{Φ}-Noise: Training-Free Temporal Video Conditioning via Phase-Based Noise Manipulation
Pith reviewed 2026-06-30 13:40 UTC · model grok-4.3
The pith
Injecting low-frequency phase from a reference video into diffusion noise enables training-free motion control in video generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
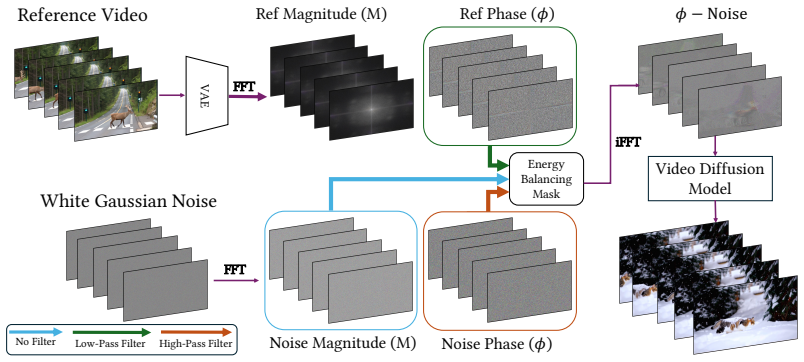
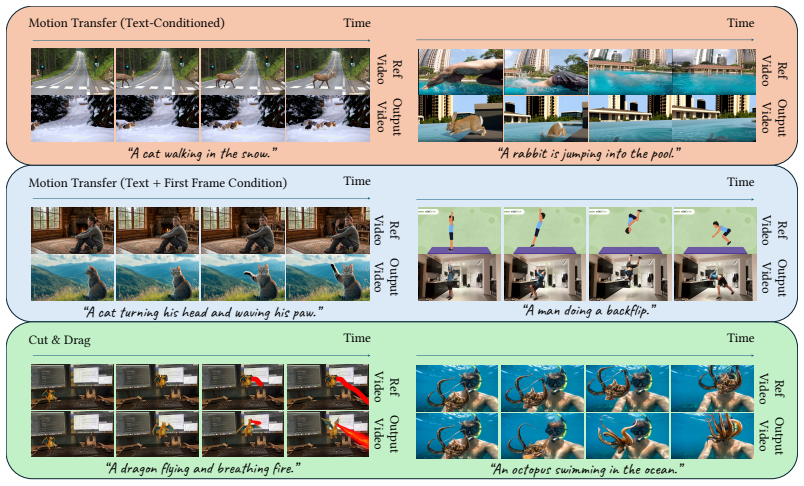
Injecting low-frequency phase information from a reference video directly into the diffusion noise latents transfers motion cues to the generated video, achieving effective control over both appearance and dynamics while requiring no changes to the model architecture or inference pipeline.
What carries the argument
Φ-Noise: the replacement of low-frequency phase components in the initial diffusion noise latents with the corresponding phase extracted from a reference video's latent representation.
If this is right
- The same diffusion model can produce videos whose dynamics match a chosen reference while appearance follows a separate text or image condition.
- No retraining or architectural modification is needed to add motion conditioning to existing latent video diffusion pipelines.
- The approach yields results competitive with or better than methods that require additional training or overhead.
- Multiple applications become possible by swapping different reference videos to control temporal behavior.
Where Pith is reading between the lines
- The same phase-injection step could be tested on non-video diffusion tasks where temporal or structural consistency matters.
- Varying which frequency bands are copied might isolate which components primarily carry motion versus static content.
- Real-time editing workflows could adopt this as a lightweight way to animate still images or short clips.
- If phase carries the bulk of the motion signal, similar manipulations might simplify conditioning in other generative architectures.
Load-bearing premise
Low-frequency phase taken from a reference video can be inserted into the diffusion noise latents to copy motion cues without altering appearance or requiring any model change or training.
What would settle it
Generate paired videos with and without the phase injection using the same prompt and seed; if motion similarity to the reference does not increase while appearance similarity metrics stay comparable, the claim fails.
