Don't Collapse Your Features: Why CenterLoss Hurts OOD Detection and Multi-Scale Mahalanobis Wins
Pith reviewed 2026-05-22 01:28 UTC · model grok-4.3
The pith
CenterLoss degrades out-of-distribution detection by overly tightening feature clusters and distorting covariance, while multi-scale Mahalanobis without it reaches 0.9483 AUROC on CIFAR-10.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
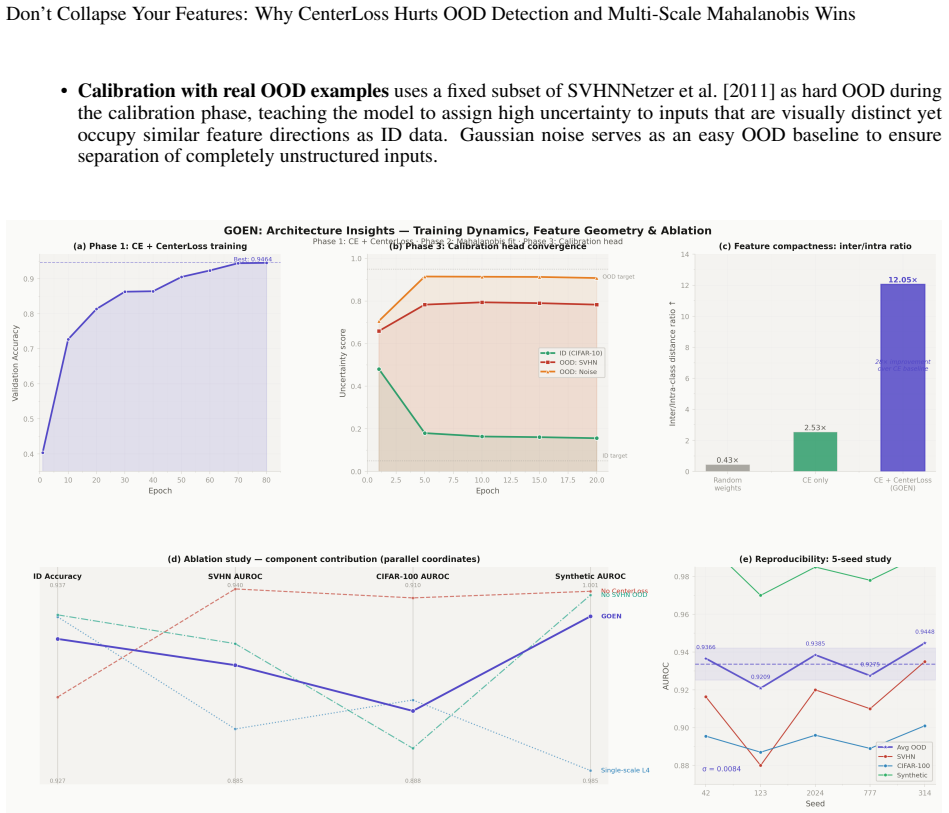
The central claim is that CenterLoss significantly degrades OOD detection performance, reducing average OOD AUROC from 0.9483 to 0.9366 despite improving classification accuracy, because overly tight feature clusters compress inter-class margins and distort the covariance structure needed for effective OOD detection. The best variant, GOEN-NoCenterLoss, achieves an average OOD AUROC of 0.9483, surpassing all baselines including deep ensembles (0.8827), KNN (0.8967), and ODIN (0.8870) on CIFAR-10 benchmarks, while maintaining competitive in-distribution accuracy.
