Towards Evaluation Engineering: An Empirical Study of ML Evaluation Harnesses in the Wild
Pith reviewed 2026-06-30 14:38 UTC · model grok-4.3
The pith
ML evaluation harnesses face the majority of their operational challenges during the specification of external models, datasets, and judges.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
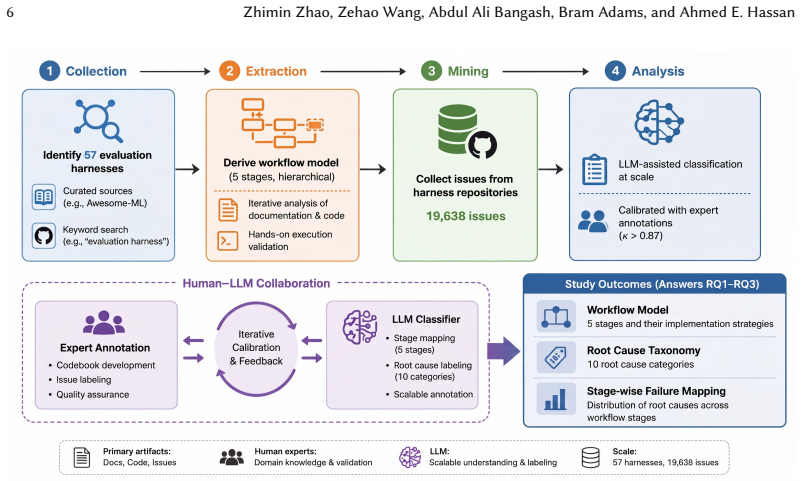
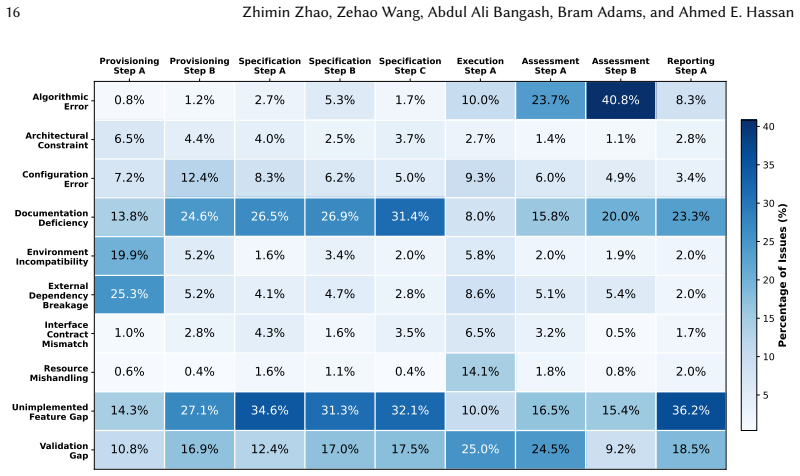
The paper derives a five-stage harness model and shows through classification of 16,560 issues that most operational challenges concentrate in the Specification stage (41.4% of issues), where harnesses integrate external models, datasets, and scoring judges. The three most frequent root causes are unimplemented features (24.3%), documentation gaps (20.3%), and missing input validation (17.2%), together accounting for 61.7% of classified issues.
What carries the argument
The five-stage harness model that divides the evaluation workflow into distinct stages, paired with classification of issues by workflow stage and root cause.
If this is right
- Root causes differ by stage, with environment incompatibility and external dependency breakage causing 36.2% of provisioning issues.
- Algorithmic error (25.9%) and validation gap (22.5%) dominate assessment issues.
- Addressing unimplemented features, documentation, and validation could resolve over 60% of issues.
- Evaluation engineering merits treatment as a distinct software engineering concern.
Where Pith is reading between the lines
- Developers of new evaluation harnesses should prioritize clear documentation and input validation early in design.
- Future studies could examine whether addressing specification issues improves overall ML experiment reproducibility.
- Tool builders might benefit from standardized interfaces for models and datasets to reduce integration problems.
Load-bearing premise
The 57 harnesses studied and the issues extracted from them form a representative sample of ML evaluation harnesses, and the classification into stages and root causes reflects the true distribution without substantial bias.