Figures


















read the original abstract
Latent video diffusion models generate videos by progressively transforming Gaussian noise into realistic samples conditioned on text or visual inputs. However, existing conditioning methods often require additional training and computational overhead. Motivated by recent findings on the importance of frequency components in generative models, we propose a simple, training-free approach for motion-conditioned video generation by injecting low-frequency phase information from a reference video directly into the diffusion noise latents. Our method transfers motion cues without modifying the model architecture or inference pipeline. Using several applications, we demonstrate effective control over both appearance and dynamics in generated videos, while achieving competitive or superior results compared to more complex conditioning approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Φ-Noise, a training-free method for motion-conditioned video generation in latent video diffusion models. It extracts low-frequency phase information from a reference video and injects it directly into the diffusion noise latents to transfer motion cues, without modifying the model architecture, inference pipeline, or requiring additional training. The approach is evaluated on several applications demonstrating control over appearance and dynamics, with results claimed to be competitive or superior to more complex conditioning methods.
Significance. If the central claim holds, the result would be significant for video generation research by offering a lightweight, training-free conditioning mechanism that exploits frequency-domain properties. This could lower barriers to motion control in diffusion models and reduce reliance on architectural changes or fine-tuning. The direct phase-injection approach is a strength if it cleanly separates motion from appearance without side effects.
major comments (3)
- [§3] §3 (Method): The phase extraction and injection procedure is described at a high level but lacks the explicit equations for computing the low-frequency phase mask and its application to the noise latent; without these, it is impossible to verify that the operation preserves the required statistical properties of the diffusion noise.
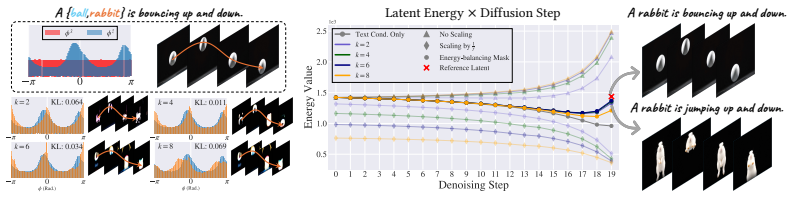
- [§4] §4 (Experiments): No quantitative ablation is reported on the choice of frequency cutoff for the low-frequency band; the claim that motion transfers while appearance remains unaffected therefore rests on untested hyperparameter sensitivity.
- [Table 2] Table 2 (comparison results): The reported metrics show only marginal gains over baselines; the paper does not include statistical significance tests or variance across multiple seeds, weakening the claim of competitive or superior performance.
minor comments (2)
- The abstract and introduction use the term 'phase information' without first defining the Fourier transform convention or the exact frequency range considered low-frequency.
- Figure 3 caption does not specify the exact reference video used or the diffusion timestep at which injection occurs.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our manuscript. We address each major comment below and will make the necessary revisions to strengthen the paper.
read point-by-point responses
-
Referee: [§3] §3 (Method): The phase extraction and injection procedure is described at a high level but lacks the explicit equations for computing the low-frequency phase mask and its application to the noise latent; without these, it is impossible to verify that the operation preserves the required statistical properties of the diffusion noise.
Authors: We agree that providing explicit equations is essential for reproducibility and verification. In the revised manuscript, we will add the detailed mathematical expressions for extracting the low-frequency phase using the Fourier transform and injecting it into the diffusion noise latents. This will also include a brief analysis showing that the phase manipulation preserves the necessary statistical properties of the Gaussian noise. revision: yes
-
Referee: [§4] §4 (Experiments): No quantitative ablation is reported on the choice of frequency cutoff for the low-frequency band; the claim that motion transfers while appearance remains unaffected therefore rests on untested hyperparameter sensitivity.
Authors: We appreciate this suggestion. While our current experiments include qualitative demonstrations across different cutoffs, we will add a quantitative ablation study on the frequency cutoff parameter in the revised version to empirically validate the robustness of the method and support the claims regarding motion transfer and appearance preservation. revision: yes
-
Referee: [Table 2] Table 2 (comparison results): The reported metrics show only marginal gains over baselines; the paper does not include statistical significance tests or variance across multiple seeds, weakening the claim of competitive or superior performance.
