Latent Video Prediction Learns Better World Models
Pith reviewed 2026-05-20 19:05 UTC · model grok-4.3
The pith
Latent prediction models for video show a distinct robustness profile across corruption, occlusion and time tests that favors their use as world models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Across the five axes of feature discriminability, corruption robustness, fine-grained discrimination, occlusion robustness, and sensitivity to temporal direction, latent-prediction models form a consistent profile: they handle pixel corruption with smaller drops in performance, retain usable class information under heavy occlusion instead of collapsing to geometric stability, detect fine physical contact events without pixel-level reconstruction, and encode the arrow of time in a way the other models do not.
What carries the argument
Systematic evaluation on five matched robustness axes that measure how video models behave under realistic degradations rather than clean top-1 accuracy alone.
If this is right
- A frozen V-JEPA 2 backbone with a lightweight probe can outperform a fully fine-tuned VideoMAE on corruption and occlusion tasks.
- World models built from latent prediction may remain functional in environments with sensor noise or partial views.
- Temporal direction awareness could support planning tasks that require distinguishing past from future states.
- Fine-grained contact cues captured without full reconstruction may transfer to robotic manipulation without expensive pixel synthesis.
Where Pith is reading between the lines
- The same latent-prediction advantage might appear in longer-horizon prediction or in combining video with other sensor streams.
