FBOS-RL: Feedback-Driven Bi-Objective Synergistic Reinforcement Learning
Pith reviewed 2026-05-21 08:06 UTC · model grok-4.3
The pith
Environment feedback guides exploration while two reinforcing objectives accelerate reinforcement learning and raise its performance ceiling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FBOS-RL lets the model perform Feedback-Guided Exploration Enhancement based on environment feedback and then applies two mutually reinforcing training objectives: Exploitation-oriented Policy Alignment (EPA) and Exploration-oriented Capability Cultivation (ECC). These components form a positive flywheel effect that improves both training efficiency and the final performance ceiling of reinforcement learning.
What carries the argument
Feedback-Guided Exploration Enhancement combined with the bi-objective pair of Exploitation-oriented Policy Alignment (EPA) and Exploration-oriented Capability Cultivation (ECC) that produce mutual reinforcement.
If this is right
- Under an identical number of rollouts FBOS-RL learns substantially faster than GRPO and feedback-based baselines.
- FBOS-RL ultimately attains a higher performance ceiling than the compared methods.
- The training process maintains higher policy entropy and lower gradient norms throughout.
- The mutual reinforcement between EPA and ECC produces a flywheel that lifts both efficiency and final capability.
Where Pith is reading between the lines
- If environment feedback stays reliable for weak policies, the same steering principle could be added to other rollout strategies beyond the GRPO family.
- Sustained higher entropy during training may help long-horizon tasks that require continued exploration after initial progress.
- Lower gradient norms could reduce the need for extra clipping or regularization in large-model RL pipelines.
Load-bearing premise
The environment feedback must be sufficiently informative and unbiased to steer sampling toward useful rollouts even when the current policy is weak.
What would settle it
Apply FBOS-RL in an environment that supplies noisy or systematically biased feedback and check whether it still learns faster and reaches a higher final score than GRPO under the same rollout budget.
Figures















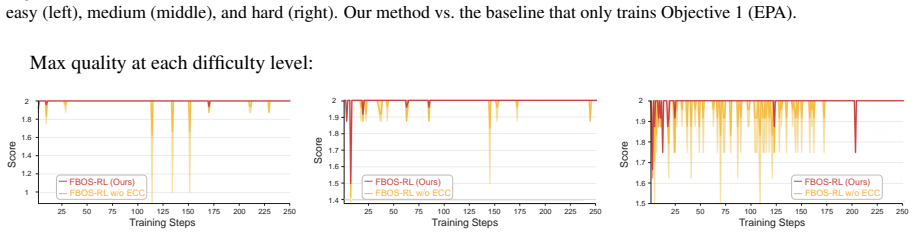








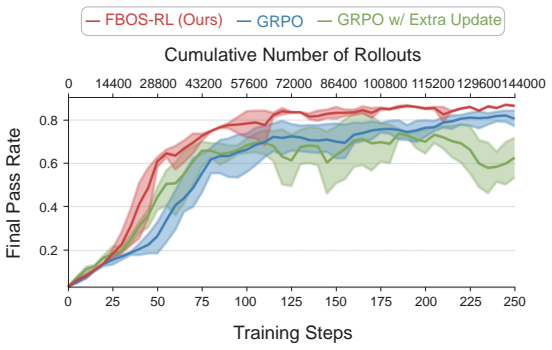
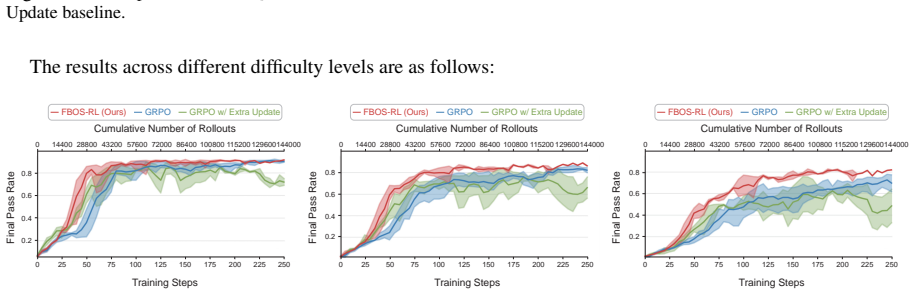
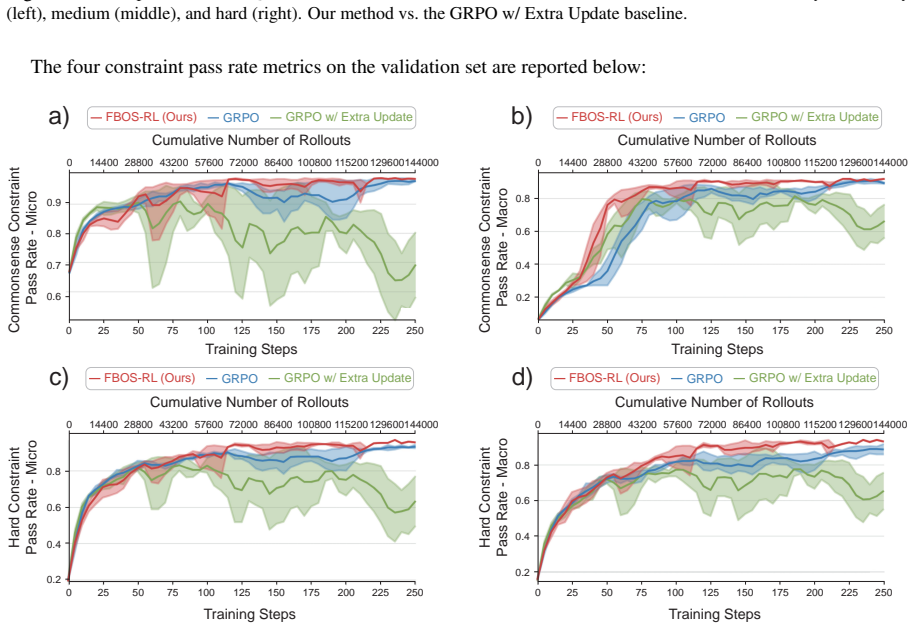











read the original abstract
