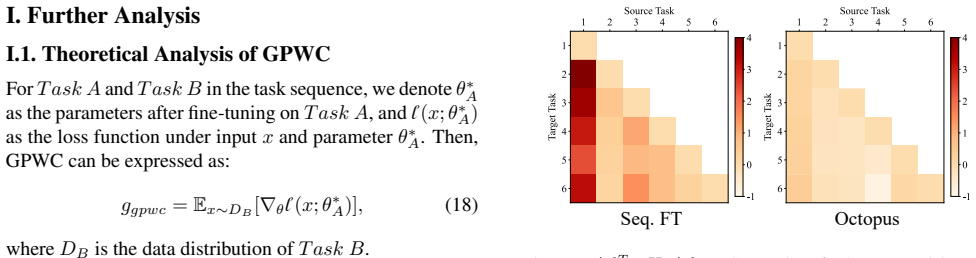
History-Free Gradient Orthogonalization (HiFGO), a mechanism that makes current task gradients orthogonal to those of previous tasks without accessing stored data.
Load-bearing premise
Enforcing gradient-level orthogonality without any historical task data is sufficient to prevent parameter interference and achieve stable balance between plasticity and stability.
What would settle it
A demonstration that models trained with HiFGO still suffer substantial catastrophic forgetting on earlier tasks despite orthogonal gradients.
Figures

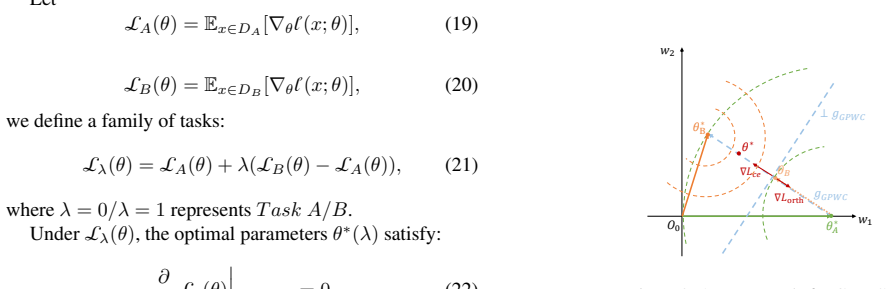

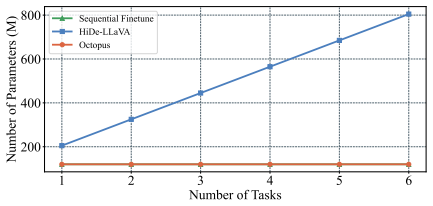
read the original abstract
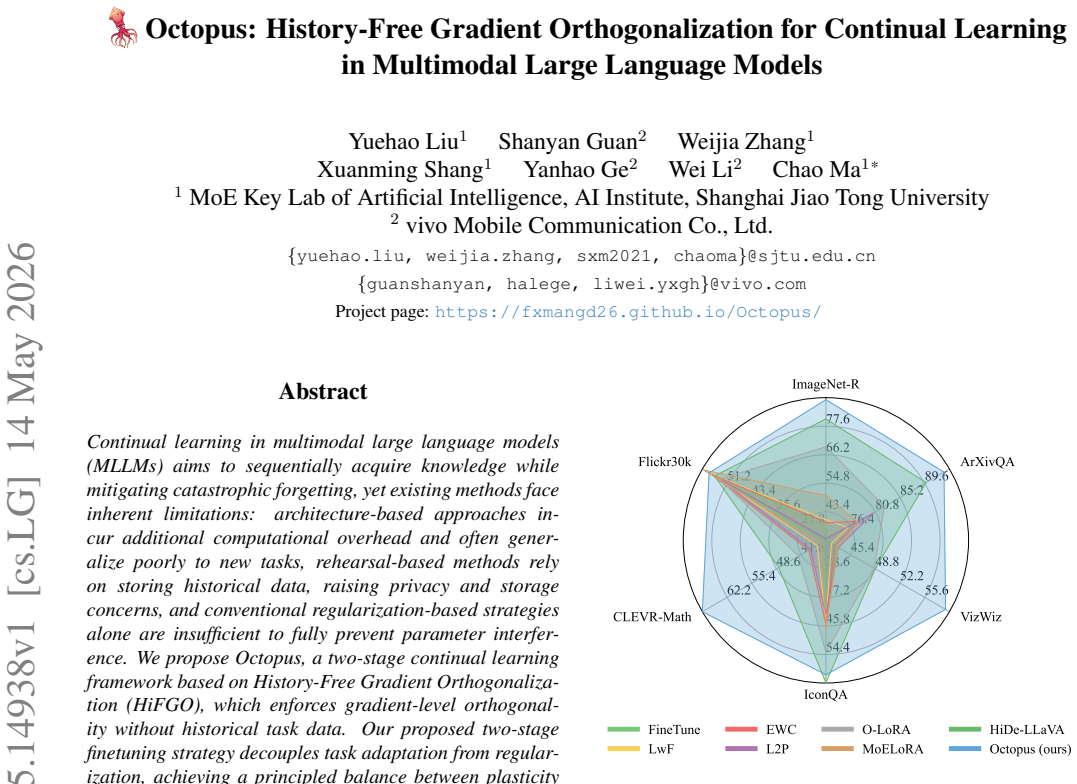
Continual learning in multimodal large language models (MLLMs) aims to sequentially acquire knowledge while mitigating catastrophic forgetting, yet existing methods face inherent limitations: architecture-based approaches incur additional computational overhead and often generalize poorly to new tasks, rehearsal-based methods rely on storing historical data, raising privacy and storage concerns, and conventional regularization-based strategies alone are insufficient to fully prevent parameter interference. We propose Octopus, a two-stage continual learning framework based on History-Free Gradient Orthogonalization (HiFGO), which enforces gradient-level orthogonality without historical task data. Our proposed two-stage finetuning strategy decouples task adaptation from regularization, achieving a principled balance between plasticity and stability. Experiments on UCIT show that Octopus establishes state-of-the-art performance, surpassing prior SOTA by 2.14% and 6.82% in terms of Avg and Last.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Octopus, a two-stage continual learning framework for multimodal large language models (MLLMs) based on History-Free Gradient Orthogonalization (HiFGO). HiFGO is claimed to enforce gradient-level orthogonality to prior tasks without access to historical data or gradients. The two-stage finetuning decouples task adaptation from regularization to balance plasticity and stability. Experiments on the UCIT benchmark report state-of-the-art results, surpassing prior SOTA by 2.14% in Avg and 6.82% in Last metrics.
Significance. If the HiFGO mechanism can be shown to achieve genuine orthogonality to unseen prior task gradients using only current-task information and if the reported gains are causally linked to this mechanism rather than other factors, the work would meaningfully advance continual learning for MLLMs by eliminating rehearsal-based storage/privacy issues and architecture overhead. The explicit two-stage decoupling is a constructive design choice that could be adopted more broadly.