Authors: The gains, though marginal in some cases, are consistent and meaningful in the context of training-free methods. To address this, we will update Table 2 to include variance across multiple seeds and conduct statistical significance tests (e.g., paired t-tests) to provide stronger evidence for the performance claims. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes a direct, training-free manipulation that injects low-frequency phase from a reference video into diffusion noise latents. No equations, fitted parameters, or self-citation chains are shown that would reduce the central claim to its own inputs by construction. The approach is presented as an explicit procedural step rather than a derived prediction, leaving the result self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Low-frequency phase components of a video latent carry the dominant motion information that can be transferred to a new generation without side effects on appearance.
Reference graph
Works this paper leans on
-
[1]
Diffuhaul: A training-free method for object dragging in images
Omri Avrahami, Rinon Gal, Gal Chechik, Ohad Fried, Dani Lischinski, Arash Vahdat, and Weili Nie. Diffuhaul: A training-free method for object dragging in images. InSIGGRAPH Asia 2024 Conference Papers, SA ’24, New York, NY , USA, 2024. Association for Computing Machinery. ISBN 9798400711312. doi: 10.1145/3680528.3687590. URL https://doi.org/ 10.1145/36805...
-
[2]
Lumiere: A space-time diffusion model for video generation
Omer Bar-Tal, Hila Chefer, Omer Tov, Charles Herrmann, Roni Paiss, Shiran Zada, Ariel Ephrat, Junhwa Hur, Guanghui Liu, Amit Raj, Yuanzhen Li, Michael Rubinstein, Tomer Michaeli, Oliver Wang, Deqing Sun, Tali Dekel, and Inbar Mosseri. Lumiere: A space-time diffusion model for video generation. InSIGGRAPH Asia 2024 Conference Papers, SA ’24, New York, NY ,...
-
[3]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Do- minik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, Varun Jampani, and Robin Rombach. Stable video diffusion: Scaling latent video diffusion models to large datasets, 2023. URLhttps://arxiv.org/abs/2311.15127
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Align your latents: High-resolution video synthesis with latent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[5]
Go-with-the-flow: Motion-controllable video diffusion models using real-time warped noise
Ryan Burgert, Yuancheng Xu, Wenqi Xian, Oliver Pilarski, Pascal Clausen, Mingming He, Li Ma, Yitong Deng, Lingxiao Li, Mohsen Mousavi, Michael Ryoo, Paul Debevec, and Ning Yu. Go-with-the-flow: Motion-controllable video diffusion models using real-time warped noise. In Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 13–...
2025
-
[6]
Pascal Chang, Jingwei Tang, Markus Gross, and Vinicius C. Azevedo. How i warped your noise: a temporally-correlated noise prior for diffusion models. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum? id=pzElnMrgSD
2024
-
[7]
Videocrafter2: Overcoming data limitations for high-quality video diffusion models, 2024
Haoxin Chen, Yong Zhang, Xiaodong Cun, Menghan Xia, Xintao Wang, Chao Weng, and Ying Shan. Videocrafter2: Overcoming data limitations for high-quality video diffusion models, 2024
2024
-
[8]
Control-a-video: Controllable text-to-video generation with diffusion models, 2023
Weifeng Chen, Jie Wu, Pan Xie, Hefeng Wu, Jiashi Li, Xin Xia, Xuefeng Xiao, and Liang Lin. Control-a-video: Controllable text-to-video generation with diffusion models, 2023
2023
-
[9]
Cohen, Oron Nir, and Ariel Shamir
Nadav Z. Cohen, Oron Nir, and Ariel Shamir. Conditional balance: Improving multi- conditioning trade-offs in image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2641–2650, June 2025
2025
-
[10]
Nadav Z. Cohen, Ofir Abramovich, and Ariel Shamir. Colorful-Noise: Training-Free Low- Frequency Noise Manipulation for Color-Based Conditional Image Generation.arXiv e-prints, art. arXiv:2605.00548, May 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Yitong Deng, Winnie Lin, Lingxiao Li, Dmitriy Smirnov, Ryan D Burgert, Ning Yu, Vincent Dedun, and Mohammad H. Taghavi. Infinite-resolution integral noise warping for diffusion models. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=Y6LPWBo2HP
2025
-
[12]
Dragvideo: Interactive drag-style video editing.arXiv preprint arXiv:2312.02216, 2023
Yufan Deng, Ruida Wang, Yuhao Zhang, Yu-Wing Tai, and Chi-Keung Tang. Dragvideo: Interactive drag-style video editing.arXiv preprint arXiv:2312.02216, 2023
-
[13]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis. InProceedings of the 41st International Conference on Machine Learning, ICML...