Reinforcement learning has become a cornerstone for aligning and unlocking the reasoning capabilities of large-scale models. At its core, the training loop of GRPO and its variants alternates between rollout sampling and policy update. Unlike supervised learning, where each gradient step is anchored to an explicit ground-truth target, the optimal gradient direction for updating model parameters in this setting is not known a priori; the high-quality rollouts drawn during the sampling stage therefore act as the implicit "teacher" that guides every parameter update. However, GRPO adopt a simple sampling scheme that conditions all rollouts on the same original prompt. When a task lies beyond the policy model's current capability, this sampling scheme rarely yields a high-quality rollout, leaving the policy model without a meaningful gradient direction when updating its parameters, which causes training to stall. To address this issue, we propose FBOS-RL, a Feedback-Driven Bi-Objective Synergistic reinforcement learning framework. Specifically, we let the model perform Feedback-Guided Exploration Enhancement based on the feedback provided by the environment, and on top of this we design two mutually reinforcing training objectives: Exploitation-oriented Policy Alignment(EPA) and Exploration-oriented Capability Cultivation(ECC). Extensive experiments demonstrate that EPA and ECC can mutually reinforce each other, forming a positive flywheel effect that significantly improves both the training efficiency and the final performance ceiling of reinforcement learning. Specifically, under an identical number of rollouts, FBOS-RL learns substantially faster than GRPO and feedback-based baselines and ultimately attains a higher performance ceiling, while exhibiting higher policy entropy and lower gradient norms throughout training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FBOS-RL, a feedback-driven bi-objective synergistic RL framework for improving training of large models. It augments the GRPO loop with Feedback-Guided Exploration Enhancement that conditions rollout sampling on environment feedback, plus two mutually reinforcing objectives: Exploitation-oriented Policy Alignment (EPA) and Exploration-oriented Capability Cultivation (ECC). The central claim is that EPA and ECC form a positive flywheel, yielding faster learning, higher performance ceilings, higher policy entropy, and lower gradient norms than GRPO and feedback baselines under a fixed rollout budget.