major comments (2)
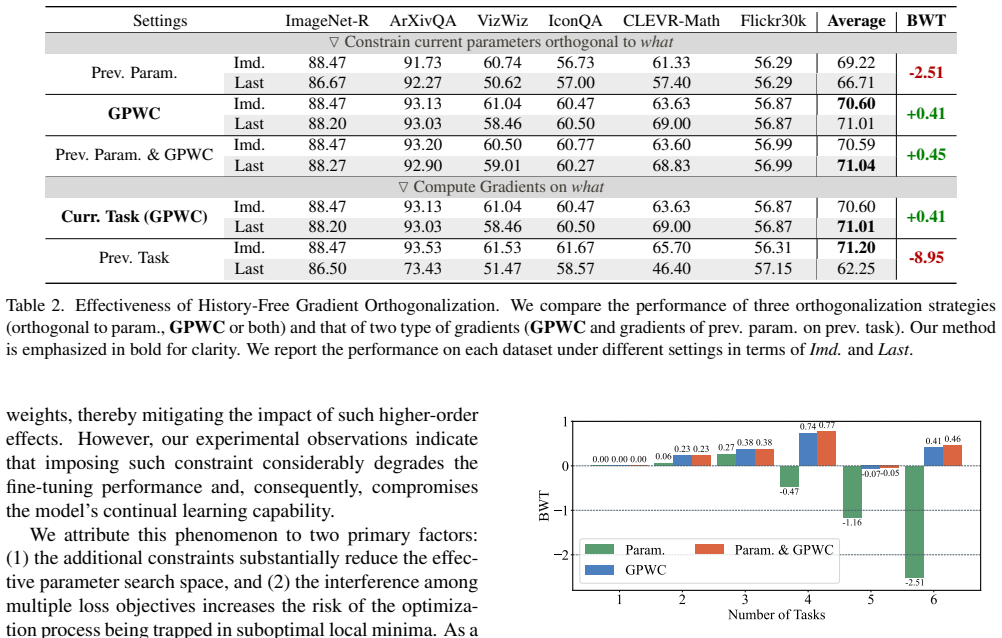
- [Method (HiFGO definition)] Method section describing HiFGO: the central claim that gradient orthogonality to all prior tasks can be enforced history-free must be supported by an explicit formulation (e.g., how current-batch statistics or parameter constraints serve as a proxy for past gradient directions) together with either a proof of orthogonality preservation or an empirical verification measuring angles against held-out past gradients; without this, the reported interference mitigation cannot be attributed to the stated mechanism.
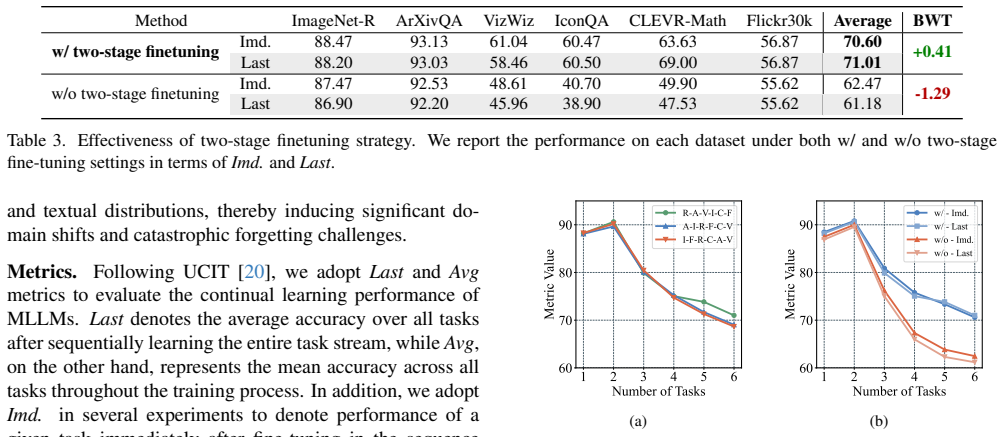
- [Experiments (UCIT evaluation)] Experiments section on UCIT results: the SOTA claim (2.14% Avg, 6.82% Last gains) is presented without error bars, number of random seeds, ablation studies isolating HiFGO from the two-stage strategy, or full implementation details (hyperparameters, exact architecture modifications), rendering it impossible to verify reproducibility or rule out confounding factors.
minor comments (1)
- [Abstract] Abstract: the UCIT benchmark is referenced without a one-sentence description of its task sequence or modalities, which would aid readers unfamiliar with the continual-learning MLLM literature.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of HiFGO and strengthen the experimental reporting. We address each point below and will incorporate the suggested additions in the revised manuscript.
read point-by-point responses
-
Referee: [Method (HiFGO definition)] Method section describing HiFGO: the central claim that gradient orthogonality to all prior tasks can be enforced history-free must be supported by an explicit formulation (e.g., how current-batch statistics or parameter constraints serve as a proxy for past gradient directions) together with either a proof of orthogonality preservation or an empirical verification measuring angles against held-out past gradients; without this, the reported interference mitigation cannot be attributed to the stated mechanism.
