TRACE: Trajectory Correction from Cross-layer Evidence for Hallucination Reduction
Pith reviewed 2026-05-20 10:24 UTC · model grok-4.3
The pith
A single training-free algorithm corrects hallucinations in language models by deriving fixes from cross-layer trajectories in one forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TRACE corrects hallucinations at inference time by deriving both the corrective layer and the appropriate correction operator from each input's cross-layer candidate trajectory inside the LLM's own forward pass, selecting among scalar reversal, earlier-state recovery, and candidate-space correction using only model-internal evidence.
What carries the argument
The cross-layer candidate trajectory observed during a single forward pass, from which the method selects the corrective operator.
If this is right
- TRACE improves factuality scores in every tested combination of model and benchmark.
- It achieves average gains of over 12 points on MC1 and 8 on MC2-style metrics.
- The method requires no per-model calibration or additional data.
- Improvements occur without any regressions in performance.
- Maximum observed gains reach up to 47 points on MC1.
Where Pith is reading between the lines
- Internal model computations may hold enough self-diagnostic signals to fix many factual errors without outside help.
- This approach could inspire similar trajectory-based corrections for other model behaviors like reasoning consistency.
- Future work might test if the same principle applies to multimodal models or different generation tasks.
Load-bearing premise
The cross-layer candidate trajectory from a single forward pass always supplies sufficient internal evidence to choose the correct correction operator for any input.
What would settle it
A test case where applying the TRACE-selected correction decreases factuality compared to the uncorrected output, or where the trajectory provides ambiguous evidence leading to incorrect operator choice.
Figures







read the original abstract
Hallucination correction is not a one-direction problem. We show that intermediate layers are neither uniformly more truthful than final layers nor uniformly less trustworthy. Yet hallucination reduction is usually instantiated through one fixed intervention form: contrast one layer against another, steer along a truthfulness direction, or defer to external evidence. This framing is structurally incomplete. Cross-layer factual evidence does not evolve uniformly: in some failures truthful support is present internally and later suppressed, whereas in others candidate competition remains genuinely multi-directional across depth, so no single signed scalar family is generally sufficient. We introduce Trajectory Correction from Cross-layer Evidence for Hallucination Reduction (TRACE), a deterministic, training-free algorithm which corrects hallucinations at inference time by deriving both the corrective layer and the appropriate correction operator from each input's cross-layer candidate trajectory inside the LLM's own forward pass. Under one frozen hyperparameter setting, TRACE selects among scalar reversal, earlier-state recovery, and candidate-space correction using only model-internal evidence. Evaluated as a single universal algorithm across 15 models, 8 model families, and 3 factuality benchmarks, TRACE improves every evaluation cell, yielding mean gains of +12.26 MC1 points and +8.65 MC2-style points with no regressions, with gains reaching +47.20 MC1 and +43.38 MC2-style points. The method uses no labels, retrieval, pretraining, finetuning, or per-model calibration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TRACE, a deterministic, training-free inference-time algorithm for hallucination reduction in LLMs. It argues that cross-layer factual evidence is non-uniform and proposes to derive both the corrective layer and the appropriate operator (scalar reversal, earlier-state recovery, or candidate-space correction) directly from each input's cross-layer candidate trajectory observed in a single forward pass. The selection uses only model-internal evidence under one frozen hyperparameter. The method is evaluated as a universal algorithm across 15 models from 8 families on 3 factuality benchmarks, claiming consistent gains in every cell (mean +12.26 MC1 and +8.65 MC2-style points, no regressions, with peaks of +47.20 MC1 and +43.38 MC2-style points) without labels, retrieval, or per-model tuning.