What carries the argument
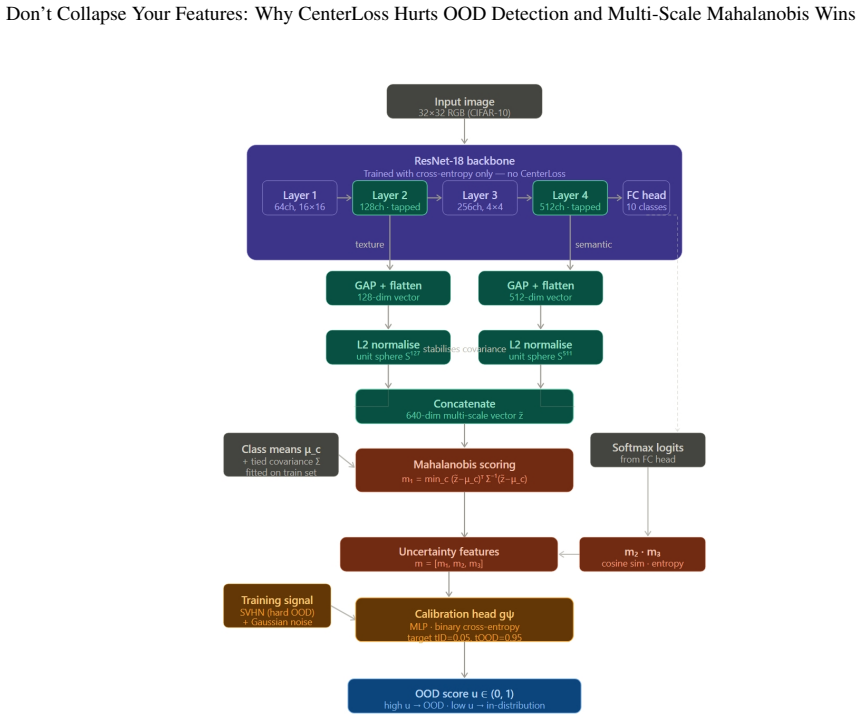
Multi-scale features extracted from a classification network trained without CenterLoss, L2-normalised, and scored by Mahalanobis distance against the estimated in-distribution covariance; this geometry preserves inter-class margins that allow better separation of out-of-distribution inputs.
If this is right
- Training without CenterLoss preserves the covariance structure required for effective Mahalanobis-based OOD scoring while keeping in-distribution accuracy competitive.
- Multi-scale features combined with L2 normalisation and Mahalanobis distance outperform single-scale or non-Mahalanobis baselines on CIFAR-10 OOD benchmarks.
- Adding a calibration head trained on hard out-of-distribution examples further refines detection without requiring full retraining of the backbone.
- The entire pipeline trains in under 20 minutes on one GPU, making it practical for repeated experimentation on uncertainty estimation.
Where Pith is reading between the lines
- Practitioners who need both accurate classification and reliable uncertainty estimates may need to drop or weaken compactness regularisers such as CenterLoss.
- The finding implies that the optimal feature geometry for classification and the optimal geometry for OOD separation are not identical, particularly with respect to cluster tightness.
- Similar trade-offs could be tested on larger-scale vision or language models to check whether the covariance-distortion effect generalises beyond the CIFAR-10 setting.
Load-bearing premise
The covariance structure estimated from in-distribution multi-scale features after L2 normalisation accurately captures the geometry needed to separate in-distribution from out-of-distribution inputs via Mahalanobis distance, and the hard OOD examples chosen for calibration head training are representative of realistic distribution shifts.
What would settle it
Run the same pipeline on a new dataset or architecture and observe whether adding CenterLoss still lowers OOD AUROC while the multi-scale Mahalanobis scores continue to separate in-distribution from out-of-distribution inputs at the reported margin.
