InstructAV2AV: Instruction-Guided Audio-Video Joint Editing
Pith reviewed 2026-05-20 11:30 UTC · model grok-4.3
The pith
InstructAV2AV is the first end-to-end framework that jointly edits audio and video from text instructions while preserving source content.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
InstructAV2AV is the first end-to-end framework for instruction-guided audio-video joint editing. It rests on a new large-scale dataset InsAVE-80K created via scalable synthesis, then adapts an audio-video generation backbone through input concatenation with noisy latents, source-instruction gated attention for balanced following and preservation, and two-stage training to leverage pre-trained priors.
What carries the argument
Source-instruction gated attention that modulates the model's focus between the instruction and the source audio-video content to improve following while reducing unwanted changes.
If this is right
- Joint audio-video editing becomes feasible in one pass without separate pipelines for sound and visuals.
- Pre-trained audio-video generators can be repurposed for editing tasks with modest additional training.
- Controllable multimedia creation expands to cases where audio must change consistently with visual edits.
Where Pith is reading between the lines
- The gated attention design could generalize to other conditional generation tasks that need to balance new instructions against source fidelity.
- Scaling the synthetic data pipeline further might reduce the need for real paired editing data in future multimodal models.
- Real-time or interactive versions of the approach would require testing latency under the current two-stage training setup.
Load-bearing premise
The synthetic source-to-target pairs created by the data pipeline are sufficiently close to real editing scenarios to let the model learn effective instruction following and content preservation.
What would settle it
Human evaluation or objective scores on a held-out set of real user-recorded videos with natural language instructions, checking whether audio remains synchronized and source identity is retained after editing.
Figures






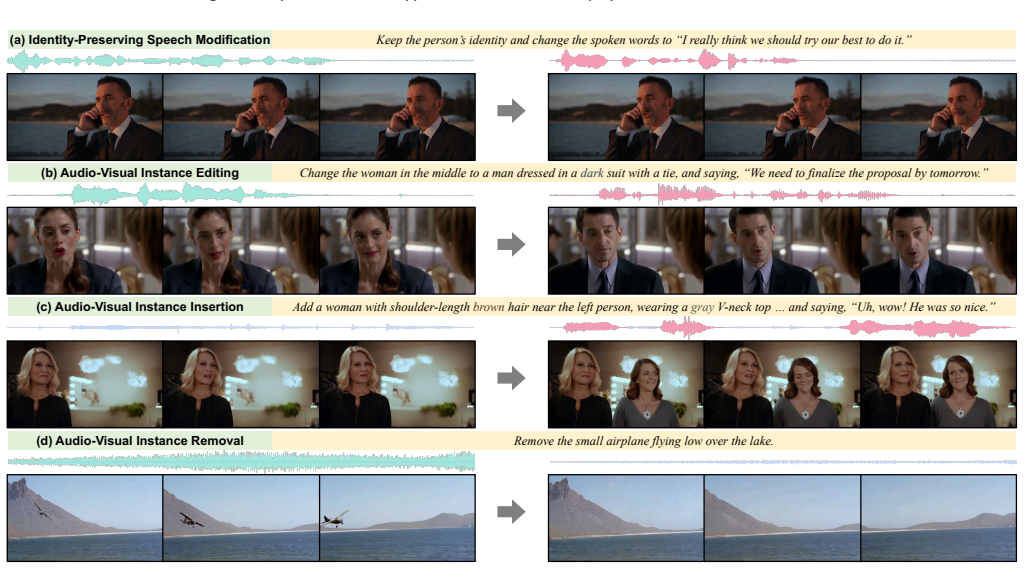

read the original abstract
Recent diffusion-based methods have achieved impressive progress in video content manipulation. However, they typically ignore the accompanying audio, leaving the audio disjointed from the edited results. In this paper, we propose InstructAV2AV, the first end-to-end framework for instruction-guided audio-video joint editing. We first develop a scalable data synthesis pipeline and construct InsAVE-80K, the first large-scale audio-video editing dataset with high-quality source-to-target pairs. With this data foundation, we adapt an audio-video generation backbone to leverage its robust priors. We concatenate the audio-video input with noisy latent codes to anchor the source context, propose the source-instruction gated attention to improve instruction following and content preservation, and introduce a two-stage training strategy to effectively transfer these pre-trained priors. Extensive experiments demonstrate that InstructAV2AV outperforms state-of-the-art methods across 11 metrics spanning three aspects on two evaluation sets, highlighting its potential for controllable content creation. Project page: https://hjzheng.net/projects/InstructAV2AV/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces InstructAV2AV as the first end-to-end framework for instruction-guided audio-video joint editing. It develops a scalable data synthesis pipeline to construct the InsAVE-80K dataset of high-quality source-to-target audio-video pairs, adapts a pre-trained audio-video generation backbone by concatenating inputs with noisy latent codes, proposes source-instruction gated attention for better instruction following and content preservation, and employs a two-stage training strategy to transfer priors. Extensive experiments claim outperformance over state-of-the-art methods across 11 metrics spanning three aspects on two evaluation sets.