Significance. If the central claim is supported—that cross-layer trajectory statistics alone suffice for correct, input-only operator selection without benchmark feedback or post-hoc choices—TRACE would offer a notable contribution to training-free hallucination mitigation. The reported universality across model families and the absence of regressions would strengthen its practical value, particularly if the internal decision criteria are fully specified and reproducible.
major comments (2)
- [§3] §3 (Method): The paper states that operator selection relies on 'model-internal evidence' from the cross-layer candidate trajectory under one frozen hyperparameter, yet does not provide explicit, reproducible decision rules (e.g., a threshold on layer-wise KL divergence, sign of probability delta, or multi-modal competition metric) that map trajectory statistics to one of the three operators for arbitrary inputs. Without such criteria formalized as equations or pseudocode, it is impossible to verify that the selection is deterministic and independent of the evaluation benchmarks.
- [§4.2] §4.2 and Table 2: The claim of 'no regressions' and universal gains across all 15 models and 3 benchmarks is load-bearing for the universality argument, but the reported results lack per-cell standard deviations, confidence intervals, or statistical tests. This makes it difficult to assess whether the mean gains of +12.26 MC1 points reflect robust improvements or could be sensitive to post-hoc dataset or model choices.
minor comments (2)
- [§2] §2 (Related Work): The discussion of prior contrastive or steering methods could more explicitly contrast TRACE's operator selection with fixed-direction approaches to clarify the claimed structural incompleteness.
- Notation: The terms 'MC1' and 'MC2-style points' are used without a brief definition or reference to the exact benchmark scoring in the main text; a short footnote or parenthetical would improve clarity for readers unfamiliar with the specific factuality metrics.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and have revised the manuscript to improve reproducibility and statistical presentation where appropriate.
read point-by-point responses
-
Referee: [§3] §3 (Method): The paper states that operator selection relies on 'model-internal evidence' from the cross-layer candidate trajectory under one frozen hyperparameter, yet does not provide explicit, reproducible decision rules (e.g., a threshold on layer-wise KL divergence, sign of probability delta, or multi-modal competition metric) that map trajectory statistics to one of the three operators for arbitrary inputs. Without such criteria formalized as equations or pseudocode, it is impossible to verify that the selection is deterministic and independent of the evaluation benchmarks.
Authors: We agree that explicit formalization strengthens verifiability. The original §3 describes operator selection via trajectory analysis for patterns of truthful suppression versus persistent competition, using a single frozen hyperparameter. In the revised manuscript we have added §3.3 containing the precise decision rules as equations and pseudocode: operator choice is determined by comparing layer-wise probability deltas and a competition metric (maximum KL divergence across candidate pairs) against fixed thresholds. This mapping is fully deterministic, benchmark-independent, and uses only internal forward-pass statistics. revision: yes
-
Referee: [§4.2] §4.2 and Table 2: The claim of 'no regressions' and universal gains across all 15 models and 3 benchmarks is load-bearing for the universality argument, but the reported results lack per-cell standard deviations, confidence intervals, or statistical tests. This makes it difficult to assess whether the mean gains of +12.26 MC1 points reflect robust improvements or could be sensitive to post-hoc dataset or model choices.
