FoodMonitor: Benchmarking MLLMs for Explainable Compliance Analysis
Pith reviewed 2026-06-30 13:48 UTC · model grok-4.3
The pith
A benchmark for kitchen surveillance videos shows state-of-the-art multimodal models reach only 0.360 on explainable compliance analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
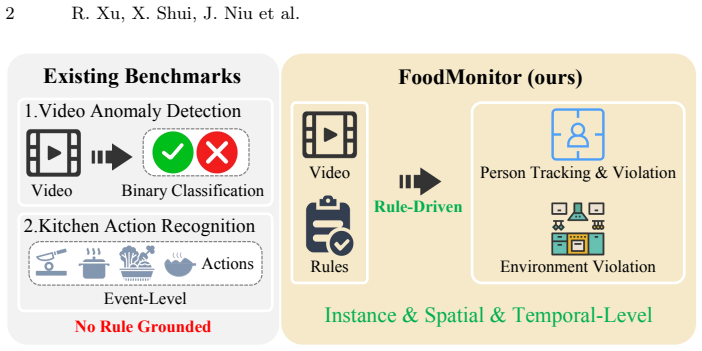
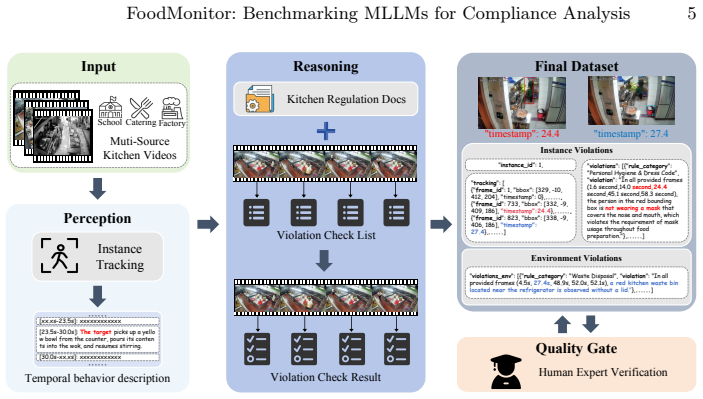
FoodMonitor comprises 477 video clips and 3,307 violation annotations that record the violated rule, the non-compliant action, the responsible party, and bounding boxes at the frame level. The benchmark uses a dual-channel structure for person and environment violations together with a two-stage matching mechanism that isolates spatial localization from semantic understanding; these are aggregated into the composite C_score. Systematic tests of leading multimodal models produce a maximum C_score of 0.360, with the dominant error types being localization-dominated and semantics-dominated failures.
What carries the argument
The two-stage matching mechanism that scores spatial localization and semantic rule understanding separately before combining them into the C_score metric.
If this is right
- Spatial localization must improve before multimodal models can reliably support compliance tasks.
- Fine-grained rule understanding remains a separate bottleneck from localization.
- Two identifiable failure modes supply concrete targets for model development.
- Explainable compliance systems will require advances in both vision grounding and regulatory semantics.
Where Pith is reading between the lines
- The same benchmark structure could be reused for other regulated environments such as construction sites or food-processing lines.
- Models that reduce one failure mode may still need separate training to reduce the other.
- Low absolute scores imply that current systems would still require human review for high-stakes decisions.
- Adding explicit rule-text inputs at inference time might raise C_score without retraining.
Load-bearing premise
The dual-channel design, violation annotations, and two-stage matching mechanism accurately reflect the requirements for explainable compliance analysis in real public governance and industrial safety scenarios.
What would settle it
Running the same models on fresh, unlabeled commercial-kitchen footage and checking whether higher C_score on FoodMonitor predicts more accurate human-verified violation explanations.
