MOCHA: Multi-Objective Chebyshev Annealing for Agent Skill Optimization
Pith reviewed 2026-05-20 06:05 UTC · model grok-4.3
The pith
MOCHA optimizes LLM agent skills across conflicting platform constraints by using Chebyshev scalarization to cover the full Pareto front plus annealing to shift from exploration to exploitation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MOCHA replaces single-objective selection with Chebyshev scalarization that covers the full Pareto front, including non-convex regions, combined with exponential annealing that transitions from exploration to exploitation. Across six diverse agent skills, all methods share the identical multi-objective mutation operator and baselines receive identical per-objective textual feedback; existing optimizers fail to improve the seed skill on four of the six tasks after 1000 rollouts, while MOCHA improves on every task with a 7.5 percent relative gain in mean correctness and twice as many Pareto-optimal variants.
What carries the argument
Chebyshev scalarization, which minimizes the maximum weighted deviation from ideal per-objective values so that non-convex parts of the Pareto front remain reachable, paired with an exponential annealing schedule that gradually tightens the search from exploration to exploitation.
If this is right
- Skill libraries for agents can be maintained as explicit Pareto sets rather than single best prompts, letting deployers pick variants that fit different context budgets.
- Multi-objective mutation plus Chebyshev selection can be dropped into existing agent frameworks without changing the mutation code or the feedback format.
- Tasks that previously showed zero progress under weighted-sum or single-objective optimizers become solvable once the full non-convex front is searched.
- The annealing schedule provides a controllable knob between discovering diverse skill variants and converging on high-correctness ones for a given deployment.
- Platform constraints such as description length and instruction compaction become first-class objectives instead of after-the-fact filters.
Where Pith is reading between the lines
- The same Chebyshev-plus-annealing pattern could be applied to other LLM tuning problems that trade accuracy against latency or cost, even outside agent skill design.
- If the annealing temperature is made adaptive to the observed spread of objective values rather than fixed, further reductions in the number of wasted rollouts may be possible.
- Extending the method to include dynamic context-window resizing as an additional objective would test whether the Pareto front itself moves during deployment.
- Open-sourcing the discovered Pareto skill sets would let downstream researchers measure how much of the reported gain transfers to new model families or new task distributions.
Load-bearing premise
That giving every optimizer the same mutation operator and the same per-objective textual feedback isolates the benefit to the selection mechanism, and that the six chosen tasks represent the hard platform constraints typical in actual LLM deployments.
What would settle it
Re-running the identical experimental protocol but on a new set of tasks whose context-window or truncation limits are twice as severe, then checking whether MOCHA still improves correctness on every task and still returns at least twice the number of Pareto-optimal variants.
Figures













read the original abstract
LLM agents organize behavior through skills - structured natural-language specifications governing how an agent reasons, retrieves, and responds. Unlike monolithic prompts, skills are multi-field artifacts subject to hard platform constraints: description fields are truncated for routing, instruction bodies are compacted via progressive disclosure, and co-resident skills compete for limited context windows. These constraints make skill optimization inherently multi-objective: a skill must simultaneously maximize task performance and satisfy platform limits. Yet existing prompt optimizers either ignore these trade-offs or collapse them into a weighted sum, missing Pareto-optimal variants in non-convex objective regions. We introduce MOCHA (Multi-Objective Chebyshev Annealing), which replaces single-objective selection with Chebyshev scalarization - covering the full Pareto front, including non-convex regions - combined with exponential annealing that transitions from exploration to exploitation. In our experiments across six diverse agent skills - where all methods share the same multi-objective mutation operator and baselines receive identical per-objective textual feedback - existing optimizers fail to improve the seed skill on 4 of 6 tasks: 1000 rollouts yield zero progress. MOCHA breaks through on every task, achieving 7.5% relative improvement in mean correctness over the strongest baseline (up to 14.9% on FEVER and 10.4% on TheoremQA) while discovering twice as many more Pareto-optimal skill variants.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MOCHA, which applies Chebyshev scalarization combined with exponential annealing to optimize LLM agent skills as multi-objective artifacts subject to platform constraints such as truncation and context limits. It claims that, when all methods share the same multi-objective mutation operator and per-objective feedback, MOCHA improves mean correctness by 7.5% relative to the strongest baseline (with peaks of 14.9% on FEVER and 10.4% on TheoremQA), discovers twice as many Pareto-optimal variants, and succeeds on all six tasks while baselines fail on four even after 1000 rollouts.