Authors: We agree that an explicit formulation and supporting verification are necessary to substantiate the history-free orthogonality claim. The current manuscript presents the HiFGO update rule in Section 3.2, but we will expand this in revision to include: (i) the precise mathematical definition showing how per-batch gradient statistics and a projection operator serve as a proxy without storing past gradients, (ii) a short derivation establishing that the resulting update direction is orthogonal to the span of prior-task gradients under the stated assumptions, and (iii) an empirical verification subsection that reports cosine angles between the HiFGO-adjusted gradients and held-out past-task gradients on UCIT sequences. These additions will directly link the observed interference reduction to the mechanism. revision: yes
-
Referee: [Experiments (UCIT evaluation)] Experiments section on UCIT results: the SOTA claim (2.14% Avg, 6.82% Last gains) is presented without error bars, number of random seeds, ablation studies isolating HiFGO from the two-stage strategy, or full implementation details (hyperparameters, exact architecture modifications), rendering it impossible to verify reproducibility or rule out confounding factors.
Authors: We acknowledge that the current experimental section lacks sufficient statistical detail and controls. In the revised version we will: (i) report means and standard deviations over at least three random seeds for all UCIT metrics, (ii) add an ablation table that isolates HiFGO from the two-stage finetuning schedule, and (iii) include a dedicated reproducibility subsection (or appendix) listing all hyperparameters, optimizer settings, exact model modifications, and training schedules. These changes will allow readers to reproduce the results and assess the contribution of each component. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper proposes a two-stage continual learning framework (Octopus) based on HiFGO for enforcing gradient orthogonality without historical data. No equations, derivations, or self-citations appear in the provided abstract or text that reduce the claimed SOTA gains (2.14% Avg, 6.82% Last on UCIT) to a fitted parameter or input quantity defined from the same data by construction. The performance claims rest on experimental benchmarks rather than any self-definitional or load-bearing self-citation step. The method is presented as an empirical engineering contribution whose validity is tested externally, making the derivation chain self-contained.
Axiom & Free-Parameter Ledger
invented entities (1)
-
HiFGO
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ss-il: Separated softmax for incremental learning
Hongjoon Ahn, Jihwan Kwak, Subin Lim, Hyeonsu Bang, Hyojun Kim, and Taesup Moon. Ss-il: Separated softmax for incremental learning. InICCV, 2021. 1
2021
-
[2]
Spice: Semantic propositional image cap- tion evaluation
Peter Anderson, Basura Fernando, Mark Johnson, and Stephen Gould. Spice: Semantic propositional image cap- tion evaluation. InECCV, 2016. 1, 2
2016
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Dark experience for general continual learning: a strong, simple baseline.NeurIPS, 2020
Pietro Buzzega, Matteo Boschini, Angelo Porrello, Davide Abati, and Simone Calderara. Dark experience for general continual learning: a strong, simple baseline.NeurIPS, 2020. 2
2020
-
[5]
Meng Cao, Yuyang Liu, Yingfei Liu, Tiancai Wang, Ji- ahua Dong, Henghui Ding, Xiangyu Zhang, Ian Reid, and Xiaodan Liang. Continual llava: Continual instruction tuning in large vision-language models.arXiv preprint arXiv:2411.02564, 2024. 1
-
[6]
Multitask learning.Machine learning, 1997
Rich Caruana. Multitask learning.Machine learning, 1997. 2
1997
-
[7]
Continual learning with tiny episodic memories
