Reason--Imagine--Act: Closed-Loop LLM Decision Making with World Models for Autonomous Driving
Pith reviewed 2026-06-30 18:44 UTC · model grok-4.3
The pith
RIA couples an LLM reasoner to an action-conditioned world model so that short-horizon rollouts verify safety before each driving action is executed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
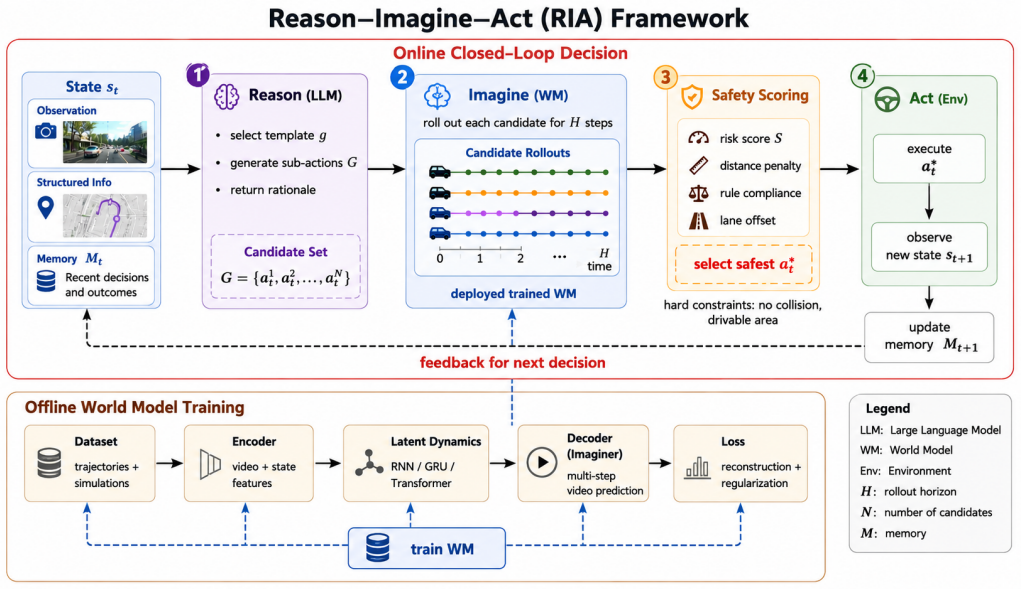
RIA performs closed-loop decision making by having the LLM propose an action template and candidate sub-actions, the world model run short-horizon rollouts to forecast outcomes, and a safety scorer select the safest executable action with feedback returned to the next reasoning step; under a unified CARLA point-goal protocol of 1000 episodes this produces 80.05 percent route completion, 51.10 percent arrival rate, and 0.20 percent collision rate while outperforming CARLA TM and MADA on the same closed-loop interface.
What carries the argument
The Reason-Imagine-Act cycle in which LLM proposals are verified by world-model rollouts and a safety scorer before execution.
If this is right
- Actions are filtered at decision time by explicit physical-outcome predictions rather than by language heuristics alone.
- Safety feedback from each rollout is available to refine the LLM's next proposal within the same episode.
- The same interface lets RIA surpass training-free baselines on route completion and collision metrics without additional training.
- Short-horizon rollouts suffice to reduce collisions to 0.20 percent under the tested point-goal protocol.
Where Pith is reading between the lines
- The same propose-rollout-score loop could be applied to other embodied agents that must reconcile semantic goals with continuous dynamics.
- Performance gains depend on the world model remaining accurate enough over the chosen rollout length; longer horizons would require stronger predictive models.
- Real-vehicle transfer would first need the world model to be updated from onboard sensor streams rather than simulator data.
Load-bearing premise
The world model must correctly predict the physical results of proposed actions over short time horizons so that its safety scores match real outcomes.
What would settle it
Run the same 1000-episode CARLA protocol after replacing the learned world model with a version whose predictions deviate measurably from actual vehicle dynamics; if the collision rate then rises above 0.20 percent while route completion falls, the claim that online rollouts provide reliable safety verification is falsified.