Figures
read the original abstract
The ability to detect out-of-distribution (OOD) inputs is fundamental to safe deployment of machine learning systems. Yet, current methods often rely on feature representations that are optimised solely for classification accuracy, neglecting the distinct requirements of epistemic uncertainty. We introduce GOEN (Geometry-Optimised Epistemic Network), a simple pipeline that combines multi-scale features, L2 normalisation, Mahalanobis distance, and a calibration head trained with real hard OOD examples. Through systematic ablation we uncover a counter-intuitive finding: CenterLoss, a popular regulariser for feature compactness, significantly degrades OOD detection performance, reducing average OOD AUROC from 0.9483 to 0.9366 despite improving classification accuracy. The best variant, GOEN-NoCenterLoss, achieves an average OOD AUROC of 0.9483, surpassing all baselines including deep ensembles (0.8827), KNN (0.8967), and ODIN (0.8870) on CIFAR-10 benchmarks, while maintaining competitive in-distribution accuracy. Our results challenge the prevailing assumption that better classification geometry automatically leads to better epistemic uncertainty. Instead, we show that overly tight feature clusters compress inter-class margins and distort the covariance structure needed for effective OOD detection. GOEN is efficient, training in under 20 minutes on a single GPU, and provides a practical blueprint for building AI systems that reliably recognise their own limitations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GOEN, a pipeline combining multi-scale features, L2 normalization, Mahalanobis distance, and a calibration head trained on hard OOD examples for out-of-distribution detection. Through ablations on CIFAR-10, it reports that CenterLoss degrades average OOD AUROC from 0.9483 to 0.9366 (despite improving classification accuracy) by overly compressing inter-class margins and distorting the covariance structure used for Mahalanobis scoring; the best variant (GOEN-NoCenterLoss) outperforms baselines including deep ensembles (0.8827), KNN (0.8967), and ODIN (0.8870).
Significance. If the empirical findings hold under more rigorous validation, the work usefully challenges the assumption that classification-optimized compact features automatically improve epistemic uncertainty estimation. The counter-intuitive CenterLoss result and the practical, efficient GOEN pipeline (under 20 min on one GPU) add to the OOD detection literature by highlighting geometry trade-offs and providing a simple multi-scale Mahalanobis baseline with direct published-method comparisons.
major comments (2)
- [§4] §4 (Ablation studies) and associated tables: The central causal claim—that CenterLoss distorts the covariance matrix and thereby reduces OOD AUROC—rests on the observed performance gap (0.9483 vs 0.9366) but lacks direct supporting measurements. No comparison of covariance properties (condition number, eigenvalue spread, determinant, or inter-class Mahalanobis distances) between the CenterLoss and NoCenterLoss variants is reported, leaving open the possibility that the drop arises from altered training dynamics or calibration-head effects instead.
- [§4] Experimental protocol (throughout §4 and §5): AUROC values are presented without error bars, multiple random seeds, or statistical significance tests. Given that the key delta is only 0.0117, it is unclear whether the reported superiority of GOEN-NoCenterLoss over baselines is robust to data splits or OOD selection choices.
minor comments (2)
- [§3] The description of 'real hard OOD examples' for calibration-head training is referenced in the abstract and §3 but lacks an explicit protocol or dataset details; this should be clarified for reproducibility.
- [§3] Notation for multi-scale feature aggregation and the precise form of the Mahalanobis distance after L2 normalization should be formalized with an equation in §3 to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which identify opportunities to strengthen the empirical support for our claims. We address each major comment below and commit to revisions that enhance the rigor of the analysis without altering the core findings.
read point-by-point responses
-
Referee: [§4] §4 (Ablation studies) and associated tables: The central causal claim—that CenterLoss distorts the covariance matrix and thereby reduces OOD AUROC—rests on the observed performance gap (0.9483 vs 0.9366) but lacks direct supporting measurements. No comparison of covariance properties (condition number, eigenvalue spread, determinant, or inter-class Mahalanobis distances) between the CenterLoss and NoCenterLoss variants is reported, leaving open the possibility that the drop arises from altered training dynamics or calibration-head effects instead.
Authors: We agree that direct measurements of covariance properties would provide stronger causal evidence and help rule out alternative explanations. In the revised manuscript we will add a new subsection in §4 reporting the condition number, eigenvalue spread, determinant, and average inter-class Mahalanobis distances computed on the feature covariances for both the CenterLoss and NoCenterLoss variants. These quantities will be derived from the same trained models used in the existing ablations. revision: yes
-
Referee: [§4] Experimental protocol (throughout §4 and §5): AUROC values are presented without error bars, multiple random seeds, or statistical significance tests. Given that the key delta is only 0.0117, it is unclear whether the reported superiority of GOEN-NoCenterLoss over baselines is robust to data splits or OOD selection choices.
