When Efficiency Backfires: Cascading LLMs Trigger Cascade Failure under Adversarial Attack
Pith reviewed 2026-05-19 23:55 UTC · model grok-4.3
The pith
Adversarial attacks exploit LLM cascade designs to degrade both accuracy and efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LLM cascade systems are susceptible to targeted adversarial manipulation which disrupts both performance objectives and the intended cost advantages of the cascade design. A novel attack framework employs constrained sequential collaborative optimization of adversarial suffixes under cascade dependencies, enabling simultaneous exploitation of lightweight models and decision mechanisms while adapting to adversaries with varying capabilities to induce controllable degradation in both cost-efficiency and accuracy, achieving significantly stronger impact than prior attacks targeting standalone models.
What carries the argument
Constrained sequential collaborative optimization of adversarial suffixes under cascade dependencies, which jointly targets the lightweight models and the internal escalation decisions.
If this is right
- The attack succeeds against adversaries with limited or full access to the cascade internals.
- Both accuracy and computational cost can be degraded at the same time through one optimized suffix.
- The method produces measurably larger damage than attacks designed without knowledge of the cascade routing.
- Results hold across multiple datasets and existing LLM cascade implementations.
Where Pith is reading between the lines
- Cascade designers may need to add checks that verify routing decisions independently of the models themselves.
- Similar routing-based vulnerabilities could affect other staged AI systems that use early filters for efficiency.
- Defenses could focus on hardening only the decision layer while preserving the speed of the lightweight front end.
Load-bearing premise
The inclusion of lightweight front-end models and internal decision mechanisms in the cascade design expands the attack surface in ways that prior standalone-model attacks cannot exploit.
What would settle it
An experiment in which the cascade-specific attack produces no greater drop in accuracy or rise in cost than a standard single-model attack on the same lightweight or heavy models would falsify the claim of a structurally stronger exploit.
Figures


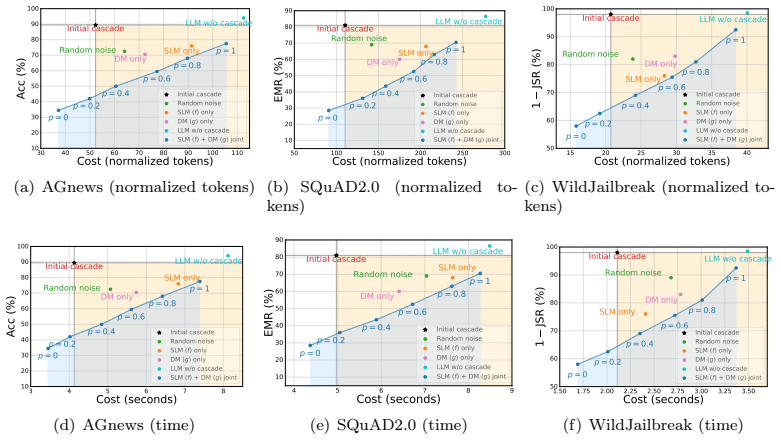






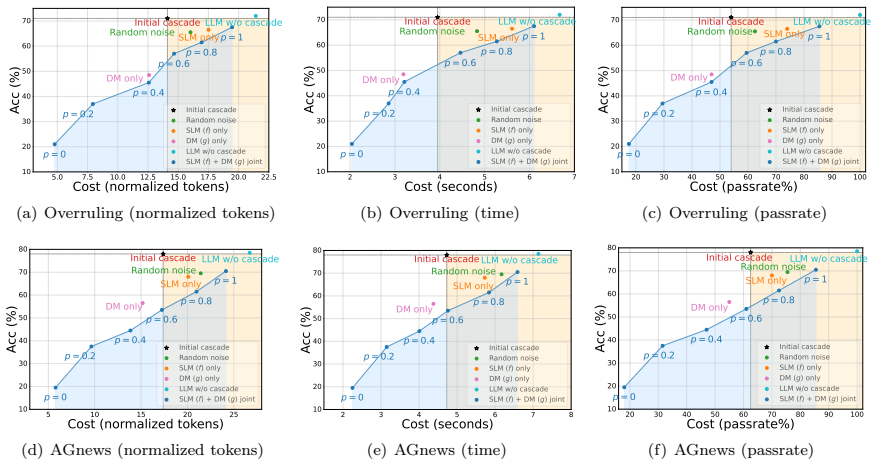



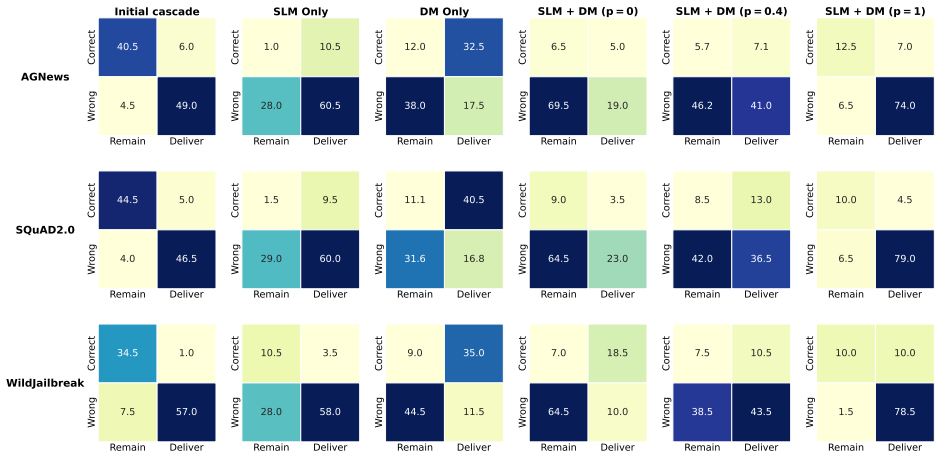
read the original abstract