Figures

read the original abstract
Large language models (LLMs) are promising for autonomous driving, but semantics-only decision policies can yield physically unsafe behavior in dynamic traffic. Existing methods either perform online language reasoning without explicit dynamics verification or use world models mainly in offline pipelines, leaving a gap between semantic intent and physical feasibility at decision time. We propose Reason--Imagine--Act (RIA), a closed-loop framework that couples an LLM reasoner with an action-conditioned world model for online safety verification. At each step, the LLM proposes an action template and candidate sub-actions, the world model performs short-horizon rollouts, and a safety scorer selects the safest executable action with feedback to the next reasoning step. Under a unified CARLA point-goal protocol (1000 episodes), RIA achieves 80.05% route completion, 51.10% arrival rate, and 0.20% collision rate. Under the same closed-loop interface, RIA consistently outperforms training-free baselines, including CARLA TM and MADA, on core closed-loop metrics. For reproducibility, code is available at https://github.com/pku-smart-city/source_code/tree/main/RIA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Reason--Imagine--Act (RIA), a closed-loop framework coupling an LLM reasoner with an action-conditioned world model for online safety verification in autonomous driving. At each timestep the LLM proposes action templates, the world model runs short-horizon rollouts, and a safety scorer selects the safest action with feedback to the next reasoning step. Under a unified CARLA point-goal protocol (1000 episodes) RIA reports 80.05% route completion, 51.10% arrival rate and 0.20% collision rate, outperforming training-free baselines including CARLA TM and MADA. Open-source code is provided.
Significance. If the world-model component is shown to be reliable, RIA offers a concrete mechanism for grounding LLM semantic decisions in short-term physical feasibility, addressing a recognized gap between language-only policies and dynamics-aware control. The public code release is a clear strength for reproducibility.
major comments (1)
- [Experiments / Results section] The performance gains (especially the 0.20% collision rate) are explicitly attributed to the closed-loop safety verification that relies on short-horizon rollouts from the action-conditioned world model. No section reports a direct quantitative comparison of the world model's predicted trajectories, collision events, or lane violations against CARLA ground-truth transitions over the horizons actually used at decision time (e.g., no prediction-error table or collision-prediction precision/recall). This validation is load-bearing for the central claim that the safety scorer, rather than the LLM templates or evaluation variance, explains the improvement over baselines.
minor comments (1)
- [Method section] The abstract and method description refer to 'a safety scorer' without specifying its exact formulation, thresholds, or weighting of collision vs. progress terms; adding this detail would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The major comment raises an important point about validating the world model, which we address below.
read point-by-point responses
-
Referee: [Experiments / Results section] The performance gains (especially the 0.20% collision rate) are explicitly attributed to the closed-loop safety verification that relies on short-horizon rollouts from the action-conditioned world model. No section reports a direct quantitative comparison of the world model's predicted trajectories, collision events, or lane violations against CARLA ground-truth transitions over the horizons actually used at decision time (e.g., no prediction-error table or collision-prediction precision/recall). This validation is load-bearing for the central claim that the safety scorer, rather than the LLM templates or evaluation variance, explains the improvement over baselines.
Authors: We agree that the manuscript does not currently include a direct quantitative evaluation of the world model's prediction accuracy against CARLA ground truth over the short horizons used at runtime. Such validation would strengthen the attribution of gains specifically to the safety scorer. In the revised manuscript we will add a dedicated subsection (or appendix table) reporting world-model fidelity metrics on held-out CARLA episodes, including position/velocity MSE, collision-event precision/recall, and lane-violation prediction accuracy, computed exactly over the 4-8 step horizons employed by the safety scorer. This addition will be performed without changing the main experimental protocol or results. revision: yes
Circularity Check
No circularity; empirical CARLA evaluation stands on its own
full rationale
The paper describes an LLM-plus-world-model framework (RIA) and reports its performance as the outcome of 1000 closed-loop CARLA episodes against baselines. No equations, fitted parameters, or derivations are presented that reduce to the inputs by construction. No self-citations are invoked to justify uniqueness or load-bearing premises. The reported metrics (route completion, arrival rate, collision rate) are direct simulation outputs rather than renamed fits or self-referential predictions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The CARLA simulator accurately models real-world driving dynamics for the purpose of evaluation.