- Design choices in new video models could prioritize latent targets over pixel targets when robustness is the goal.
- Direct tests on downstream control or simulation tasks would reveal whether the robustness profile translates into better decision making.
Load-bearing premise
The five selected robustness axes are the right and sufficient set of tests for judging whether a video model will function as a usable world model in deployment.
What would settle it
Finding that a reconstruction-based model such as VideoMAEv2 matches or exceeds latent-prediction models on every one of the five robustness axes when capacities are matched.
Figures









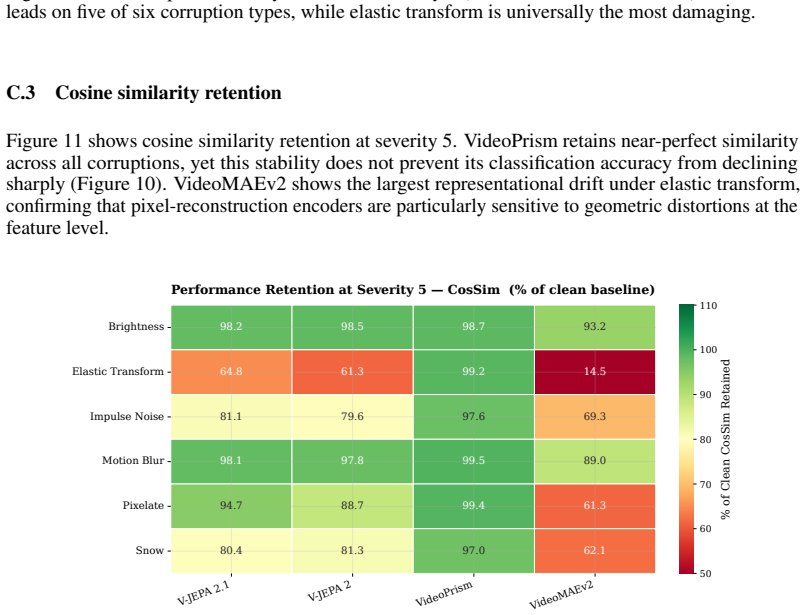


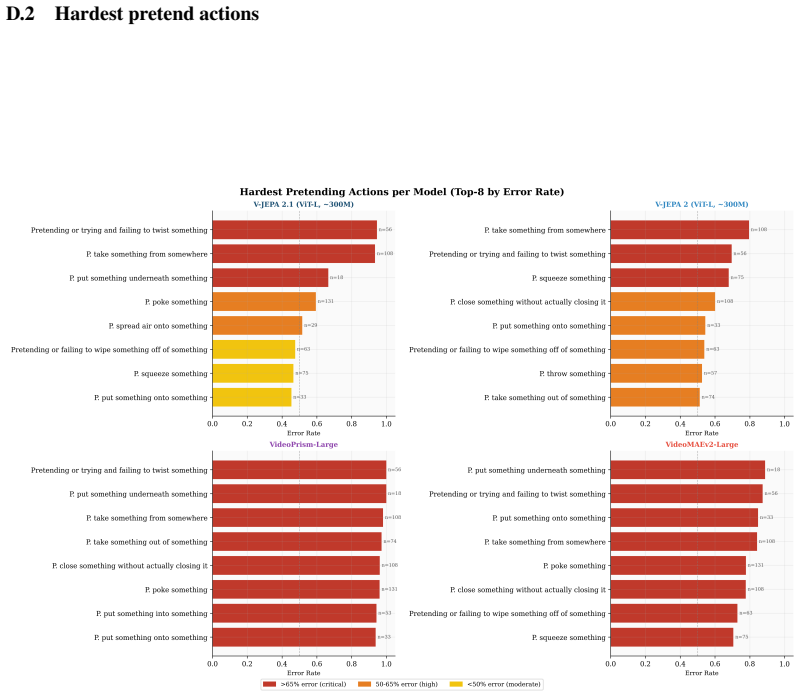
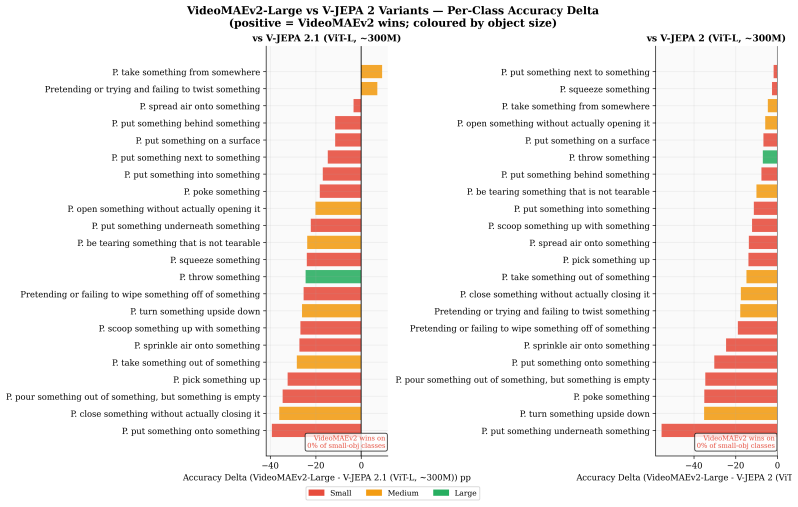

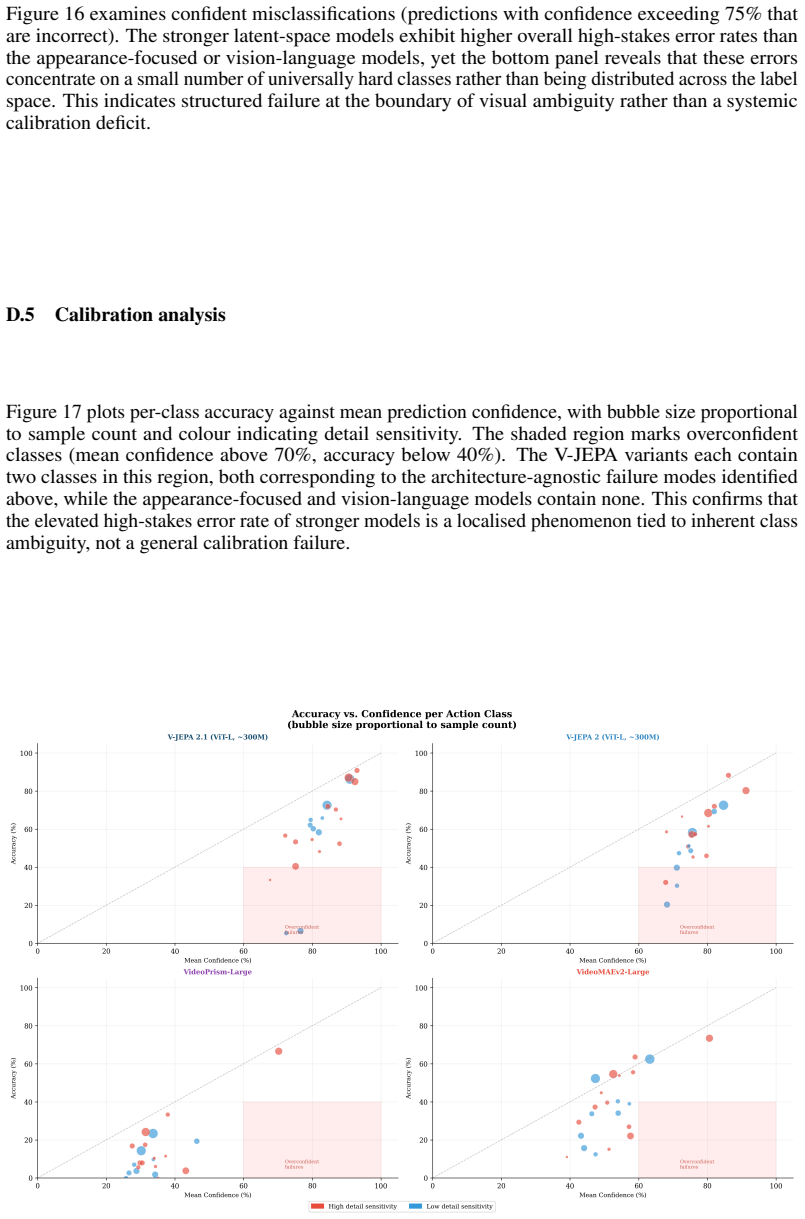










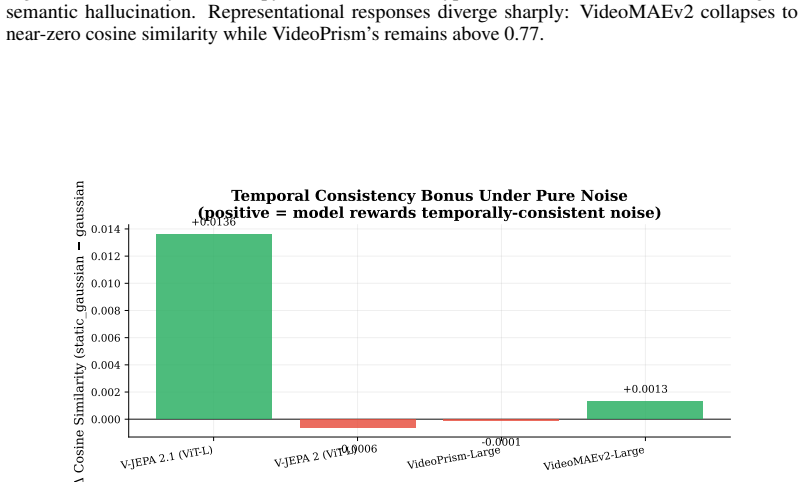


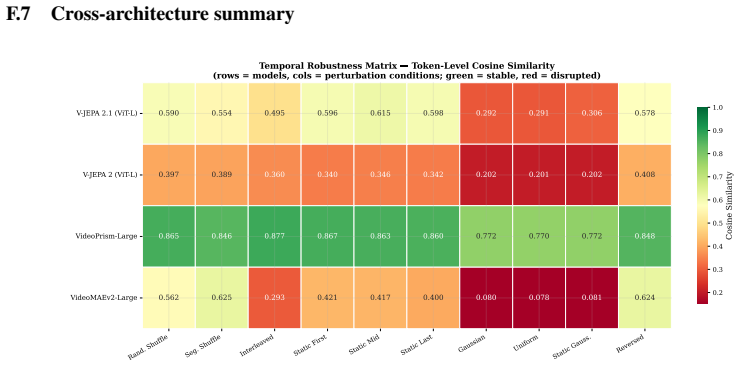
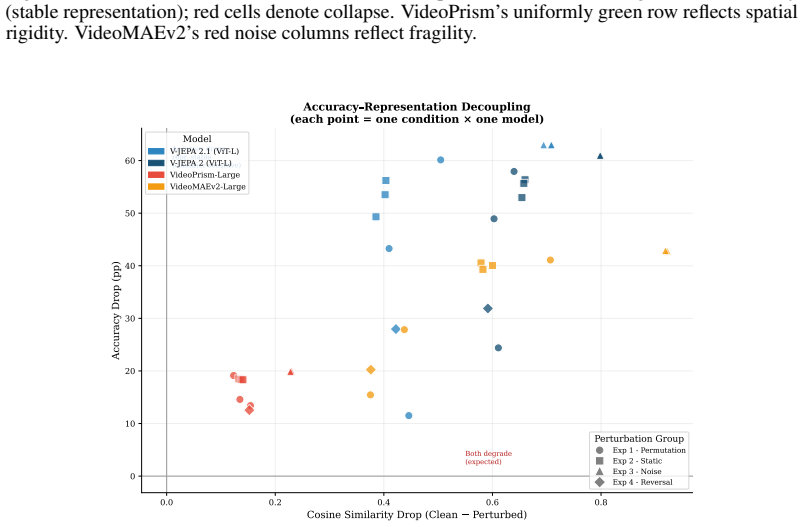
read the original abstract
Self-supervised video models are increasingly framed as world models, yet their evaluation remains largely confined to a single top-1 accuracy score on clean benchmarks. This leaves a major gap in comprehending their potential as world models. We present the first systematic study addressing this gap, analyzing four matched-capacity frontier video foundation models, V-JEPA 2.1, V-JEPA 2, VideoPrism, and VideoMAEv2, across five robustness axes relevant to their deployment as video world models: feature discriminability, corruption robustness, fine-grained discrimination, occlusion robustness, and sensitivity to temporal direction. Our evaluations establish that across all five axes, latent-prediction models form a distinct and consistent profile. They degrade more gracefully under pixel