Large Language Model (LLM) cascade systems are designed to balance efficiency and performance by processing queries with lightweight models while selectively escalating complex cases to more powerful ones. Such systems seek to reduces computational cost and latency while maintaining task performance, making it an appealing choice for large-scale deployment. However, the cascade design introduces new vulnerabilities through an expanded attack surface: the inclusion of lightweight front-end models and internal decision mechanisms introduces new weaknesses. In this work, we present the first study demonstrating that LLM cascade systems are susceptible to targeted adversarial manipulation, which disrupts both performance objectives and the intended cost advantages of the cascade design. We propose a novel attack framework that employs constrained sequential collaborative optimization of adversarial suffix under cascade dependencies, enabling simultaneous exploitation of lightweight models and decision mechanisms. This framework adapts to adversaries with varying capabilities, inducing controllable degradation in both cost-efficiency and accuracy. Unlike prior attacks targeting standalone models, our approach strategically leverages the cascade structure to achieve significantly stronger impact. Extensive experiments across diverse datasets and representative LLM cascade systems validate the practicality and severity of this attack. Our findings highlight the urgent need to rigorously scrutinize the security of LLM cascade systems and call for broader attention to the systemic risks inherent in such designs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM cascade systems—designed to route simple queries to lightweight front-end models and escalate complex ones to powerful back-ends—are vulnerable to a novel adversarial attack. The authors introduce a constrained sequential collaborative optimization framework that exploits both the front-end models and the internal decision/routing mechanisms under cascade dependencies. They argue this produces stronger degradation of both accuracy and cost-efficiency than prior standalone-model attacks, supported by extensive experiments across datasets and representative cascade systems. The work positions itself as the first study on targeted manipulation of such systems.
Significance. If the central claims hold, the result would be significant for the security of efficiency-focused LLM deployments, as it directly challenges the cost-saving rationale of cascades by showing how their expanded attack surface can be exploited to increase both error rates and computational overhead. The emphasis on controllable degradation and adaptation to adversary capabilities is a positive aspect. No machine-checked proofs, parameter-free derivations, or open reproducible code are referenced in the provided text.
major comments (3)
- [Attack Framework] Attack framework description: The claim that the method 'strategically leverages the cascade structure' to achieve significantly stronger impact requires an explicit formulation (e.g., objective or constraint terms) showing how cascade dependencies and routing decisions enter the optimization. Without this, it remains possible that the attack reduces to sequential front-end optimization, as the skeptic note suggests.