Significance. If the empirical claims hold under rigorous controls, the work offers a concrete mechanism for breaking the 'no high-quality rollout' stall in early RL training of LLMs. The explicit design of mutually reinforcing exploitation and exploration objectives, together with the reported entropy and gradient-norm diagnostics, provides a falsifiable account of the flywheel effect that could influence subsequent sample-efficient RL methods.
major comments (2)
- [§3.2] §3.2 (Feedback-Guided Exploration Enhancement): The premise that environment feedback remains sufficiently informative and unbiased to steer sampling toward useful rollouts even from a weak initial policy is stated without supporting controls. When rewards are sparse or binary, guided sampling reduces to near-random selection among poor trajectories; this directly undermines the claimed positive interaction between EPA and ECC and the resulting flywheel. No ablation varying feedback informativeness or initial policy strength is reported.
- [§4] §4 (Experiments): The abstract and results claim substantially faster learning and higher ceilings under identical rollout counts, yet the manuscript supplies no error bars, statistical tests, or sensitivity analysis to hyper-parameters. Without these, it is impossible to determine whether the reported advantages are robust or sensitive to the very feedback quality that the method assumes.
minor comments (2)
- [§3.3] Notation for the two objectives (EPA, ECC) is introduced without an explicit joint loss equation; a single combined objective formula would clarify how the bi-objective synergy is implemented.
- [Figure 3] Figure captions for training curves should explicitly state the number of random seeds and whether shaded regions represent standard deviation or standard error.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the assumptions underlying FBOS-RL and improve the empirical presentation. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Feedback-Guided Exploration Enhancement): The premise that environment feedback remains sufficiently informative and unbiased to steer sampling toward useful rollouts even from a weak initial policy is stated without supporting controls. When rewards are sparse or binary, guided sampling reduces to near-random selection among poor trajectories; this directly undermines the claimed positive interaction between EPA and ECC and the resulting flywheel. No ablation varying feedback informativeness or initial policy strength is reported.
Authors: We appreciate this observation. The Feedback-Guided Exploration Enhancement relies on environment feedback to bias rollout selection, and our experiments span tasks with varying reward density. However, we acknowledge that explicit controls for feedback quality and initial policy strength would provide stronger validation of the flywheel mechanism. In the revised manuscript we will add ablations that (i) start from weaker initial checkpoints and (ii) inject controlled noise into the feedback signal to simulate reduced informativeness, thereby testing robustness of the EPA-ECC interaction. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract and results claim substantially faster learning and higher ceilings under identical rollout counts, yet the manuscript supplies no error bars, statistical tests, or sensitivity analysis to hyper-parameters. Without these, it is impossible to determine whether the reported advantages are robust or sensitive to the very feedback quality that the method assumes.
