ActQuant: Sub-4-bit Action-Guided Quantization for Vision-Language-Action Models
Pith reviewed 2026-06-30 17:52 UTC · model grok-4.3
The pith
ActQuant quantizes vision-language-action models to 3 bits per weight or less while retaining over 94 percent of baseline action accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
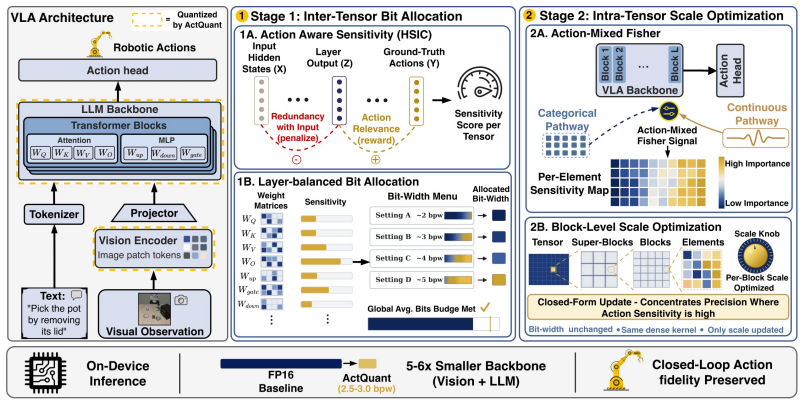
ActQuant is an action-guided mixed-precision post-training quantization framework whose inter-tensor bit allocator assigns each weight matrix a single bit-width based on its contribution to predicting the agent's actions and whose intra-tensor scale optimizer tunes per-block quantization scales using action-aware curvature. When applied to OpenVLA-OFT and π0.5 it is the only method that operates at or below 3 bits-per-weight while retaining 95.0 percent and 94.8 percent of baseline performance; at 2.5 bits-per-weight it reaches 90.1 percent on OpenVLA-OFT with 5.3 times compression and preserves baseline success rate on a real 6-DoF UR3 arm after conversion through OmniModel.cpp.
What carries the argument
The inter-tensor bit allocator that scores each weight matrix by its measured contribution to action prediction together with the intra-tensor scale optimizer that concentrates dynamic range using action-aware curvature.
If this is right
- VLA models become deployable on edge platforms because memory drops from 14.3 GB to 2.7 GB at 2.5 bits per weight.
- Only existing post-training method achieves usable performance at or below 3 bits per weight on these models.
- Control performance is preserved both in simulation benchmarks and on physical robot hardware.
- The OmniModel.cpp pipeline converts the quantized models into a native C/C++ runtime with efficient low-bit kernels for on-device use.
Where Pith is reading between the lines
- The same action-contribution metric might let quantization adapt automatically when a robot encounters new tasks without retraining the allocator.
- Because scale optimization is driven by action curvature, the method may generalize better to other embodied models whose outputs are also continuous actions rather than discrete tokens.
- If calibration trajectories cover only narrow action ranges the allocator could under-allocate bits to matrices important for rare but critical motions.
Load-bearing premise
That measuring each matrix's contribution to action prediction and computing action-aware curvature from a calibration set produces bit allocations and scales reliable enough to preserve control performance without any post-hoc task-specific tuning.
What would settle it
Running the 3-bit ActQuant version of OpenVLA-OFT or π0.5 on the LIBERO benchmark or the UR3 arm and observing success rate drop below 80 percent of the full-precision baseline would falsify the claim.