Figures

read the original abstract
As AI-powered compliance monitoring becomes increasingly important in public governance and industrial safety, the ability to provide verifiable evidence and traceable accountability signals is essential. However, existing video anomaly detection datasets focus on event-level binary classification, lacking the rule-driven, explainable analysis required for real-world compliance scenarios. We introduce FoodMonitor, a benchmark for explainable compliance analysis in commercial kitchen surveillance. FoodMonitor comprises 477 video clips with 3,307 violation annotations across a dual-channel design covering both person-level and environment-level violations. Each annotation specifies which rule was violated, what non-compliant behavior occurred, and who committed it with frame-level bounding boxes. We establish a unified evaluation protocol with a two-stage matching mechanism that separately assesses spatial localization and semantic understanding, along with a composite metric ($C_{\text{score}}$) that balances environment and person detection performance. Systematic evaluation of several state-of-the-art multimodal large language models reveals that the best-performing model achieves only 0.360 $C_{\text{score}}$, with spatial localization and fine-grained rule understanding emerging as the primary bottlenecks. Our analysis identifies two distinct failure modes: localization-dominated errors and semantics-dominated errors, providing diagnostic insights for future model development.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FoodMonitor, a benchmark for explainable compliance analysis in commercial kitchen surveillance videos. It comprises 477 video clips with 3,307 frame-level violation annotations in a dual-channel design (person-level and environment-level), each specifying the violated rule, non-compliant behavior, and perpetrator with bounding boxes. The authors define a two-stage matching mechanism and composite C_score metric, then evaluate several state-of-the-art MLLMs, reporting that the best model reaches only 0.360 C_score with spatial localization and fine-grained rule understanding as primary bottlenecks.
Significance. If the benchmark is shown to be reliable and representative, the work would provide a useful diagnostic dataset and protocol for assessing MLLM limitations in safety-critical explainable analysis, potentially informing targeted improvements in localization and semantic reasoning for compliance tasks.
major comments (2)
- [Abstract] Abstract: the description of benchmark construction and model results provides no details on the annotation process, inter-annotator agreement, or data splits. The central performance claims (best model at 0.360 C_score and identified failure modes) rest directly on the quality and fidelity of these 3,307 annotations, making the omission load-bearing.
- [Abstract] Abstract: the claim that the dual-channel videos, violation annotations, and two-stage matching mechanism 'accurately reflect the requirements for explainable compliance analysis needed in real public governance and industrial safety scenarios' is presented without external validation (e.g., expert inter-rater agreement with food-safety inspectors or alignment to official violation codes). If the annotations diverge from operational standards, the reported bottlenecks are benchmark-specific rather than diagnostic of MLLM capability.
minor comments (1)
- [Abstract] Abstract: the composite metric is denoted C_score without an explicit equation or weighting formula; the full manuscript should include the precise definition of C_score and how it balances environment and person detection.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the importance of transparency in benchmark construction and validation. We address each major comment below and outline planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the description of benchmark construction and model results provides no details on the annotation process, inter-annotator agreement, or data splits. The central performance claims (best model at 0.360 C_score and identified failure modes) rest directly on the quality and fidelity of these 3,307 annotations, making the omission load-bearing.
Authors: The abstract is space-constrained, but the full manuscript details the annotation process (Section 3), including annotator training, dual-channel protocol, inter-annotator agreement (Cohen's kappa of 0.82 for rule identification), and 70/15/15 splits. We will revise the abstract to briefly reference these quality controls and data partitioning to better ground the performance claims. revision: yes
-
Referee: [Abstract] Abstract: the claim that the dual-channel videos, violation annotations, and two-stage matching mechanism 'accurately reflect the requirements for explainable compliance analysis needed in real public governance and industrial safety scenarios' is presented without external validation (e.g., expert inter-rater agreement with food-safety inspectors or alignment to official violation codes). If the annotations diverge from operational standards, the reported bottlenecks are benchmark-specific rather than diagnostic of MLLM capability.
