Leveraging Latent Visual Reasoning in Silence
Pith reviewed 2026-05-20 10:23 UTC · model grok-4.3
The pith
Latent visual reasoning improves visual grounding and textual reasoning during training even when the latent tokens are rarely generated at inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
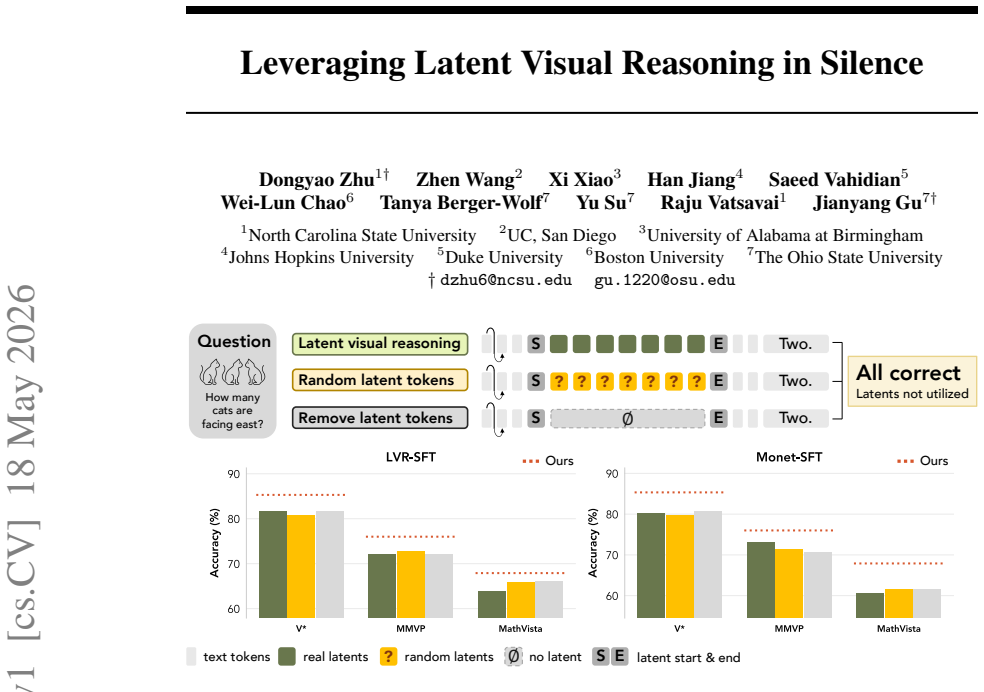
Latent visual reasoning remains meaningful because its tokens guide learning during training rather than serving as a persistent inference-time format. Replacing or removing the tokens causes little degradation, and post-training RL diminishes their generation, yet an attention-based reward that encourages latent tokens to interact with later text tokens during RL improves visual grounding and textual reasoning accuracy across benchmarks while preserving flexibility for text-only paths.
What carries the argument
An attention-based reward applied during reinforcement learning that encourages generated latent tokens to interact with later text tokens.
If this is right
- Performance improves on perception and visual reasoning benchmarks even when latent tokens are rarely generated after training.
- The model retains flexibility to switch to pure-text reasoning when the latent mode is not activated.
- Latent utilization is promoted specifically when the latent mode is active without forcing it in all cases.
- Better visual grounding and more accurate textual reasoning occur through internal shaping during learning.
Where Pith is reading between the lines
- Similar reward mechanisms could be tested in other multimodal or language models to shape useful internal representations that are discarded at test time.
- The finding that hard task-level routing for latent modes is brittle points to reward-based methods as a more robust alternative for selective reasoning activation.
- This training dynamic might generalize to other latent structures in AI systems where the benefit occurs during optimization rather than in the final output format.
Load-bearing premise
Performance gains arise specifically from improved latent-to-text interactions encouraged by the reward rather than from other changes in the RL training procedure.
What would settle it
Running the same RL post-training but with the attention-based reward disabled and checking whether the reported gains on perception and visual reasoning benchmarks disappear.