Figures


read the original abstract
Vision-Language-Action (VLA) models exhibit remarkable action generation for embodied intelligence, but their heavy compute make deployment on edge platforms impractical. Aggressive, sub-4-bit weight quantization is the natural solution, yet existing post-training quantization (PTQ) methods suffer severe performance degradation in this regime. To address this, we introduce ActQuant, an action-guided mixed-precision PTQ framework that operates in two stages: (1) an inter-tensor bit allocator that assigns each weight matrix a single bit-width based on how much it contributes to predicting the agent's actions; (2) an intra-tensor scale optimizer tunes per-block quantization scales using action-aware curvature, so that dynamic range is concentrated on the weights most influential for control. To deliver the on-device benefits of our aggressive quantization, we further introduce OmniModel.cpp, an agentic conversion pipeline that ports architectures into a native C/C++ runtime with efficient low-bit kernels. We evaluate ActQuant both in simulation and on a real-world 6-DoF UR3 arm, with all models deployed through OmniModel.cpp. On the LIBERO benchmark, ActQuant is the only method that operates at or below 3 bits-per-weight, retaining 95.0% on OpenVLA-OFT and 94.8% on $\pi_{0.5}$. Pushed further, ActQuant reaches 2.5 bpw at 90.1% on OpenVLA-OFT, compressing the backbone from 14.3 GB to 2.7 GB (5.3$\times$). On the physical UR3 arm, $\pi_{0.5}$ quantized with ActQuant retains the baseline's success rate while reducing the memory footprint by 2.5$\times$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ActQuant, a novel action-guided mixed-precision post-training quantization (PTQ) framework for Vision-Language-Action (VLA) models. It consists of two stages: an inter-tensor bit allocator that assigns bit-widths based on contribution to action prediction, and an intra-tensor scale optimizer that uses action-aware curvature to tune quantization scales. Additionally, it introduces OmniModel.cpp for efficient C/C++ deployment of the quantized models. Evaluations on the LIBERO benchmark show that ActQuant is the only method to operate at or below 3 bits-per-weight while retaining 95.0% success on OpenVLA-OFT and 94.8% on π0.5, with further compression to 2.5 bpw achieving 90.1% on OpenVLA-OFT and 5.3× compression from 14.3 GB to 2.7 GB. Physical validation on a UR3 arm shows retention of baseline success rate with 2.5× smaller footprint.
Significance. If the central claims regarding performance retention at sub-4-bit quantization are substantiated by detailed experiments, ablations, and comparisons in the full manuscript, this work could have high significance for the field of efficient embodied AI. Enabling deployment of large VLA models on edge platforms through aggressive quantization while maintaining control performance would be a valuable advance, particularly with the inclusion of real-robot validation and a deployment pipeline.
major comments (2)
- Abstract: The abstract reports specific success rates (95.0%, 94.8%, 90.1%) without any mention of error bars, number of trials, or statistical significance, which is essential for validating the robustness of the performance claims under the action-guided quantization.
- Abstract: No details, equations, or pseudocode are provided for the inter-tensor bit allocator or the intra-tensor scale optimizer, making it impossible to assess whether these components reliably preserve action prediction performance without post-hoc tuning, as highlighted in the weakest assumption.
minor comments (2)
- Abstract: The term 'bpw' is used without prior definition, although it is clear from context as bits-per-weight.
- Abstract: The compression factor is reported as 5.3× for the backbone and 2.5× for the physical arm; clarifying if these are consistent or different aspects would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their comments on the abstract. We address each point below and clarify how the manuscript provides the necessary details while agreeing where revisions can strengthen the presentation.
read point-by-point responses
-
Referee: Abstract: The abstract reports specific success rates (95.0%, 94.8%, 90.1%) without any mention of error bars, number of trials, or statistical significance, which is essential for validating the robustness of the performance claims under the action-guided quantization.
Authors: We agree that reporting the number of trials and variance would improve clarity. The LIBERO evaluations average success rates over 100 episodes per task (with results aggregated across three random seeds), and the physical robot experiments use 20 trials per task. We will revise the abstract to note 'mean success rate over 100 trials' and ensure the main text and supplementary material explicitly state the trial counts and observed standard deviations (typically <2% on simulation tasks). revision: partial
-
Referee: Abstract: No details, equations, or pseudocode are provided for the inter-tensor bit allocator or the intra-tensor scale optimizer, making it impossible to assess whether these components reliably preserve action prediction performance without post-hoc tuning, as highlighted in the weakest assumption.