Authors: Violation rules are derived from official food safety regulations, with annotation guidelines developed using domain expertise. We did not conduct a separate formal validation with practicing inspectors. We will revise the paper to cite the specific regulatory sources, add an explicit limitations paragraph on the lack of direct inspector inter-rater validation, and frame the benchmark as a proxy rather than a perfect operational replica. revision: partial
Circularity Check
No significant circularity
full rationale
The paper is an empirical benchmark introduction and model evaluation study. It defines FoodMonitor, its annotations, dual-channel design, two-stage matching, and C_score metric internally, then reports measured performance of external MLLMs against that benchmark. No derivations, fitted parameters renamed as predictions, self-citation chains, or ansatzes appear in the provided text or abstract. The central claim (best model at 0.360 C_score with identified bottlenecks) is a direct empirical measurement, not a reduction to the paper's own inputs by construction. This is the normal non-circular outcome for a new-benchmark evaluation paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: CVPR
Acsintoae, A., Florescu, A., Georgescu, M.I., Mare, T., Sumedrea, P., Ionescu, R.T., Khan, F.S., Shah, M.: Ubnormal: New benchmark for supervised open-set video anomaly detection. In: CVPR. pp. 20111–20121 (2022)
2022
-
[2]
Bai, S., Cai, Y., Chen, R., Chen, K., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
ByteDance Seed: Seed2.0 model card: Towards intelligence frontier for real-world complexity (2026),https://seed.bytedance.com/en/blog/seed2- 0- release, official release page
2026
-
[5]
In: ECCV
Damen, D., Doughty, H., Farinella, G.M., Fidler, S., Furnari, A., Kazakos, E., Moltisanti, D., Munro, J., Perrett, T., Price, W., Wray, M.: Scaling egocentric vision: The epic-kitchens dataset. In: ECCV. pp. 753–771 (2018)
2018
-
[6]
IJCV130(1), 33–55 (2022).https://doi.org/10.1007/s11263-021-01531-2
Damen, D., Doughty, H., Farinella, G.M., Furnari, A., Kazakos, E., Ma, J., Molti- santi, D., Munro, J., Perrett, T., Price, W., Wray, M.: Rescaling egocentric vi- sion: Collection, pipeline and challenges for epic-kitchens-100. IJCV130(1), 33–55 (2022).https://doi.org/10.1007/s11263-021-01531-2
-
[7]
In: CVPR
Feng, J.C., Hong, F.T., Zheng, W.S.: Mist: Multiple instance self-training frame- work for video anomaly detection. In: CVPR. pp. 14009–14018 (2021)
2021
-
[8]
Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models
Fu, C., Dai, Y., Luo, Y., Li, L., Ren, S., Zhang, R., Wang, Z., Zhou, C., Shen, Y., Zhang, M., et al.: Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. In: CVPR. pp. 24108–24118 (2025).https: //doi.org/10.1109/CVPR52734.2025.02245
-
[9]
Gemini Team: Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025),https://arxiv.org/abs/2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Google: Gemini: A family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Google: Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
GLM-V Team, Hong, W., Yu, W., Gu, X., Wang, G., et al.: Glm-4.5v and glm- 4.1v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning. arXiv preprint arXiv:2507.01006 (2025),https://arxiv.org/abs/2507. 01006
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
In: ICCV
Gong, D., Liu, L., Le, V., Saha, B., Mansour, M.R., Venkatesh, S., Van Den Hen- gel, A.: Memorizing normality to detect anomaly: Memory-augmented deep au- toencoder for unsupervised anomaly detection. In: ICCV. pp. 1705–1714 (2019)
2019
-
[14]
In: CVPR
Grauman, K., Westbury, A., Byrne, E., et al.: Ego4d: Around the world in 3,000 hours of egocentric video. In: CVPR. pp. 18995–19012 (2022)
2022
-
[15]
In: CVPR
Hasan, M., Choi, J., Neumann, J., Roy-Chowdhury, A.K., Davis, L.S.: Learning temporal regularity in video sequences. In: CVPR. pp. 733–742 (2016)
2016
-
[16]
International Organization for Standardization: Iso 22000:2018 food safety man- agement systems – requirements for any organization in the food chain. Tech. rep., ISO (2018)
2018
-
[17]
Kimi K2.5: Visual Agentic Intelligence
Kimi Team: Kimi k2.5: Visual agentic intelligence. arXiv preprint arXiv:2602.02276 (2026),https://arxiv.org/abs/2602.02276 16 R. Xu, X. Shui, J. Niu et al
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
