OnePred: Next-Query Prediction via Recursive Intent Memory in Multi-Turn Conversations
Pith reviewed 2026-05-25 04:13 UTC · model grok-4.3
The pith
OnePred predicts the next user query using only a recursively updated intent memory instead of the full conversation history.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
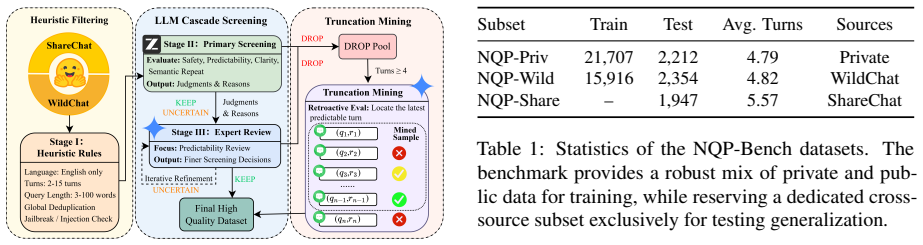
Accurate next-query prediction does not require re-reading raw dialogue history; it suffices to track the user's evolving intent trajectory across topics, unresolved needs, and interest shifts by maintaining a recursively updated memory as the sole cross-turn context. The memory is shaped into a prediction-oriented intent chain through a two-stage reinforcement learning pipeline that first teaches what to predict and then what to compress. This bounds per-turn token consumption independently of conversation length and improves prediction quality over full-history and truncated baselines on the introduced NQP-Bench.
What carries the argument
Recursive Intent Memory: a compressed, recursively updated representation of the user's intent trajectory that serves as the only cross-turn context for prediction.
If this is right
- Per-turn token consumption remains bounded regardless of how many turns the conversation reaches.
- Prediction quality improves over full-history inputs especially as conversation length grows.
- The two-stage RL process produces a memory that functions as a standalone intent chain for downstream prediction.
- Proactive interaction becomes feasible in production systems without linear compute scaling.
Where Pith is reading between the lines
- The same recursive memory could support other proactive tasks such as suggesting follow-up actions or detecting intent shifts in real time.
- Deploying this approach might lower latency in live chat systems by eliminating the need to re-process growing histories on each turn.
- The method could transfer to non-conversational multi-turn settings like sequential decision making where only a compact state summary is retained.
Load-bearing premise
Accurate next-query prediction does not require re-reading raw history and can instead rely solely on a recursively updated memory that tracks the user's evolving intent trajectory across topics, unresolved needs, and interest shifts.
What would settle it
A direct comparison on conversations longer than those in NQP-Bench where the memory-based model shows lower next-query accuracy than a full-history baseline despite using far fewer tokens.
Figures







read the original abstract
Although large language model (LLM) conversational systems process millions of multi-turn dialogues daily, they remain fundamentally reactive: they respond only after the user types a query. A key step toward proactive interaction is next-query prediction, which anticipates the user's subsequent query based solely on the preceding dialogue. Progress on this task is hindered by the lack of dedicated benchmarks and a fundamental efficiency--quality trade-off: naively concatenating full dialogue history incurs linearly growing token consumption, while truncating to the latest turn discards crucial cross-turn context. Our key insight is that accurate prediction does not require re-reading raw history; it suffices to track the user's evolving intent trajectory across topics, unresolved needs, and interest shifts. We propose OnePred, which maintains a recursively updated memory as its sole cross-turn context, bounding the per-turn cost independently of conversation length. We train the model via a two-stage reinforcement learning pipeline that first teaches what to predict, then what to compress, shaping the memory into a prediction-oriented intent chain. To establish a rigorous testbed, we introduce NQP-Bench, spanning three diverse subsets. Experiments demonstrate that OnePred reduces per-turn token consumption by up to 22$\times$ compared to full-history inputs while consistently exceeding all baselines in prediction quality, with larger gains on longer conversations. Our code is publicly available at https://github.com/ZBWpro/OnePred.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes OnePred for next-query prediction in multi-turn LLM conversations. It maintains a recursively updated intent memory as the sole cross-turn context to track evolving user intent, topics, unresolved needs, and shifts. A two-stage RL pipeline first teaches prediction then compression. The work introduces NQP-Bench with three subsets and reports up to 22× per-turn token reduction versus full-history baselines while exceeding all baselines in prediction quality, with gains increasing on longer conversations. Code is released publicly.
Significance. If the empirical claims hold, the bounded recursive memory approach would address a core efficiency-quality trade-off in conversational systems, enabling proactive next-query prediction without linear token growth. Public code and the new benchmark are positive contributions that could support follow-on work.
minor comments (3)
- The abstract states performance gains and a 22× token reduction but provides no experimental details, baseline descriptions, statistical significance, or verification of the recursive update mechanism; the full manuscript should include these in the experiments section to allow verification.
- Clarify the exact form of the recursive update rule and how the two-stage RL shapes the memory into a 'prediction-oriented intent chain' (mentioned in abstract); a concrete pseudocode or equation would improve reproducibility.