Arslan Chaudhry, Marcus Rohrbach, Mohamed Elhoseiny, Thalaiyasingam Ajanthan, P Dokania, P Torr, and M Ran- zato. Continual learning with tiny episodic memories. In Workshop on Multi-Task and Lifelong Reinforcement Learn- ing, 2019. 1
2019
-
[8]
Coin: A benchmark of continual instruction tuning for multimodel large language models
Cheng Chen, Junchen Zhu, Xu Luo, Heng T Shen, Jingkuan Song, and Lianli Gao. Coin: A benchmark of continual instruction tuning for multimodel large language models. NeurIPS, 2024. 1, 5, 7, 2
2024
-
[9]
Adaptformer: Adapting vision transformers for scalable visual recognition
Shoufa Chen, Chongjian Ge, Zhan Tong, Jiangliu Wang, Yibing Song, Jue Wang, and Ping Luo. Adaptformer: Adapting vision transformers for scalable visual recognition. NeurIPS, 2022. 2
2022
-
[10]
Multi-task learning with deep neural networks: A survey.arXiv preprint arXiv:2009.09796, 2020
Michael Crawshaw. Multi-task learning with deep neural networks: A survey.arXiv preprint arXiv:2009.09796, 2020. 2
-
[11]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InCVPR, 2009. 1
2009
-
[12]
Meteor universal: Lan- guage specific translation evaluation for any target language
Michael Denkowski and Alon Lavie. Meteor universal: Lan- guage specific translation evaluation for any target language. InProceedings of the ninth workshop on statistical machine translation, 2014. 7, 1
2014
-
[13]
Podnet: Pooled outputs distil- lation for small-tasks incremental learning
Arthur Douillard, Matthieu Cord, Charles Ollion, Thomas Robert, and Eduardo Valle. Podnet: Pooled outputs distil- lation for small-tasks incremental learning. InECCV, 2020. 1
2020
-
[14]
Orthogonal gradient descent for continual learning
Mehrdad Farajtabar, Navid Azizan, Alex Mott, and Ang Li. Orthogonal gradient descent for continual learning. InInter- national conference on artificial intelligence and statistics,
-
[15]
Catastrophic forgetting in connectionist networks.Trends in cognitive sciences, 1999
Robert M French. Catastrophic forgetting in connectionist networks.Trends in cognitive sciences, 1999. 1, 3
1999
-
[16]
Cyclical Annealing Schedule: A Simple Approach to Mitigating KL Vanishing
Hao Fu, Chunyuan Li, Xiaodong Liu, Jianfeng Gao, Asli Ce- likyilmaz, and Lawrence Carin. Cyclical annealing schedule: A simple approach to mitigating kl vanishing.arXiv preprint arXiv:1903.10145, 2019. 6
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[17]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Dan Zhang, Diego Rojas, Guanyu Feng, Hanlin Zhao, et al. Chatglm: A family of large language models from glm-130b to glm-4 all tools.arXiv preprint arXiv:2406.12793, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Making the v in vqa matter: Elevating the role of image understanding in visual question answer- ing
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Ba- tra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answer- ing. InCVPR, 2017. 1
2017
-
[19]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Ab- hinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Haiyang Guo, Fanhu Zeng, Ziwei Xiang, Fei Zhu, Da- Han Wang, Xu-Yao Zhang, and Cheng-Lin Liu. Hide- llava: Hierarchical decoupling for continual instruction tun- ing of multimodal large language model.arXiv preprint arXiv:2503.12941, 2025. 1, 2, 5, 6, 7, 4
-
[21]
Vizwiz grand challenge: Answering visual questions from blind people
Danna Gurari, Qing Li, Abigale J Stangl, Anhong Guo, Chi Lin, Kristen Grauman, Jiebo Luo, and Jeffrey P Bigham. Vizwiz grand challenge: Answering visual questions from blind people. InCVPR, 2018. 1
2018
-
[22]
The many faces of robust- ness: A critical analysis of out-of-distribution generalization
Dan Hendrycks, Steven Basart, Norman Mu, Saurav Kada- vath, Frank Wang, Evan Dorundo, Rahul Desai, Tyler Zhu, Samyak Parajuli, Mike Guo, et al. The many faces of robust- ness: A critical analysis of out-of-distribution generalization. InICCV, 2021. 1