invented entities (1)
-
RIA framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Large language models for human-like autonomous driving: A survey,
Y . Li, K. Katsumata, E. Javanmardi, and M. Tsukada, “Large language models for human-like autonomous driving: A survey,” in2024 IEEE 27th International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2024, pp. 439–446
2024
-
[2]
Dilu: A knowledge-driven approach to autonomous driving with large language models,
L. Wen, D. Fu, X. Li, X. Cai, T. MA, P. Cai, M. Dou, B. Shi, L. He, and Y . Qiao, “Dilu: A knowledge-driven approach to autonomous driving with large language models,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[3]
Drivevlm: The convergence of autonomous driving and large vision-language models,
X. Tian, J. Gu, B. Li, Y . Liu, Y . Wang, Z. Zhao, K. Zhan, P. Jia, X. Lang, and H. Zhao, “Drivevlm: The convergence of autonomous driving and large vision-language models,” in8th Annual Conference on Robot Learning, 2025
2025
-
[4]
Personalized autonomous driving with large language models: Field experiments,
C. Cui, Z. Yang, Y . Zhou, Y . Ma, J. Lu, L. Li, Y . Chen, J. Panchal, and Z. Wang, “Personalized autonomous driving with large language models: Field experiments,” in2024 IEEE 27th International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2024, pp. 20–27
2024
-
[5]
A LLM-based multimodal warning system for driver assistance,
Z. Xu, T. Chen, and S. Chen, “A LLM-based multimodal warning system for driver assistance,” in2024 IEEE 27th International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2024, pp. 1527–1532
2024
-
[6]
Lmdrive: Closed-loop end-to-end driving with large language models,
H. Shao, Y . Hu, L. Wang, G. Song, S. L. Waslander, Y . Liu, and H. Li, “Lmdrive: Closed-loop end-to-end driving with large language models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 15 120–15 130
2024
-
[7]
Drivegpt4: Interpretable end-to-end autonomous driving via large language model,
Z. Xu, Y . Zhang, E. Xie, Z. Zhao, Y . Guo, K.-Y . K. Wong, Z. Li, and H. Zhao, “Drivegpt4: Interpretable end-to-end autonomous driving via large language model,”IEEE Robotics and Automation Letters, vol. 9, no. 10, pp. 8186–8193, 2024
2024
-
[8]
Drivegpt4-v2: Harnessing large language model capabilities for enhanced closed-loop autonomous driving,
Z. Xu, Y . Bai, Y . Zhang, Z. Li, F. Xia, K.-Y . K. Wong, J. Wang, and H. Zhao, “Drivegpt4-v2: Harnessing large language model capabilities for enhanced closed-loop autonomous driving,” in2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE Computer Society, 2025, pp. 17 261–17 270
2025
-
[9]
Autovla: A vision-language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning,
Z. Zhou, T. Cai, S. Z. Zhao, Y . Zhang, Z. Huang, B. Zhou, and J. Ma, “Autovla: A vision-language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning,” in The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[10]
Solve: Synergy of language-vision and end-to-end networks for autonomous driving,
X. Chen, L. Huang, T. Ma, R. Fang, S. Shi, and H. Li, “Solve: Synergy of language-vision and end-to-end networks for autonomous driving,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 12 068–12 077
2025
-
[11]
Think2drive: Efficient reinforcement learning by thinking with latent world model for autonomous driving (in carla-v2),
Q. Li, X. Jia, S. Wang, and J. Yan, “Think2drive: Efficient reinforcement learning by thinking with latent world model for autonomous driving (in carla-v2),” inEuropean conference on computer vision. Springer, 2024, pp. 142–158
2024
-
[12]
Adawm: Adaptive world model based planning for autonomous driving,