Authors: Abstracts are necessarily concise and omit equations by design. The full manuscript provides the complete formulation: the inter-tensor allocator is defined in Section 3.2 with the contribution score in Equation (2) and the resulting bit assignment procedure; the intra-tensor scale optimizer is detailed in Section 3.3 with the action-aware curvature loss in Equation (4) and the per-block optimization steps in Algorithm 1. These sections include all hyperparameters and the end-to-end training-free procedure, allowing direct assessment of the method without post-hoc tuning. revision: no
Circularity Check
No significant circularity
full rationale
The provided abstract and description outline an action-guided mixed-precision PTQ method with inter-tensor bit allocation based on action prediction contribution and intra-tensor scale optimization via action-aware curvature, followed by deployment via OmniModel.cpp. Performance is reported on external benchmarks (LIBERO, OpenVLA-OFT, π0.5, UR3 arm) with no equations, fitted parameters, or self-referential metrics shown that would reduce success rates or compression factors to the allocator/optimizer inputs by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked in the text. The derivation chain is self-contained against external task performance and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π_0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Towards mixed-precision quantization of neural networks via constrained optimization
Weihan Chen, Peisong Wang, and Jian Cheng. Towards mixed-precision quantization of neural networks via constrained optimization. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5350–5359, 2021
2021
-
[3]
Channel-Wise Mixed-Precision Quantization for Large Language Models
Zihan Chen, Bike Xie, Jundong Li, and Cong Shen. Channel-wise mixed-precision quantization for large language models.arXiv preprint arXiv:2410.13056, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Qlora: Efficient finetuning of quantized llms.Advances in neural information processing systems, 36:10088– 10115, 2023
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms.Advances in neural information processing systems, 36:10088– 10115, 2023
2023
-
[5]
Tim Dettmers, Ruslan Svirschevski, Vage Egiazarian, Denis Kuznedelev, Elias Frantar, Saleh Ashkboos, Alexander Borzunov, Torsten Hoefler, and Dan Alistarh. Spqr: A sparse-quantized representation for near-lossless llm weight compression.arXiv preprint arXiv:2306.03078, 2023
-
[6]
Hawq-v2: Hessian aware trace-weighted quantization of neural networks.Advances in neural information processing systems, 33:18518–18529, 2020
Zhen Dong, Zhewei Yao, Daiyaan Arfeen, Amir Gholami, Michael W Mahoney, and Kurt Keutzer. Hawq-v2: Hessian aware trace-weighted quantization of neural networks.Advances in neural information processing systems, 33:18518–18529, 2020
2020
-
[7]
Extreme compression of large language models via additive quantization
Vage Egiazarian, Andrei Panferov, Denis Kuznedelev, Elias Frantar, Artem Babenko, and Dan Alistarh. Extreme compression of large language models via additive quantization.arXiv preprint arXiv:2401.06118, 2024
-
[8]
Generalized Lagrange multiplier method for solving problems of optimum allocation of resources.Operations Research, 11(3):399–417, 1963
Hugh Everett III. Generalized Lagrange multiplier method for solving problems of optimum allocation of resources.Operations Research, 11(3):399–417, 1963
1963
-
[9]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers.arXiv preprint arXiv:2210.17323, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
GGML: Tensor library for machine learning
Georgi Gerganov. GGML: Tensor library for machine learning. https://github.com/ ggml-org/ggml, 2023. Accessed 2026-05-01
2023
-
[11]
llama.cpp: LLM inference in c/C++
Georgi Gerganov and llama.cpp contributors. llama.cpp: LLM inference in c/C++. https: //github.com/ggerganov/llama.cpp, 2023. Accessed 2026-05-01
2023
-
[12]
Measuring statistical dependence with Hilbert-Schmidt norms