Authors: We agree that statistical rigor and sensitivity analysis are necessary to substantiate the claims. The current results are reported from single runs without error bars or formal tests. In the revision we will rerun the main experiments with multiple random seeds, report mean and standard deviation, include statistical significance tests between FBOS-RL and baselines, and add sensitivity plots for the EPA/ECC weighting coefficient and feedback guidance strength. These additions will directly address concerns about robustness to feedback quality. revision: yes
Circularity Check
No circularity detected in derivation or claims
full rationale
The paper introduces FBOS-RL by describing a Feedback-Guided Exploration Enhancement step followed by two new objectives (EPA and ECC) whose mutual reinforcement is asserted and then validated through experimental comparisons against GRPO and feedback baselines. No equations, parameter-fitting procedures, or self-citations are shown that would make any claimed prediction or result equivalent to its own inputs by construction. The central performance claims rest on rollout counts, entropy, and gradient-norm measurements rather than on any self-definitional loop or renamed fitted quantity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Environment feedback is reliable enough to guide exploration when the policy is weak.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
FBOS-RL performs Feedback-Guided Exploration Enhancement … two mutually reinforcing training objectives: Exploitation-oriented Policy Alignment (EPA) and Exploration-oriented Capability Cultivation (ECC) … positive bootstrapping flywheel
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Minif2f: a cross-system benchmark for formal olympiad-level mathemat- ics,
K. Zheng, J. M. Han, and S. Polu, “Minif2f: a cross-system benchmark for formal olympiad-level mathemat- ics,” inInternational Conference on Learning Representations (ICLR), 2022
work page 2022
-
[2]
Travelplanner: A benchmark for real-world planning with language agents
J. Xie, K. Zhang, J. Chen, T. Zhu, R. Lou, Y . Tian, Y . Xiao, and Y . Su, “Travelplanner: A benchmark for real-world planning with language agents,”arXiv preprint arXiv:2402.01622, 2024
-
[3]
Learning to Reason under Off-Policy Guidance
J. Yan, Y . Li, Z. Hu, Z. Wang, G. Cui, X. Qu, Y . Cheng, and Y . Zhang, “Learning to reason under off-policy guidance,”arXiv preprint arXiv:2504.14945, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wuet al., “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,”arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[6]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Rayet al., “Training language models to follow instructions with human feedback,” inAdvances in Neural Information Processing Systems, vol. 35, 2022, pp. 27 730–27 744
work page 2022
-
[7]
Constitutional AI: Harmlessness from AI Feedback
Y . Bai, S. Kadavath, S. Kundu, A. Askell, J. Kernion, A. Jones, A. Chen, A. Goldie, A. Mirhoseini, C. McKinnonet al., “Constitutional ai: Harmlessness from ai feedback,”arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,” inAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[9]
Self-refine: Iterative refinement with self-feedback,
A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y . Yanget al., “Self-refine: Iterative refinement with self-feedback,” inAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[10]
Reflexion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal reinforcement learning,” inAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[11]
Training language models to self-correct via reinforcement learning,
A. Kumar, V . Zhuang, R. Agarwal, Y . Su, J. D. Co-Reyes, A. Singh, K. Baumli, S. Iqbal, C. Bishop, R. Roelofset al., “Training language models to self-correct via reinforcement learning,” 2024
work page 2024
-
[12]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Q. Yu, Z. Zhang, R. Zhu, Y . Yuan, X. Zuo, Y . Yue, T. Fan, G. Liu, L. Liu, X. Liuet al., “Dapo: An open-source llm reinforcement learning system at scale,”arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
H. Lightman, V . Kosaraju, Y . Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe, “Let’s verify step by step,”arXiv preprint arXiv:2305.20050, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Large Language Models Cannot Self-Correct Reasoning Yet
J. Huang, X. Chen, S. Mishra, H. S. Zheng, A. W. Yu, X. Song, and D. Zhou, “Large language models cannot self-correct reasoning yet,”arXiv preprint arXiv:2310.01798, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Biet al., “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Math-shepherd: Verify and rein- force llms step-by-step without human annotations,
