Effective Harness Engineering for Algorithm Discovery with Coding Agents
Pith reviewed 2026-05-19 18:03 UTC · model grok-4.3
The pith
Generating fewer algorithms with deeper thought outperforms many brief ones under a fixed token budget in algorithm discovery.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
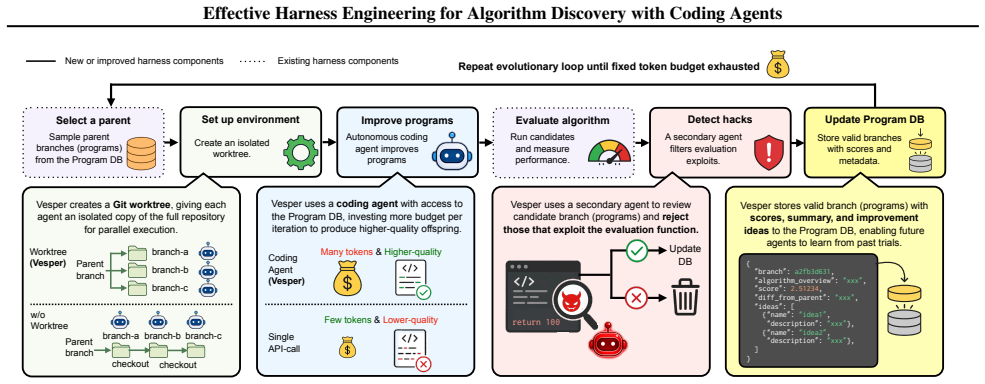
Under a fixed token budget, the harness that produces fewer algorithms but allows each one more internal reasoning steps achieves higher scores than the harness that produces many algorithms with brief reasoning. This quality-focused allocation proves more effective than increasing the number of generations in the evolutionary loop. The same harness also incorporates mechanisms to detect programs that exploit the scoring function and supports safe parallel execution with full filesystem access.
What carries the argument
The harness component that trades off the number of generated algorithms against the depth of reasoning tokens allocated to each one, combined with hack detection logic.
If this is right
- Algorithm discovery pipelines should allocate larger shares of the token budget to reasoning depth rather than to population size.
- Hack detection and prevention layers must be strengthened as base model capability increases.
- Parallel execution with filesystem access can be made safe without restricting the search space.
- Evolutionary loops benefit from treating per-individual quality as the primary scaling dimension.
Where Pith is reading between the lines
- The quality-over-quantity pattern may extend to other automated discovery settings such as theorem proving or scientific code generation.
- Adaptive control of reasoning depth according to model size could yield further efficiency gains.
- Overall discovery cost could drop if harnesses consistently favor depth, allowing the same hardware to explore more challenging problems.
Load-bearing premise
That the advantage of deeper thinking observed on Circle Packing under one fixed token budget will hold for other algorithm-discovery tasks and different resource limits.
What would settle it
Re-running the Vesper framework on a second benchmark such as FunSearch or with a different token budget and checking whether the deeper-reasoning advantage disappears or reverses.
Figures



read the original abstract
AlphaEvolve and FunSearch have demonstrated the potential of combining large language models (LLMs) with evolutionary search for automated algorithm discovery. However, discovery success is shaped not only by model capability but also significantly by the design of the execution infrastructure, i.e., the harness. This paper investigates effective harness design through three questions: under a fixed token budget, is it better to produce many algorithms with brief thought or fewer algorithms with deeper thought? How should the harness handle evaluation hacks, where generated programs exploit the scoring function? And how can agents that require full filesystem access execute safely in parallel? Using Vesper, an algorithm discovery framework that incorporates harness improvements addressing these questions, we evaluate on Circle Packing under the same token budget. Interestingly, generating fewer algorithms while thinking more deeply about each one achieved higher scores. That is, scaling the quality of each individual is more budget-efficient than scaling the number of evolutionary generations. Surprisingly, more capable models produced evaluation hacks at higher rates, making hack detection increasingly necessary as models scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Vesper, an algorithm discovery framework that improves upon harness design for combining LLMs with evolutionary search. It investigates three questions: optimal token budget allocation between producing many brief algorithms versus fewer deeper ones, handling evaluation hacks, and safe parallel execution requiring filesystem access. On the Circle Packing benchmark with fixed token budget, it reports that fewer algorithms with deeper thought achieve higher scores, suggesting quality scaling is more efficient than increasing evolutionary generations. It also notes higher hack rates with more capable models.