In: CVPR
Li, F., Liu, W., Chen, J., Zhang, R., Wang, Y., Zhong, X., Wang, Z.: Anomize: Bet- ter open vocabulary video anomaly detection. In: CVPR. pp. 29203–29212 (2025)
2025
-
[19]
In: CVPR
Li, K., Wang, Y., He, Y., Li, Y., Wang, Y., Liu, Y., Wang, Z., Xu, J., Chen, G., Luo, P., Wang, L., Qiao, Y.: Mvbench: A comprehensive multi-modal video understanding benchmark. In: CVPR. pp. 22195–22206 (2024)
2024
-
[20]
In: CVPR
Lv, H., Yue, Z., Sun, Q., Luo, B., Cui, Z., Zhang, H.: Unbiased multiple instance learning for weakly supervised video anomaly detection. In: CVPR. pp. 8022–8031 (2023)
2023
-
[21]
In: NeurIPS (2023)
Mangalam, K., Akshulakov, R., Malik, J.: Egoschema: A diagnostic benchmark for very long-form video language understanding. In: NeurIPS (2023)
2023
-
[22]
Journal of Food Protection61(9), 1246–1259 (1998).https://doi.org/10.4315/0362-028X- 61.9.1246
National Advisory Committee on Microbiological Criteria for Foods: Hazard anal- ysis and critical control point principles and application guidelines. Journal of Food Protection61(9), 1246–1259 (1998).https://doi.org/10.4315/0362-028X- 61.9.1246
-
[23]
In: CVPR
Park, H., Noh, J., Ham, B.: Learning memory-guided normality for anomaly de- tection. In: CVPR. pp. 14372–14381 (2020)
2020
-
[24]
In: WACV
Ramachandra, B., Jones, M.J.: Street scene: A new dataset and evaluation protocol for video anomaly detection. In: WACV. pp. 2569–2578 (2020)
2020
-
[25]
In: CVPR
Sener, F., Chatterjee, D., Shelepov, D., He, K., Singhania, D., Wang, R., Yao, A.: Assembly101: A large-scale multi-view video dataset for understanding procedural activities. In: CVPR. pp. 21096–21106 (2022)
2022
-
[26]
In: ACM Int
Stein, S., McKenna, S.J.: Combining embedded accelerometers with computer vi- sion for recognizing food preparation activities. In: ACM Int. Joint Conf. Pervasive Ubiquitous Comput. pp. 729–738 (2013)
2013
-
[27]
In: CVPR
Sultani, W., Chen, C., Shah, M.: Real-world anomaly detection in surveillance videos. In: CVPR. pp. 6479–6488 (2018)
2018
-
[28]
In: CVPR
Tang, Y., Ding, D., Rao, Y., Zheng, Y., Zhang, D., Zhao, L., Lu, J., Zhou, J.: Coin: A large-scale dataset for comprehensive instructional video analysis. In: CVPR. pp. 1207–1216 (2019)
2019
-
[29]
In: ICCV
Tian, Y., Pang, G., Chen, Y., Singh, R., Verjans, J.W., Carneiro, G.: Weakly- supervised video anomaly detection with robust temporal feature magnitude learn- ing. In: ICCV. pp. 4975–4986 (2021)
2021
-
[30]
In: ECCV
Wu, P., Liu, J., Shi, Y., Sun, Y., Shao, F., Wu, Z., Yang, Z.: Not only look, but also listen: Learning multimodal violence detection under weak supervision. In: ECCV. pp. 322–339 (2020)
2020
-
[31]
In: CVPR
Wu, P., Zhou, X., Pang, G., Sun, Y., Liu, J., Wang, P., Zhang, Y.: Open-vocabulary video anomaly detection. In: CVPR. pp. 18297–18307 (2024)
2024
-
[32]
In: AAAI
Wu, P., Zhou, X., Pang, G., Zhou, L., Yan, Q., Wang, P., Zhang, Y.: Vadclip: Adapting vision-language models for weakly supervised video anomaly detection. In: AAAI. vol. 38, pp. 6074–6082 (2024)
2024
-
[33]
MiMo-VL Technical Report.arXiv preprint arXiv:2506.03569, 2025
Xiaomi LLM-Core Team: Mimo-vl technical report. arXiv preprint arXiv:2506.03569 (2025),https://arxiv.org/abs/2506.03569
-
[34]
In: AAAI
Yang, M., Han, G., Yan, B., Zhang, W., Qi, J., Lu, H., Wang, D.: Hybrid-sort: Weak cues matter for online multi-object tracking. In: AAAI. vol. 38, pp. 6504– 6512 (2024)
2024
-
[35]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yang, Z., Wang, J., Tang, Y., Chen, K., Zhao, H., Torr, P.H.: Lavt: Language- aware vision transformer for referring image segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18155– 18165 (2022)
2022
-
[36]
In: CVPR
Yang, Z., Liu, J., Wu, P.: Text prompt with normality guidance for weakly super- vised video anomaly detection. In: CVPR. pp. 18899–18908 (2024) FoodMonitor: Benchmarking MLLMs for Compliance Analysis 17
2024
-
[37]
In: AAAI
Yu, Z., Xu, D., Yu, J., Yu, T., Zhao, Z., Zhuang, Y., Tao, D.: Activitynet-qa: A dataset for understanding complex web videos via question answering. In: AAAI. pp. 9127–9134 (2019)
2019
-
[38]
Zhipu AI: Glm-4.6v (2025),https://docs.z.ai/guides/vlm/glm-4.6v, official documentation page
2025
-
[39]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Zhu, J., et al.: Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.