Significance. If the reported gains prove robust under statistical controls and the experimental isolation of the selection mechanism holds, the work would meaningfully advance multi-objective prompt and skill optimization for constrained LLM agents by addressing non-convex Pareto fronts without weighted-sum collapse. The concrete task-specific numbers and the emphasis on platform constraints provide a practical contribution, though the current empirical presentation limits immediate impact.
major comments (2)
- [Abstract] Abstract and experimental results: the reported 7.5% relative improvement in mean correctness (and task-specific gains) is presented without variance estimates, statistical significance tests, exact rollout counts per method, or a precise definition and measurement procedure for Pareto optimality. This omission makes the central empirical claim difficult to evaluate and requires additional tables or reporting to substantiate.
- [Experiments] Experimental setup: the design asserts that sharing the identical multi-objective mutation operator and per-objective textual feedback across methods isolates the benefit of Chebyshev scalarization plus annealing. However, without an ablation that swaps only the selection rule while holding mutation fixed, performance differences could arise from asymmetric interactions between mutation proposals and selection dynamics rather than the claimed MOCHA components; this assumption is load-bearing for attributing the 7.5% lift and doubled Pareto count.
minor comments (1)
- [Abstract] Abstract: the phrasing 'twice as many more Pareto-optimal skill variants' is imprecise and should be replaced with exact counts and a clear definition of how Pareto optimality is determined in the skill space.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments on our manuscript. We address each of the major comments below and have made revisions to improve the clarity and robustness of our empirical claims.
read point-by-point responses
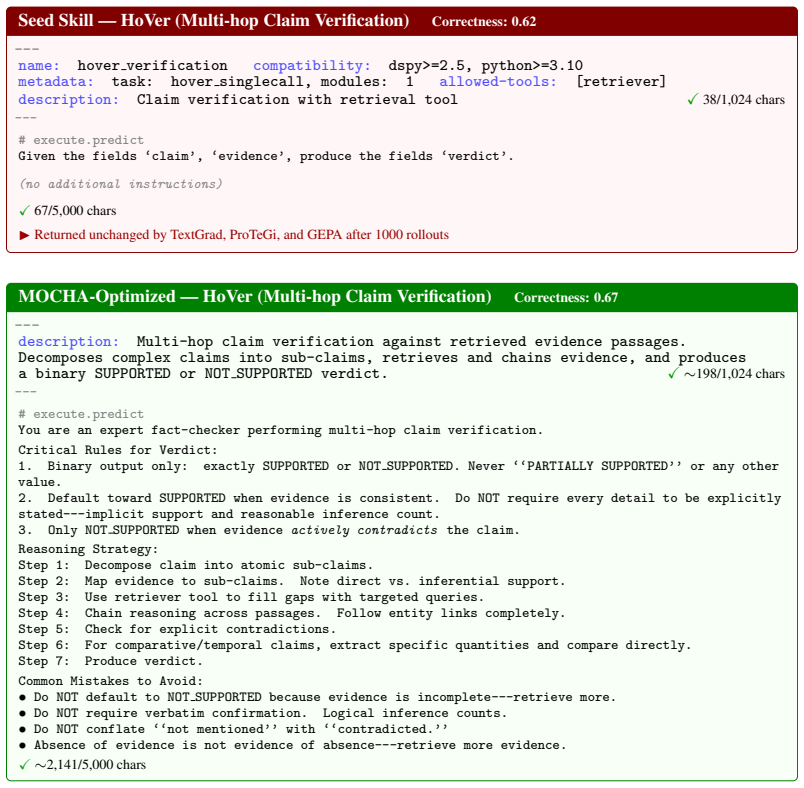
-
Referee: [Abstract] Abstract and experimental results: the reported 7.5% relative improvement in mean correctness (and task-specific gains) is presented without variance estimates, statistical significance tests, exact rollout counts per method, or a precise definition and measurement procedure for Pareto optimality. This omission makes the central empirical claim difficult to evaluate and requires additional tables or reporting to substantiate.