Significance. If the central claims hold, this work would be significant for advancing controllable multimedia editing by jointly handling audio and video under natural language instructions, addressing a clear gap left by prior diffusion-based video methods that ignore audio. The construction of a large-scale paired dataset and the architectural adaptations (gated attention and two-stage training) represent concrete contributions that could enable more realistic content creation pipelines, provided the synthetic data foundation is robust.
major comments (2)
- [Methods (Data Synthesis Pipeline)] Data Synthesis Pipeline (Methods section): The description of the scalable synthesis pipeline for InsAVE-80K provides no quantitative validation—such as human ratings on instruction adherence, artifact detection rates, or statistical comparisons of source-target distributions—for the quality of the generated pairs. This is load-bearing for the central claim, as the reported gains on the 11 metrics and the effectiveness of the two-stage training and gated attention depend on the assumption that these pairs enable clean transfer of pre-trained priors without systematic mismatches (e.g., desync or content leakage) that could cause overfitting to dataset artifacts.
- [Experiments] Experiments section: The abstract and results claim outperformance across 11 metrics on two evaluation sets, but the provided text does not include the actual quantitative tables, baseline details, error bars, or ablation studies isolating the contribution of the gated attention and two-stage training. Without these, it is not possible to assess whether the gains are attributable to the proposed components or to unverified properties of the synthetic data.
minor comments (2)
- [Abstract] The abstract states 'outperforms state-of-the-art methods across 11 metrics' without referencing specific tables or figures; adding a forward reference to the results tables would improve clarity.
- [Methods] Notation for the source-instruction gated attention mechanism could be clarified with an explicit equation or diagram reference in the Methods section to distinguish it from standard cross-attention.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment point by point below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Methods (Data Synthesis Pipeline)] Data Synthesis Pipeline (Methods section): The description of the scalable synthesis pipeline for InsAVE-80K provides no quantitative validation—such as human ratings on instruction adherence, artifact detection rates, or statistical comparisons of source-target distributions—for the quality of the generated pairs. This is load-bearing for the central claim, as the reported gains on the 11 metrics and the effectiveness of the two-stage training and gated attention depend on the assumption that these pairs enable clean transfer of pre-trained priors without systematic mismatches (e.g., desync or content leakage) that could cause overfitting to dataset artifacts.
Authors: We acknowledge that the current manuscript does not include explicit quantitative validation (such as human ratings or statistical distribution comparisons) for the InsAVE-80K pairs in the main text. While the pipeline leverages established models for pair generation, we agree this validation is important to support the data quality assumption. In the revised version, we will add a dedicated subsection with human evaluation results on instruction adherence and artifact rates, plus statistical comparisons between source and target distributions to rule out systematic issues like desync or leakage. revision: yes
-
Referee: [Experiments] Experiments section: The abstract and results claim outperformance across 11 metrics on two evaluation sets, but the provided text does not include the actual quantitative tables, baseline details, error bars, or ablation studies isolating the contribution of the gated attention and two-stage training. Without these, it is not possible to assess whether the gains are attributable to the proposed components or to unverified properties of the synthetic data.