corruption, preserve usable class structure rather than mere geometric stability under occlusion, capture fine-grained physical contact cues without reconstructing pixels, and uniquely encode the arrow of time. These advantages can even survive task adaptation: a frozen V-JEPA 2 backbone with a lightweight attentive probe outperforms a fully fine-tuned VideoMAE and a supervised TimeSformer on corruption and occlusion robustness. Our extensive results offer concrete new evidence in favor of latent prediction for robust world modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that latent-prediction models (V-JEPA 2.1 and V-JEPA 2) form a distinct robustness profile superior to reconstruction-based models (VideoPrism and VideoMAEv2) across five axes—feature discriminability, corruption robustness, fine-grained discrimination, occlusion robustness, and sensitivity to temporal direction—when evaluated as video world models. It reports that these advantages include more graceful degradation under pixel corruption, preservation of class structure under occlusion, capture of physical contact cues without pixel reconstruction, and encoding of the arrow of time, with some benefits persisting under frozen-backbone task adaptation.
Significance. If the central attribution to the latent-prediction objective holds, the work supplies the first multi-axis empirical comparison of frontier video models as world models and offers concrete evidence that prediction targets can yield more robust representations than reconstruction. The survival of advantages after lightweight probing is a notable strength that strengthens the practical implications.
major comments (2)