P. Wang, L. Li, Z. Shao, R. Xu, D. Dai, Y . Li, D. Chen, Y . Wu, and Z. Sui, “Math-shepherd: Verify and rein- force llms step-by-step without human annotations,”Annual Meeting of the Association for Computational Linguistics (ACL), 2024
work page 2024
-
[17]
Critic: Large language models can self-correct with tool-interactive critiquing,
Z. Gou, Z. Shao, Y . Gong, Y . Shen, Y . Yang, N. Duan, and W. Chen, “Critic: Large language models can self-correct with tool-interactive critiquing,” inInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[18]
Generating sequences by learning to self-correct,
S. Welleck, X. Lu, P. West, F. Brahman, T. Shen, D. Khashabi, and Y . Choi, “Generating sequences by learning to self-correct,” inInternational Conference on Learning Representations (ICLR), 2023. 23
work page 2023
-
[19]
Self-critiquing models for assisting human evaluators
W. Saunders, C. Yeh, J. Wu, S. Bills, L. Ouyang, J. Ward, and J. Leike, “Self-critiquing models for assisting human evaluators,”arXiv preprint arXiv:2206.05802, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Self-rewarding language models,
W. Yuan, R. Y . Pang, K. Cho, S. Sukhbaatar, J. Xu, and J. Weston, “Self-rewarding language models,” International Conference on Machine Learning (ICML), 2024
work page 2024
-
[21]
Rl on incorrect synthetic data scales the efficiency of llm math reasoning by eight-fold,
A. Setlur, S. Garg, X. Geng, N. Garg, V . Smith, and A. Kumar, “Rl on incorrect synthetic data scales the efficiency of llm math reasoning by eight-fold,”Advances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[22]
ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models
M. Liu, S. Diao, X. Lu, J. Hu, X. Dong, Y . Choi, J. Kautz, and Y . Dong, “Prorl: Prolonged reinforcement learning expands reasoning boundaries in large language models,”arXiv preprint arXiv:2505.24864, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Y . Yue, Z. Chen, R. Lu, A. Zhao, Z. Wang, Y . Yue, S. Song, and G. Huang, “Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model?”arXiv preprint arXiv:2504.13837, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
G. Cui, Y . Zhang, J. Chen, L. Yuan, Z. Wang, Y . Zuo, H. Li, Y . Fan, H. Chen, W. Chenet al., “The entropy mechanism of reinforcement learning for reasoning language models,”arXiv preprint arXiv:2505.22617, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
Y . Wang, Q. Yang, Z. Zeng, L. Ren, L. Liu, B. Peng, H. Cheng, X. He, K. Wang, J. Gaoet al., “Reinforcement learning for reasoning in large language models with one training example,”arXiv preprint arXiv:2504.20571, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Self-play fine-tuning converts weak language models to strong language models,
Z. Chen, Y . Deng, H. Yuan, K. Ji, and Q. Gu, “Self-play fine-tuning converts weak language models to strong language models,”International Conference on Machine Learning (ICML), 2024
work page 2024
-
[27]
Beyond grpo: Tree-search enhanced reinforcement learning for reasoning,
T. Zhenget al., “Beyond grpo: Tree-search enhanced reinforcement learning for reasoning,”arXiv preprint arXiv:2502.10717, 2025
-
[28]
Exploration–exploitation trade-off in reinforcement learning for large language models,
Y . Tanget al., “Exploration–exploitation trade-off in reinforcement learning for large language models,” arXiv preprint arXiv:2506.10202, 2025
-
[29]
Recursive introspection: Teaching language model agents how to self-improve,
Y . Qu, T. Zhang, N. Garg, and A. Kumar, “Recursive introspection: Teaching language model agents how to self-improve,”Advances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[30]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
C. Snell, J. Lee, K. Xu, and A. Kumar, “Scaling llm test-time compute optimally can be more effective than scaling model parameters,”arXiv preprint arXiv:2408.03314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Training large language models for reasoning through reverse curriculum reinforcement learning,
Z. Xi, W. Yang, R. Chen, B. Ding, Y . Liu, J. Liu, R. Zheng, W. Zhou, T. Gui, Q. Zhang, and X. Huang, “Training large language models for reasoning through reverse curriculum reinforcement learning,” 2024
work page 2024
-
[32]
Process Reinforcement through Implicit Rewards
G. Cui, L. Yuan, Z. Wang, H. Wang, W. Li, B. He, Y . Fan, T. Yu, Q. Xu, W. Chenet al., “Process reinforcement through implicit rewards,”arXiv preprint arXiv:2502.01456, 2025. 24
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.