Reading Calibrated Uncertainty from Language Model Trajectories
Pith reviewed 2026-05-25 05:42 UTC · model grok-4.3
The pith
Eleven geometric features from language model layer trajectories let a linear probe read uncertainty better than maximum softmax probability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
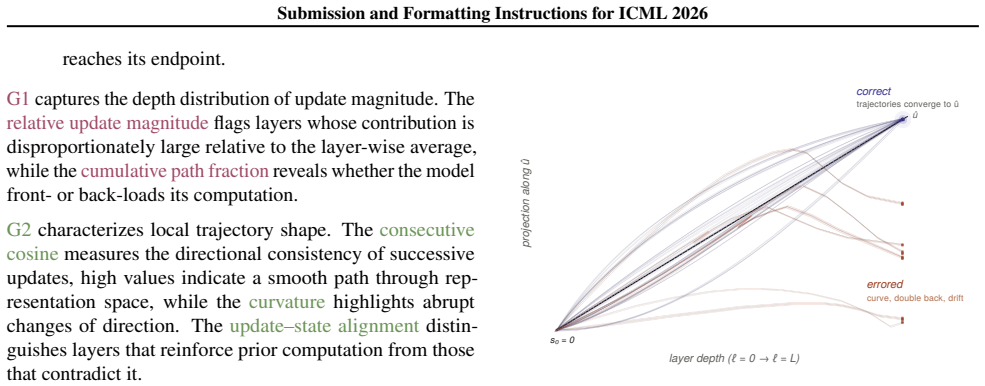
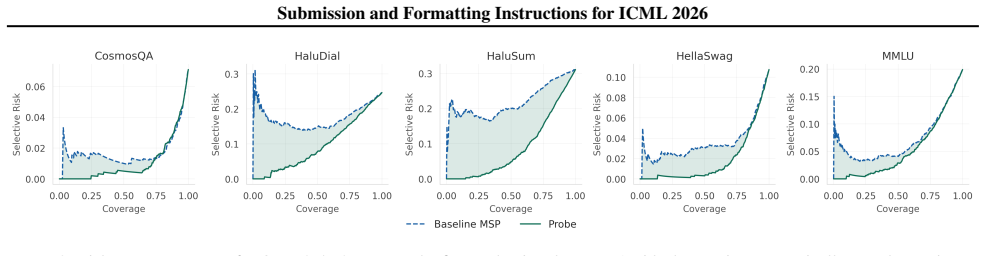
By tracing the path of per-layer MLP updates with eleven scale-invariant geometric features and feeding them to a sparse linear probe, uncertainty estimates can be obtained that outperform those from the maximum softmax probability under selective abstention, improving by up to 21 AURC points, and the probe coefficients indicate the depth at which errors take shape.
What carries the argument
Eleven scale-invariant geometric features extracted from the cumulative paths of per-layer MLP updates, used as input to a sparse linear probe for uncertainty estimation.
If this is right
- The probe coefficients identify specific layers where the model commits prematurely or produces contradictions.
- Improvements are largest precisely when the maximum softmax probability is most miscalibrated.
- The same trajectory features apply across different models and structured output formats.
- Uncertainty quantification can shift from endpoint probabilities to the full internal path.
Where Pith is reading between the lines
- Trajectory features could be extracted from attention or other layer types to capture additional signals.
- The approach might support interventions that adjust representations at the layers where drift is detected.
- If the geometric features prove highly predictive, they could reduce reliance on learned probes in favor of direct calculations.
- Similar path analysis could extend to non-language sequence models that use layered updates.
Load-bearing premise
The eleven geometric features from per-layer MLP update paths contain information about prediction correctness beyond what the final maximum softmax probability already captures, and this relationship holds across models and output structures.
What would settle it
If the probe shows no improvement over MSP or if gains fail to scale with baseline miscalibration on new models and tasks, the central claim would not hold.