- [Abstract and §1] Abstract and §1 (or equivalent methods section): the repeated claim that the four models are 'matched-capacity frontier video foundation models' is asserted without any supporting metrics such as parameter counts, FLOPs, layer depths, or effective capacity comparisons. This is load-bearing for the central attribution of the observed robustness profile specifically to the latent-prediction objective rather than scale differences.
- [Results sections on the five robustness axes] Results sections reporting the five axes (e.g., corruption, occlusion, temporal direction): the evaluations are described as establishing 'consistent' advantages, yet the supplied text provides no error bars, statistical significance tests, or exclusion criteria. This undermines the strength of the 'distinct and consistent profile' claim across all axes.
minor comments (1)
- [Figures and tables] Figure and table captions could more explicitly label which models belong to the latent-prediction versus reconstruction groups to improve immediate readability.
Simulated Author's Rebuttal
We are grateful to the referee for their insightful comments, which have helped us identify areas for improvement in our manuscript. Below, we provide detailed responses to the major comments and indicate the revisions we plan to make.
read point-by-point responses
-
Referee: [Abstract and §1] Abstract and §1 (or equivalent methods section): the repeated claim that the four models are 'matched-capacity frontier video foundation models' is asserted without any supporting metrics such as parameter counts, FLOPs, layer depths, or effective capacity comparisons. This is load-bearing for the central attribution of the observed robustness profile specifically to the latent-prediction objective rather than scale differences.