Authors: We agree with the referee that the empirical claims would benefit from additional statistical rigor and precise reporting. In the revised manuscript, we have included variance estimates from multiple independent runs, conducted statistical significance tests (such as paired t-tests with p-values reported), specified the exact number of rollouts for each method, and added a clear definition and measurement procedure for identifying Pareto-optimal variants. These details are now presented in a new supplementary table and expanded experimental section. revision: yes
-
Referee: [Experiments] Experimental setup: the design asserts that sharing the identical multi-objective mutation operator and per-objective textual feedback across methods isolates the benefit of Chebyshev scalarization plus annealing. However, without an ablation that swaps only the selection rule while holding mutation fixed, performance differences could arise from asymmetric interactions between mutation proposals and selection dynamics rather than the claimed MOCHA components; this assumption is load-bearing for attributing the 7.5% lift and doubled Pareto count.
Authors: We thank the referee for highlighting this important point about experimental isolation. Our original design ensured that the multi-objective mutation operator and per-objective feedback are identical across all compared methods, with the only varying component being the selection mechanism. This directly attributes differences to the Chebyshev scalarization and annealing in MOCHA. To further strengthen this isolation, we have added an explicit ablation experiment in the revised manuscript where we hold the mutation operator fixed and vary only the selection rule, demonstrating that the performance improvements stem from MOCHA's selection strategy rather than interactions. revision: yes
Circularity Check
No significant circularity; derivation and claims are self-contained
full rationale
The paper presents MOCHA as an algorithmic combination of Chebyshev scalarization for Pareto coverage and exponential annealing for exploration-exploitation transition. The central claims of improved mean correctness and doubled Pareto-optimal variants are supported by empirical results on six tasks under a shared mutation operator. No equation, selection rule, or performance metric reduces by construction to a fitted parameter, self-citation chain, or input definition. The experimental isolation of selection benefit is an assumption about fairness rather than a definitional tautology, and the derivation does not invoke uniqueness theorems or ansatzes from prior self-work that would force the outcome.