Arthur Gretton, Olivier Bousquet, Alex Smola, and Bernhard Schölkopf. Measuring statistical dependence with Hilbert-Schmidt norms. InInternational Conference on Algorithmic Learning Theory (ALT), pages 63–77. Springer, 2005
2005
-
[13]
Wei Huang, Haotong Qin, Yangdong Liu, Yawei Li, Qinshuo Liu, Xianglong Liu, Luca Benini, Michele Magno, Shiming Zhang, and Xiaojuan Qi. Slim-llm: Salience-driven mixed-precision quantization for large language models.arXiv preprint arXiv:2405.14917, 2024
-
[14]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π0.5: a vision- language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Squeezellm: Dense-and-sparse quanti- zation,
Sehoon Kim, Coleman Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W Mahoney, and Kurt Keutzer. Squeezellm: Dense-and-sparse quantization.arXiv preprint arXiv:2306.07629, 2023. 10
-
[18]
Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, et al. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Self-supervised learning with kernel dependence maximization.Advances in Neural Information Processing Systems, 34:15543–15556, 2021
Yazhe Li, Roman Pogodin, Danica J Sutherland, and Arthur Gretton. Self-supervised learning with kernel dependence maximization.Advances in Neural Information Processing Systems, 34:15543–15556, 2021
2021
-
[20]
Awq: Activation-aware weight quantization for on-device llm compression and acceleration.Proceedings of machine learning and systems, 6:87–100, 2024
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for on-device llm compression and acceleration.Proceedings of machine learning and systems, 6:87–100, 2024
2024
-
[21]
Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[22]
Hsic- infogan: learning unsupervised disentangled representations by maximising approximated mutual information
Xiao Liu, Spyridon Thermos, Pedro Sanchez, Alison Q O’Neil, and Sotirios A Tsaftaris. Hsic- infogan: learning unsupervised disentangled representations by maximising approximated mutual information. InMICCAI Workshop on Medical Applications with Disentanglements, pages 15–21. Springer, 2022
2022
-
[23]
Stuart P. Lloyd. Least squares quantization in PCM.IEEE Transactions on Information Theory, 28(2):129–137, 1982
1982
-
[24]
Wan-Duo Kurt Ma, J. P. Lewis, and W. Bastiaan Kleijn. The HSIC bottleneck: Deep learning without back-propagation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 5085–5092, 2020
2020
-
[25]
Non-structured dnn weight pruning—is it beneficial in any platform?IEEE transactions on neural networks and learning systems, 33(9):4930–4944, 2021
Xiaolong Ma, Sheng Lin, Shaokai Ye, Zhezhi He, Linfeng Zhang, Geng Yuan, Sia Huat Tan, Zhengang Li, Deliang Fan, Xuehai Qian, et al. Non-structured dnn weight pruning—is it beneficial in any platform?IEEE transactions on neural networks and learning systems, 33(9):4930–4944, 2021
2021
-
[26]
Ompq: Orthogonal mixed precision quantization
Yuexiao Ma, Taisong Jin, Xiawu Zheng, Yan Wang, Huixia Li, Yongjian Wu, Guannan Jiang, Wei Zhang, and Rongrong Ji. Ompq: Orthogonal mixed precision quantization. InProceedings of the AAAI conference on artificial intelligence, volume 37, pages 9029–9037, 2023
2023
-
[27]
New insights and perspectives on the natural gradient method.Journal of Machine Learning Research, 21(146):1–76, 2020
James Martens. New insights and perspectives on the natural gradient method.Journal of Machine Learning Research, 21(146):1–76, 2020
2020
-
[28]
Lukas Miklautz, Chengzhi Shi, Andrii Shkabrii, Theodoros Thirimachos Davarakis, Prudence Lam, Claudia Plant, Jennifer Dy, and Stratis Ioannidis. H-splid: Hsic-based saliency preserving latent information decomposition.arXiv preprint arXiv:2510.20627, 2025
-
[29]
Nemhauser, Laurence A
George L. Nemhauser, Laurence A. Wolsey, and Marshall L. Fisher. An analysis of approxima- tions for maximizing submodular set functions (I).Mathematical Programming, 14(1):265–294, 1978
1978
-
[30]
DINOv2: Learn- ing robust visual features without supervision.Transactions on Machine Learning Research (TMLR), 2024
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. DINOv2: Learn- ing robust visual features without supervision.Transactions on Machine Learning Research (TMLR), 2024
