Margin-Adaptive Confidence Ranking for Reliable LLM Judgement
Pith reviewed 2026-05-19 16:01 UTC · model grok-4.3
The pith
A learned margin-adaptive confidence estimator improves LLM-human agreement by strengthening the link between confidence scores and disagreement risk.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Training a confidence estimator via simulated annotator diversity and a margin-based ranking objective produces a model whose scores more reliably separate human-agreement from human-disagreement instances; the resulting generalization guarantee is margin-dependent, and the trained estimator, once inserted into fixed-sequence testing, raises the probability of satisfying target agreement levels while empirically restoring monotonicity between reported confidence and observed disagreement risk.
What carries the argument
Margin-based ranking formulation that scores how confidently the LLM distinguishes agreement cases from disagreement cases, trained on simulated annotator diversity.
If this is right
- The estimator produces higher ranking accuracy than heuristic confidence signals when ordering examples by disagreement risk.
- The monotonic relationship between confidence and disagreement risk is empirically strengthened.
- Fixed-sequence testing achieves higher success rates at meeting target agreement levels on multiple datasets and judge models.
- The margin-dependent generalization bound directly informs the choice of training margin and adaptive schedule.
Where Pith is reading between the lines
- If the simulation-to-real transfer holds only for certain domains, the method would need domain-specific diversity simulators rather than a single generic one.
- The same margin-ranking idea could be applied to other LLM reliability tasks such as calibration for factual errors or refusal decisions.
- Because the bound depends explicitly on margin size, practitioners gain a knob to trade sample efficiency against ranking quality without changing the underlying judge model.
Load-bearing premise
Training on simulated annotator diversity produces a confidence estimator whose ranking behavior transfers to real human disagreement distributions.
What would settle it
Run the learned estimator on a held-out set of real human disagreement labels and check whether ranking accuracy or success rate in meeting agreement targets fails to exceed the heuristic baseline used by Jung et al.
Figures

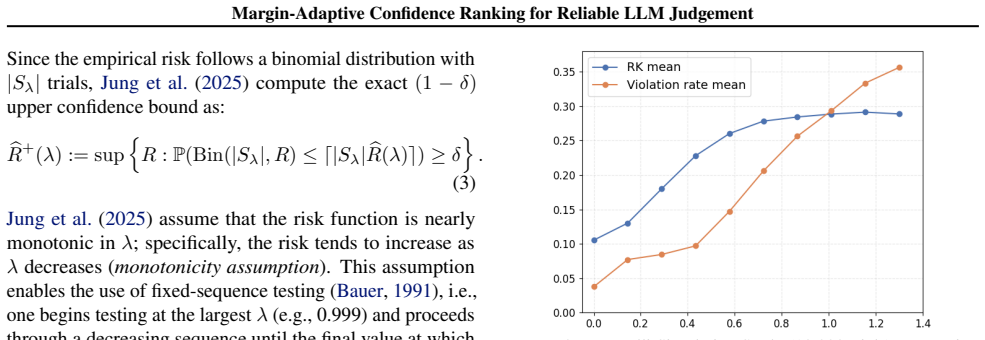



read the original abstract
Jung et al. (2025) introduce a hypothesis testing framework for guaranteeing agreement between large language models (LLMs) and human judgments, relying on the assumption that the model's estimated confidence is monotonic with respect to human-disagreement risk. In practice, however, this assumption may be violated, and the generalization behavior of the confidence estimator is not explicitly analyzed. We mitigate these issues by learning a dedicated confidence estimator instead of relying on heuristic confidence signals. Our approach leverages simulated annotator diversity and a margin-based ranking formulation to explicitly model how confidently an LLM distinguishes between human-agreement and human-disagreement cases. We further derive generalization guarantees for this estimator, revealing a margin-dependent trade-off that informs the design of an adaptive estimator training procedure. When integrated into fixed-sequence testing, the learned confidence estimator yields improved ranking accuracy and empirically strengthens the monotonic relationship between confidence and disagreement risk, leading to higher success rates in satisfying target agreement levels across multiple datasets and judge models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a margin-adaptive confidence ranking approach for reliable LLM judgments. It learns a dedicated confidence estimator using simulated annotator diversity and margin-based ranking to model distinctions between human-agreement and disagreement cases. Generalization guarantees are derived showing a margin-dependent trade-off, and the estimator is integrated into fixed-sequence testing, yielding improved ranking accuracy, strengthened monotonicity between confidence and disagreement risk, and higher success rates in meeting target agreement levels across multiple datasets and judge models.