2024
-
[14]
Implicit style-content separation using b-lora, 2024
Yarden Frenkel, Yael Vinker, Ariel Shamir, and Daniel Cohen-Or. Implicit style-content separation using b-lora, 2024
2024
-
[15]
Daniel Geng, Charles Herrmann, Junhwa Hur, Forrester Cole, Serena Zhang, Tobias Pfaff, Tatiana Lopez-Guevara, Carl Doersch, Yusuf Aytar, Michael Rubinstein, Chen Sun, Oliver Wang, Andrew Owens, and Deqing Sun. Motion prompting: Controlling video generation with motion trajectories, 2025. URLhttps://arxiv.org/abs/2412.02700
-
[16]
TokenFlow: Consistent Diffusion Features for Consistent Video Editing
Michal Geyer, Omer Bar-Tal, Shai Bagon, and Tali Dekel. Tokenflow: Consistent diffusion features for consistent video editing.arXiv preprint arxiv:2307.10373, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Animatediff: Animate your personalized text-to-image diffu- sion models without specific tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to-image diffu- sion models without specific tuning. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[18]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richard- son, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, Poriya Panet, Sapir Weissbuch, Victor Kulikov, Yaki Bitterman, Zeev Melumian, and Ofir Bibi. Ltx-video: Realtime video latent diffusion, 2024. URLhttps://arxiv.org/abs/2501.00103
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Cameractrl: Enabling camera control for text-to-video generation, 2024
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for text-to-video generation, 2024
2024
-
[20]
Latent video diffusion models for high-fidelity long video generation, 2023
Yingqing He, Tianyu Yang, Yong Zhang, Ying Shan, and Qifeng Chen. Latent video diffusion models for high-fidelity long video generation, 2023. URL https://arxiv.org/abs/2211. 13221
2023
-
[21]
Style aligned image generation via shared attention
Amir Hertz, Andrey V oynov, Shlomi Fruchter, and Daniel Cohen-Or. Style aligned image generation via shared attention. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4775–4785, June 2024
2024
-
[22]
Imagen Video: High Definition Video Generation with Diffusion Models
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P. Kingma, Ben Poole, Mohammad Norouzi, David J. Fleet, and Tim Salimans. Imagen video: High definition video generation with diffusion models, 2022. URL https: //arxiv.org/abs/2210.02303
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models.arXiv:2204.03458, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
Animate anyone: Consistent and controllable image-to-video synthesis for character animation
Li Hu. Animate anyone: Consistent and controllable image-to-video synthesis for character animation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8153–8163, June 2024
2024
-
[25]
Videocontrolnet: A motion-guided video-to-video translation frame- work by using diffusion model with controlnet, 2023
Zhihao Hu and Dong Xu. Videocontrolnet: A motion-guided video-to-video translation frame- work by using diffusion model with controlnet, 2023. URL https://arxiv.org/abs/2307. 14073
2023
-
[26]
Blue noise for diffusion models
Xingchang Huang, Corentin Salaun, Cristina Vasconcelos, Christian Theobalt, Cengiz Oztireli, and Gurprit Singh. Blue noise for diffusion models. InACM SIGGRAPH 2024 Conference Papers, SIGGRAPH ’24, New York, NY , USA, 2024. Association for Computing Machinery. ISBN 9798400705250. doi: 10.1145/3641519.3657435. URL https://doi.org/10.1145/ 3641519.3657435
-
[27]
Text2video-zero: Text-to-image diffusion models are zero-shot video generators
Levon Khachatryan, Andranik Movsisyan, Vahram Tadevosyan, Roberto Henschel, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. Text2video-zero: Text-to-image diffusion models are zero-shot video generators. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 15954–15964, October 2023
2023
-
[28]
Onlyflow: Optical flow based motion conditioning for video diffusion models
Mathis Koroglu, Hugo Caselles-Dupré, Guillaume Jeanneret, and Matthieu Cord. Onlyflow: Optical flow based motion conditioning for video diffusion models. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), page 6216–6226. IEEE, 2025. doi: 10.1109/cvprw67362.2025.00619. URL http://dx.doi.org/10.1109/ CVPRW67362.2025.00619. 12
-
[29]
Flux.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024
2024
-
[30]
Motionclone: Training-free motion cloning for controllable video generation
Pengyang Ling, Jiazi Bu, Pan Zhang, Xiaoyi Dong, Yuhang Zang, Tong Wu, Huaian Chen, Jiaqi Wang, and Yi Jin. Motionclone: Training-free motion cloning for controllable video generation. arXiv preprint arXiv:2406.05338, 2024
-
[31]
SDEdit: Guided image synthesis and editing with stochastic differential equations
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. SDEdit: Guided image synthesis and editing with stochastic differential equations. In International Conference on Learning Representations, 2022
2022
-
[32]
Chong Mou, Xintao Wang, Jiechong Song, Ying Shan, and Jian Zhang. Dragondiffusion: Enabling drag-style manipulation on diffusion models.arXiv preprint arXiv:2307.02421, 2023
-
[33]
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, and Ying Shan. T2i-adapter: learning adapters to dig out more controllable ability for text-to-image diffusion models. InProceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and F...