- The NQP-Bench description is high-level; add dataset statistics, construction details, and evaluation metrics in a dedicated section or table.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work on OnePred and the recommendation for minor revision. No specific major comments appear in the provided report, so we have no individual points to address.
Circularity Check
No significant circularity detected
full rationale
The abstract and described method present a self-contained experimental claim: a bounded recursive memory is proposed and trained via a two-stage RL pipeline to enable next-query prediction, with quality gains measured against full-history and truncated baselines on the introduced NQP-Bench. No equations, derivations, or load-bearing steps are visible that reduce by construction to fitted parameters, self-definitions, or self-citation chains. The key assumption is explicitly positioned as the hypothesis under test rather than presupposed, and results are reported as external validation. This is the normal case of an independent empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
WildChat: 1M ChatGPT Interaction Logs in the Wild , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[2]
ShareGPT: Share your wildest ChatGPT conversations with one click , author=. 2023 , url=
work page 2023
-
[3]
ShareChat: A Dataset of Chatbot Conversations in the Wild
ShareChat: A Dataset of Chatbot Conversations in the Wild , author=. arXiv preprint arXiv:2512.17843 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[5]
Learning to Attend, Copy, and Generate for Session-Based Query Suggestion , author=. Proceedings of the ACM International Conference on Information and Knowledge Management (CIKM) , year=
-
[6]
Context Attentive Document Ranking and Query Suggestion , author=. Proceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval , year=
-
[7]
Proceedings of the Annual SIGdial Meeting on Discourse and Dialogue , year=
The Ubuntu Dialogue Corpus , author=. Proceedings of the Annual SIGdial Meeting on Discourse and Dialogue , year=
-
[8]
Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL) , year=
Sequential Matching Network: A New Architecture for Multi-turn Response Selection in Retrieval-Based Chatbots , author=. Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL) , year=
-
[10]
VERL: An Extensible Framework for Post-Training of Large Language Models , author=. arXiv preprint , year=
- [11]
-
[12]
International conference on extending database technology , pages=
Query recommendation using query logs in search engines , author=. International conference on extending database technology , pages=. 2004 , organization=
work page 2004
-
[13]
Context-aware query suggestion by mining click-through and session data , author=. Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining , pages=
-
[14]
A hierarchical recurrent encoder-decoder for generative context-aware query suggestion , author=. proceedings of the 24th ACM international on conference on information and knowledge management , pages=
-
[15]
Proceedings of the web conference 2020 , pages=
Leading conversational search by suggesting useful questions , author=. Proceedings of the web conference 2020 , pages=
work page 2020
-
[16]
CTR-guided generative query suggestion in conversational search , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
work page 2025
-
[17]
Proceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
From clicks to preference: A multi-stage alignment framework for generative query suggestion in conversational system , author=. Proceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1 , pages=
-
[18]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Onesug: The unified end-to-end generative framework for e-commerce query suggestion , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[19]
arXiv preprint arXiv:2601.09713 , year=
LLM-Driven Preference Data Synthesis for Proactive Prediction of the Next User Utterance in Human-Machine Dialogue , author=. arXiv preprint arXiv:2601.09713 , year=
-
[20]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages=
Proactive human-machine conversation with explicit conversation goal , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages=
-
[21]
arXiv preprint arXiv:2305.02750 , year=
A survey on proactive dialogue systems: Problems, methods, and prospects , author=. arXiv preprint arXiv:2305.02750 , year=
-
[22]
Proceedings of the 29th Conference on Computational Natural Language Learning , pages=
Interpersonal memory matters: A new task for proactive dialogue utilizing conversational history , author=. Proceedings of the 29th Conference on Computational Natural Language Learning , pages=
-
[23]
Transactions of the association for computational linguistics , volume=
Lost in the middle: How language models use long contexts , author=. Transactions of the association for computational linguistics , volume=
-
[24]
Advances in Neural Information Processing Systems , volume=
Augmenting language models with long-term memory , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
Memagent: Reshaping long-context llm with multi-conv rl-based memory agent, 2025 , author=. URL https://arxiv. org/abs/2507 , volume=
work page 2025
-
[26]
MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents
Mem1: Learning to synergize memory and reasoning for efficient long-horizon agents , author=. arXiv preprint arXiv:2506.15841 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
arXiv preprint arXiv:2603.04946 , year=
LocalSUG: Geography-Aware LLM for Query Suggestion in Local-Life Services , author=. arXiv preprint arXiv:2603.04946 , year=
- [30]
-
[31]
GLM-5: from Vibe Coding to Agentic Engineering
Glm-5: from vibe coding to agentic engineering , author=. arXiv preprint arXiv:2602.15763 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
ACM Transactions on Information Systems , volume=
Proactive conversational ai: A comprehensive survey of advancements and opportunities , author=. ACM Transactions on Information Systems , volume=. 2025 , publisher=
work page 2025
- [33]
- [34]
- [35]
-
[36]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.