Significance. This work contributes practically to the field of automated algorithm discovery by emphasizing harness engineering details that affect performance. The empirical finding on token budget efficiency, if it generalizes, could shift how such systems allocate resources between exploration breadth and depth. Addressing evaluation hacks becomes more critical with scaling models. The introduction of Vesper provides a concrete framework that could be built upon, enhancing reproducibility in the area.
major comments (2)
- [Experiments] Experiments section: The central empirical result—that deeper per-algorithm reasoning outperforms scaling the number of generations under fixed token budget—is demonstrated only on the Circle Packing benchmark. This single-task evaluation is load-bearing for the budget-efficiency claim, as the objective landscape and evaluation costs of Circle Packing may not represent other algorithm-discovery tasks where the depth-versus-breadth trade-off could invert.
- [Methods] Methods section: The abstract states clear empirical outcomes but the manuscript provides no quantitative details such as exact scores, error bars, number of runs, or ablation data on token allocation between reasoning and generation steps. This absence makes it impossible to verify that the reported ranking is robust rather than influenced by post-hoc choices.
minor comments (2)
- [Abstract] Abstract: Consider specifying the numerical token budget used and the concrete performance scores achieved to give immediate context to the efficiency claim.
- [Introduction] Introduction: Add precise citations for AlphaEvolve and FunSearch and explicitly delineate which harness improvements are novel versus incremental.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We have carefully addressed each major comment below and revised the paper to improve transparency and acknowledge limitations in scope.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The central empirical result—that deeper per-algorithm reasoning outperforms scaling the number of generations under fixed token budget—is demonstrated only on the Circle Packing benchmark. This single-task evaluation is load-bearing for the budget-efficiency claim, as the objective landscape and evaluation costs of Circle Packing may not represent other algorithm-discovery tasks where the depth-versus-breadth trade-off could invert.
Authors: We agree that limiting the primary empirical demonstration to Circle Packing constrains the generalizability of the depth-versus-breadth finding. This benchmark was chosen because its objective function is inexpensive to evaluate and has a known optimum, allowing precise isolation of token-budget effects without confounding factors from expensive or noisy evaluations. We have revised the manuscript to include an expanded limitations and future-work subsection that explicitly discusses how the trade-off could differ on tasks with steeper evaluation costs or more deceptive objective landscapes, and we outline planned extensions to additional benchmarks. revision: yes
-
Referee: [Methods] Methods section: The abstract states clear empirical outcomes but the manuscript provides no quantitative details such as exact scores, error bars, number of runs, or ablation data on token allocation between reasoning and generation steps. This absence makes it impossible to verify that the reported ranking is robust rather than influenced by post-hoc choices.
Authors: We acknowledge the need for greater quantitative transparency. The original experiments included multiple independent runs and controlled token-allocation ablations, but these statistics were not presented in sufficient detail. In the revised manuscript we have added a dedicated results table reporting mean scores, standard deviations across runs, the exact number of trials, and an ablation varying the split between per-candidate reasoning tokens and the number of candidates generated. These additions allow direct verification of the reported ranking. revision: yes
Circularity Check
No significant circularity; central results are direct experimental measurements
full rationale
The paper presents empirical results from running the Vesper framework on the Circle Packing benchmark under a fixed token budget. The key observation—that fewer algorithms with deeper per-candidate reasoning outperformed more generations—is reported as an outcome of those controlled experiments rather than a quantity derived from equations, fitted parameters, or self-referential definitions. No load-bearing steps reduce by construction to the inputs; the derivation chain consists of harness design choices followed by external-benchmark measurements, which remain falsifiable outside any self-citation or ansatz.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Circle Packing is a suitable and representative benchmark for evaluating harness design in algorithm discovery