-
[34]
Sora: Creating video from text
OpenAI. Sora: Creating video from text. https://openai.com/sora, 2024. Accessed: 2026-05-02
2024
-
[35]
Richter, Christopher J
Pablo Pernias, Dominic Rampas, Mats L. Richter, Christopher J. Pal, and Marc Aubreville. Wuerstchen: An efficient architecture for large-scale text-to-image diffusion models, 2023
2023
-
[36]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis, 2023. URLhttps://arxiv.org/abs/2307.01952
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
S. Pollard. On parseval’s theorem.Proceedings of the London Mathematical Society, s2-25(1): 237–246, 1926. doi: https://doi.org/10.1112/plms/s2-25.1.237. URL https://londmathsoc. onlinelibrary.wiley.com/doi/abs/10.1112/plms/s2-25.1.237
-
[38]
Video motion transfer with diffusion transformers
Alexander Pondaven, Aliaksandr Siarohin, Sergey Tulyakov, Philip Torr, and Fabio Pizzati. Video motion transfer with diffusion transformers. InCVPR, 2025
2025
-
[39]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[40]
Fds: Frequency-aware denoising score for text-guided latent diffusion image editing
Yufan Ren, Zicong Jiang, Tong Zhang, Søren Forchhammer, and Sabine Süsstrunk. Fds: Frequency-aware denoising score for text-guided latent diffusion image editing. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 2651–2660, June 2025
2025
-
[41]
Generative modelling with inverse heat dissipation, 2023
Severi Rissanen, Markus Heinonen, and Arno Solin. Generative modelling with inverse heat dissipation, 2023. URLhttps://arxiv.org/abs/2206.13397
-
[42]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, June 2022
2022
-
[43]
Tempocontrol: Temporal attention guidance for text-to-video models, 2026
Shira Schiber, Ofir Lindenbaum, and Idan Schwartz. Tempocontrol: Temporal attention guidance for text-to-video models, 2026. URLhttps://arxiv.org/abs/2510.02226
-
[44]
Yujun Shi, Chuhui Xue, Jiachun Pan, Wenqing Zhang, Vincent YF Tan, and Song Bai. Dragdif- fusion: Harnessing diffusion models for interactive point-based image editing.arXiv preprint arXiv:2306.14435, 2023. 13
-
[45]
Time-to-move: Training-free motion controlled video generation via dual-clock denoising, 2025
Assaf Singer, Noam Rotstein, Amir Mann, Ron Kimmel, and Or Litany. Time-to-move: Training-free motion controlled video generation via dual-clock denoising, 2025. URL https: //arxiv.org/abs/2511.08633
-
[46]
Make-a-video: Text-to-video generation without text-video data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, Devi Parikh, Sonal Gupta, and Yaniv Taigman. Make-a-video: Text-to-video generation without text-video data. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[47]
Score-based denoising diffusion with non-isotropic gaussian noise models, 2022
Vikram V oleti, Christopher Pal, and Adam Oberman. Score-based denoising diffusion with non-isotropic gaussian noise models, 2022. URLhttps://arxiv.org/abs/2210.12254
-
[49]
Wan: Open and Advanced Large-Scale Video Generative Models
Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Xiaofeng Meng, Ningying Zhang, Pandeng Li, Ping Wu, Ruihang Chu, Rui Feng, Shiwei Zhang, Siyang Sun, Tao Fang, Tianxing Wang...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Motion inversion for video customization, 2024
Luozhou Wang, Ziyang Mai, Guibao Shen, Yixun Liang, Xin Tao, Pengfei Wan, Di Zhang, Yijun Li, and Yingcong Chen. Motion inversion for video customization, 2024. URL https: //arxiv.org/abs/2403.20193