2024
-
[31]
Quantization-aware imitation-learning for resource-efficient robotic control, 2024
Seongmin Park, Hyungmin Kim, Sangwoo Kim, Wonseok Jeong, Juyoung Park, and Jungwook Choi. Quantization-aware imitation-learning for resource-efficient robotic control, 2024
2024
-
[32]
PyTorch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. PyTorch: An imperative style, high-performance deep learning library. InAdvances in Neural Information Processing Systems (NeurIPS), 2019. 11
2019
-
[33]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Qtip: Quantization with trellises and incoherence processing.Advances in Neural Information Processing Systems, 37:59597– 59620, 2024
Albert Tseng, Qingyao Sun, David Hou, and Christopher De. Qtip: Quantization with trellises and incoherence processing.Advances in Neural Information Processing Systems, 37:59597– 59620, 2024
2024
-
[35]
Bitvla: 1-bit vision-language- action models for robotics manipulation, 2026
Hongyu Wang, Chuyan Xiong, Ruiping Wang, and Xilin Chen. Bitvla: 1-bit vision-language- action models for robotics manipulation, 2026
2026
-
[36]
Revisiting hilbert- schmidt information bottleneck for adversarial robustness.Advances in Neural Information Processing Systems, 34:586–597, 2021
Zifeng Wang, Tong Jian, Aria Masoomi, Stratis Ioannidis, and Jennifer Dy. Revisiting hilbert- schmidt information bottleneck for adversarial robustness.Advances in Neural Information Processing Systems, 34:586–597, 2021
2021
-
[37]
Dualhsic: Hsic-bottleneck and alignment for continual learning
Zifeng Wang, Zheng Zhan, Yifan Gong, Yucai Shao, Stratis Ioannidis, Yanzhi Wang, and Jennifer Dy. Dualhsic: Hsic-bottleneck and alignment for continual learning. InInternational Conference on Machine Learning, pages 36578–36592. PMLR, 2023
2023
-
[38]
TinyVLA: Towards Fast, Data-Efficient Vision-Language-Action Models for Robotic Manipulation
Junjie Wen, Yichen Zhu, Jinming Li, Minjie Zhu, Kun Wu, Zhiyuan Xu, Ning Liu, Ran Cheng, Chaomin Shen, Yaxin Peng, et al. TinyVLA: Towards fast, data-efficient vision-language-action models for robotic manipulation.arXiv preprint arXiv:2409.12514, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Qvla: Not all channels are equal in vision-language-action model’s quantization, 2026
Yuhao Xu, Yantai Yang, Zhenyang Fan, Yufan Liu, Yuming Li, Bing Li, and Zhipeng Zhang. Qvla: Not all channels are equal in vision-language-action model’s quantization, 2026
2026
-
[40]
Efficientvla: Training-free acceleration and compression for vision- language-action models.Advances in Neural Information Processing Systems, 38:40891–40914, 2026
Yantai Yang, Yuhao Wang, Zichen Wen, Luo Zhongwei, Chang Zou, Zhipeng Zhang, Chuan Wen, and Linfeng Zhang. Efficientvla: Training-free acceleration and compression for vision- language-action models.Advances in Neural Information Processing Systems, 38:40891–40914, 2026
2026
-
[41]
Hawq-v3: Dyadic neural network quantization
Zhewei Yao, Zhen Dong, Zhangcheng Zheng, Amir Gholami, Jiali Yu, Eric Tan, Leyuan Wang, Qijing Huang, Yida Wang, Michael Mahoney, et al. Hawq-v3: Dyadic neural network quantization. InInternational Conference on Machine Learning, pages 11875–11886. PMLR, 2021
2021
-
[42]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[43]
Quantvla: Scale-calibrated post-training quantization for vision-language-action models, 2026
Jingxuan Zhang, Yunta Hsieh, Zhongwei Wan, Haokun Lin, Xin Wang, Ziqi Wang, Yingtie Lei, and Mi Zhang. Quantvla: Scale-calibrated post-training quantization for vision-language-action models, 2026
2026
-
[44]
A Survey on Vision-Language-Action Models: An Action Tokenization Perspective
Yifan Zhong, Fengshuo Bai, Shaofei Cai, Xuchuan Huang, Zhang Chen, Xiaowei Zhang, Yuanfei Wang, Shaoyang Guo, Tianrui Guan, Ka Nam Lui, et al. A survey on vision-language- action models: An action tokenization perspective.arXiv preprint arXiv:2507.01925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023. 12 A Hilbert-Schmidt Independence Criterion This appendix expands on the HSIC definiti...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.