Authors: We thank the referee for pointing this out. Upon review, we recognize that while the models are selected as recent high-performing video foundation models with comparable scales as per their original publications, we did not include explicit capacity metrics in our manuscript. To strengthen the attribution to the prediction objective, we will revise the manuscript to include a table or section detailing parameter counts, FLOPs, and architectural depths for each model, confirming their matched capacity as frontier models. revision: yes
-
Referee: [Results sections on the five robustness axes] Results sections reporting the five axes (e.g., corruption, occlusion, temporal direction): the evaluations are described as establishing 'consistent' advantages, yet the supplied text provides no error bars, statistical significance tests, or exclusion criteria. This undermines the strength of the 'distinct and consistent profile' claim across all axes.
Authors: We agree that including measures of variability and statistical analysis would enhance the robustness of our claims. In the revised version, we will add error bars to the relevant figures and tables based on multiple runs, and include statistical significance tests (e.g., t-tests or Wilcoxon tests) to support the consistent advantages observed across the five axes. We will also clarify any exclusion criteria used in the evaluations. revision: yes
Circularity Check
No circularity in empirical comparative evaluation
full rationale
The paper is a purely empirical study that compares four video foundation models across five robustness axes using experimental evaluations. It contains no mathematical derivations, first-principles predictions, fitted parameters renamed as outputs, or self-referential definitions that reduce claims to their own inputs by construction. The central attribution of advantages to the latent-prediction objective rests on observed performance differences under the stated matched-capacity assumption, but this is an external experimental premise rather than a closed logical loop. No load-bearing steps invoke self-citations, ansatzes, or uniqueness theorems that collapse back onto the paper's own results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The four video foundation models have matched capacity
- domain assumption The five robustness axes adequately capture suitability for deployment as video world models
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArrowOfTime.leanarrow_from_z echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
latent-prediction models ... uniquely encode the arrow of time ... Directional Semantic Coherence Score (DSCS)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
four matched-capacity frontier video foundation models ... latent prediction ... V-JEPA 2.1, V-JEPA 2
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Self-supervised learning from images with a joint- embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint- embedding predictive architecture. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15619–15629, 2023
work page 2023
-
[3]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
V-jepa: Latent video prediction for visual representation learning
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mido Assran, and Nicolas Ballas. V-jepa: Latent video prediction for visual representation learning. 2023
work page 2023
-
[5]
Is space-time attention all you need for video understanding? InIcml, volume 2, page 4, 2021
Gedas Bertasius, Heng Wang, and Lorenzo Torresani. Is space-time attention all you need for video understanding? InIcml, volume 2, page 4, 2021
work page 2021
-
[6]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021
work page 2021
-
[7]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InInternational conference on machine learning, pages 1597–1607. PmLR, 2020
work page 2020
-
[8]
Quentin Garrido, Nicolas Ballas, Mahmoud Assran, Adrien Bardes, Laurent Najman, Michael Rabbat, Emmanuel Dupoux, and Yann LeCun. Intuitive physics understanding emerges from self-supervised pretraining on natural videos.arXiv preprint arXiv:2502.11831, 2025
-
[9]
Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, et al. The" something something" video database for learning and evaluating visual common sense. InProceedings of the IEEE international conference on computer vision, pages 5842– 5850, 2017
work page 2017
-
[10]
Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, et al. Bootstrap your own latent-a new approach to self-supervised learning.Advances in neural information processing systems, 33:21271–21284, 2020
work page 2020
-
[11]