2021
-
[23]
Parameter-efficient transfer learning for nlp
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. InICML, 2019. 2
2019
-
[24]
Lora: Low-rank adaptation of large language models.ICLR,
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR,
-
[25]
Distilling causal effect of data in class- incremental learning
Xinting Hu, Kaihua Tang, Chunyan Miao, Xian-Sheng Hua, and Hanwang Zhang. Distilling causal effect of data in class- incremental learning. InCVPR, 2021. 1
2021
-
[26]
Cl-moe: Enhancing multi- modal large language model with dual momentum mixture- of-experts for continual visual question answering
Tianyu Huai, Jie Zhou, Xingjiao Wu, Qin Chen, Qingchun Bai, Ze Zhou, and Liang He. Cl-moe: Enhancing multi- modal large language model with dual momentum mixture- of-experts for continual visual question answering. InCVPR,
-
[27]
Gqa: A new dataset for real-world visual reasoning and compositional question answering
Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. InCVPR, 2019. 1
2019
-
[28]
Vi- sual prompt tuning
Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, and Ser-Nam Lim. Vi- sual prompt tuning. InECCV, 2022. 2
2022
-
[29]
Ziqi Jia, Anmin Wang, Xiaoyang Qu, Xiaowen Yang, and Jianzong Wang. Hierarchical-task-aware multi-modal mix- ture of incremental lora experts for embodied continual learning.arXiv preprint arXiv:2506.04595, 2025. 2
-
[30]
Referitgame: Referring to objects in pho- tographs of natural scenes
Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. Referitgame: Referring to objects in pho- tographs of natural scenes. InEMNLP, 2014. 1
2014
-
[31]
Overcoming catastrophic forgetting in neu- ral networks.Proceedings of the national academy of sci- ences, 2017
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska- Barwinska, et al. Overcoming catastrophic forgetting in neu- ral networks.Proceedings of the national academy of sci- ences, 2017. 2, 5, 7
2017
-
[32]
The Power of Scale for Parameter-Efficient Prompt Tuning
Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning.arXiv preprint arXiv:2104.08691, 2021. 2
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[33]
Lei Li, Yuqi Wang, Runxin Xu, Peiyi Wang, Xiachong Feng, Lingpeng Kong, and Qi Liu. Multimodal arxiv: A dataset for improving scientific comprehension of large vision-language models.arXiv preprint arXiv:2403.00231, 2024. 1
-
[34]
Prefix-Tuning: Optimizing Continuous Prompts for Generation
Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimiz- ing continuous prompts for generation.arXiv preprint arXiv:2101.00190, 2021. 2
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[35]
Learning without forgetting
Zhizhong Li and Derek Hoiem. Learning without forgetting. TPAMI, 2017. 2, 5, 7
2017
-
[36]
Inflora: Interference-free low-rank adaptation for continual learning
Yan-Shuo Liang and Wu-Jun Li. Inflora: Interference-free low-rank adaptation for continual learning. InCVPR, 2024. 2
2024
-
[37]
Rouge: A package for automatic evaluation of summaries
Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. InText summarization branches out, pages 74–81, 2004. 7, 1
2004
-
[38]
Adam Dahlgren Lindstr ¨om and Savitha Sam Abra- ham. Clevr-math: A dataset for compositional lan- guage, visual and mathematical reasoning.arXiv preprint arXiv:2208.05358, 2022. 1
-
[39]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InCVPR,
-
[40]
Gradient episodic memory for continual learning.NeurIPS, 2017
David Lopez-Paz and Marc’Aurelio Ranzato. Gradient episodic memory for continual learning.NeurIPS, 2017. 2, 7
2017
-
[41]
Pan Lu, Liang Qiu, Jiaqi Chen, Tony Xia, Yizhou Zhao, Wei Zhang, Zhou Yu, Xiaodan Liang, and Song-Chun Zhu. Iconqa: A new benchmark for abstract diagram under- standing and visual language reasoning.arXiv preprint arXiv:2110.13214, 2021. 1
-
[42]