Axiom & Free-Parameter Ledger
free parameters (1)
- annealing rate and Chebyshev parameter
axioms (1)
- domain assumption Chebyshev scalarization can cover the full Pareto front including non-convex regions
Reference graph
Works this paper leans on
-
[1]
Lakshya A. Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J. Ryan, Meng Jiang, Christopher Potts, Koushik Sen, Alexandros G. Dimakis, Dan Klein, Ion Stoica, Matei Zaharia, and Omar Khattab. GEPA: Reflective prompt evolution can outperform reinforcement learning. InICLR, 2026
work page 2026
-
[2]
Anthropic. Extend claude with skills. https://code.claude.com/docs/en/skills. Ac- cessed: 2026-04-25
work page 2026
-
[3]
Approximation quality of the hypervolume indicator
Karl Bringmann and Tobias Friedrich. Approximation quality of the hypervolume indicator. Artificial Intelligence, 195:265–290, 2013
work page 2013
-
[4]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. InNeurIPS, volume 33, pages 1877–1901, 2020
work page 1901
-
[5]
TheoremQA: A theorem-driven question answering dataset
Wenhu Chen, Ming Yin, Max Ku, Pan Lu, Yixin Wan, Xueguang Ma, Jianyu Xu, Xinyi Wang, and Tony Xia. TheoremQA: A theorem-driven question answering dataset. InEMNLP, pages 7889–7901, 2023
work page 2023
-
[6]
Ching-An Cheng, Allen Nie, and Adith Swaminathan. Trace is the next autodiff: Generative optimization with rich feedback, execution traces, and LLMs.arXiv preprint arXiv:2406.16218, 2024
-
[7]
Differentiable expected hypervolume improvement for parallel multi-objective Bayesian optimization
Samuel Daulton, Maximilian Balandat, and Eytan Bakshy. Differentiable expected hypervolume improvement for parallel multi-objective Bayesian optimization. InNeurIPS, volume 33, pages 9851–9864, 2020
work page 2020
-
[8]
Kalyanmoy Deb, Amrit Pratap, Sameer Agarwal, and TAMT Meyarivan. A fast and elitist multiobjective genetic algorithm: Nsga-ii.IEEE Transactions on Evolutionary Computation, 6 (2):182–197, 2002
work page 2002
-
[9]
Mingkai Deng, Jianyu Wang, Cheng-Ping Hsieh, Yihan Wang, Han Guo, Tianmin Shu, Meng Song, Eric P. Xing, and Zhiting Hu. RLPrompt: Optimizing discrete text prompts with reinforcement learning. InEMNLP, 2022
work page 2022
-
[10]
Michael T. M. Emmerich and Andr ´e H. Deutz. A tutorial on multiobjective optimization: Fundamentals and evolutionary methods.Natural Computing, 17(3):585–609, 2018
work page 2018
-
[11]
Andreia P. Guerreiro, Carlos M. Fonseca, and Lu ´ıs Paquete. The hypervolume indicator: Problems and algorithms.ACM Computing Surveys, 54(6):1–42, 2021
work page 2021
-
[12]
EvoPrompt: Connecting LLMs with Evolutionary Algorithms Yields Powerful Prompt Optimizers
Qingyan Guo, Rui Wang, Junliang Guo, Bei Li, Kaitao Song, Xu Tan, Guoqing Liu, Jiang Bian, and Yujiu Yang. Connecting large language models with evolutionary algorithms yields powerful prompt optimizers.arXiv preprint arXiv:2309.08532, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
HoVer: A dataset for many-hop fact extraction and claim verification
Yichen Jiang, Shikha Bordia, Zheng Zhong, Charles Dognin, Maneesh Singh, and Mohit Bansal. HoVer: A dataset for many-hop fact extraction and claim verification. InFindings of EMNLP, 2020
work page 2020
-
[14]
Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. DSPy: Compiling declarative language model calls into self-improving pipelines. InICLR, 2024
work page 2024
-
[15]
Meta-Harness: End-to-End Optimization of Model Harnesses
Yoonho Lee, Roshen Nair, Qizheng Zhang, Kangwook Lee, Omar Khattab, and Chelsea Finn. Meta-harness: End-to-end optimization of model harnesses.arXiv preprint arXiv:2603.28052, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Smooth tchebycheff scalarization for multi-objective optimization
Xi Lin, Xiaoyuan Zhang, Zhiyuan Yang, Fei Liu, Zhenkun Wang, and Qingfu Zhang. Smooth tchebycheff scalarization for multi-objective optimization. InICML, 2024. 10
work page 2024
-
[17]
Eureka: Human-level reward design via coding large language models
Yecheng Jason Ma, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Eureka: Human-level reward design via coding large language models. InICLR, 2024
work page 2024
-
[18]