Authors: We acknowledge that the modest delta warrants additional statistical validation. In the revision we will rerun the main experiments and ablations with five independent random seeds, report mean AUROC values together with standard deviations, and include paired t-test p-values for the primary comparisons against baselines. Updated tables in §4 and §5 will reflect these results. revision: yes
Circularity Check
No significant circularity; claims rest on direct empirical measurements
full rationale
The paper's central claims rest on ablation experiments and benchmark comparisons (e.g., OOD AUROC of 0.9483 without CenterLoss vs. 0.9366 with it on CIFAR-10) rather than any mathematical derivation chain. Performance numbers are measured quantities from training and evaluation runs, not outputs of self-referential equations or parameters fitted to the target result. No uniqueness theorems, ansatzes, or self-citations are invoked as load-bearing steps for the geometry or covariance arguments; the pipeline (multi-scale features + L2 norm + Mahalanobis + calibration head) is presented as a practical combination justified by the observed results themselves.
Axiom & Free-Parameter Ledger
free parameters (2)
- multi-scale layer selection
- calibration head weights
axioms (1)
- domain assumption Mahalanobis distance computed on L2-normalized multi-scale features measures epistemic uncertainty for OOD inputs
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
overly tight feature clusters compress inter-class margins and distort the covariance structure needed for effective OOD detection
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CenterLoss ... intra/inter feature ratio (from 2.5 to 7.5)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Learning multiple layers of features from tiny images , author=. 2009 , publisher=
work page 2009
-
[2]
International conference on machine learning , pages=
On calibration of modern neural networks , author=. International conference on machine learning , pages=. 2017 , organization=
work page 2017
-
[3]
Advances in neural information processing systems , volume=
Evidential deep learning to quantify classification uncertainty , author=. Advances in neural information processing systems , volume=
-
[4]
Advances in Neural Information Processing Systems , volume=
Epistemic neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
Adaptive mixtures of local experts , author=. Neural computation , volume=. 1991 , publisher=
work page 1991
-
[6]
Advances in neural information processing systems , volume=
Energy-based out-of-distribution detection , author=. Advances in neural information processing systems , volume=
-
[7]
Enhancing the reliability of out-of-distribution image detection in neural networks
Enhancing the reliability of out-of-distribution image detection in neural networks , author=. arXiv preprint arXiv:1706.02690 , year=
-
[8]
Advances in neural information processing systems , volume=
A simple unified framework for detecting out-of-distribution samples and adversarial attacks , author=. Advances in neural information processing systems , volume=
-
[9]
International conference on machine learning , pages=
Out-of-distribution detection with deep nearest neighbors , author=. International conference on machine learning , pages=. 2022 , organization=
work page 2022
-
[10]
NIPS workshop on deep learning and unsupervised feature learning , volume=
Reading digits in natural images with unsupervised feature learning , author=. NIPS workshop on deep learning and unsupervised feature learning , volume=. 2011 , organization=
work page 2011
-
[11]
Advances in neural information processing systems , volume=
Simple and scalable predictive uncertainty estimation using deep ensembles , author=. Advances in neural information processing systems , volume=
-
[12]
international conference on machine learning , pages=
Dropout as a bayesian approximation: Representing model uncertainty in deep learning , author=. international conference on machine learning , pages=. 2016 , organization=
work page 2016
-
[13]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[14]
arXiv preprint arXiv:2503.07137 , year=
A comprehensive survey of mixture-of-experts: Algorithms, theory, and applications , author=. arXiv preprint arXiv:2503.07137 , year=
-
[15]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Controllable-LPMoE: Adapting to Challenging Object Segmentation via Dynamic Local Priors from Mixture-of-Experts , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[16]
IEEE INFOCOM 2025-IEEE Conference on Computer Communications , pages=
Theory of mixture-of-experts for mobile edge computing , author=. IEEE INFOCOM 2025-IEEE Conference on Computer Communications , pages=. 2025 , organization=
work page 2025
-
[17]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Same: Learning generic language-guided visual navigation with state-adaptive mixture of experts , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[18]