- [Experiments] Experimental validation: No ablation isolating the cascade-dependency term is described. A direct comparison to a baseline that attacks the lightweight model independently (ignoring routing) is needed to establish that the reported gains in accuracy and cost degradation are cascade-specific rather than generic multi-model effects.
- [Abstract] Abstract and results: The abstract asserts 'significantly stronger impact' and 'controllable degradation' but supplies no concrete success metrics, datasets, or quantitative comparisons. This absence makes it impossible to verify the load-bearing claim that the attack disrupts the intended cost advantages of the cascade design.
minor comments (3)
- [Abstract] Grammatical issue: 'seek to reduces computational cost' should read 'seek to reduce computational cost'.
- [Introduction] Related work: Ensure comprehensive citation of prior adversarial attacks on LLMs and any existing work on multi-model or routing-based systems to clarify novelty.
- [Experiments] Reproducibility: Tables or figures reporting attack success rates or latency/cost increases should include error bars, number of runs, and exact hyperparameter settings.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, indicating the revisions we will make to strengthen the presentation and validation of our claims.
read point-by-point responses
-
Referee: [Attack Framework] Attack framework description: The claim that the method 'strategically leverages the cascade structure' to achieve significantly stronger impact requires an explicit formulation (e.g., objective or constraint terms) showing how cascade dependencies and routing decisions enter the optimization. Without this, it remains possible that the attack reduces to sequential front-end optimization, as the skeptic note suggests.
Authors: We agree that greater explicitness will remove any potential ambiguity. The constrained sequential collaborative optimization framework incorporates cascade dependencies by augmenting the objective with terms that model the routing decision: the adversarial suffix is optimized jointly to degrade the front-end prediction while also influencing the escalation trigger (e.g., via constraints that penalize or reward escalation outcomes). This is described conceptually in Section 3, but we will add the full mathematical objective and constraint set in the revision so that the dependence on routing is stated formally rather than left implicit. revision: yes
-
Referee: [Experiments] Experimental validation: No ablation isolating the cascade-dependency term is described. A direct comparison to a baseline that attacks the lightweight model independently (ignoring routing) is needed to establish that the reported gains in accuracy and cost degradation are cascade-specific rather than generic multi-model effects.
Authors: This is a fair request for isolating the contribution of the cascade structure. Our current experiments compare against prior standalone-model attacks, which already show larger degradation than those baselines; however, we will add a new ablation that directly contrasts our full cascade-aware attack against an independent front-end-only optimization that ignores the escalation mechanism. The results of this comparison will be reported in the revised experimental section to quantify the incremental benefit attributable to modeling cascade dependencies. revision: yes
-
Referee: [Abstract] Abstract and results: The abstract asserts 'significantly stronger impact' and 'controllable degradation' but supplies no concrete success metrics, datasets, or quantitative comparisons. This absence makes it impossible to verify the load-bearing claim that the attack disrupts the intended cost advantages of the cascade design.