What would settle it
A replication study on a different or larger set of harnesses that finds the specification stage accounting for substantially less than 41% of issues, or a different set of dominant root causes.
Figures



read the original abstract
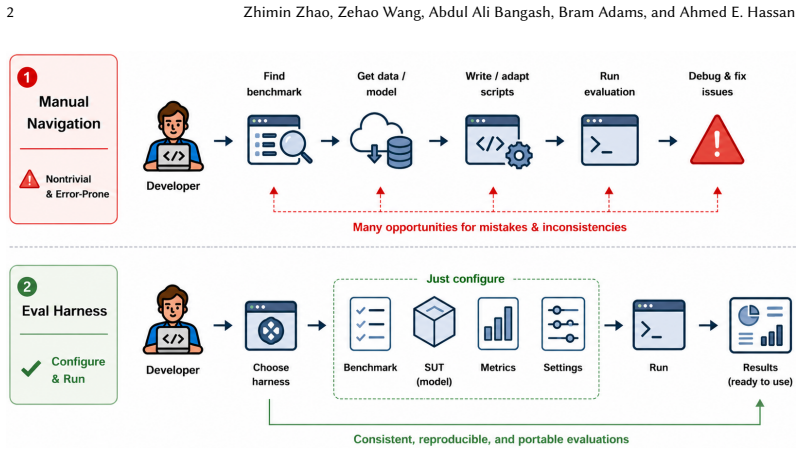
Evaluation harnesses are software systems that orchestrate model evaluation by managing model invocation, data loading, metric computation, and result reporting. Despite their critical role in machine learning infrastructure, their operational challenges and engineering concerns have received limited attention so far. We present an empirical study of 57 evaluation harnesses, deriving a five-stage harness model and classifying 16,560 issues by workflow stage and root cause. Most harness operational challenges concentrate in the Specification stage (41.4% of issues), where harnesses integrate external models, datasets, and scoring judges. The three most frequent root causes of operational challenges are unimplemented features (24.3%), documentation gaps (20.3%), and missing input validation (17.2%), which together account for 61.7% of classified issues, spanning both defects in existing functionality and capability gaps that block intended workflows. Root causes also vary by workflow stage: environment incompatibility and external dependency breakage account for 36.2% of provisioning issues, whereas algorithmic error (25.9%) and validation gap (22.5%) dominate assessment issues. Together, these contributions establish an empirical foundation for treating evaluation engineering as a distinct software engineering concern.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an empirical study of 57 ML evaluation harnesses. It derives a five-stage workflow model and manually classifies 16,560 issues by workflow stage and root cause. The central findings are that 41.4% of issues occur in the Specification stage, with the top three root causes being unimplemented features (24.3%), documentation gaps (20.3%), and missing input validation (17.2%). These account for 61.7% of issues, and root causes vary by stage (e.g., environment incompatibility for provisioning, algorithmic error for assessment).
Significance. If the sample of harnesses is representative and the classifications reproducible, the work supplies the first large-scale empirical map of operational pain points in ML evaluation infrastructure. This directly supports the paper's claim that evaluation engineering merits treatment as a distinct software-engineering concern, with concrete stage-specific and root-cause distributions that could guide tool builders and researchers.
major comments (2)
- [Methods (harness selection)] The harness selection methodology (Methods section) provides no sampling frame, inclusion/exclusion criteria, or justification for the 57 harnesses. Without these, systematic biases (e.g., popularity, language, or hosting platform) cannot be ruled out, undermining the claim that the reported percentages characterize 'the wild'.
- [Methods (issue classification)] The classification procedure for the 16,560 issues (Methods section) reports no inter-rater reliability statistics, number of raters, or adjudication protocol. Because the headline percentages (41.4% Specification stage; 24.3%/20.3%/17.2% root causes) are direct outputs of this labeling, the absence of reliability evidence is load-bearing for the validity of all distributional claims.
minor comments (2)
- The five-stage model is introduced in the abstract but would benefit from an explicit diagram or table early in the paper to make the stage boundaries unambiguous for readers.