Significance. If the central claims hold, this work could advance reliable use of LLMs in judgment tasks by addressing violations of the monotonicity assumption in standard confidence signals. The explicit modeling via margin-based formulation and derivation of generalization guarantees represent strengths, particularly the adaptive training procedure informed by the margin-dependent trade-off. Empirical validation across datasets and models adds to the potential impact in the field of reliable AI systems.
major comments (3)
- The confidence estimator is trained exclusively on simulated annotator diversity. However, the manuscript does not provide direct measurements such as distributional distances, calibration plots, or ablations comparing the simulated disagreement patterns to actual human multi-annotator variance. This is load-bearing for the transfer of the learned ranking behavior and the validity of the generalization bounds to real human-agreement guarantees.
- The generalization bound is presented as derived from the margin formulation. Please provide the full derivation to clarify whether it reduces to a quantity already fitted during training or remains independent, addressing potential circularity concerns.
- The reported empirical gains in ranking accuracy and success rates in fixed-sequence testing; it is unclear if these survive multiple-testing correction across the multiple datasets and judge models used. Additionally, confirm whether the selection of datasets and models was pre-specified to avoid post-hoc bias.
minor comments (2)
- The abstract mentions 'Jung et al. (2025)' but the full reference should be checked for consistency in the bibliography.
- Ensure consistent use of notation for the margin hyper-parameter and the adaptive estimator throughout the paper.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, indicating planned revisions where the manuscript can be strengthened without misrepresenting our contributions.
read point-by-point responses
-
Referee: The confidence estimator is trained exclusively on simulated annotator diversity. However, the manuscript does not provide direct measurements such as distributional distances, calibration plots, or ablations comparing the simulated disagreement patterns to actual human multi-annotator variance. This is load-bearing for the transfer of the learned ranking behavior and the validity of the generalization bounds to real human-agreement guarantees.
Authors: We agree that explicit validation of the simulation against real multi-annotator human data would strengthen the transfer argument. Our simulation is constructed to reproduce disagreement patterns observed in prior annotation studies, but we acknowledge the absence of direct distributional comparisons or calibration plots in the current version. In the revision we will add a dedicated limitations subsection that discusses the simulation assumptions, includes any feasible calibration analysis using existing single-annotator data, and explicitly flags comprehensive real-human multi-annotator validation as future work. This keeps the claims appropriately scoped while addressing the referee's concern. revision: partial
-
Referee: The generalization bound is presented as derived from the margin formulation. Please provide the full derivation to clarify whether it reduces to a quantity already fitted during training or remains independent, addressing potential circularity concerns.
Authors: The bound is derived from standard margin-based generalization theory applied to the ranking risk and is independent of the specific parameters fitted during training. It quantifies a margin-dependent trade-off that informs the adaptive training schedule but does not simply reproduce a training loss term. To eliminate any ambiguity, the revised manuscript will include the complete derivation in the appendix, with explicit steps separating the training objective from the theoretical guarantee. revision: yes
-
Referee: The reported empirical gains in ranking accuracy and success rates in fixed-sequence testing; it is unclear if these survive multiple-testing correction across the multiple datasets and judge models used. Additionally, confirm whether the selection of datasets and models was pre-specified to avoid post-hoc bias.
Authors: We will apply a Bonferroni correction to the reported statistical comparisons in the revised experimental section to confirm that the gains remain significant after accounting for multiple tests. The datasets and judge models were chosen according to criteria stated in the experimental setup (standard benchmarks covering diverse domains and model families) prior to running the experiments; all evaluated configurations are reported. We will add a short paragraph clarifying the pre-specification to address potential concerns about post-hoc selection. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper introduces a margin-based ranking formulation to learn a dedicated confidence estimator from simulated annotator diversity, then analytically derives generalization guarantees that expose a margin-dependent trade-off used to shape an adaptive training procedure. These elements are presented as forward derivations from the ranking objective rather than tautological redefinitions or fitted quantities renamed as predictions. Empirical results on ranking accuracy, strengthened monotonicity, and success rates in fixed-sequence testing are reported across multiple datasets and judge models, providing external evaluation points. No load-bearing self-citations, uniqueness theorems imported from prior author work, or ansatzes smuggled via citation appear in the abstract or described chain. The simulation-to-real transfer is an explicit modeling assumption rather than a hidden circular reduction, leaving the central claims self-contained against the stated inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- margin hyper-parameter
axioms (1)