Kaisa Miettinen.Nonlinear Multiobjective Optimization. Springer, Boston, MA, 1999
work page 1999
-
[19]
Multi-objective alignment of large language models through hypervolume maximization
Subhojyoti Mukherjee, Anusha Lalitha, Sailik Sengupta, Aniket Deshmukh, and Branislav Kve- ton. Multi-objective alignment of large language models through hypervolume maximization. arXiv preprint arXiv:2412.05469, 2024
-
[20]
Ryan, Josh Purtell, David Broman, Christopher Potts, Matei Zaharia, and Omar Khattab
Krista Opsahl-Ong, Michael J. Ryan, Josh Purtell, David Broman, Christopher Potts, Matei Zaharia, and Omar Khattab. Optimizing instructions and demonstrations for multi-stage language model programs. InEMNLP, 2024
work page 2024
-
[21]
Reid Pryzant, Dan Iter, Jerry Li, Yin Tat Lee, Chenguang Zhu, and Michael Zeng. Automatic prompt optimization with “gradient descent” and beam search. InEMNLP, 2023
work page 2023
-
[22]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. GPQA: A graduate-level google-proof q&a benchmark.arXiv preprint arXiv:2311.12022, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
FEVER: a large-scale dataset for fact extraction and VERification
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. FEVER: a large-scale dataset for fact extraction and VERification. InNAACL-HLT, pages 809–819, 2018
work page 2018
-
[24]
DebugBench: Evaluating debugging capability of large language models
Runchu Tian, Yining Ye, Yujia Qin, Xin Cong, Yankai Lin, Yinxu Pan, Yesai Wu, Haotian Hui, Weichuan Liu, Zhiyuan Liu, and Maosong Sun. DebugBench: Evaluating debugging capability of large language models. InFindings of ACL, pages 4173–4198, 2024
work page 2024
-
[25]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Haoxiang Wang, Yong Lin, Wei Xiong, Rui Yang, Shizhe Diao, Shuang Qiu, Han Zhao, and Tong Zhang. Arithmetic control of LLMs for diverse user preferences: Directional preference alignment with multi-objective rewards.arXiv preprint arXiv:2402.18571, 2024
-
[27]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. In NeurIPS, volume 35, pages 24824–24837, 2022
work page 2022
-
[28]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, Zeyu Zheng, Cihang Xie, and Huaxiu Yao. Skillrl: Evolving agents via recursive skill-augmented reinforcement learning.arXiv preprint arXiv:2602.08234, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Large language models as optimizers
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou, and Xinyun Chen. Large language models as optimizers. InICLR, 2024
work page 2024
-
[30]
Cohen, Ruslan Salakhut- dinov, and Christopher D
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhut- dinov, and Christopher D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. InEMNLP, pages 2369–2380, 2018
work page 2018
-
[31]
TextGrad: Automatic "Differentiation" via Text
Mert Y¨uksekg¨on¨ul, Federico Bianchi, Joseph Boen, Sheng Liu, Zhi Huang, Carlos Guestrin, and James Zou. TextGrad: Automatic “differentiation” via text.arXiv preprint arXiv:2406.07496, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Large language models are human-level prompt engineers
Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. Large language models are human-level prompt engineers. InICLR, 2023
work page 2023
-
[33]
Beyond one-preference-fits-all alignment: Multi-objective direct preference optimization
Zhanhui Zhou, Jie Liu, Jing Shao, Xiangyu Yue, Chao Yang, Wanli Ouyang, and Yu Qiao. Beyond one-preference-fits-all alignment: Multi-objective direct preference optimization. In Findings of ACL, 2024. 11
work page 2024
-
[34]
Eckart Zitzler and Lothar Thiele. Multiobjective evolutionary algorithms: a comparative case study and the strength pareto approach.IEEE Transactions on Evolutionary Computation, 3(4): 257–271, 1999
work page 1999
-
[35]
Eckart Zitzler, Lothar Thiele, Marco Laumanns, Carlos M Fonseca, and Viviane Grunert Da Fonseca. Performance assessment of multiobjective optimizers: An analysis and review. IEEE Transactions on Evolutionary Computation, 7(2):117–132, 2003. 12 A Background: Scalarization and Hypervolume Theory We provide extended background on the theoretical foundations ...