- Consider reporting the total number of issues per harness or per stage to allow readers to assess whether a few large harnesses dominate the 16,560-issue corpus.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments identify important gaps in methodological transparency. We address each below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Methods (harness selection)] The harness selection methodology (Methods section) provides no sampling frame, inclusion/exclusion criteria, or justification for the 57 harnesses. Without these, systematic biases (e.g., popularity, language, or hosting platform) cannot be ruled out, undermining the claim that the reported percentages characterize 'the wild'.
Authors: We agree that the current Methods section lacks an explicit sampling frame, inclusion/exclusion criteria, and justification. The 57 harnesses were identified through GitHub searches using terms such as 'evaluation harness' and 'model evaluation framework', filtered by popularity (stars and forks), language (primarily Python), and relevance to ML model evaluation. In the revision we will add a dedicated subsection that states the full search strategy, precise inclusion criteria (open-source, supports model invocation and metric computation, active maintenance within the last 12 months, English documentation), exclusion criteria (toy examples, non-ML focus, archived repositories), and a limitations paragraph discussing potential biases toward popular English-language projects. This will allow readers to evaluate representativeness. revision: yes
-
Referee: [Methods (issue classification)] The classification procedure for the 16,560 issues (Methods section) reports no inter-rater reliability statistics, number of raters, or adjudication protocol. Because the headline percentages (41.4% Specification stage; 24.3%/20.3%/17.2% root causes) are direct outputs of this labeling, the absence of reliability evidence is load-bearing for the validity of all distributional claims.
Authors: We concur that reliability evidence is necessary. Classification was performed by two authors using an iteratively refined codebook; disagreements were resolved in consensus meetings. The revision will explicitly report the number of raters (two), the full adjudication protocol, and inter-rater reliability on a random sample of at least 500 issues (Cohen's kappa). The headline percentages will remain unchanged because they reflect the final consensus labels. We view this addition as strengthening rather than altering the empirical claims. revision: yes
Circularity Check
No circularity: purely empirical classification with direct counts
full rationale
The paper is an empirical study that selects 57 harnesses, extracts 16,560 issues, and manually classifies them into a five-stage workflow model plus root-cause taxonomy. Reported percentages (e.g., 41.4% Specification stage) are literal tallies of classified items with no equations, fitted parameters, predictions, or derivations. No self-citation chain, ansatz, or uniqueness theorem is invoked to justify the central claims; the distributions are produced by the classification process itself and do not reduce to any prior result by construction. The study is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 57 selected evaluation harnesses and the 16,560 issues drawn from them are representative of ML evaluation harnesses in the wild.
Reference graph
Works this paper leans on
-
[1]
Hervé Abdi and Lynne J Williams. 2010. Principal component analysis.Wiley interdisciplinary reviews: computational statistics2, 4 (2010), 433–459
2010
-
[2]
Saleema Amershi, Andrew Begel, Christian Bird, Robert DeLine, Harald Gall, Ece Kamar, Nachiappan Nagappan, Besmira Nushi, and Thomas Zimmermann. 2019. Software engineering for machine learning: a case study. In 2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP)