Authors: While the abstract is deliberately concise, we accept that including a few concrete indicators would make the central claims easier to evaluate at a glance. In the revision we will update the abstract to reference representative quantitative outcomes (e.g., accuracy degradation and cost-increase percentages on the evaluated datasets) together with the comparison to prior attacks. The detailed metrics, tables, and figures already appear in the experimental results; the abstract change will simply surface the key numbers earlier. revision: yes
Circularity Check
No circularity: empirical attack framework rests on external experiments, not internal redefinition
full rationale
The paper presents a novel attack framework for LLM cascades via constrained sequential collaborative optimization under cascade dependencies, claiming stronger impact than standalone attacks. No equations, fitted parameters, or self-referential definitions appear in the provided text that would reduce any claimed result to its inputs by construction. The central claims are positioned as validated through extensive experiments on diverse datasets and systems, with no load-bearing self-citations or uniqueness theorems invoked from prior author work. This is a standard empirical security study whose validity is externally falsifiable rather than tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Ale- man, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 tech- nical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
The claude 3 model family: Opus, sonnet, haiku, 2024
Anthropic. The claude 3 model family: Opus, sonnet, haiku, 2024. Anthropic Technical Re- port
work page 2024
-
[3]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Sori- cut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a fam- ily of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, YuHan, FeiHuang, etal. Qwentechnicalreport. arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chenzhuang Du, Chu Wei, et al. Kimi-vl technical report.arXiv preprint arXiv:2504.07491, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Lei Li et al. Cascadebert: Accelerating infer- ence of pre-trained language models via cali- brated complete models cascade. InFindings of the Association for Computational Linguistics: EMNLP 2021, 2021
work page 2021
-
[8]
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
Lingjiao Chen, Matei Zaharia, and James Zou. Frugalgpt: How to use large language models while reducing cost and improving performance. arXiv preprint arXiv:2305.05176, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Navigating uncertainty: optimizing api dependency for hallucination re- duction in closed-book qa
Pierre Erbacher et al. Navigating uncertainty: optimizing api dependency for hallucination re- duction in closed-book qa. InEuropean Con- ference on Information Retrieval, Cham, 2024. Springer Nature Switzerland
work page 2024
-
[10]
Lingjiao Chen et al. Are more llm calls all you need? towards the scaling properties of com- pound ai systems.Advances in Neural Informa- tion Processing Systems, 37:45767–45790, 2024
work page 2024
-
[11]
Llm cascade with multi- objective optimal consideration
Kai Zhang et al. Llm cascade with multi- objective optimal consideration. 2024
work page 2024
-
[12]
Mixture-of-Agents Enhances Large Language Model Capabilities
Junlin Wang et al. Mixture-of-agents enhances largelanguagemodelcapabilities.arXiv preprint arXiv:2406.04692, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Mixllm: Dynamic routing in mixed large language models.arXiv preprint arXiv:2502.18482, 2025
Xinyuan Wang et al. Mixllm: Dynamic routing in mixed large language models.arXiv preprint arXiv:2502.18482, 2025
-
[14]
Dong Chen et al. Improving large models with small models: Lower costs and better perfor- mance.Neural Networks, page 108276, 2025
work page 2025
-
[15]
Jianpeng Zhou et al. Adaptive-solver frame- work for dynamic strategy selection in large lan- guage model reasoning.Information Processing & Management, 62(3):104052, 2025
work page 2025
-
[16]
On- line cascade learning for efficient inference over streams.arXiv preprint arXiv:2402.04513, 2024
Lunyiu Nie, Zhimin Ding, Erdong Hu, Christo- pher Jermaine, and Swarat Chaudhuri. On- line cascade learning for efficient inference over streams.arXiv preprint arXiv:2402.04513, 2024
-
[17]
On optimal caching and model multiplexing for large model inference
Banghua Zhu et al. On optimal caching and model multiplexing for large model inference. arXiv preprint arXiv:2306.02003, 2023. 18
-
[18]
