Edit-GRPO: A Locality-Preserving Policy Optimization Framework for Image Editing
Pith reviewed 2026-05-19 20:41 UTC · model grok-4.3
The pith
Edit-GRPO decouples editing and preservation objectives with region-specific signals to keep image edits localized.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
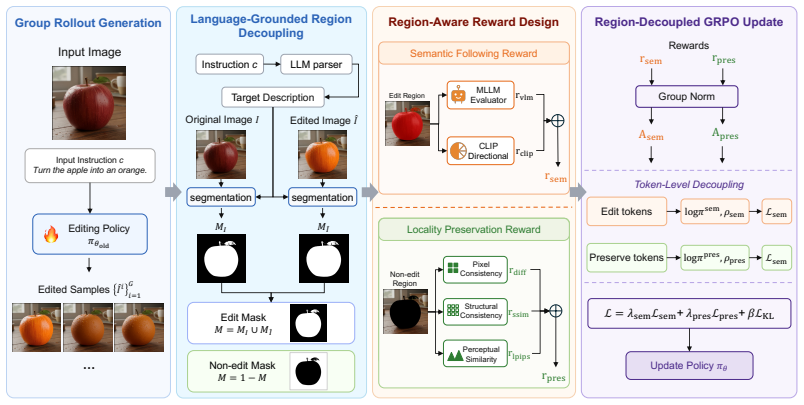
Edit-GRPO is a locality-preserving policy optimization framework that explicitly decouples editing and preservation objectives. By assigning region-specific optimization signals to edit and non-edit areas, it aligns policy updates with the spatial structure of editing tasks, enabling localized improvements while maintaining global visual coherence. This design effectively suppresses common artifacts such as context distortion and boundary inconsistency.
What carries the argument
Region-specific optimization signals that decouple editing rewards from preservation constraints during policy updates.
If this is right
- Targeted content improves without altering surrounding regions.
- Artifacts such as context distortion and boundary inconsistency decrease.
- Editing performance stays strong across multiple image editing scenarios.
- The same decoupling approach applies to a range of optimization-based editing tasks.
Where Pith is reading between the lines
- The framework could integrate with automatic region proposal networks to reduce manual mask input.
- Extending the region signals to video frames might support consistent edits over time.
- Similar objective separation could address locality issues in other generative domains like text-to-image synthesis.
Load-bearing premise
That assigning region-specific optimization signals will align policy updates with spatial structure without needing extra mechanisms to handle boundary effects or context interactions.
What would settle it
An experiment in which Edit-GRPO still produces large unintended changes in non-edit regions on images containing interacting objects near edit boundaries.
Figures







read the original abstract
A fundamental challenge in image editing lies in preserving spatial locality: edits should improve targeted content without inadvertently altering surrounding regions. However, most optimization-based editing approaches treat images as holistic entities, causing global policy updates that undermine locality and introduce undesired context changes. We observe that this issue stems from a mismatch between localized editing intent and globally applied optimization signals. Motivated by this insight, we propose Edit-GRPO, preserving Locality while optimizing image editing, a locality-preserving policy optimization framework that explicitly decouples editing and preservation objectives. By assigning region-specific optimization signals to edit and non-edit areas, Edit-GRPO aligns policy updates with the spatial structure of editing tasks, enabling localized improvements while maintaining global visual coherence. This design effectively suppresses common artifacts such as context distortion and boundary inconsistency. Extensive experiments across diverse image editing scenarios demonstrate that Edit-GRPO significantly improves locality preservation while maintaining strong editing performance compared to existing optimization-based methods, validating the generality and effectiveness of the proposed framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Edit-GRPO, a locality-preserving policy optimization framework for image editing. It argues that global optimization signals in existing methods cause undesired context changes, and introduces region-specific optimization signals assigned separately to edit and non-edit regions to decouple editing and preservation objectives. This alignment with spatial structure is claimed to suppress artifacts such as context distortion and boundary inconsistency while preserving editing performance, with validation via extensive experiments across diverse scenarios showing significant improvements in locality preservation over prior optimization-based methods.