2019
-
[3]
Andrea Arcuri and Gordon Fraser. 2013. Parameter Tuning or Default Values? An Empirical Investigation in Search-Based Software Engineering.Empirical Software Engineering18, 3 (2013), 594–623. doi:10.1007/s10664- 013-9249-9
-
[4]
Rob Ashmore, Radu Calinescu, and Colin Paterson. 2021. Assuring the machine learning lifecycle: Desiderata, methods, and challenges.ACM computing surveys (CSUR)54, 5 (2021), 1–39
2021
-
[5]
Hamdy Michael Ayas, Hartmut Fischer, Philipp Leitner, and Francisco Gomes de Oliveira Neto. 2022. An Empirical Analysis of Microservices Systems Using Consumer-Driven Contract Testing. In48th Euromicro Conference on Software Engineering and Advanced Applications (SEAA 2022). IEEE, Masovia, Poland, 92–99. doi:10.1109/SEAA56994.2022.00022
-
[6]
Earl T Barr, Mark Harman, Phil McMinn, Muzammil Shahbaz, and Shin Yoo. 2015. The Oracle Problem in Software Testing: A Survey.IEEE Transactions on Software Engineering41, 5 (2015), 507–525
2015
-
[7]
Aaditya Bhatia, Foutse Khomh, Bram Adams, and Ahmed E Hassan. 2023. An empirical study of self-admitted technical debt in machine learning software.ACM Transactions on Software Engineering and Methodology33, 1 (2023), 1–38
2023
-
[8]
Stella Biderman, Hailey Schoelkopf, Lintang Sutawika, Leo Gao, Jonathan Tow, Baber Abbasi, Alham Fikri Aji, Pawan Sasanka Ammanamanchi, Sidney Black, Jordan Clive, et al. 2024. Lessons from the Trenches on Reproducible Evaluation of Language Models. arXiv preprint arXiv:2405.14782. ACM Trans. Softw. Eng. Methodol., Vol. 1, No. 1, Article . Publication dat...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Eric Breck, Shanqing Cai, Eric Nielsen, Michael Salib, and D Sculley. 2019. Data Validation for Machine Learning. In Proceedings of Machine Learning and Systems. MLSys, Stanford, CA, USA, 334–347
2019
- [10]
-
[11]
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al. 2024. A survey on evaluation of large language models.ACM transactions on intelligent systems and technology15, 3 (2024), 1–45
2024
-
[12]
Tsong Yueh Chen, Fei-Ching Kuo, Huai Liu, Pak-Lok Poon, Dave Towey, TH Tse, and Zhi Quan Zhou. 2018. Metamorphic testing: A review of challenges and opportunities.Comput. Surveys51, 1 (2018), 1–27
2018
-
[13]
1977.Sampling techniques
William Gemmell Cochran. 1977.Sampling techniques. John Wiley & Sons, New York, NY, USA
1977
- [14]
-
[15]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition. IEEE, Piscataway, NJ, USA, 248–255
2009
-
[16]
George Ecurali and Zelie Thackeray. 2024. Automated methodologies for evaluating lying, hallucinations, and bias in large language models. arXiv preprint
2024
-
[17]
Isabel O Gallegos, Ryan A Rossi, Joe Barrow, Md Mehrab Tanjim, Sungchul Kim, Franck Dernoncourt, Tong Yu, Ruiyi Zhang, and Nesreen K Ahmed. 2024. Bias and fairness in large language models: A survey.Computational Linguistics 50, 3 (2024), 1097–1179
2024
-
[18]
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. 2024. The L...
-
[19]
Vahid Garousi and Barış Küçük. 2018. Smells in software test code: A survey of knowledge in industry and academia. Journal of systems and software138 (2018), 52–81
2018
-
[20]
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé Iii, and Kate Crawford. 2021. Datasheets for datasets.Commun. ACM64, 12 (2021), 86–92
2021
-
[21]
Barney G Glaser et al. 1967. Strauss.The discovery of grounded theory: strategies for qualitative research11 (1967), 1–271
1967
-
[22]
Rothblum, Jonathan Shafer, and Amir Yehudayoff
Shafi Goldwasser, Guy N. Rothblum, Jonathan Shafer, and Amir Yehudayoff. 2021. Interactive Proofs for Verifying Machine Learning. In12th Innovations in Theoretical Computer Science Conference (ITCS 2021) (Leibniz International Proceedings in Informatics (LIPIcs), Vol. 185), James R. Lee (Ed.). Schloss Dagstuhl – Leibniz-Zentrum für Informatik, Dagstuhl, G...