Figures













read the original abstract
Latent visual reasoning involves visual evidence more directly in multimodal reasoning by inserting continuous latent tokens before textual generation. However, the necessity of these latent tokens at inference remains ambiguous. We show that replacing latent tokens with random noise or removing them completely causes little performance degradation across spatial reasoning benchmarks. Reinforcement learning further diminishes the latent generation behavior after post-training. These observations raise a central question: Is latent visual reasoning still meaningful? We argue that its value should be measured by how effectively latent tokens guide learning, rather than whether they persist as an inference-time format. Our analysis shows that latent reasoning is unevenly favorable across question types, yet hard task-level routing for applying latent generation is brittle. Motivated by these findings, we propose an attention-based reward that encourages generated latent tokens to interact with later text tokens during RL. This reward promotes latent utilization when the latent mode is activated while preserving the flexibility to use pure-text reasoning. Experiments show that our method improves performance across perception and visual reasoning benchmarks, even when latent tokens are rarely generated after post-training. Our results highlight that, without explicit expression at inference, latent visual reasoning can shape better visual grounding and more accurate textual reasoning in silence. Our code and trained models are publicly available at \href{https://github.com/ddydyd32/silent-lvr/tree/master}{GitHub} and \href{https://huggingface.co/collections/cornuHGF/silent-lvr}{Hugging Face}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates latent visual reasoning in multimodal models via insertion of continuous latent tokens prior to textual generation. It reports that replacing these tokens with noise or removing them entirely yields minimal degradation on spatial reasoning benchmarks, while RL post-training further reduces latent generation. The authors argue that the utility of latent reasoning lies in its role guiding learning rather than requiring explicit use at inference, and introduce an attention-based reward during RL to promote interactions between generated latent tokens and subsequent text tokens. Experiments indicate performance gains on perception and visual reasoning tasks even when latent tokens are rarely generated post-training, supporting the claim that latent visual reasoning can improve visual grounding and textual reasoning 'in silence'.
Significance. If the mechanism is isolated as claimed, the work reframes latent tokens as a training-time scaffold rather than an inference-time necessity, with potential implications for efficient multimodal inference. Public release of code and models strengthens reproducibility. The result is interesting but its significance depends on confirming that gains arise specifically from encouraged latent-text interactions during RL rather than ancillary optimization effects.
major comments (2)
- [Experiments] Experiments section: The reported benchmark improvements with the attention-based reward are not supported by an ablation that removes or disables only the latent-specific attention term while holding total reward magnitude and training schedule fixed. This control is load-bearing for the central claim, given the paper's own finding that RL already diminishes latent generation and that latent tokens can be replaced or removed with little degradation.
- [RL training description] RL training and reward definition: No quantitative metrics (e.g., attention maps or interaction scores between latent and text tokens) are provided to demonstrate that the reward specifically increases latent-text interactions rather than altering gradient flow or regularization on the text pathway alone.
minor comments (2)
- [Abstract] Abstract and §1: The term 'in silence' is used to describe inference without explicit latent expression; a brief operational definition in the main text would improve clarity.
- [Results] Results tables: Inclusion of statistical significance tests and more granular baseline details (exact model variants, hyperparameter matches) would strengthen the empirical claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the experimental controls needed to support our central claims about the attention-based reward. We address each point below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The reported benchmark improvements with the attention-based reward are not supported by an ablation that removes or disables only the latent-specific attention term while holding total reward magnitude and training schedule fixed. This control is load-bearing for the central claim, given the paper's own finding that RL already diminishes latent generation and that latent tokens can be replaced or removed with little degradation.
Authors: We agree that the requested ablation is essential for isolating the effect of the latent-specific attention term. In the revised manuscript we will add this control experiment, disabling only the attention component while preserving identical total reward magnitude and training schedule. This will allow direct comparison to the full reward and help confirm that gains arise from promoted latent-text interactions rather than ancillary RL effects. revision: yes
-
Referee: [RL training description] RL training and reward definition: No quantitative metrics (e.g., attention maps or interaction scores between latent and text tokens) are provided to demonstrate that the reward specifically increases latent-text interactions rather than altering gradient flow or regularization on the text pathway alone.