H. Wang, X. Ye, F. Tao, C. Pan, A. Mallik, B. Yaman, L. Ren, and J. Zhang, “Adawm: Adaptive world model based planning for autonomous driving,”arXiv preprint arXiv:2501.13072, 2025
-
[13]
Drivedreamer: Towards real-world-drive world models for autonomous driving,
X. Wang, Z. Zhu, G. Huang, X. Chen, J. Zhu, and J. Lu, “Drivedreamer: Towards real-world-drive world models for autonomous driving,” in European conference on computer vision. Springer, 2024, pp. 55–72
2024
-
[14]
Drivedreamer-2: Llm-enhanced world models for diverse driving video generation,
G. Zhao, X. Wang, Z. Zhu, X. Chen, G. Huang, X. Bao, and X. Wang, “Drivedreamer-2: Llm-enhanced world models for diverse driving video generation,” inProceedings of the AAAI Conference on Artificial Intel- ligence, vol. 39, no. 10, 2025, pp. 10 412–10 420
2025
-
[15]
Occworld: Learning a 3d occupancy world model for autonomous driving,
W. Zheng, W. Chen, Y . Huang, B. Zhang, Y . Duan, and J. Lu, “Occworld: Learning a 3d occupancy world model for autonomous driving,” in European conference on computer vision. Springer, 2024, pp. 55–72
2024
-
[16]
Driving in the occupancy world: Vision-centric 4d occupancy forecasting and planning via world models for autonomous driving,
Y . Yang, J. Mei, Y . Ma, S. Du, W. Chen, Y . Qian, Y . Feng, and Y . Liu, “Driving in the occupancy world: Vision-centric 4d occupancy forecasting and planning via world models for autonomous driving,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 9, 2025, pp. 9327–9335
2025
-
[17]
Occ-llm: Enhancing autonomous driving with occupancy-based large language models,
T. Xu, H. Lu, X. Yan, Y . Cai, B. Liu, and Y . Chen, “Occ-llm: Enhancing autonomous driving with occupancy-based large language models,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 8434–8441
2025
-
[18]
Learning latent dynamics for planning from pixels,
D. Hafner, T. Lillicrap, I. Fischer, R. Villegas, D. Ha, H. Lee, and J. Davidson, “Learning latent dynamics for planning from pixels,” in International conference on machine learning. PMLR, 2019, pp. 2555– 2565
2019
-
[19]
Driving style alignment for llm-powered driver agent,
R. Yang, X. Zhang, A. Fernandez-Laaksonen, X. Ding, and J. Gong, “Driving style alignment for llm-powered driver agent,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 11 318–11 324
2024
-
[20]
DeepSeek API Docs,
DeepSeek, “DeepSeek API Docs,” https://api-docs.deepseek.com/, 2026, online; accessed February 26, 2026
2026
-
[21]
Carla: An open urban driving simulator,
A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V . Koltun, “Carla: An open urban driving simulator,” inConference on Robot Learning. PMLR, 2017, pp. 1–16
2017
-
[22]
Msma: Multi-agent trajectory prediction in connected and autonomous vehicle environment with multi-source data integration,
X. Chen, R. Bhadani, Z. Sun, and L. Head, “Msma: Multi-agent trajectory prediction in connected and autonomous vehicle environment with multi-source data integration,” inCICTP 2024, 2024, pp. 268–278
2024
-
[23]
Evaluation criteria for the leaderboard 2.0,
“Evaluation criteria for the leaderboard 2.0,” http://leaderboard.carla. org/evaluation v2 0/, 2026, cARLA Autonomous Driving Leaderboard; accessed February 28, 2026
2026
-
[24]
Learning by cheating,
D. Chen, B. Zhou, V . Koltun, and P. Kr¨ahenb¨uhl, “Learning by cheating,” inConference on Robot Learning. PMLR, 2020, pp. 66–75
2020
-
[25]
Follownet: A comprehensive benchmark for car-following behavior modeling,
X. Chen, M. Zhu, K. Chen, P. Wang, H. Lu, H. Zhong, X. Han, X. Wang, and Y . Wang, “Follownet: A comprehensive benchmark for car-following behavior modeling,”Scientific Data, vol. 10, no. 1, p. 828, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.