-
[23]
Hao He, Bogdan Vasilescu, and Christian Kästner. 2025. Pinning Is Futile: You Need More Than Local Dependency Versioning to Defend against Supply Chain Attacks.Proc. ACM Softw. Eng.2, FSE (2025), 266–289. doi:10.1145/3715728
-
[24]
Michael Hilton, Timothy Tunnell, Kai Huang, Darko Marinov, and Danny Dig. 2016. Usage, costs, and benefits of continuous integration in open-source projects. InProceedings of the 31st IEEE/ACM international conference on automated software engineering. ACM, New York, NY, USA, 426–437
2016
-
[25]
Soneya Binta Hossain, Raygan Taylor, and Matthew B. Dwyer. 2025. Doc2OracLL: Investigating the Impact of Documentation on LLM-Based Test Oracle Generation.Proc. ACM Softw. Eng.2, FSE (2025), 1870–1891. doi:10.1145/37 29354
work page doi:10.1145/37 2025
-
[26]
Alperen Keleş. 2025. Verifiability is the Limit. https://alperenkeles.com/posts/verifiability-is-the-limit/
2025
-
[27]
Dominik Kreuzberger, Niklas Kühl, and Sebastian Hirschl. 2023. Machine learning operations (mlops): Overview, definition, and architecture.IEEE access11 (2023), 31866–31879
2023
-
[28]
J Richard Landis and Gary G Koch. 1977. The measurement of observer agreement for categorical data.Biometrics33, 1 (1977), 159–174
1977
-
[29]
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, et al . 2022. Holistic evaluation of language models. arXiv preprint arXiv:2211.09110
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
Qingzhou Luo, Farah Hariri, Lamyaa Eloussi, and Darko Marinov. 2014. An empirical analysis of flaky tests. In Proceedings of the 22nd ACM SIGSOFT international symposium on foundations of software engineering. ACM, New York, NY, USA, 643–653
2014
-
[31]
Nestor Maslej, Loredana Fattorini, Raymond Perrault, Vanessa Parli, Anka Reuel, Erik Brynjolfsson, John Etchemendy, Katrina Ligett, Terah Lyons, James Manyika, Juan Carlos Niebles, Yoav Shoham, Russell Wald, and Jack Clark. 2024. Artificial Intelligence Index Report 2024. arXiv:2405.19522 [cs.AI] https://arxiv.org/abs/2405.19522
-
[32]
William M McKeeman. 1998. Differential testing for software.Digital Technical Journal10, 1 (1998), 100–107. ACM Trans. Softw. Eng. Methodol., Vol. 1, No. 1, Article . Publication date: May 2026. 24 Zhimin Zhao, Zehao Wang, Abdul Ali Bangash, Bram Adams, and Ahmed E. Hassan
1998
-
[33]
Tom Mens. 2008. Introduction and roadmap: History and challenges of software evolution. InSoftware evolution. Springer, Berlin, Germany, 1–11
2008
-
[34]
Design by Contract
Bertrand Meyer. 1992. Applying “Design by Contract”.Computer25, 10 (1992), 40–51
1992
-
[35]
Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. 2019. Model cards for model reporting. InProceedings of the conference on fairness, accountability, and transparency. ACM, New York, NY, USA, 220–229
2019
- [36]
- [37]
-
[38]
OpenAI. 2023. The new stack and ops for AI [Conference talk]. OpenAI DevDay. https://www.youtube.com/watch? v=XGJNo8TpuVA
2023
-
[39]
Andrei Paleyes, Raoul-Gabriel Urma, and Neil D Lawrence. 2022. Challenges in deploying machine learning: a survey of case studies.ACM computing surveys55, 6 (2022), 1–29
2022
-
[40]
Owain Parry, Gregory M Kapfhammer, Michael Hilton, and Phil McMinn. 2021. A survey of flaky tests.ACM Transactions on Software Engineering and Methodology (TOSEM)31, 1 (2021), 1–74
2021
-
[41]
Peter J Rousseeuw. 1987. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis.Journal of computational and applied mathematics20 (1987), 53–65
1987
- [42]
-
[43]
David Sculley, Gary Holt, Daniel Golovin, Eugene Davydov, Todd Phillips, Dietmar Ebner, Vinay Chaudhary, Michael Young, Jean-Francois Crespo, and Dan Dennison. 2015. Hidden technical debt in machine learning systems.Advances in neural information processing systems28 (2015), 2503–2511
2015
-
[44]
Harald Semmelrock, Tony Ross-Hellauer, Simone Kopeinik, Dieter Theiler, Armin Haberl, Stefan Thalmann, and Dominik Kowald. 2025. Reproducibility in machine-learning-based research: Overview, barriers, and drivers.AI Magazine46, 2 (2025), e70002
2025
-
[45]