Multimedia Tools and Applications , volume=
A systematic literature review of visual feature learning: deep learning techniques, applications, challenges and future directions , author=. Multimedia Tools and Applications , volume=. 2025 , publisher=
work page 2025
-
[19]
NeXtBrain: Combining local and global feature learning for brain tumor classification , author=. Brain Research , volume=. 2025 , publisher=
work page 2025
-
[20]
Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency , pages=
How misclassification severity and timing influence user trust in AI image classification: User perceptions of high-and low-stakes contexts , author=. Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency , pages=
work page 2025
-
[21]
Out-of-distribution (OOD) detection based on deep learning: A review , author=. Electronics , volume=. 2022 , publisher=
work page 2022
-
[22]
Information and Software Technology , volume=
Performance analysis of out-of-distribution detection on trained neural networks , author=. Information and Software Technology , volume=. 2021 , publisher=
work page 2021
-
[23]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
The many faces of robustness: A critical analysis of out-of-distribution generalization , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[24]
arXiv preprint arXiv:2003.09711 , year=
Robust out-of-distribution detection for neural networks , author=. arXiv preprint arXiv:2003.09711 , year=
-
[25]
Proceedings of the AAAI conference on artificial intelligence , volume=
Self-supervised learning for generalizable out-of-distribution detection , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[26]
Multi-class data description for out-of-distribution detection , author=. Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages=
-
[27]
Neural network-based uncertainty quantification: A survey of methodologies and applications , author=. IEEE access , volume=. 2018 , publisher=
work page 2018
-
[28]
arXiv preprint arXiv:1912.01530 , year=
On the validity of Bayesian neural networks for uncertainty estimation , author=. arXiv preprint arXiv:1912.01530 , year=
-
[29]
ACM Computing Surveys , volume=
A survey on uncertainty quantification methods for deep learning , author=. ACM Computing Surveys , volume=. 2026 , publisher=
work page 2026
-
[30]
Nuclear Science and Engineering , volume=
Quantification of deep neural network prediction uncertainties for VVUQ of machine learning models , author=. Nuclear Science and Engineering , volume=. 2023 , publisher=
work page 2023
-
[31]
2020 25th International Conference on Pattern Recognition (ICPR) , pages=
Separation of aleatoric and epistemic uncertainty in deterministic deep neural networks , author=. 2020 25th International Conference on Pattern Recognition (ICPR) , pages=. 2021 , organization=
work page 2020
-
[32]
Advances in neural information processing systems , volume=
On mixup training: Improved calibration and predictive uncertainty for deep neural networks , author=. Advances in neural information processing systems , volume=
-
[33]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Continual Out-of-Distribution Detection with Analytic Neural Collapse , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[34]
Advances in Neural Information Processing Systems , volume=
Neural collapse inspired feature alignment for out-of-distribution generalization , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Detecting out-of-distribution through the lens of neural collapse , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[36]
Advances in Neural Information Processing Systems , volume=
Learning to shape in-distribution feature space for out-of-distribution detection , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
arXiv preprint arXiv:2209.08378 , year=
Linking neural collapse and l2 normalization with improved out-of-distribution detection in deep neural networks , author=. arXiv preprint arXiv:2209.08378 , year=
-
[38]
A comprehensive study of calibration and uncertainty quantification for Bayesian convolutional neural networks—An application to seismic data , author=. Geophysics , volume=. 2022 , publisher=
work page 2022
-
[39]
Advances in neural information processing systems , volume=
On mixup training: Improved calibration and predictive uncertainty for deep neural networks , author=. Advances in neural information processing systems , volume=. 2023 , organization=
work page 2023
-
[40]
Neural Computing and Applications , volume=
Adaptive temperature scaling for robust calibration of deep neural networks , author=. Neural Computing and Applications , volume=. 2024 , publisher=
work page 2024
-
[41]
Advances in Neural Information Processing Systems , volume=
Self-calibrating conformal prediction , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.