Jieyu Zhang et al. Ecoassistant: Using llm as- sistant more affordably and accurately.arXiv preprint arXiv:2310.03046, 2023
-
[19]
Language model cascades: Token-level uncertainty and beyond.arXiv preprint arXiv:2404.10136, 2024
Neha Gupta et al. Language model cascades: Token-level uncertainty and beyond.arXiv preprint arXiv:2404.10136, 2024
-
[20]
Large language model cas- cades with mixture of thought representations for cost-efficient reasoning
Murong Yue et al. Large language model cas- cades with mixture of thought representations for cost-efficient reasoning. InICLR 2024 Work- shop on Reliable and Responsible Foundation Models, 2024
work page 2024
-
[21]
Guillem Ramírez, Alexandra Birch, and Ivan Titov. Optimising calls to large language models with uncertainty-based two-tier selection.arXiv preprint arXiv:2405.02134, 2024
-
[22]
Model router for mi- crosoft foundry concepts
Microsoft Corporation. Model router for mi- crosoft foundry concepts. Microsoft Learn Doc- umentation, 2025
work page 2025
-
[23]
Gpt-5 in azure ai foundry: Build & scale ai agents
88Hours. Gpt-5 in azure ai foundry: Build & scale ai agents. 2025. Reports up to 60% cost reduction via Model Router
work page 2025
-
[24]
Cascade- flow: Dynamic prompt routing tool.https: //github.com/lemony-ai/CascadeFlow, 2025
Lemony.ai (Uptime Industries Inc.). Cascade- flow: Dynamic prompt routing tool.https: //github.com/lemony-ai/CascadeFlow, 2025. Exclusive coverage and open source release. Reduces AI costs by up to 85% via cascad- ing pipeline with configurable quality metrics; supported models include OpenAI, Anthropic, Groq, vLLM, Ollama; adds only 2ms latency
work page 2025
-
[25]
Exclusive: Lemony says its dynamic prompt routing tool cuts ai costs by up to 85%
Paul Gillin. Exclusive: Lemony says its dynamic prompt routing tool cuts ai costs by up to 85%. SiliconANGLE, Nov 2025. Initial benchmarks: up to 85% of prompts can use smaller/domain- specific models
work page 2025
-
[26]
Terminus group partners with chinese academy of sciences to inaugurate chongqing edge com- puting laboratory.Global Times. Press release
-
[27]
Terminus Technology Group. Terminus aiot em- powers shanghai jiao tong university school of medicine with intelligent management.Termi- nus Group Official. Adopts an end-edge-cloud collaborative architecture
-
[28]
Edge computing promoting the development of large models
Terminus Technology Group. Edge computing promoting the development of large models. Ter- minus Group Official Interview, 2025. Edge rea- soning and cloud-edge collaboration for AIoT scenarios
work page 2025
-
[29]
N. Varshney and C. Baral. Model cascading: To- wards jointly improving efficiency and accuracy of nlp systems. InProceedings of the 2022 Con- ference on Empirical Methods in Natural Lan- guage Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, pages 11007–11021. Association for Computa- tional Linguistics, 2022
work page 2022
-
[30]
Pranjal Aggarwal et al. Automix: Automati- cally mixing language models.Advances in Neu- ral Information Processing Systems, 37:131000– 131034, 2024
work page 2024
-
[31]
H. Lee, H. Cheng, and M. Ostendorf. Orches- trallm: Efficient orchestration of language mod- els for dialogue state tracking. InProceedings of the 2024 Conference of the North Ameri- can Chapter of the Association for Computa- tional Linguistics: Human Language Technolo- gies (Volume 1: Long Papers), 2024
work page 2024
-
[32]
Surya Narayanan Hari and Matt Thomson. Tryage: Real-time, intelligent routing of user prompts to large language models.arXiv preprint arXiv:2308.11601, 2023
-
[33]
Large language model rout- ing with benchmark datasets.arXiv preprint arXiv:2309.15789, 2023
Tal Shnitzer et al. Large language model rout- ing with benchmark datasets.arXiv preprint arXiv:2309.15789, 2023
-
[34]
Jing Hao et al. Fullanno: A data engine for enhancing image comprehension of mllms.arXiv preprint arXiv:2409.13540, 2024
-
[35]
Fly-swat or cannon? cost-effective lan- guage model choice via meta-modeling
Marija Šakota, Maxime Peyrard, and Robert West. Fly-swat or cannon? cost-effective lan- guage model choice via meta-modeling. InPro- ceedings of the 17th ACM International Confer- ence on Web Search and Data Mining, 2024. 19
work page 2024
-
[36]
Yifan Yao, Jinhao Duan, Kaidi Xu, Yuanfang Cai, Zhibo Sun, and Yue Zhang. A survey on large language model (llm) security and pri- vacy: The good, the bad, and the ugly.High- Confidence Computing, 4(2):100211, 2024
work page 2024
-
[37]
Isabel O Gallegos, Ryan A Rossi, Joe Barrow, Md Mehrab Tanjim, Sungchul Kim, Franck Der- noncourt, Tong Yu, Ruiyi Zhang, and Nesreen K Ahmed. Bias and fairness in large language models: A survey.Computational Linguistics, 50(3):1097–1179, 2024