Significance. If the experimental claims hold with rigorous controls, the framework could meaningfully advance optimization-based image editing by addressing a core mismatch between localized intent and global updates in generative models. The explicit decoupling via region-specific signals offers a generalizable design principle that may apply beyond the reported scenarios. No machine-checked proofs or parameter-free derivations are present, but the emphasis on spatial alignment and reproducibility of the approach (if code is released) would strengthen its contribution to the field.
major comments (2)
- [§3.2] §3.2 (Region-Specific Optimization): The central mechanism assigns distinct signals to edit vs. non-edit regions to achieve locality without additional boundary handling. However, for models relying on global attention or convolutional receptive fields, this does not address potential gradient propagation or context mixing across region boundaries, which directly undermines the claim that the design 'effectively suppresses' boundary inconsistency and context distortion.
- [§5] §5 (Experiments): The abstract and results section describe improvements only at a high level ('significantly improves locality preservation') without reporting specific quantitative metrics, baseline comparisons, statistical tests, or ablation on boundary effects. This makes it impossible to verify whether the reported gains are robust or affected by post-hoc region mask choices, which is load-bearing for the central experimental claim.
minor comments (2)
- [§3] Notation for the region masks and optimization signals (e.g., how the preservation signal is formulated mathematically) could be clarified with an explicit equation in §3 to avoid ambiguity in implementation.
- [§2] The related work section should include a direct comparison table to recent locality-aware editing methods to better position the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, providing clarifications and indicating where revisions have been made to strengthen the presentation and evidence.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Region-Specific Optimization): The central mechanism assigns distinct signals to edit vs. non-edit regions to achieve locality without additional boundary handling. However, for models relying on global attention or convolutional receptive fields, this does not address potential gradient propagation or context mixing across region boundaries, which directly undermines the claim that the design 'effectively suppresses' boundary inconsistency and context distortion.
Authors: We appreciate the referee's point on the potential limitations of region-specific signals in the presence of global attention mechanisms. In Edit-GRPO, the decoupling is achieved by applying distinct reward functions and computing masked policy gradients separately for edit and non-edit regions. This structure ensures that the preservation objective in non-edit areas actively counters changes that could result from cross-boundary gradient flow. While the original submission relied primarily on empirical validation rather than a dedicated gradient propagation analysis, the consistent reduction in boundary artifacts across experiments supports the effectiveness of this approach. In the revised manuscript, we have expanded the discussion in §3.2 to explicitly address interactions with global attention and added attention map visualizations demonstrating localized update patterns. revision: yes
-
Referee: [§5] §5 (Experiments): The abstract and results section describe improvements only at a high level ('significantly improves locality preservation') without reporting specific quantitative metrics, baseline comparisons, statistical tests, or ablation on boundary effects. This makes it impossible to verify whether the reported gains are robust or affected by post-hoc region mask choices, which is load-bearing for the central experimental claim.
Authors: We thank the referee for this observation. The experiments in Section 5 report quantitative comparisons using locality preservation metrics and editing performance measures against prior optimization-based methods, along with qualitative results across diverse scenarios. We agree that additional statistical rigor and boundary-specific analysis would enhance verifiability. The revised manuscript now includes explicit numerical values with standard deviations, baseline tables with direct metric comparisons, t-test results for significance, and an ablation study on region mask variations to assess robustness to post-hoc choices. revision: yes
Circularity Check
No circularity: framework introduced as explicit design choice
full rationale
The paper motivates Edit-GRPO from an observed mismatch between localized editing intent and global optimization signals, then proposes the framework as a design that assigns region-specific signals to decouple objectives. No equations, fitted parameters, or derivation steps appear in the provided text that would reduce any claim to its own inputs by construction. The approach is presented as a methodological choice rather than a prediction derived from prior results or self-citations, and validation is external via experiments. This keeps the contribution self-contained without circular reduction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By assigning region-specific optimization signals to edit and non-edit areas, Edit-GRPO aligns policy updates with the spatial structure of editing tasks... L=λ_sem L_sem + λ_pres L_pres + β L_KL