Authors: We apologize if the placement of results was unclear in the submitted version. The manuscript includes tables reporting the 11 metrics on both evaluation sets with baseline comparisons, and Section 4.3 contains ablations for gated attention and two-stage training. To address the concern, we will revise the Experiments section to explicitly reference and describe these tables in the main text, add error bars to the metrics, and expand the ablation discussion to better isolate component contributions versus data properties. revision: yes
Circularity Check
No significant circularity; contributions rest on novel dataset synthesis and empirical adaptations
full rationale
The paper introduces a scalable data synthesis pipeline to build InsAVE-80K, adapts an audio-video generation backbone, concatenates inputs with noisy latents, proposes source-instruction gated attention, and uses two-stage training to transfer priors. These steps are presented as engineering choices enabling instruction-guided joint editing, with outperformance demonstrated via experiments on separate evaluation sets across 11 metrics. No load-bearing claim reduces by construction to fitted parameters, self-definitions, or unverified self-citations; the derivation chain remains self-contained against external benchmarks and does not equate predictions to inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- two-stage training hyperparameters
axioms (1)
- domain assumption Pre-trained audio-video generation models contain robust priors that transfer effectively to editing tasks when conditioned on source input and instructions.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose the Source-Instruction Gated Attention (SIGA) module ... two-stage training strategy ... flow matching formulation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Scaling instruction-based video editing with a high-quality synthetic dataset
Scaling instruction-based video editing with a high-quality synthetic dataset.arXiv preprint arXiv:2510.15742 (2025). Max Bain, Arsha Nagrani, Andrew Brown, and Andrew Zisserman
-
[2]
AVControl: Efficient Framework for Training Audio-Visual Controls.arXiv preprint arXiv:2603.24793 (2026). Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, et al
-
[3]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets. arXiv preprint arXiv:2311.15127(2023). Tim Brooks, Aleksander Holynski, and Alexei A. Efros
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
arXiv preprint arXiv:2508.19320(2025)
MIDAS: Multimodal Interactive Digital-humAn Synthesis via Real-time Autoregressive Video Generation. arXiv preprint arXiv:2508.19320(2025). Ho Kei Cheng, Masato Ishii, Akio Hayakawa, Takashi Shibuya, Alexander Schwing, and Yuki Mitsufuji
-
[5]
Clap learning audio concepts from natural language supervision. InICASSP 2023- 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5. Youquan Fu, Ruiyang Si, Hongfa Wang, Dongzhan Zhou, Jiacheng Sun, Ping Luo, Di Hu, Hongyuan Zhang, and Xuelong Li
work page 2023
-
[6]
Ridouane Ghermi, Xi Wang, Vicky Kalogeiton, and Ivan Laptev
Object-AVEdit: An Object-level Audio-Visual Editing Model.arXiv preprint arXiv:2510.00050(2025). Ridouane Ghermi, Xi Wang, Vicky Kalogeiton, and Ivan Laptev
-
[7]
Long Story Short: Story-level Video Understanding from 20K Short Films.arXiv preprint arXiv:2406.10221(2024). Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra
-
[8]
Peavs: Perceptual evaluation of audio-visual synchrony grounded in viewers’ opinion scores,
PEAVS: Perceptual Evaluation of Audio-Visual Synchrony Grounded in Viewers’ Opinion Scores. arXiv:2404.07336 [cs.CV] Google DeepMind
-
[9]
LTX-2: Efficient Joint Audio-Visual Foundation Model
LTX-2: Efficient Joint Audio-Visual Foundation Model.arXiv preprint arXiv:2601.03233(2026). Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Prompt-to-Prompt Image Editing with Cross Attention Control
Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626(2022). Vladimir Iashin and Esa Rahtu
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Taming visually guided sound generation.arXiv preprint arXiv:2110.08791(2021). InstructAV2AV: Instruction-Guided Audio-Video Joint Editing•13 Masato Ishii, Akio Hayakawa, Takashi Shibuya, and Yuki Mitsufuji
-
[12]
Coherent Audio-Visual Editing via Conditional Audio Generation Following Video Edits.arXiv preprint arXiv:2512.07209(2025). Nikita Karaev, Iurii Makarov, Jianyuan Wang, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht
-
[13]
Fr\'echet Audio Distance: A Metric for Evaluating Music Enhancement Algorithms
Fr\’echet audio distance: A metric for evaluating music enhancement algorithms.arXiv preprint arXiv:1812.08466(2018). Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
HunyuanVideo: A Systematic Framework For Large Video Generative Models.arXiv preprint arXiv:2412.03603(2024). Susan Liang, Chao Huang, Yapeng Tian, Anurag Kumar, and Chenliang Xu
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Sounding video generator: A unified framework for text-guided sounding video generation.IEEE Transactions on Multimedia26 (2023), 141–153. Kai Liu, Wei Li, Lai Chen, Shengqiong Wu, Yanhao Zheng, Jiayi Ji, Fan Zhou, Jiebo Luo, Ziwei Liu, Hao Fei, et al
work page 2023
-
[16]