Authors: We acknowledge that explicit quantitative metrics would strengthen the mechanistic interpretation. While the overall benchmark gains are consistent with our design, we will include in the revision computed interaction scores (e.g., average attention weights between latent and subsequent text tokens) and selected attention map visualizations to show the reward's specific effect on latent-text interactions. revision: yes
Circularity Check
No circularity: empirical observations and benchmark tests
full rationale
The paper advances its claims through a sequence of empirical observations (latent tokens replaceable by noise with little degradation; RL diminishing latent generation) followed by introduction of an attention-based reward during RL training and measurement of resulting benchmark gains. No derivation chain exists that reduces a claimed result to its own inputs by construction, no fitted parameter is relabeled as a prediction, and no load-bearing premise rests on a self-citation whose validity is internal to the authors' prior work. The central argument—that latent reasoning shapes learning even when suppressed at inference—is presented as an interpretation of experimental outcomes rather than a mathematical necessity, making the findings independently falsifiable via the reported controls and public code.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard reinforcement learning assumptions for post-training multimodal models hold and do not introduce confounding factors in the observed latent token behavior
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose an attention-based reward that encourages generated latent tokens to interact with later text tokens during RL... R_i^A = 1/|T_t| ∑_{j∈T_t} ∑_{k∈T_L} A_{j,k}
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
latent visual reasoning can shape better visual grounding and more accurate textual reasoning in silence
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Sule Bai, Mingxing Li, Yong Liu, Jing Tang, Haoji Zhang, Lei Sun, Xiangxiang Chu, and Yansong Tang. Univg-r1: Reasoning guided universal visual grounding with reinforcement learning.arXiv preprint arXiv:2505.14231, 2025. 3
-
[2]
All you may need for vqa are image captions
Soravit Changpinyo, Doron Kukliansy, Idan Szpektor, Xi Chen, Nan Ding, and Radu Soricut. All you may need for vqa are image captions. InProceedings of the 2022 conference of the north american chapter of the association for computational linguistics: human language technologies, pages 1947–1963, 2022. 3
work page 2022
-
[3]
Liangyu Chen, Bo Li, Sheng Shen, Jingkang Yang, Chunyuan Li, Kurt Keutzer, Trevor Darrell, and Ziwei Liu. Large language models are visual reasoning coordinators.Advances in Neural Information Processing Systems, 36:70115–70140, 2023. 3
work page 2023
-
[4]
Zixu Cheng, Jian Hu, Ziquan Liu, Chenyang Si, Wei Li, and Shaogang Gong. V-star: Bench- marking video-llms on video spatio-temporal reasoning.arXiv preprint arXiv:2503.11495,
-
[5]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Vlmevalkit: An open-source toolkit for evaluating large multi-modality models
Haodong Duan, Junming Yang, Yuxuan Qiao, Xinyu Fang, Lin Chen, Yuan Liu, Xiaoyi Dong, Yuhang Zang, Pan Zhang, Jiaqi Wang, et al. Vlmevalkit: An open-source toolkit for evaluating large multi-modality models. InProceedings of the 32nd ACM International Conference on Multimedia, pages 11198–11201, 2024. 3, 7
work page 2024
-
[7]
Blink: Multimodal large language models can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. InEuropean Conference on Computer Vision, pages 148–166. Springer, 2024. 2
work page 2024
-
[8]
Gemini 3.1 pro model card, 2026
Google DeepMind. Gemini 3.1 pro model card, 2026. URL https://storage.googleapis. com/deepmind-media/Model-Cards/Gemini-3-1-Pro-Model-Card.pdf. 7
work page 2026
-
[9]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Training Large Language Models to Reason in a Continuous Latent Space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Yushi Hu, Hang Hua, Zhengyuan Yang, Weijia Shi, Noah A. Smith, and Jiebo Luo. Promptcap: Prompt-guided image captioning for vqa with gpt-3. In2023 IEEE/CVF International Confer- ence on Computer Vision (ICCV), pages 2951–2963, 2023. doi: 10.1109/ICCV51070.2023. 00277. 3