work page 2003
-
[36]
Identify the domain and relevant theorem(s): State which theorem, formula, or principle applies
-
[37]
Define all variables and given quantities explicitly: Write out every given value with correct signs and units
-
[38]
Double-check: •Signs: Pay extreme attention to negative signs
Apply the theorem step by step: Show each algebraic/logical step. Double-check: •Signs: Pay extreme attention to negative signs. Never drop them. •Powers of 10: Verify exponent arithmetic carefully. •Units: Track throughout. Convert as needed but CHECK expected units
-
[39]
Domain-specific rules: •Resistance with geometry: Axial:R=ρL/(π(R 2 o −R 2 i )). Radial:R= (ρ/2πL) ln(R o/Ri). •Stopping times:Tis stopping time iff{T≤t} ∈ F t. Sum of non-negative stopping times IS a stopping time. •Iteration methods: For Aitken’s∆ 2, count iterations of the ACCELERATED method only. CRITICAL Formatting Rules: •If multiple sub-parts, retu...
-
[40]
Never ‘‘PARTIALLY SUPPORTED’’ or any other value
Binary output only: exactly SUPPORTED or NOT SUPPORTED. Never ‘‘PARTIALLY SUPPORTED’’ or any other value
-
[41]
Default toward SUPPORTED when evidence is consistent. Do NOT require every detail to be explicitly stated---implicit support and reasonable inference count
-
[42]
Only NOT SUPPORTED when evidenceactively contradictsthe claim. Reasoning Strategy: Step 1: Decompose claim into atomic sub-claims. Step 2: Map evidence to sub-claims. Note direct vs. inferential support. Step 3: Use retriever tool to fill gaps with targeted queries. Step 4: Chain reasoning across passages. Follow entity links completely. Step 5: Check for...
-
[43]
Identify what entity/fact each hop requires
Decompose: Break question into sub-questions. Identify what entity/fact each hop requires
-
[44]
Extract: Read every evidence piece. Extract all names (full formal names), dates, nicknames, roles, locations---even from parenthetical remarks
-
[45]
Retrieve: If evidence is insufficient, call retriever with targeted queries. Do NOT give up
-
[46]
Entity A in passage 1→Entity B in passage 2
Chain: Connect facts across passages. Entity A in passage 1→Entity B in passage 2
-
[47]
Synthesize: Determine final answer. Critical Rules for Answer Field: •Short exact phrase---name, date, number, place, or brief noun phrase. •EXACT form from evidence: ‘‘Jerral Wayne Jones Sr.’’ NOT ‘‘Jerry Jones’’. ‘‘Dayton, Ohio’’ NOT ‘‘Dayton’’. •Copy verbatim whenever possible. Preserve location qualifiers. •Use the most complete, formal name version f...
work page 1953
-
[48]
Fix ONLY the incorrect reference(s)
Understand bug type first---it determines fixing strategy: •reference error: Wrong variable/function/method name. Fix ONLY the incorrect reference(s). •syntax error: Missing colon, semicolon, bracket, wrong operator syntax. Fix ONLY syntax. •logic error: Off-by-one, wrong comparison, wrong return, wrong condition. Fix ONLY logic. •type error: Wrong type u...
-
[49]
A wrong fix is worse than a missing fix
Conservative fixing principle: When uncertain, do NOT change. A wrong fix is worse than a missing fix
-
[50]
Reproduce the rest EXACTLY---preserve all indentation, spacing, comments, structure. Reasoning Process: Step 1: Read bug type. Single-category or multiple? Step 2: Understand algorithm PURPOSE before making changes. Step 3: For each bug, state: (a) exact line, (b) what is wrong, (c) fix, (d) why it is definitely a bug. Step 4: For multiple error---count b...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.