Authors: We acknowledge that additional statistical detail would aid assessment of robustness. TRACE is deterministic with zero per-input variance, so classical standard deviations per cell are not applicable. In the revision we have updated §4.2 and Table 2 to explicitly list the per-cell gains (confirming no regressions across all 45 cells) and added bootstrap confidence intervals on the aggregate means in a new supplementary section. These show the reported improvements remain stable under resampling and are not driven by particular dataset or model subsets. revision: partial
Circularity Check
TRACE derivation uses model-internal trajectory with one frozen hyperparameter; no reduction to fitted benchmark values or self-citation chains
full rationale
The paper presents TRACE as selecting among correction operators from cross-layer candidate trajectories observed in a single forward pass, using only model-internal evidence under one frozen hyperparameter. No equations, decision rules, or load-bearing steps are shown to reduce the operator choice or final output to a quantity defined from the same evaluation data or prior self-citations. The central claim remains independent of the reported benchmark gains, consistent with self-contained inference-time correction against external factuality benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- single frozen hyperparameter
axioms (1)
- domain assumption Intermediate layers are neither uniformly more truthful than final layers nor uniformly less trustworthy.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
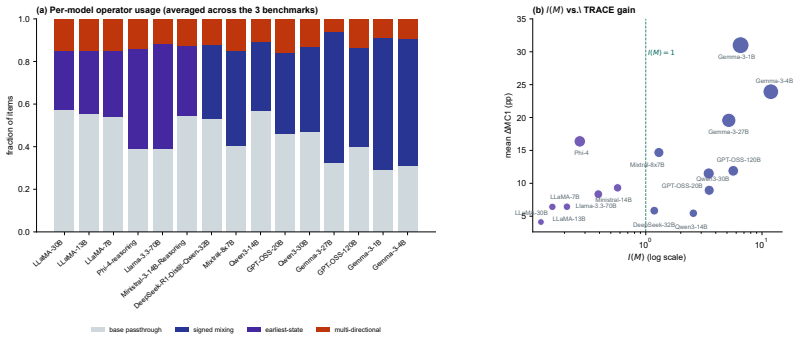
deff(x) = (tr C(x))^2 / tr(C(x)^2) ... partitions items into scalar and candidate-space regimes (Theorem 2.1)
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
I(M) = ϕN ϕO / (ϕK ϕV) ... dispatches between signed mixing and earliest-state fallback
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J. Hewett, Mojan Javaheripi, Piero Kauffmann, et al. Phi-4 technical report.arXiv preprint arXiv:2412.08905, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Phi-4-reasoning Technical Report
Marah Abdin, Sahaj Agarwal, Ahmed Awadallah, Harkirat Behl, Sébastien Bubeck, Lingjiao Cai, Qin Cai, Suriya Gunasekar, Dan Iter, Yin Tat Lee, et al. Phi-4-reasoning technical report. arXiv preprint arXiv:2504.21318, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
The internal state of an LLM knows when it’s lying
Amos Azaria and Tom Mitchell. The internal state of an LLM knows when it’s lying. InFind- ings of the Association for Computational Linguistics: EMNLP 2023, pages 11817–11832,
work page 2023
-
[4]
doi: 10.18653/v1/2023.findings-emnlp.802
-
[5]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer normalization.arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[6]
Farima Fatahi Bayat, Xin Liu, H. V . Jagadish, and Lu Wang. Enhanced language model truthfulness with learnable intervention and uncertainty expression. InFindings of the Association for Computational Linguistics: ACL 2024, pages 12387–12405, 2024. doi: 10.18653/v1/2024.findings-acl.737
-
[7]
Eliciting latent predictions from transformers with the tuned lens
Nora Belrose, Zach Furman, Logan Smith, Danny Halawi, Igor Ostrovsky, Lev McKinney, Stella Biderman, and Jacob Steinhardt. Eliciting latent predictions from transformers with the tuned lens. InNeurIPS, 2023
work page 2023
-
[8]
Discovering latent knowledge in language models without supervision
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. Discovering latent knowledge in language models without supervision. InICLR, 2023
work page 2023
-
[9]
INSIDE: LLMs’ internal states retain the power of hallucination detection
Chao Chen, Kai Liu, Ze Chen, Yi Gu, Yue Wu, Mingyuan Tao, Zhihang Fu, and Jieping Ye. INSIDE: LLMs’ internal states retain the power of hallucination detection. InICLR, 2024
work page 2024
-
[10]
DoLa: Decoding by contrasting layers improves factuality in large language models
Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James Glass, and Pengcheng He. DoLa: Decoding by contrasting layers improves factuality in large language models. InICLR, 2024
work page 2024
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. LLM.int8(): 8-bit ma- trix multiplication for transformers at scale. InAdvances in Neural Information Processing Systems, 2022. arXiv:2208.07339
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
A frame- work for few-shot language model evaluation, 2023
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. A frame- wo...