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3):440, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[12]
Dream to Control: Learning Behaviors by Latent Imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[13]
Mastering Atari with Discrete World Models
Danijar Hafner, Timothy Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering atari with discrete world models.arXiv preprint arXiv:2010.02193, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[14]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Training Agents Inside of Scalable World Models
Danijar Hafner, Wilson Yan, and Timothy Lillicrap. Training agents inside of scalable world models.arXiv preprint arXiv:2509.24527, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022
work page 2022
-
[17]
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
Dan Hendrycks and Thomas Dietterich. Benchmarking neural network robustness to common corruptions and perturbations.arXiv preprint arXiv:1903.12261, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[18]
De-An Huang, Vignesh Ramanathan, Dhruv Mahajan, Lorenzo Torresani, Manohar Paluri, Li Fei-Fei, and Juan Carlos Niebles. What makes a video a video: Analyzing temporal information in video understanding models and datasets. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7366–7375, 2018
work page 2018
-
[19]
Interpreting physics in video world models.arXiv preprint arXiv:2602.07050, 2026
Sonia Joseph, Quentin Garrido, Randall Balestriero, Matthew Kowal, Thomas Fel, Shahab Bakhtiari, Blake Richards, and Mike Rabbat. Interpreting physics in video world models.arXiv preprint arXiv:2602.07050, 2026
-
[20]
A path towards autonomous machine intelligence version 0.9
Yann LeCun et al. A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27. Open Review, 62(1):1–62, 2022
work page 2022
-
[21]
Lorenzo Mur-Labadia, Matthew Muckley, Amir Bar, Mido Assran, Koustuv Sinha, Mike Rabbat, Yann LeCun, Nicolas Ballas, and Adrien Bardes. V-jepa 2.1: Unlocking dense features in video self-supervised learning.arXiv preprint arXiv:2603.14482, 2026
-
[22]
Intriguing properties of vision transformers
Muhammad Muzammal Naseer, Kanchana Ranasinghe, Salman H Khan, Munawar Hayat, Fahad Shahbaz Khan, and Ming-Hsuan Yang. Intriguing properties of vision transformers. Advances in Neural Information Processing Systems, 34:23296–23308, 2021
work page 2021
-
[23]
Genie 2: A large-scale foundation world model.URL: https://deepmind
Jack Parker-Holder, Philip Ball, Jake Bruce, Vibhavari Dasagi, Kristian Holsheimer, Christos Kaplanis, Alexandre Moufarek, Guy Scully, Jeremy Shar, Jimmy Shi, et al. Genie 2: A large-scale foundation world model.URL: https://deepmind. google/discover/blog/genie-2-a- large-scale-foundation-world-model, 2, 2024
work page 2024
-
[24]
Vision transformers are robust learners
Sayak Paul and Pin-Yu Chen. Vision transformers are robust learners. InProceedings of the AAAI conference on Artificial Intelligence, volume 36, pages 2071–2081, 2022
work page 2071
-
[25]
Only time can tell: Discovering temporal data for temporal modeling
Laura Sevilla-Lara, Shengxin Zha, Zhicheng Yan, Vedanuj Goswami, Matt Feiszli, and Lorenzo Torresani. Only time can tell: Discovering temporal data for temporal modeling. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 535–544, 2021
work page 2021
-
[26]
Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training.Advances in neural information processing systems, 35:10078–10093, 2022
work page 2022
-
[27]
Videomae v2: Scaling video masked autoencoders with dual masking
Limin Wang, Bingkun Huang, Zhiyu Zhao, Zhan Tong, Yinan He, Yi Wang, Yali Wang, and Yu Qiao. Videomae v2: Scaling video masked autoencoders with dual masking. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14549–14560, 2023
work page 2023
-
[28]
Sukmin Yun, Jaehyung Kim, Dongyoon Han, Hwanjun Song, Jung-Woo Ha, and Jinwoo Shin. Time is matter: Temporal self-supervision for video transformers.arXiv preprint arXiv:2207.09067, 2022
-
[29]
Long Zhao, Nitesh B Gundavarapu, Liangzhe Yuan, Hao Zhou, Shen Yan, Jennifer J Sun, Luke Friedman, Rui Qian, Tobias Weyand, Yue Zhao, et al. Videoprism: A foundational visual encoder for video understanding.arXiv preprint arXiv:2402.13217, 2024
-
[30]
DINO-WM: World Models on Pre-trained Visual Features enable Zero-shot Planning
Gaoyue Zhou, Hengkai Pan, Yann LeCun, and Lerrel Pinto. Dino-wm: World models on pre-trained visual features enable zero-shot planning.arXiv preprint arXiv:2411.04983, 2024. 11 This appendix provides extended experimental details and additional analyses for each section of the main paper. We begin with global methodological context in Appendix A (encoder ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.