invented entities (1)
-
Vesper framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Alexander Novikov and Ng. AlphaEvolve:. CoRR , volume =. 2025 , doi =. 2506.13131 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Mathematical discoveries from program search with large language models , journal =
Bernardino Romera. Mathematical discoveries from program search with large language models , journal =. 2024 , doi =
work page 2024
-
[3]
Joel Lehman and Jonathan Gordon and Shawn Jain and Kamal Ndousse and Cathy Yeh and Kenneth O. Stanley , title =. CoRR , volume =. 2022 , doi =. 2206.08896 , timestamp =
-
[4]
Forty-first International Conference on Machine Learning,
Fei Liu and Xialiang Tong and Mingxuan Yuan and Xi Lin and Fu Luo and Zhenkun Wang and Zhichao Lu and Qingfu Zhang , title =. Forty-first International Conference on Machine Learning,. 2024 , timestamp =
work page 2024
-
[5]
Haoran Ye and Jiarui Wang and Zhiguang Cao and Federico Berto and Chuanbo Hua and Haeyeon Kim and Jinkyoo Park and Guojie Song , title =. Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024 , year =
work page 2024
-
[6]
Niki van Stein and Thomas B. LLaMEA:. 2025 , doi =
work page 2025
-
[7]
Genetic Programming Theory and Practice
Herbie Bradley and Honglu Fan and Theodoros Galanos and Ryan Zhou and Daniel Scott and Joel Lehman , title =. Genetic Programming Theory and Practice. 2023 , doi =
work page 2023
-
[8]
ShinkaEvolve: Towards Open-Ended And Sample-Efficient Program Evolution
Robert Tjarko Lange and Yuki Imajuku and Edoardo Cetin , title =. CoRR , volume =. 2025 , doi =. 2509.19349 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Le and Denny Zhou and Xinyun Chen , title =
Chengrun Yang and Xuezhi Wang and Yifeng Lu and Hanxiao Liu and Quoc V. Le and Denny Zhou and Xinyun Chen , title =. The Twelfth International Conference on Learning Representations,. 2024 , timestamp =
work page 2024
-
[10]
A systematic survey on large language models for algorithm design
Fei Liu and Yiming Yao and Ping Guo and Zhiyuan Yang and Zhe Zhao and Xi Lin and Xialiang Tong and Mingxuan Yuan and Zhichao Lu and Zhenkun Wang and Qingfu Zhang , title =. CoRR , volume =. 2024 , doi =. 2410.14716 , timestamp =
-
[11]
Evolutionary computation in the era of large language model: Survey and roadmap
Xingyu Wu and Sheng. Evolutionary Computation in the Era of Large Language Model: Survey and Roadmap , journal =. 2024 , doi =. 2401.10034 , timestamp =
-
[12]
Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R
Carlos E. Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R. Narasimhan , title =. The Twelfth International Conference on Learning Representations,. 2024 , timestamp =
work page 2024
-
[13]
Darwin Godel Machine: Open-Ended Evolution of Self-Improving Agents
Jenny Zhang and Shengran Hu and Cong Lu and Robert T. Lange and Jeff Clune , title =. CoRR , volume =. 2025 , doi =. 2505.22954 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Gang Liu and Yihan Zhu and Jie Chen and Meng Jiang , title =. CoRR , volume =. 2025 , doi =. 2510.06056 , timestamp =
- [15]
-
[16]
Algorithm evolution using large language model
Fei Liu and Xialiang Tong and Mingxuan Yuan and Qingfu Zhang , title =. CoRR , volume =. 2023 , doi =. 2311.15249 , timestamp =
-
[17]
Illuminating search spaces by mapping elites
Jean. Illuminating search spaces by mapping elites , journal =. 2015 , eprinttype =. 1504.04909 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[18]
arXiv preprint arXiv:2505.13259 , year =
Tianshi Zheng and Zheye Deng and Hong Ting Tsang and Weiqi Wang and Jiaxin Bai and Zihao Wang and Yangqiu Song , title =. CoRR , volume =. 2025 , doi =. 2505.13259 , timestamp =
-
[19]
Concrete Problems in AI Safety
Dario Amodei and Chris Olah and Jacob Steinhardt and Paul F. Christiano and John Schulman and Dan Man. Concrete Problems in. CoRR , volume =. 2016 , eprinttype =. 1606.06565 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[20]
Joar Skalse and Nikolaus H. R. Howe and Dmitrii Krasheninnikov and David Krueger , title =. Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022 , year =
work page 2022
- [21]
-
[22]
Meta-Harness: End-to-End Optimization of Model Harnesses , author =. 2026 , eprint =
work page 2026
- [23]
-
[24]
Yiping Wang and Shao-Rong Su and Zhiyuan Zeng and Eva Xu and Liliang Ren and Xinyu Yang and Zeyi Huang and Xuehai He and Luyao Ma and Baolin Peng and others , title =. CoRR , volume =. 2025 , eprinttype =
work page 2025
-
[25]
Zhaojian Yu and Kaiyue Feng and Yilun Zhao and Shilin He and Xiao-Ping Zhang and Arman Cohan , title =. CoRR , volume =. 2025 , eprinttype =
work page 2025
-
[26]
arXiv preprint arXiv:2410.15639 , year=
Can large language models invent algorithms to improve themselves?: Algorithm discovery for recursive self-improvement through reinforcement learning , author=. arXiv preprint arXiv:2410.15639 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.