work page 2023
-
[17]
Gemma Team. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Yunzhen He, Yusuke Takase, Yoichi Ishibashi, and Hidetoshi Shimodaira. DeLTa: A de- coding strategy based on logit trajectory prediction improves factuality and reasoning ability. InProceedings of the 2nd Workshop on Uncertainty-Aware NLP (UncertaiNLP 2025), pages 309–319, 2025. doi: 10.18653/v1/2025.uncertainlp-main.26
-
[20]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qiang- long Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems, 2024
work page 2024
-
[21]
LLM internal states reveal hallucination risk faced with a query
Zekai Ji, Vivek Madan, Hassan Sajjad, and Preslav Nakov. LLM internal states reveal hallucination risk faced with a query. InProceedings of the Seventh BlackboxNLP Work- shop on Analyzing and Interpreting Neural Networks for NLP, pages 56–74, 2024. doi: 10.18653/v1/2024.blackboxnlp-1.6
-
[22]
Survey of hallucination in natural language generation
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Yejin Bang, Delong Chen, Wenliang Dai, et al. Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12), 2023
work page 2023
-
[23]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7B.arXiv preprint arXiv:23...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
On large language models’ hallucination with regard to known facts
Xin Jiang, Yurun Xue, Danrui Yang, Yuwei Yang, Lixu Wang, Yutao Zheng, Yikang Liu, Hao Pan, Hong Shen, et al. On large language models’ hallucination with regard to known facts. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1074–1093, 2024. doi: 10.18...
-
[26]
SH2: Self-highlighted hesitation helps you decode more truthfully
Jushi Kai, Tianhang Zhang, Hai Hu, and Zhouhan Lin. SH2: Self-highlighted hesitation helps you decode more truthfully. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 4514–4530, 2024. doi: 10.18653/v1/2024.findings-emnlp.260
-
[27]
Retrieval-augmented generation for knowledge-intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandras Piktus, Fabio Petroni, Vladimir Karpukhin, Na- man Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. In NeurIPS, 2020
work page 2020
-
[28]
HaluEval: A Large-Scale Hallucination Evaluation Benchmark for Large Language Models
Junyi Li, Xiaoxue Cheng, Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. HaluEval: A large-scale hallucination evaluation benchmark for large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6449–6464, 2023. doi: 10.18653/v1/2023.emnlp-main.397
-
[29]
Inference- time intervention: Eliciting truthful answers from a language model
Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Inference- time intervention: Eliciting truthful answers from a language model. InNeurIPS, 2023
work page 2023
-
[30]
TruthfulQA: Measuring how models mimic human falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. TruthfulQA: Measuring how models mimic human falsehoods. InACL, 2022
work page 2022
-
[31]
Alexander H. Liu et al. Ministral 3.arXiv preprint arXiv:2601.08584, 2026. 11
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
LLMs know more than they show: On the intrinsic representation of LLM hallucinations
Hadas Orgad, Michael Toker, Zorik Gekhman, Roi Reichart, Idan Szpektor, Hadas Kotek, and Yonatan Belinkov. LLMs know more than they show: On the intrinsic representation of LLM hallucinations. InICLR, 2025
work page 2025
-
[34]
Pytorch: An imperative style, high- performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high- perf...