Learn to explain: Multimodal reasoning via thought chains for science question answering.NeurIPS,
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering.NeurIPS,
-
[43]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathemat- ical reasoning of foundation models in visual contexts.arXiv preprint arXiv:2310.02255, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Piggy- back: Adapting a single network to multiple tasks by learn- ing to mask weights
Arun Mallya, Dillon Davis, and Svetlana Lazebnik. Piggy- back: Adapting a single network to multiple tasks by learn- ing to mask weights. InECCV, 2018. 2
2018
-
[45]
Generation and comprehension of unambiguous object descriptions
Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Camburu, Alan L Yuille, and Kevin Murphy. Generation and comprehension of unambiguous object descriptions. In CVPR, 2016. 1
2016
-
[46]
Catastrophic inter- ference in connectionist networks: The sequential learning problem
Michael McCloskey and Neal J Cohen. Catastrophic inter- ference in connectionist networks: The sequential learning problem. InPsychology of learning and motivation. 1989. 1, 3
1989
-
[47]
Ocr-vqa: Visual question answering by reading text in images
Anand Mishra, Shashank Shekhar, Ajeet Kumar Singh, and Anirban Chakraborty. Ocr-vqa: Visual question answering by reading text in images. InICDAR, 2019. 1
2019
-
[48]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics, 2002. 7, 1
2002
-
[49]
Continual lifelong learning with neural networks: A review.Neural networks, 2019
German I Parisi, Ronald Kemker, Jose L Part, Christopher Kanan, and Stefan Wermter. Continual lifelong learning with neural networks: A review.Neural networks, 2019. 1
2019
-
[50]
Flickr30k entities: Collecting region-to-phrase corre- spondences for richer image-to-sentence models
Bryan A Plummer, Liwei Wang, Chris M Cervantes, Juan C Caicedo, Julia Hockenmaier, and Svetlana Lazeb- nik. Flickr30k entities: Collecting region-to-phrase corre- spondences for richer image-to-sentence models. InICCV,
-
[51]
Language models are unsu- pervised multitask learners.OpenAI blog, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsu- pervised multitask learners.OpenAI blog, 2019. 2
2019
-
[52]
Correlated low-rank adaptation for convnets
Wu Ran, Weijia Zhang, ShuYang Pang, Qi Zhu, Jinfan Liu, JingSheng Liu, Xin Cao, Qiang Li, Yichao Yan, and Chao Ma. Correlated low-rank adaptation for convnets. In NeurIPS, 2025. 2
2025
-
[53]
Experience replay for continual learning
David Rolnick, Arun Ahuja, Jonathan Schwarz, Timothy Lil- licrap, and Gregory Wayne. Experience replay for continual learning. InNeurIPS, 2019. 1
2019
-
[54]
Continual learning with deep generative replay.NeurIPS,
Hanul Shin, Jung Kwon Lee, Jaehong Kim, and Jiwon Kim. Continual learning with deep generative replay.NeurIPS,
-
[55]
Towards vqa models that can read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. InCVPR,
-
[56]
Coda-prompt: Contin- ual decomposed attention-based prompting for rehearsal-free continual learning
James Seale Smith, Leonid Karlinsky, Vyshnavi Gutta, Paola Cascante-Bonilla, Donghyun Kim, Assaf Arbelle, Rameswar Panda, Rogerio Feris, and Zsolt Kira. Coda-prompt: Contin- ual decomposed attention-based prompting for rehearsal-free continual learning. InCVPR, 2023. 2
2023
-
[57]
Adaptive memory replay for continual learning
James Seale Smith, Lazar Valkov, Shaunak Halbe, Vysh- navi Gutta, Rogerio Feris, Zsolt Kira, and Leonid Karlinsky. Adaptive memory replay for continual learning. InCVPR,
-
[58]
Shikhar Srivastava, Md Yousuf Harun, Robik Shrestha, and Christopher Kanan. Improving multimodal large lan- guage models using continual learning.arXiv preprint arXiv:2410.19925, 2024. 1
-
[59]
Model merging with svd to tie the knots.arXiv preprint arXiv:2410.19735, 2024
George Stoica, Pratik Ramesh, Boglarka Ecsedi, Leshem Choshen, and Judy Hoffman. Model merging with svd to tie the knots.arXiv preprint arXiv:2410.19735, 2024. 2