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We partition the images into edit regions and non-edit regions, and design different rewards separately... logπ_sem_θ = 1/|M| Σ_{k∈M} logπ_θ^(k)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jinbin Bai, Wei Chow, Ling Yang, Xiangtai Li, Juncheng Li, Hanwang Zhang, and Shuicheng Yan. Humanedit: A high-quality human-rewarded dataset for instruction-based image editing.arXiv preprint arXiv:2412.04280, 2024
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Training Diffusion Models with Reinforcement Learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning.arXiv preprint arXiv:2305.13301, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
arXiv preprint arXiv:2211.09800 , year=
Tim Brooks, Aleksander Holynski, and Alexei A Efros. Instructpix2pix: Learning to follow image editing instructions.arXiv preprint arXiv:2211.09800, 2022
-
[5]
HiDream-I1: A High-Efficient Image Generative Foundation Model with Sparse Diffusion Transformer
Qi Cai, Jingwen Chen, Yang Chen, Yehao Li, Fuchen Long, Yingwei Pan, Zhaofan Qiu, Yiheng Zhang, Feng Gao, Peihan Xu, Yimeng Wang, Kai Yu, Wenxuan Chen, Ziwei Feng, Zi-Qiang Gong, Jia-Wern Pan, Yingzhi Peng, Rui Tian, Siyu Wang, Bo Zhao, Ting Yao, and Tao Mei. Hidream-i1: A high-efficient image generative foundation model with sparse diffusion transformer....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman Rädle, Triantafyllos Afouras, Effrosyni Mavroudi, Katherine Xu, Tsung-Han Wu, Yu Zhou, Liliane ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiao- Ping Nie, Ziang Song, Shi Guang, and Haoqi Fan. Emerging properties in unified multimodal pretraining. ArXiv, abs/2505.14683, 2025. URLhttps://api.semanticscholar.org/CorpusID:278768720
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
work page 2024
-
[9]
arXiv preprint arXiv:2305.16381 , year=
Ying Fan, Olivia Watkins, Yuqing Du, Hao Liu, Moonkyung Ryu, Craig Boutilier, P. Abbeel, Mohammad Ghavamzadeh, Kangwook Lee, and Kimin Lee. Dpok: Reinforcement learning for fine-tuning text-to- image diffusion models.ArXiv, abs/2305.16381, 2023. URL https://api.semanticscholar.org/ CorpusID:258947323
-
[10]
Yuan Gong, Xionghui Wang, Jie Wu, Shiyin Wang, Yitong Wang, and Xinglong Wu. Onereward: Unified mask-guided image generation via multi-task human preference learning.arXiv preprint arXiv:2508.21066, 2025
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
work page 2020
-
[13]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE
Junzhe Li, Yutao Cui, Tao Huang, Yinping Ma, Chun Fan, Yiming Cheng, Miles Yang, Zhao Zhong, and Liefeng Bo. Mixgrpo: Unlocking flow-based grpo efficiency with mixed ode-sde.arXiv preprint arXiv:2507.21802, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Zongjian Li, Zheyuan Liu, Qihui Zhang, Bin Lin, Feize Wu, Shenghai Yuan, Zhiyuan Yan, Yang Ye, Wangbo Yu, Yuwei Niu, et al. Uniworld-v2: Reinforce image editing with diffusion negative-aware finetuning and mllm implicit feedback.arXiv preprint arXiv:2510.16888, 2025
-
[16]
UniWorld-V1: High-Resolution Semantic Encoders for Unified Visual Understanding and Generation
Bin Lin, Zongjian Li, Xinhua Cheng, Yuwei Niu, Yang Ye, Xianyi He, Shenghai Yuan, Wangbo Yu, Shaodong Wang, Yunyang Ge, Yatian Pang, and Li Yuan. Uniworld-v1: High-resolution semantic encoders for unified visual understanding and generation.ArXiv, abs/2506.03147, 2025. URL https: //api.semanticscholar.org/CorpusID:279119654
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
Flow-GRPO: Training Flow Matching Models via Online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Step1X-Edit: A Practical Framework for General Image Editing
Shiyu Liu, Yucheng Han, Peng Xing, Fukun Yin, Rui Wang, Wei Cheng, Jiaqi Liao, Yingming Wang, Honghao Fu, Chunrui Han, et al. Step1x-edit: A practical framework for general image editing.arXiv preprint arXiv:2504.17761, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
Sdedit: Guided image synthesis and editing with stochastic differential equations
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equations. InInternational Conference on Learning Representations, 2021. URL https://api.semanticscholar.org/CorpusID:245704504
work page 2021
-
[23]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
work page 2022
-
[24]
William S. Peebles and Saining Xie. Scalable diffusion models with transformers.2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 4172–4182, 2022. URL https://api. semanticscholar.org/CorpusID:254854389
work page 2023
-
[25]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model.ArXiv, abs/2305.18290,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
URLhttps://api.semanticscholar.org/CorpusID:258959321
-
[27]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
work page 2022
-
[28]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.ArXiv, abs/1707.06347, 2017. URL https://api.semanticscholar.org/ CorpusID:28695052
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.ArXiv, abs/2010.02502, 2020. URLhttps://api.semanticscholar.org/CorpusID:222140788
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[31]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Narain Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.ArXiv, abs/2011.13456,
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[32]
URLhttps://api.semanticscholar.org/CorpusID:227209335
-
[33]
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq R. Joty, and Nikhil Naik. Diffusion model alignment using direct preference optimization.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8228–8238, 2023. URLhttps://api.semanticscholar.org/CorpusID...