work page 2024
-
[38]
Badhan Chandra Das, M Hadi Amini, and Yanzhao Wu. Security and privacy challenges of large language models: A survey.ACM Com- puting Surveys, 57(6):1–39, 2025
work page 2025
-
[39]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qiang- long Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. A survey on hallucination in large lan- guage models: Principles, taxonomy, challenges, and open questions.ACM Transactions on In- formation Systems, 43(2):1–55, 2025
work page 2025
-
[40]
Hotflip: White-box adversarial ex- amples for text classification
Javid Ebrahimi, Anyi Rao, Daniel Lowd, and Dejing Dou. Hotflip: White-box adversarial ex- amples for text classification. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 31–36, 2018
work page 2018
-
[41]
Di Jin, Zhijing Jin, Joey Tianyi Zhou, and Peter Szolovits. Is bert really robust? a strong base- line for natural language attack on text classi- fication and entailment. InProceedings of the AAAI conference on artificial intelligence, vol- ume 34, pages 8018–8025, 2020
work page 2020
-
[42]
Bert-attack: Ad- versarial attack against bert using bert.arXiv preprint arXiv:2004.09984, 2020
Linyang Li, Ruotian Ma, Qipeng Guo, Xi- angyang Xue, and Xipeng Qiu. Bert-attack: Ad- versarial attack against bert using bert.arXiv preprint arXiv:2004.09984, 2020
-
[43]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou et al. Universal and transferable ad- versarial attacks on aligned language models. arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Tree of attacks: Jailbreak- ing black-box llms automatically
Anay Mehrotra et al. Tree of attacks: Jailbreak- ing black-box llms automatically. InAdvances in Neural Information Processing Systems, vol- ume 37, pages 61065–61105, 2024
work page 2024
-
[45]
Jailbreaking black box large language models in twenty queries
Patrick Chao et al. Jailbreaking black box large language models in twenty queries. In2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML). IEEE, 2025
work page 2025
-
[46]
Akshita Jha and Chandan K. Reddy. Codeat- tack: Code-based adversarial attacks for pre- trained programming language models. InPro- ceedings of the AAAI Conference on Artificial Intelligence, volume 37, 2023
work page 2023
-
[47]
FlipAttack: Jailbreak LLMs via Flipping
Yue Liu et al. Flipattack: Jailbreak llms via flipping.arXiv preprint arXiv:2410.02832, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Artprompt: Ascii art- based jailbreak attacks against aligned llms
Fengqing Jiang et al. Artprompt: Ascii art- based jailbreak attacks against aligned llms. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers), 2024
work page 2024
-
[49]
Xinyue Shen et al. "do anything now": Char- acterizing and evaluating in-the-wild jailbreak prompts on large language models. InProceed- ings of the 2024 ACM SIGSAC Conference on Computer and Communications Security, 2024
work page 2024
-
[50]
Haibo Jin et al. Guard: Role-playing to gener- ate natural-language jailbreakings to test guide- line adherence of large language models.arXiv preprint arXiv:2402.03299, 2024
-
[51]
Optimization-based prompt in- jection attack to llm-as-a-judge
Jiawen Shi et al. Optimization-based prompt in- jection attack to llm-as-a-judge. InProceedings of the 2024 ACM SIGSAC Conference on Com- puter and Communications Security, 2024
work page 2024
-
[52]
Certified robustness to adversarial word substitutions
Robin Jia, Aditi Raghunathan, Kerem Gök- sel, and Percy Liang. Certified robustness to adversarial word substitutions. InProceedings of the 2019 Conference on Empirical Meth- ods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 4129–4142, 2019. 20
work page 2019
-
[53]
SAFER: A structure-free approach for certified robustness to adversarial word substitutions
Mao Ye, Chengyue Gong, and Qiang Liu. SAFER: A structure-free approach for certified robustness to adversarial word substitutions. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 3465–3475, Online, July 2020. Association for Computational Linguistics
work page 2020
-
[54]
Achieving verified robustness to symbol substitutions via interval bound propa- gation
Po-Sen Huang, Robert Stanforth, Johannes Welbl, Chris Dyer, Dani Yogatama, Sven Gowal, Krishnamurthy Dvijotham, and Push- meet Kohli. Achieving verified robustness to symbol substitutions via interval bound propa- gation. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Pro- cessing and the 9th International Joint Confer- ence...