- standard math Standard generalization bounds for margin-based ranking losses hold under the usual i.i.d. assumption on simulated annotator samples.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We adopt a pairwise ranking formulation … margin-based ranking loss: ℓ_γ(θ; x_i, x_j) := 1(C_θ(s_i) < C_θ(s_j) + γ)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Corollary 3.4 … RK(θ) ≤ dRK_γ(θ) + O(√(Φ(C_θ) + ln … / γ²(mp−1)))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2305.14975 , year=
Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback , author=. arXiv preprint arXiv:2305.14975 , year=
-
[2]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
- [4]
-
[5]
Advances in Neural Information Processing Systems , volume=
Alpacafarm: A simulation framework for methods that learn from human feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
work page 2000
-
[7]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
work page 1980
-
[8]
M. J. Kearns , title =
-
[9]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
work page 1983
-
[10]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
work page 2000
-
[11]
Suppressed for Anonymity , author=
-
[12]
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
work page 1981
-
[13]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
work page 1959
-
[14]
Explaining and Harnessing Adversarial Examples
Explaining and harnessing adversarial examples , author=. arXiv preprint arXiv:1412.6572 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
A PAC-Bayesian Approach to Spectrally-Normalized Margin Bounds for Neural Networks
A pac-bayesian approach to spectrally-normalized margin bounds for neural networks , author=. arXiv preprint arXiv:1707.09564 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Trust or escalate: Llm judges with provable guarantees for human agreement , author=. ICLR , year=
-
[17]
arXiv preprint arXiv:2402.10978 , year=
Language models with conformal factuality guarantees , author=. arXiv preprint arXiv:2402.10978 , year=
-
[18]
arXiv preprint arXiv:2405.01563 , year=
Mitigating llm hallucinations via conformal abstention , author=. arXiv preprint arXiv:2405.01563 , year=
-
[19]
Statistics in medicine , volume=
Multiple testing in clinical trials , author=. Statistics in medicine , volume=
-
[20]
International Conference on Machine Learning , pages=
Crfl: Certifiably robust federated learning against backdoor attacks , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[21]
Higher-order certification for randomized smoothing , author=. NeurIPS , year=
-
[22]
How robust are randomized smoothing based defenses to data poisoning? , author=. CVPR , year=
-
[23]
International Conference on Artificial Intelligence and Statistics , year=
Hidden cost of randomized smoothing , author=. International Conference on Artificial Intelligence and Statistics , year=
-
[24]
Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security , year=
Tss: Transformation-specific smoothing for robustness certification , author=. Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security , year=
work page 2021
-
[25]
Detection as regression: Certified object detection with median smoothing , author=. NeurIPS , year=
-
[26]
Certified Robustness for Top-k Predictions against Adversarial Perturbations via Randomized Smoothing , author=. ICLR , year=
-
[27]
Scalable certified segmentation via randomized smoothing , author=. ICML , year=
-
[28]
Certified defense to image transformations via randomized smoothing , author=. NeurIPS , year=
-
[29]
Boosting Randomized Smoothing with Variance Reduced Classifiers , author=. ICLR , year=
-
[30]
A framework for robustness certification of smoothed classifiers using f-divergences , author=. ICLR , year=
- [31]
-
[32]
Decoupled Weight Decay Regularization
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
International conference on machine learning , pages=
Batch normalization: Accelerating deep network training by reducing internal covariate shift , author=. International conference on machine learning , pages=. 2015 , organization=
work page 2015
- [34]
-
[35]
Journal of machine learning research , volume=
PAC-Bayesian generalisation error bounds for Gaussian process classification , author=. Journal of machine learning research , volume=
-
[36]
Enhancing Adversarial Training with Second-Order Statistics of Weights , author=. CVPR , year=
-
[37]
arXiv preprint arXiv:1906.02629 , year=
When does label smoothing help? , author=. arXiv preprint arXiv:1906.02629 , year=
-
[38]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Rethinking the inception architecture for computer vision , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[39]
Adversarial Distributional Training for Robust Deep Learning , url =
Dong, Yinpeng and Deng, Zhijie and Pang, Tianyu and Zhu, Jun and Su, Hang , booktitle =. Adversarial Distributional Training for Robust Deep Learning , url =
-
[40]
Distributionally Robust Deep Learning as a Generalization of Adversarial Training , journal=
Matthew Staib and Stefanie Jegelka , year=. Distributionally Robust Deep Learning as a Generalization of Adversarial Training , journal=
-
[41]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Distributionally Adversarial Attack , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2019 , month=. doi:10.1609/aaai.v33i01.33012253 , number=
-
[42]
Adversarial logit pairing , author=. arXiv preprint arXiv:1803.06373 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Evaluating and Understanding the Robustness of Adversarial Logit Pairing
Evaluating and understanding the robustness of adversarial logit pairing , author=. arXiv preprint arXiv:1807.10272 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Theoretically principled trade-off between robustness and accuracy , author=. ICML , year=
-
[45]
Improving robust fariness via balance adversarial training , author=. AAAI , year=
-
[46]
Advances in Neural Information Processing Systems , volume=
On the tradeoff between robustness and fairness , author=. Advances in Neural Information Processing Systems , volume=
-