-
[12]
Yushi Hu, Weijia Shi, Xingyu Fu, Dan Roth, Mari Ostendorf, Luke Zettlemoyer, Noah A Smith, and Ranjay Krishna. Visual sketchpad: Sketching as a visual chain of thought for multimodal language models.Advances in Neural Information Processing Systems, 37:139348–139379,
-
[13]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large lan- guage model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023. 15
work page 2023
-
[14]
Latent visual reasoning.ICLR, 2026
Bangzheng Li, Ximeng Sun, Jiang Liu, Ze Wang, Jialian Wu, Xiaodong Yu, Hao Chen, Emad Barsoum, Muhao Chen, and Zicheng Liu. Latent visual reasoning.ICLR, 2026. 2, 3, 4, 13, 14 10
work page 2026
-
[15]
Imagine while reasoning in space: multimodal visualization-of-thought
Chengzu Li, Wenshan Wu, Huanyu Zhang, Yan Xia, Shaoguang Mao, Li Dong, Ivan Vuli ´c, and Furu Wei. Imagine while reasoning in space: multimodal visualization-of-thought. In Proceedings of the 42nd International Conference on Machine Learning, ICML’25. JMLR.org,
-
[16]
Imagination helps visual reasoning, but not yet in latent space, 2026
You Li, Chi Chen, Yanghao Li, Fanhu Zeng, Kaiyu Huang, Jinan Xu, and Maosong Sun. Imagination helps visual reasoning, but not yet in latent space.arXiv preprint arXiv:2602.22766,
-
[17]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233. Springer, 2024. 2, 7
work page 2024
-
[18]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts.arXiv preprint arXiv:2310.02255, 2023. 2, 7
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Cogcom: A visual language model with chain-of-manipulations reasoning
Ji Qi, Ming Ding, Weihan Wang, Yushi Bai, Qingsong Lv, Wenyi Hong, Bin Xu, Lei Hou, Juanzi Li, Yuxiao Dong, et al. Cogcom: A visual language model with chain-of-manipulations reasoning.arXiv preprint arXiv:2402.04236, 2024. 3
-
[20]
Chain-of-visual-thought: Teaching vlms to see and think better with continuous visual tokens,
Yiming Qin, Bomin Wei, Jiaxin Ge, Konstantinos Kallidromitis, Stephanie Fu, Trevor Darrell, and XuDong Wang. Chain-of-visual-thought: Teaching vlms to see and think better with continuous visual tokens.arXiv preprint arXiv:2511.19418, 2025. 3
-
[21]
Thinking Without Words: Efficient Latent Reasoning with Abstract Chain-of-Thought
Keshav Ramji, Tahira Naseem, and Ramón Fernandez Astudillo. Thinking without words: Efficient latent reasoning with abstract chain-of-thought.arXiv preprint arXiv:2604.22709,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert- networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 11 2019. URL https://arxiv.org/ abs/1908.10084. 5
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[23]
Hao Shao, Shengju Qian, Han Xiao, Guanglu Song, Zhuofan Zong, Letian Wang, Yu Liu, and Hongsheng Li. Visual cot: Advancing multi-modal language models with a comprehen- sive dataset and benchmark for chain-of-thought reasoning.Advances in Neural Information Processing Systems, 37:8612–8642, 2024. 4
work page 2024
-
[24]
Codi: Com- pressing chain-of-thought into continuous space via self-distillation
Zhenyi Shen, Hanqi Yan, Linhai Zhang, Zhanghao Hu, Yali Du, and Yulan He. Codi: Com- pressing chain-of-thought into continuous space via self-distillation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 677–693, 2025. 3
work page 2025
-
[25]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, pages 1279–1297,
-
[26]
Multimodal latent language modeling with next- token diffusion,
Yutao Sun, Hangbo Bao, Wenhui Wang, Zhiliang Peng, Li Dong, Shaohan Huang, Jianyong Wang, and Furu Wei. Multimodal latent language modeling with next-token diffusion.arXiv preprint arXiv:2412.08635, 2024. 3
-
[27]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Chameleon Team. Chameleon: Mixed-modal early-fusion foundation models, 2024.URL https://arxiv. org/abs/2405.09818, 9(8), 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Winoground: Probing vision and language models for visio-linguistic compositionality