work page 2019
-
[55]
Certified adversarial robustness via randomized smoothing
Jeremy Cohen, Elan Rosenfeld, and Zico Kolter. Certified adversarial robustness via randomized smoothing. Ininternational conference on ma- chine learning, pages 1310–1320. PMLR, 2019
work page 2019
-
[56]
Denoised smooth- ing: A provable defense for pretrained classifiers
Hadi Salman, Mingjie Sun, Greg Yang, Ashish Kapoor, and J Zico Kolter. Denoised smooth- ing: A provable defense for pretrained classifiers. Advances in Neural Information Processing Sys- tems, 33:21945–21957, 2020
work page 2020
-
[57]
Zhen Zhang, Guanhua Zhang, Bairu Hou, Wenqi Fan, Qing Li, Sijia Liu, Yang Zhang, and Shiyu Chang. Certified robustness for large lan- guage models with self-denoising.arXiv preprint arXiv:2307.07171, 2023
-
[58]
Examining the ro- bustness of llm evaluation to the distributional assumptions of benchmarks
Charlotte Siska and et al. Examining the ro- bustness of llm evaluation to the distributional assumptions of benchmarks. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa- pers), 2024
work page 2024
-
[59]
Nikolaus H. R. Howe and et al. Exploring scaling trends in llm robustness. InICML 2024 Next Generation of AI Safety Workshop, 2024
work page 2024
-
[60]
Melissa Ailem and et al. Examining the ro- bustness of llm evaluation to the distributional assumptions of benchmarks.arXiv preprint arXiv:2404.16966, 2024
-
[61]
LLM-Safety Evaluations Lack Robustness
Tim Beyer and et al. Llm-safety evaluations lack robustness.arXiv preprint arXiv:2503.02574, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
Sarada Krithivasan, Sanchari Sen, and Anand Raghunathan. Sparsity turns adversarial: En- ergy and latency attacks on deep neural net- works.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 39(11):4129–4141, 2020
work page 2020
-
[63]
Sponge examples: Energy-latency attacks on neural networks
Ilia Shumailov, Yiren Zhao, Daniel Bates, Nico- las Papernot, Robert Mullins, and Ross Ander- son. Sponge examples: Energy-latency attacks on neural networks. InProceedings of the 6th IEEE European Symposium on Security and Pri- vacy, Vienna, Austria, 2021
work page 2021
-
[64]
Route to Rome Attack: Directing LLM Routers to Expensive Models via Adversarial Suffix Optimization
Haochun Tang et al. Route to rome attack: Directing llm routers to expensive models via adversarial suffix optimization.arXiv preprint arXiv:2604.15022, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[65]
Avital Shafran et al. Rerouting llm routers. arXiv preprint arXiv:2501.01818, 2025
-
[66]
Life-cycle routing vulnerabilities of LLM router.arXiv preprint arXiv:2503.08704, 2025
Qiqi Lin, Xiaoyang Ji, Shengfang Zhai, Qingni Shen, Zhi Zhang, Yuejian Fang, and Yansong Gao. Life-cycle routing vulnerabilities of LLM router.arXiv preprint arXiv:2503.08704, 2025
-
[67]
Who routes the router: Rethinking the evaluation of LLM routing systems
Jiayi Yuan, Yifan Lu, Rixin Liu, Yu-Neng Chuang, HongyiLiu, ShaochenZhong, YangSui, Guanchu Wang, Jiarong Xing, and Xia Hu. Who routes the router: Rethinking the evaluation of LLM routing systems. InNeurIPS 2025 Work- shop on Evaluating the Evolving LLM Lifecy- cle: Benchmarks, Emergent Abilities, and Scal- ing, 2025
work page 2025
-
[68]
Promptrobust: Towards evaluating the robust- ness of large language models on adversarial 21 prompts
Kaijie Zhu, Jindong Wang, Jiaheng Zhou, Zichen Wang, Hao Chen, Yidong Wang, Linyi Yang, Wei Ye, Yue Zhang, Neil Gong, et al. Promptrobust: Towards evaluating the robust- ness of large language models on adversarial 21 prompts. InProceedings of the 1st ACM work- shop on large AI systems and models with pri- vacy and safety analysis, pages 57–68, 2023
work page 2023
-
[69]
Pappas, Florian Tramèr, Hamed Hassani, and Eric Wong
Patrick Chao, Edoardo Debenedetti, Alexan- der Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J. Pappas, Florian Tramèr, Hamed Hassani, and Eric Wong. Jailbreak- bench: An open robustness benchmark for jail- breaking large language models. InNeurIPS Datasets and Benchmarks Track, 2024