-
[60]
Cider: Consensus-based image description evalua- tion
Ramakrishna Vedantam, C Lawrence Zitnick, and Devi Parikh. Cider: Consensus-based image description evalua- tion. InCVPR, pages 4566–4575, 2015. 7, 1
2015
-
[61]
Meet jeanie: a similarity measure for 3d skeleton sequences via temporal-viewpoint alignment.IJCV, 2024
Lei Wang, Jun Liu, Liang Zheng, Tom Gedeon, and Piotr Koniusz. Meet jeanie: a similarity measure for 3d skeleton sequences via temporal-viewpoint alignment.IJCV, 2024. 1
2024
-
[62]
A comprehensive survey of continual learning: Theory, method and application.TPAMI, 2024
Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. A comprehensive survey of continual learning: Theory, method and application.TPAMI, 2024. 1
2024
-
[63]
Or- thogonal subspace learning for language model continual learning
Xiao Wang, Tianze Chen, Qiming Ge, Han Xia, Rong Bao, Rui Zheng, Qi Zhang, Tao Gui, and Xuan-Jing Huang. Or- thogonal subspace learning for language model continual learning. InFindings of the Association for Computational Linguistics: EMNLP, 2023. 1, 2, 4, 5, 7
2023
-
[64]
Dualprompt: Complementary prompting for rehearsal-free continual learning
Zifeng Wang, Zizhao Zhang, Sayna Ebrahimi, Ruoxi Sun, Han Zhang, Chen-Yu Lee, Xiaoqi Ren, Guolong Su, Vin- cent Perot, Jennifer Dy, et al. Dualprompt: Complementary prompting for rehearsal-free continual learning. InECCV,
-
[65]
Learning to prompt for continual learning
Zifeng Wang, Zizhao Zhang, Chen-Yu Lee, Han Zhang, Ruoxi Sun, Xiaoqi Ren, Guolong Su, Vincent Perot, Jen- nifer Dy, and Tomas Pfister. Learning to prompt for continual learning. InCVPR, 2022. 1, 2, 5
2022
-
[66]
Large scale in- cremental learning
Yue Wu, Yinpeng Chen, Lijuan Wang, Yuancheng Ye, Zicheng Liu, Yandong Guo, and Yun Fu. Large scale in- cremental learning. InCVPR, 2019. 1
2019
-
[67]
Restricted orthogonal gradient projection for continual learning.AI Open, 2023
Zeyuan Yang, Zonghan Yang, Yichen Liu, Peng Li, and Yang Liu. Restricted orthogonal gradient projection for continual learning.AI Open, 2023. 2
2023
-
[68]
A survey on multimodal large language models.National Science Review, 2024
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models.National Science Review, 2024. 1
2024
-
[69]
An overview of multi-task learn- ing.National Science Review, 2018
Yu Zhang and Qiang Yang. An overview of multi-task learn- ing.National Science Review, 2018. 2
2018
-
[70]
A survey on multi-task learn- ing.IEEE transactions on knowledge and data engineering,
Yu Zhang and Qiang Yang. A survey on multi-task learn- ing.IEEE transactions on knowledge and data engineering,
-
[71]
Xuanle Zhao, Xuexin Liu, Haoyue Yang, Xianzhen Luo, Fanhu Zeng, Jianling Li, Qi Shi, and Chi Chen. Chartedit: How far are mllms from automating chart analysis? eval- uating mllms’ capability via chart editing.arXiv preprint arXiv:2505.11935, 2025. 2
-
[72]
Rethinking gradient projection continual learning: Stability/plasticity feature space decou- pling
Zhen Zhao, Zhizhong Zhang, Xin Tan, Jun Liu, Yanyun Qu, Yuan Xie, and Lizhuang Ma. Rethinking gradient projection continual learning: Stability/plasticity feature space decou- pling. InCVPR, 2023. 4
2023
-
[73]
Class-incremental learning: A survey.TPAMI, 2024
Da-Wei Zhou, Qi-Wei Wang, Zhi-Hong Qi, Han-Jia Ye, De- Chuan Zhan, and Ziwei Liu. Class-incremental learning: A survey.TPAMI, 2024. 1
2024
-
[74]
Hao Zhu, Yifei Zhang, Junhao Dong, and Piotr Koniusz. Bilora: Almost-orthogonal parameter spaces for continual learning. InCVPR, 2025. 1, 2 Octopus: History-Free Gradient Orthogonalization for Continual Learning in Multimodal Large Language Models Supplementary Material This material provides supplementary information on the proposed Octopus framework. It...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.