Parshin Shojaee, Iman Mirzadeh, Keivan Alizadeh, Maxwell Horton, Samy Bengio, and Mehrdad Farajtabar. 2025. The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity. arXiv preprint arXiv:2506.06941
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [46]
-
[47]
2009.Card Sorting: Designing Usable Categories
Donna Spencer. 2009.Card Sorting: Designing Usable Categories. Rosenfeld Media, New York, NY, USA
2009
-
[48]
Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Shoeb, Abubakar Abid, Adam Fisch, Adam R Brown, Adam Santoro, Aditya Gupta, Adri Garriga-Alonso, et al. 2023. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. arXiv preprint arXiv:2206.04615
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. 2018. GLUE: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv:1804.07461
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[50]
Joe H Ward Jr. 1963. Hierarchical grouping to optimize an objective function.Journal of the American statistical association58, 301 (1963), 236–244
1963
-
[51]
Jason Wei. 2025. Asymmetry of Verification and Verifier’s Law. https://www.jasonwei.net/blog/asymmetry-of- verification-and-verifiers-law
2025
-
[52]
David Gray Widder, Michael Hilton, Christian Kästner, and Bogdan Vasilescu. 2019. A conceptual replication of continuous integration pain points in the context of Travis CI. InProceedings of the 2019 27th acm joint meeting on european software engineering conference and symposium on the foundations of software engineering. ACM, New York, NY, USA, 647–658
2019
-
[53]
Shijie Xia, Xuefeng Li, Yixin Liu, Tongshuang Wu, and Pengfei Liu. 2025. Evaluating mathematical reasoning beyond accuracy. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. AAAI Press, Menlo Park, CA, USA, 27723–27730
2025
-
[54]
Cheng Xu, Shuhao Guan, Derek Greene, M Kechadi, et al. 2024. Benchmark data contamination of large language models: A survey. arXiv preprint arXiv:2406.04244
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [55]
-
[56]
Shunyu Yao. 2024. The Second Half. https://ysymyth.github.io/The-Second-Half
2024
-
[57]
Kun Zhang, Le Wu, Kui Yu, Guangyi Lv, and Dacao Zhang. 2025. Evaluating and Improving Robustness in Large Language Models: A Survey and Future Directions. arXiv preprint arXiv:2506.11111. ACM Trans. Softw. Eng. Methodol., Vol. 1, No. 1, Article . Publication date: May 2026. Towards Evaluation Engineering: An Empirical Study of ML Evaluation Harnesses in t...
-
[58]
Mengshi Zhang, Yuqun Zhang, Lingming Zhang, Cong Liu, and Sarfraz Khurshid. 2018. DeepRoad: GAN-based metamorphic testing and input validation framework for autonomous driving systems. InProceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering (ASE 2018). ACM, Montpellier, France, 132–142. doi:10.1145/3238147.3238187
-
[59]
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. 2023. A survey of large language models. arXiv preprint arXiv:2303.18223
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[60]
Zhimin Zhao. 2024. Foundation Model Leaderboard Survey. https://github.com/zhimin-z/Foundation-Model- Leaderboard-Survey
2024
-
[61]
Zhimin Zhao. 2026. Why Code, Why Now: Learnability, Computability, and the Real Limits of Machine Learning. arXiv preprint arXiv:2602.13934
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[62]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems36 (2023), 46595–46623
2023
-
[63]
Zixuan Zhou, Xuefei Ning, Ke Hong, Tianyu Fu, Jiaming Xu, Shiyao Li, Yuming Lou, Luning Wang, Zhihang Yuan, Xiuhong Li, et al. 2024. A survey on efficient inference for large language models. arXiv preprint arXiv:2404.14294
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[64]
Jingming Zhuo, Songyang Zhang, Xinyu Fang, Haodong Duan, Dahua Lin, and Kai Chen. 2024. ProSA: Assessing and Understanding the Prompt Sensitivity of LLMs. InFindings of the Association for Computational Linguistics: EMNLP 2024. Association for Computational Linguistics, Miami, Florida, USA, 1950–1976. doi:10.18653/v1/2024.findings-emnlp.108 2.0 1.5 1.0 0....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.