Figures





read the original abstract
The maximum softmax probability (MSP) represents a default approach when evaluating uncertainty quantification for language model generation with structured output. Although cheap, it is often miscalibrated. Methods that probe the model's internal activations feed raw hidden states into opaque classifiers, reading activations as static snapshots and leaving implicit the layer-wise trajectory by which a representation is formed. Yet, similar endpoints can arise from very different paths, and how evidence accumulates, reinforces, or reverses across depth might reveal uncertainty that final probabilities obscure. We extract eleven scale-invariant geometric features, tracing the cumulative path of per-layer MLP updates, and feed them to a sparse linear probe. The probe outperforms MSP under selective abstention, with gains scaling with baseline miscalibration up to 21 AURC points. Because every feature has a closed-form geometric meaning, the probe's coefficients trace how and where along depth errors take shape -- which layers commit prematurely, which contradict the running state, where trajectories drift away from their endpoint.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that eleven scale-invariant geometric features extracted from per-layer MLP update trajectories in language models can be fed to a sparse linear probe to yield better uncertainty estimates than the maximum softmax probability (MSP). The probe improves selective abstention performance (AURC gains up to 21 points, scaling with baseline miscalibration), and the closed-form geometric meaning of the features permits interpretation of probe coefficients to locate where along depth errors form.
Significance. If the reported gains and orthogonality to MSP hold under the stated conditions, the work supplies an interpretable, low-cost-at-inference alternative to opaque activation probes for LLM uncertainty. The emphasis on scale-invariant, geometrically defined features and the explicit tracing of error accumulation across layers constitute a clear methodological contribution that could be tested on additional model families and output structures.
minor comments (2)
- Abstract: the acronym AURC is introduced without expansion or reference; a parenthetical definition or citation on first use would improve accessibility for readers outside selective-abstention literature.
- Abstract: the phrase 'structured output' is used without enumerating the concrete tasks or output formats (e.g., classification, generation with constrained decoding) on which the eleven features were evaluated.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation for minor revision. The referee summary accurately reflects the manuscript's claims and contributions on scale-invariant geometric features from per-layer MLP trajectories for uncertainty quantification.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper extracts eleven scale-invariant geometric features from per-layer MLP update trajectories and trains a sparse linear probe on them to improve uncertainty quantification over MSP. This is a standard supervised empirical pipeline: features are computed from model internals, the probe is fit on labeled data, and performance is measured via AURC on selective abstention. No equation or claim reduces the reported gains to a quantity defined by the same inputs (no self-definitional loop, no fitted parameter renamed as prediction). The geometric features have explicit closed-form meanings independent of the probe coefficients. No load-bearing self-citation, uniqueness theorem, or ansatz smuggling is present in the provided text. The method is self-contained once the probe is trained; orthogonality to MSP is an empirical claim, not a definitional one.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Scale-invariant geometric features extracted from per-layer MLP update trajectories capture uncertainty relevant to correctness that is not present in the final MSP.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We extract eleven scale-invariant geometric features, tracing the cumulative path of per-layer MLP updates... Relative update magnitude ∥m_ℓ∥/n̄, Cumulative path fraction, Consecutive cosine, Curvature, Update–state alignment, Direction to final, Update to final, Cumulative coherence ∥s_ℓ∥/∑∥m_k∥
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The probe outperforms MSP under selective abstention, with gains scaling with baseline miscalibration up to 21 AURC points.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Deepseek llm: Scaling open-source language models with longtermism , author=. arXiv preprint arXiv:2401.02954 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Yi: Open Foundation Models by 01.AI
Yi: Open foundation models by 01. ai , author=. arXiv preprint arXiv:2403.04652 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Advances in Neural Information Processing Systems , volume=
Benchmarking llms via uncertainty quantification , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[8]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
work page 2023
-
[9]
International conference on machine learning , pages=
On calibration of modern neural networks , author=. International conference on machine learning , pages=. 2017 , organization=
work page 2017
-
[10]
Proceedings of the AAAI conference on artificial intelligence , volume=
Obtaining well calibrated probabilities using bayesian binning , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[11]
arXiv preprint arXiv:2305.19187 , year=
Generating with confidence: Uncertainty quantification for black-box large language models , author=. arXiv preprint arXiv:2305.19187 , year=
-
[12]
arXiv preprint arXiv:2305.18404 , year=
Conformal prediction with large language models for multi-choice question answering , author=. arXiv preprint arXiv:2305.18404 , year=
-
[13]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Uncertainty quantification and confidence calibration in large language models: A survey , author=. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2 , pages=