Tristan Thrush, Ryan Jiang, Max Bartolo, Amanpreet Singh, Adina Williams, Douwe Kiela, and Candace Ross. Winoground: Probing vision and language models for visio-linguistic compositionality. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5238–5248, 2022. 2
work page 2022
-
[29]
Sketch-in-latents: Eliciting unified reasoning in mllms.arXiv preprint arXiv:2512.16584,
Jintao Tong, Jiaqi Gu, Yujing Lou, Lubin Fan, Yixiong Zou, Yue Wu, Jieping Ye, and Ruixuan Li. Sketch-in-latents: Eliciting unified reasoning in mllms.arXiv preprint arXiv:2512.16584,
-
[30]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 6
work page 2017
-
[31]
VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning
Haozhe Wang, Chao Qu, Zuming Huang, Wei Chu, Fangzhen Lin, and Wenhu Chen. Vl- rethinker: Incentivizing self-reflection of vision-language models with reinforcement learning. arXiv preprint arXiv:2504.08837, 2025. 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Monet: Reasoning in latent visual space beyond images and language,
Qixun Wang, Yang Shi, Yifei Wang, Yuanxing Zhang, Pengfei Wan, Kun Gai, Xianghua Ying, and Yisen Wang. Monet: Reasoning in latent visual space beyond images and language.arXiv preprint arXiv:2511.21395, 2025. 2, 3, 4, 6, 7, 14, 15
-
[33]
Wenbin Wang, Liang Ding, Minyan Zeng, Xiabin Zhou, Li Shen, Yong Luo, Wei Yu, and Dacheng Tao. Divide, conquer and combine: A training-free framework for high-resolution image perception in multimodal large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 7907–7915, 2025. 7
work page 2025
-
[34]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022. 3
work page 2022
-
[35]
Mingyuan Wu, Jingcheng Yang, Jize Jiang, Meitang Li, Kaizhuo Yan, Hanchao Yu, Minjia Zhang, Chengxiang Zhai, and Klara Nahrstedt. Vtool-r1: Vlms learn to think with images via reinforcement learning on multimodal tool use.arXiv preprint arXiv:2505.19255, 2025. (Accepted, ICLR 2026). 3
-
[36]
Weiye Xu, Jiahao Wang, Weiyun Wang, Zhe Chen, Wengang Zhou, Aijun Yang, Lewei Lu, Houqiang Li, Xiaohua Wang, Xizhou Zhu, et al. Visulogic: A benchmark for evaluating visual reasoning in multi-modal large language models.arXiv preprint arXiv:2504.15279, 2025. (Accepted, ICLR 2026). 2
-
[37]
Mmvp: A multimodal mocap dataset with vision and pressure sensors
He Zhang, Shenghao Ren, Haolei Yuan, Jianhui Zhao, Fan Li, Shuangpeng Sun, Zhenghao Liang, Tao Yu, Qiu Shen, and Xun Cao. Mmvp: A multimodal mocap dataset with vision and pressure sensors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21842–21852, 2024. 4, 7
work page 2024
-
[38]
Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Yu Qiao, et al. Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? InEuropean Conference on Computer Vision, pages 169–186. Springer, 2024. 7
work page 2024
-
[39]
Yi-Fan Zhang, Huanyu Zhang, Haochen Tian, Chaoyou Fu, Shuangqing Zhang, Junfei Wu, Feng Li, Kun Wang, Qingsong Wen, Zhang Zhang, et al. Mme-realworld: Could your multimodal llm challenge high-resolution real-world scenarios that are difficult for humans?arXiv preprint arXiv:2408.13257, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Yi-Fan Zhang, Xingyu Lu, Shukang Yin, Chaoyou Fu, Wei Chen, Xiao Hu, Bin Wen, Kaiyu Jiang, Changyi Liu, Tianke Zhang, et al. Thyme: Think beyond images.arXiv preprint arXiv:2508.11630, 2025. (Accepted, ICLR 2026). 4, 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Ziwei Zheng, Michael Yang, Jack Hong, Chenxiao Zhao, Guohai Xu, Le Yang, Chao Shen, and Xing Yu. Deepeyes: Incentivizing" thinking with images" via reinforcement learning.arXiv preprint arXiv:2505.14362, 2025. (Accepted, ICLR 2026). 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Reinforced visual perception with tools.arXiv preprint arXiv:2509.01656, 2025
Zetong Zhou, Dongping Chen, Zixian Ma, Zhihan Hu, Mingyang Fu, Sinan Wang, Yao Wan, Zhou Zhao, and Ranjay Krishna. Reinforced visual perception with tools.arXiv preprint arXiv:2509.01656, 2025. 3 12 Appendix The appendix is organized as follows. • In §A, we discuss the societal impact of this research. • In §B, we discuss the current limitations of this r...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.