[47]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Adversarial vertex mixup: Toward better adversarially robust generalization , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[48]
Advances in Neural Information Processing Systems , volume=
Adversarial weight perturbation helps robust generalization , author=. Advances in Neural Information Processing Systems , volume=
-
[49]
International Conference on Machine Learning , pages=
Overfitting in adversarially robust deep learning , author=. International Conference on Machine Learning , pages=. 2020 , organization=
work page 2020
-
[50]
International Conference on Learning Representations , year=
Improving adversarial robustness requires revisiting misclassified examples , author=. International Conference on Learning Representations , year=
-
[51]
arXiv preprint arXiv:1905.13736 , year=
Unlabeled data improves adversarial robustness , author=. arXiv preprint arXiv:1905.13736 , year=
-
[52]
Adversarially Robust Generalization Requires More Data
Adversarially robust generalization requires more data , author=. arXiv preprint arXiv:1804.11285 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
International Conference on Learning Representations , year=
Robustness May Be at Odds with Accuracy , author=. International Conference on Learning Representations , year=
-
[54]
arXiv preprint arXiv:1812.02637 , year=
Mma training: Direct input space margin maximization through adversarial training , author=. arXiv preprint arXiv:1812.02637 , year=
-
[55]
Advances in neural information processing systems , volume=
Imagenet classification with deep convolutional neural networks , author=. Advances in neural information processing systems , volume=
-
[56]
IEEE Signal processing magazine , volume=
Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups , author=. IEEE Signal processing magazine , volume=. 2012 , publisher=
work page 2012
-
[57]
Intriguing properties of neural networks
Intriguing properties of neural networks , author=. arXiv preprint arXiv:1312.6199 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
arXiv preprint arXiv:2002.05990 , year=
Skip connections matter: On the transferability of adversarial examples generated with resnets , author=. arXiv preprint arXiv:2002.05990 , year=
-
[59]
Adversarial examples in the physical world , author=
-
[60]
Towards Deep Learning Models Resistant to Adversarial Attacks
Towards deep learning models resistant to adversarial attacks , author=. arXiv preprint arXiv:1706.06083 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
2016 IEEE symposium on security and privacy (SP) , pages=
Distillation as a defense to adversarial perturbations against deep neural networks , author=. 2016 IEEE symposium on security and privacy (SP) , pages=. 2016 , organization=
work page 2016
-
[62]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Hilbert-based generative defense for adversarial examples , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[63]
Characterizing Adversarial Subspaces Using Local Intrinsic Dimensionality
Characterizing adversarial subspaces using local intrinsic dimensionality , author=. arXiv preprint arXiv:1801.02613 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
arXiv preprint arXiv:1705.07204 , year=
Ensemble adversarial training: Attacks and defenses , author=. arXiv preprint arXiv:1705.07204 , year=
-
[65]
Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks
Feature squeezing: Detecting adversarial examples in deep neural networks , author=. arXiv preprint arXiv:1704.01155 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[66]
Defense Against Adversarial Attacks Using Feature Scattering-based Adversarial Training , url =
Zhang, Haichao and Wang, Jianyu , booktitle =. Defense Against Adversarial Attacks Using Feature Scattering-based Adversarial Training , url =
-
[67]
Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples , author=. ICML , year=
-
[68]
Wide residual networks , author=. arXiv preprint arXiv:1605.07146 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[69]
Learning multiple layers of features from tiny images , author=. 2009 , publisher=
work page 2009
-
[70]
Reading digits in natural images with unsupervised feature learning , author=
-
[71]
2017 ieee symposium on security and privacy (sp) , pages=
Towards evaluating the robustness of neural networks , author=. 2017 ieee symposium on security and privacy (sp) , pages=. 2017 , organization=
work page 2017
-
[72]
Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks , author=. ICML , year=
-
[73]
Minimally distorted adversarial examples with a fast adaptive boundary attack , author=. ICML , year=
-
[74]
Square attack: a query-efficient black-box adversarial attack via random search , author=. ECCV , year=
-
[75]
Proceedings of the 2017 ACM on Asia conference on computer and communications security , pages=
Practical black-box attacks against machine learning , author=. Proceedings of the 2017 ACM on Asia conference on computer and communications security , pages=
work page 2017
-
[76]
An analysis of single-layer networks in unsupervised feature learning , author=. Proceedings of the fourteenth international conference on artificial intelligence and statistics , pages=. 2011 , organization=
work page 2011
-
[77]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Very deep convolutional networks for large-scale image recognition , author=. arXiv preprint arXiv:1409.1556 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[78]
arXiv preprint arXiv:2010.04819 , year=
How Does Mixup Help With Robustness and Generalization? , author=. arXiv preprint arXiv:2010.04819 , year=
-
[79]
Improved Regularization of Convolutional Neural Networks with Cutout
Improved regularization of convolutional neural networks with cutout , author=. arXiv preprint arXiv:1708.04552 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[80]
International Conference on Machine Learning , pages=
Adversarial risk and the dangers of evaluating against weak attacks , author=. International Conference on Machine Learning , pages=. 2018 , organization=
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.