work page 2024
-
[34]
Qian Wang, Biao Zhang, Michael Birsak, and Peter Wonka. Instructedit: Improving automatic masks for diffusion-based image editing with user instructions.ArXiv, abs/2305.18047, 2023. URL https: //api.semanticscholar.org/CorpusID:258959425. 11
-
[35]
Unified Reward Model for Multimodal Understanding and Generation
Yibin Wang, Yuhang Zang, Hao Li, Cheng Jin, and Jiaqi Wang. Unified reward model for multimodal understanding and generation.arXiv preprint arXiv:2503.05236, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Rewarddance: Reward scaling in visual generation.ArXiv, abs/2509.08826, 2025
Jie Wu, Yu Gao, Zi-Nuo Ye, Ming Li, Liang Li, Hanzhong Guo, Jie Liu, Zeyue Xue, Xiaoxia Hou, Wei Liu, Yangyang Zeng, and Weilin Huang. Rewarddance: Reward scaling in visual generation.ArXiv, abs/2509.08826, 2025. URLhttps://api.semanticscholar.org/CorpusID:281247213
-
[38]
Keming Wu, Sicong Jiang, Max Ku, Ping Nie, Minghao Liu, and Wenhu Chen. Editreward: A human- aligned reward model for instruction-guided image editing.arXiv preprint arXiv:2509.26346, 2025
-
[39]
Omnigen: Unified image generation
Shitao Xiao, Yueze Wang, Junjie Zhou, Huaying Yuan, Xingrun Xing, Ruiran Yan, Chaofan Li, Shuting Wang, Tiejun Huang, and Zheng Liu. Omnigen: Unified image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13294–13304, 2025
work page 2025
-
[40]
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation.ArXiv, abs/2304.05977, 2023. URLhttps://api.semanticscholar.org/CorpusID:258079316
-
[41]
Jiazheng Xu, Yu Huang, Jiale Cheng, Yuanming Yang, Jiajun Xu, Yuan Wang, Wenbo Duan, Shen Yang, Qunlin Jin, Shurun Li, et al. Visionreward: Fine-grained multi-dimensional human preference learning for image and video generation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 11269–11277, 2026
work page 2026
-
[42]
DanceGRPO: Unleashing GRPO on Visual Generation
Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, et al. Dancegrpo: Unleashing grpo on visual generation.arXiv preprint arXiv:2505.07818, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Qwen An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxin Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin,...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
ImgEdit: A Unified Image Editing Dataset and Benchmark
Yang Ye, Xianyi He, Zongjian Li, Bin Lin, Shenghai Yuan, Zhiyuan Yan, Bohan Hou, and Li Yuan. Imgedit: A unified image editing dataset and benchmark.ArXiv, abs/2505.20275, 2025. URL https: //api.semanticscholar.org/CorpusID:278911803
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Kai Zhang, Lingbo Mo, Wenhu Chen, Huan Sun, and Yu Su. Magicbrush: A manually annotated dataset for instruction-guided image editing.ArXiv, abs/2306.10012, 2023. URL https://api.semanticscholar. org/CorpusID:259187796
-
[46]
Qihui Zhang, Munan Ning, Zheyuan Liu, Yanbo Wang, Jiayi Ye, Yue Huang, Shuo Yang, Xiao Chen, Yibing Song, and Li Yuan. Upme: An unsupervised peer review framework for multimodal large language model evaluation.2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9165–9174, 2025. URLhttps://api.semanticscholar.org/CorpusID:277113471
work page 2025
-
[47]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
work page 2018
-
[48]
DiffusionNFT: Online Diffusion Reinforcement with Forward Process
Kaiwen Zheng, Huayu Chen, Haotian Ye, Haoxiang Wang, Qinsheng Zhang, Kai Jiang, Hang Su, Stefano Ermon, Jun Zhu, and Ming-Yu Liu. Diffusionnft: Online diffusion reinforcement with forward process. arXiv preprint arXiv:2509.16117, 2025. 12 A Implementation Details A.1 Training Details In our implementation, we use FLUX.1-Kontext [Dev] [13] and Qwen-Image-E...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.