Javisdit: Joint audio-video diffusion transformer with hierarchical spatio-temporal prior synchronization.arXiv preprint arXiv:2503.23377 (2025). Kai Liu, Yanhao Zheng, Kai Wang, Shengqiong Wu, Rongjunchen Zhang, Jiebo Luo, Dimitrios Hatzinakos, Ziwei Liu, Hao Fei, and Tat-Seng Chua
-
[17]
Ilya Loshchilov and Frank Hutter
Javisdit++: Unified modeling and optimization for joint audio-video generation.arXiv preprint arXiv:2602.19163(2026). Ilya Loshchilov and Frank Hutter
-
[18]
Decoupled Weight Decay Regularization
Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101(2017). Chetwin Low, Weimin Wang, and Calder Katyal
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
Ovi: Twin Backbone Cross-Modal Fusion for Audio-Video Generation
Ovi: Twin backbone cross-modal fusion for audio-video generation.arXiv preprint arXiv:2510.01284(2025). Eyal Molad, Eliahu Horwitz, Dani Valevski, Alex Rav Acha, Yossi Matias, Yael Pritch, Yaniv Leviathan, and Yedid Hoshen
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [20]
-
[21]
Bosheng Qin, Juncheng Li, Siliang Tang, Tat-Seng Chua, and Yueting Zhuang
CoDeF: Content Deformation Fields for Temporally Consistent Video Processing.arXiv preprint arXiv:2308.07926 (2023). Bosheng Qin, Juncheng Li, Siliang Tang, Tat-Seng Chua, and Yueting Zhuang
-
[22]
Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research 21, 140 (2020), 1–67. Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al
work page 2020
-
[23]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks.arXiv preprint arXiv:2401.14159(2024). James Robert, Marc Webbie, et al
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Ruijie Tao, Zexu Pan, Rohan Kumar Das, Xinyuan Qian, Mike Zheng Shou, and Haizhou Li
SAM Audio: Segment Anything in Audio.arXiv preprint arXiv:2512.18099(2025). Ruijie Tao, Zexu Pan, Rohan Kumar Das, Xinyuan Qian, Mike Zheng Shou, and Haizhou Li
-
[25]
Mova: Towards scalable and synchronized video-audio generation.arXiv preprint arXiv:2602.08794, 2026
Mova: Towards scalable and synchronized video-audio generation.arXiv preprint arXiv:2602.08794(2026). Linrui Tian, Siqi Hu, Qi Wang, Bang Zhang, and Liefeng Bo
-
[26]
Emo2: End- effector guided audio-driven avatar video generation,
EMO2: End-Effector Guided Audio-Driven Avatar Video Generation.arXiv preprint arXiv:2501.10687 (2025). Andros Tjandra, Yi-Chiao Wu, Baishan Guo, John Hoffman, Brian Ellis, Apoorv Vyas, Bowen Shi, Sanyuan Chen, Matt Le, Nick Zacharov, et al
-
[27]
Meta Audiobox Aesthetics: Unified Automatic Quality Assessment for Speech, Music, and Sound
Meta Audiobox Aesthetics: Unified Automatic Quality Assessment for Speech, Music, and Sound. arXiv preprint arXiv:2502.05139(2025). Zhan Tong, Yibing Song, Jue Wang, and Limin Wang
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Videomae: Masked autoen- coders are data-efficient learners for self-supervised video pre-training.Advances in neural information processing systems35 (2022), 10078–10093. Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly
work page 2022
-
[29]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Towards accurate generative models of video: A new metric & challenges.arXiv:1812.01717(2018). Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. 2025a. Wan: Open and Advanced Large-Scale Video Generative Models.arXiv preprint arXiv:2503.20314(2025). Team Wan, Ang Wang, Baole Ai, Bin We...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[30]
UniVerse-1: Unified audio-video generation via stitching of experts,
UniVerse-1: Unified Audio-Video Generation via Stitching of Experts.arXiv preprint arXiv:2509.06155(2025). Jiapeng Wang, Chengyu Wang, Kunzhe Huang, Jun Huang, and Lianwen Jin. 2024a. Videoclip-xl: Advancing long description understanding for video clip models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Pro- cessing. 16...
-
[31]
Shuchen Weng, Haojie Zheng, Zheng Chang, Si Li, Boxin Shi, and Xinlong Wang
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing13, 4 (2004), 600–612. Shuchen Weng, Haojie Zheng, Zheng Chang, Si Li, Boxin Shi, and Xinlong Wang
work page 2004
-
[32]
Audio-Sync Video Generation with Multi-Stream Temporal Control.arXiv preprint arXiv:2506.08003(2025). Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, Stan Weixian Lei, Yuchao Gong, Yufei Shi, Mike Zheng Shou, David Junhao Yang, Ming-Hsuan Hsu, and Ying Shan
-
[33]
Tune- A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation. InProceedings of the IEEE/CVF International Conference on Computer Vision. Weijia Wu, Mingwu Li, Jiawang Liu, Zhipeng Hu, Xiangtai Li, Kevin Qinghong Zhu, Xiao Tian, Yang Zhao, Bauer Chen, Yuyang Yang, et al . 2025b. MovieBench: A Hierarchical Movie Level Dataset for Lo...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
AVI-Edit: Audio-sync Video Instance Editing with Granularity-Aware Mask Refiner
Audio-sync Video Instance Editing with Granularity-Aware Mask Refiner.arXiv preprint arXiv:2512.10571(2025). Bojia Zi, Penghui Ruan, Marco Chen, Xianbiao Qi, Shaozhe Hao, Shihao Zhao, Youze Huang, Bin Liang, Rong Xiao, and Kam-Fai Wong
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Se\˜ norita-2M: A High- Quality Instruction-based Dataset for General Video Editing by Video Specialists. arXiv preprint arXiv:2502.06734(2025)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.