work page 2024
-
[70]
Impact of news on the commodity market: Dataset and re- sults
Ankur Sinha and Tanmay Khandait. Impact of news on the commodity market: Dataset and re- sults. InFuture of Information and Communica- tion Conference, pages 589–601. Springer, 2021
work page 2021
-
[71]
Lucia Zheng, Neel Guha, Brandon R Ander- son, Peter Henderson, and Daniel E Ho. When does pretraining help? assessing self-supervised learning for law and the casehold dataset of 53,000+ legal holdings. InProceedings of the eighteenth international conference on artificial intelligence and law, pages 159–168, 2021
work page 2021
-
[72]
Xiang Zhang, Junbo Zhao, and Yann LeCun. Character-level convolutional networks for text classification.Advances in neural information processing systems, 28, 2015
work page 2015
-
[73]
Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christo- pher Potts. Learning word vectors for senti- ment analysis. InProceedings of the 49th An- nual Meeting of the Association for Computa- tional Linguistics: Human Language Technolo- gies, pages 142–150, Portland, Oregon, USA, June 2011. Association for Computational Lin- guistics
work page 2011
-
[74]
Semantic parsing on Freebase from question-answer pairs
Jonathan Berant, Andrew Chou, Roy Frostig, and Percy Liang. Semantic parsing on Freebase from question-answer pairs. InProceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 1533–1544, Seattle, Washington, USA, October 2013. Asso- ciation for Computational Linguistics
work page 2013
-
[75]
Know what you don’t know: Unanswerable questions for squad
Pranav Rajpurkar, Robin Jia, and Percy Liang. Know what you don’t know: Unanswerable questions for squad. In Iryna Gurevych and Yusuke Miyao, editors,Proceedings of the 56th Annual Meeting of the Association for Compu- tational Linguistics (Volume 2: Short Papers), pages 784–789, Melbourne, Australia, July 2018. Association for Computational Linguistics
work page 2018
-
[76]
Squad: 100,000+ questions for machine comprehension of text
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. Squad: 100,000+ questions for machine comprehension of text. In Jian Su, Kevin Duh, and Xavier Carreras, editors,Proceedings of the 2016 Conference on Empirical Methods in Natural Language Process- ing, pages 2383–2392, Austin, Texas, Novem- ber 2016. Association for Computational Lin- guistics
work page 2016
-
[77]
Commongen: A con- strained text generation challenge for genera- tive commonsense reasoning
Bill Yuchen Lin, Wangchunshu Zhou, Ming Shen, Pei Zhou, Chandra Bhagavatula, Yejin Choi, and Xiang Ren. Commongen: A con- strained text generation challenge for genera- tive commonsense reasoning. InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 1823–1840, Online, Novem- ber 2020. Association for Computational Lin- guistics
work page 2020
-
[78]
Marek Kadlčík, Michal Štefánik, Ondřej Sotolář, and Vlastimil Martinek. Calc-x and calcform- ers: Empowering arithmetical chain-of-thought through interaction with symbolic systems. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: Main Track, Singapore, Singapore, December 2023. Association for Computational Linguistics
work page 2023
-
[79]
Wildteaming at scale: From in-the-wild jailbreaks to (adversari- ally) safer language models, 2024
Liwei Jiang, Kavel Rao, Seungju Han, Allyson Ettinger, Faeze Brahman, Sachin Kumar, Niloo- far Mireshghallah, Ximing Lu, Maarten Sap, Yejin Choi, and Nouha Dziri. Wildteaming at scale: From in-the-wild jailbreaks to (adversari- ally) safer language models, 2024
work page 2024
-
[80]
Random smooth-based certified defense against text adversarial attack
Zeliang Zhang and et al. Random smooth-based certified defense against text adversarial attack. 22 Findings of the Association for Computational Linguistics: EACL 2024, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.