-
[14]
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation , author=. arXiv preprint arXiv:2302.09664 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Transactions of the Association for Computational Linguistics , volume=
Benchmarking uncertainty quantification methods for large language models with lm-polygraph , author=. Transactions of the Association for Computational Linguistics , volume=
-
[16]
Language models as knowledge bases? , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
work page 2019
-
[17]
Understanding intermediate layers using linear classifier probes
Understanding intermediate layers using linear classifier probes , author=. arXiv preprint arXiv:1610.01644 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Findings of the association for computational linguistics: EMNLP 2024 , pages=
Internalinspector i2: Robust confidence estimation in llms through internal states , author=. Findings of the association for computational linguistics: EMNLP 2024 , pages=
work page 2024
-
[19]
Semantic Entropy Probes: Robust and Cheap Hallucination Detection in LLMs
Semantic entropy probes: Robust and cheap hallucination detection in llms , author=. arXiv preprint arXiv:2406.15927 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
The geometry of truth: Emergent linear structure in large language model representations of true/false datasets , author=. arXiv preprint arXiv:2310.06824 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
arXiv preprint arXiv:2506.08572 , year=
The Geometries of Truth Are Orthogonal Across Tasks , author=. arXiv preprint arXiv:2506.08572 , year=
-
[22]
Advances in Neural Information Processing Systems , volume=
Inference-time intervention: Eliciting truthful answers from a language model , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Active learning principles for in-context learning with large language models , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
work page 2023
-
[24]
A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks
A baseline for detecting misclassified and out-of-distribution examples in neural networks , author=. arXiv preprint arXiv:1610.02136 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Transformer feed-forward layers are key-value memories , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2021
-
[26]
Advances in neural information processing systems , volume=
Locating and editing factual associations in gpt , author=. Advances in neural information processing systems , volume=
-
[27]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Mechanistic understanding and mitigation of language model non-factual hallucinations , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
work page 2024
-
[28]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Semantic volume: Quantifying and detecting both external and internal uncertainty in llms , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[29]
Discovering Latent Knowledge in Language Models Without Supervision
Discovering latent knowledge in language models without supervision , author=. arXiv preprint arXiv:2212.03827 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops , pages=
Revisiting the evaluation of uncertainty estimation and its application to explore model complexity-uncertainty trade-off , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops , pages=
-
[31]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Regularization and variable selection via the elastic net , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2005 , publisher=
work page 2005
-
[32]
International Conference on Learning Representations , year=
Bias-Reduced Uncertainty Estimation for Deep Neural Classifiers , author=. International Conference on Learning Representations , year=
-
[33]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
The internal state of an LLM knows when it’s lying , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
work page 2023
-
[34]
arXiv preprint arXiv:2404.15993 , year=
Uncertainty estimation and quantification for llms: A simple supervised approach , author=. arXiv preprint arXiv:2404.15993 , year=
-
[35]
Advances in neural information processing systems , volume=
What uncertainties do we need in bayesian deep learning for computer vision? , author=. Advances in neural information processing systems , volume=
-
[36]
Language Models (Mostly) Know What They Know
Language models (mostly) know what they know , author=. arXiv preprint arXiv:2207.05221 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Detecting hallucinations in large language models using semantic entropy , author=. Nature , volume=. 2024 , publisher=
work page 2024
-
[38]
arXiv preprint arXiv:2510.04108 , year=
Can Linear Probes Measure LLM Uncertainty? , author=. arXiv preprint arXiv:2510.04108 , year=
-
[39]
Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =
Geifman, Yonatan and El-Yaniv, Ran , title =. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =. 2017 , isbn =
work page 2017
-
[40]
IEEE Transactions on information theory , volume=
On optimum recognition error and reject tradeoff , author=. IEEE Transactions on information theory , volume=. 1970 , publisher=
work page 1970
-
[41]
Cosmos QA: Machine reading comprehension with contextual commonsense reasoning , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
work page 2019
-
[42]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
Hellaswag: Can a machine really finish your sentence? , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[43]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Halueval: A large-scale hallucination evaluation benchmark for large language models , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
work page 2023
-
[44]
Bias-Reduced Uncertainty Estimation for Deep Neural Classifiers
Bias-reduced uncertainty estimation for deep neural classifiers , author=. arXiv preprint arXiv:1805.08206 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.