-
[35]
Qwen Team. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Steering Llama 2 via Contrastive Activation Addition , url =
Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Turner. Steering Llama 2 via contrastive activation addition. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, pages 15504–15522, 2024. doi: 10.18653/v1/2024.acl-long.828
-
[37]
The effective rank: A measure of effective dimensionality
Olivier Roy and Martin Vetterli. The effective rank: A measure of effective dimensionality. In 15th European Signal Processing Conference (EUSIPCO), pages 606–610, 2007
work page 2007
-
[38]
Weiyuan Su, Xingbo Wang, Hongzhi Yin, Ming Tang, Weiming Qi, and Suhang Wang. Unsu- pervised real-time hallucination detection based on the internal states of large language models. InFindings of the Association for Computational Linguistics: ACL 2024, pages 14427–14440,
work page 2024
-
[39]
doi: 10.18653/v1/2024.findings-acl.854
-
[40]
Philippe Tillet, H. T. Kung, and David Cox. Triton: An intermediate language and compiler for tiled neural network computations. InProceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages (MAPL), pages 10–19, 2019. doi: 10.1145/3315508.3329973
-
[41]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. LLaMA: Open and efficient founda- tion language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Tianlong Wang, Xianfeng Jiao, Yinghao Zhu, Zhongzhi Chen, Yifan He, Xu Chu, Junyi Gao, Yasha Wang, and Liantao Ma. Adaptive activation steering: A tuning-free LLM truthfulness improvement method for diverse hallucinations categories.Proceedings of The Web Confer- ence (WWW), 2025. arXiv:2406.00034
-
[43]
Knowledge-Centric Hallucination Detection
Yuxia Wang, Minghan Wang, Muhammad Arslan Manzoor, Fei Liu, et al. Factuality of large language models: A survey. InProceedings of the 2024 Conference on Empirical Meth- ods in Natural Language Processing, pages 19516–19544, 2024. doi: 10.18653/v1/2024. emnlp-main.1088
-
[44]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. Transformers: State- of-the-ar...
-
[45]
Improve decoding factuality by token-wise cross layer entropy of large language models
Jialiang Wu, Yi Shen, Sijia Liu, Yi Tang, Sen Song, Xiaoyi Wang, and Longjun Cai. Improve decoding factuality by token-wise cross layer entropy of large language models. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 3912–3921, 2025. doi: 10.18653/v1/2025.findings-naacl.217. 12
-
[46]
In: Zong, C., Xia, F., Li, W., Navigli, R
Hanning Yu, Zheng Zhao, Yiqi Wang, Yubo Zhuang, and Jun Zhao. Mechanistic understanding and mitigation of language model non-factual hallucinations. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 7945–7964, 2024. doi: 10.18653/v1/ 2024.findings-emnlp.466
-
[47]
Root Mean Square Layer Normalization
Biao Zhang and Rico Sennrich. Root mean square layer normalization. InAdvances in Neural Information Processing Systems, 2019. arXiv:1910.07467
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[48]
Active layer-contrastive decoding reduces hallucination in large language model generation
Hongxiang Zhang, Hao Chen, Muhao Chen, and Tianyi Zhang. Active layer-contrastive decoding reduces hallucination in large language model generation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025. doi: 10.18653/v1/2025.emnlp-main.150
-
[49]
SLED: Self logits evolution decoding for improving factuality in large language models
Jianyi Zhang, Da-Cheng Juan, Cyrus Rashtchian, Chun-Sung Ferng, Heinrich Jiang, and Yiran Chen. SLED: Self logits evolution decoding for improving factuality in large language models. InNeurIPS, 2024
work page 2024
-
[50]
Yutong Zhu, Yang Wang, Tianji Li, Cheng Qian, Wenxiao Wang, Zhiheng He, Yuntao Liu, et al. PoLLMgraph: Unraveling hallucinations in large language models via state transition dynamics.arXiv preprint arXiv:2404.04722, 2024
-
[51]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, et al. Representation engineering: A top-down approach to AI transparency.arXiv preprint arXiv:2310.01405, 2023. 13 A Full Proofs and Scope of the Structural Results This appendix records the full linear-algebra facts behind Proposition 2.1 and Theorem 2.1, together ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
and multi-directional items (deff >1), then part (i) shows that scalar mixtures suffice in the first regime, while part (ii) constructs a multi-directional case that escapes the scalar family entirely. No correction rule restricted to scalar mixtures of(b(x),t(x))can therefore be universal on such a domain; a second operator class that acts directly in ca...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.