-
[51]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation
Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, Stan Weixian Lei, Yuchao Gu, Yufei Shi, Wynne Hsu, Ying Shan, Xiaohu Qie, and Mike Zheng Shou. Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 7623–7633, October 2023
2023
-
[53]
Cvpr 2023 text guided video editing competition, 2023
Jay Zhangjie Wu, Xiuyu Li, Difei Gao, Zhen Dong, Jinbin Bai, Aishani Singh, Xiaoyu Xiang, Youzeng Li, Zuwei Huang, Yuanxi Sun, Rui He, Feng Hu, Junhua Hu, Hai Huang, Hanyu Zhu, Xu Cheng, Jie Tang, Mike Zheng Shou, Kurt Keutzer, and Forrest Iandola. Cvpr 2023 text guided video editing competition, 2023
2023
-
[54]
Freeinit: Bridging initialization gap in video diffusion models, 2024
Tianxing Wu, Chenyang Si, Yuming Jiang, Ziqi Huang, and Ziwei Liu. Freeinit: Bridging initialization gap in video diffusion models, 2024. URL https://arxiv.org/abs/2312. 07537
2024
-
[55]
Video diffusion models are training-free motion interpreter and controller
Zeqi Xiao, Yifan Zhou, Shuai Yang, and Xingang Pan. Video diffusion models are training-free motion interpreter and controller. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URLhttps://openreview.net/forum?id=ZvQ4Bn75kN. 14
2024
-
[56]
Direct-a-video: Customized video generation with user-directed camera movement and object motion
Shiyuan Yang, Liang Hou, Haibin Huang, Chongyang Ma, Pengfei Wan, Di Zhang, Xiaodong Chen, and Jing Liao. Direct-a-video: Customized video generation with user-directed camera movement and object motion. InACM SIGGRAPH 2024 Conference Papers, SIGGRAPH ’24, New York, NY , USA, 2024. Association for Computing Machinery. ISBN 9798400705250. doi: 10.1145/3641...
-
[57]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, Da Yin, Yuxuan Zhang, Weihan Wang, Yean Cheng, Bin Xu, Xiaotao Gu, Yuxiao Dong, and Jie Tang. Cogvideox: Text-to-video diffusion models with an expert transformer, 2025. URLhttps://arxiv.org/abs/2408.06072
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Space-time diffusion features for zero-shot text-driven motion transfer
Danah Yatim, Rafail Fridman, Omer Bar-Tal, Yoni Kasten, and Tali Dekel. Space-time diffusion features for zero-shot text-driven motion transfer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8466–8476, June 2024
2024
-
[59]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models, 2023. URL https://arxiv.org/abs/ 2308.06721
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[60]
Freqprior: Improving video diffusion models with frequency filtering gaussian noise
Yunlong Yuan, Yuanfan Guo, Chunwei Wang, Wei Zhang, Hang Xu, and Li Zhang. Freqprior: Improving video diffusion models with frequency filtering gaussian noise. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[61]
Patel, Vitor Guizilini, and Rowan McAl- lister
Yu Zeng, Charles Ochoa, Mingyuan Zhou, Vishal M. Patel, Vitor Guizilini, and Rowan McAl- lister. Neuralremaster: Phase-preserving diffusion for structure-aligned generation, 2026. URL https://arxiv.org/abs/2512.05106
-
[62]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 3836–3847, October 2023
2023
-
[63]
The unreason- able effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreason- able effectiveness of deep features as a perceptual metric. InCVPR, 2018
2018
-
[64]
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Dian Zheng, Ziqi Huang, Hongbo Liu, Kai Zou, Yinan He, Fan Zhang, Yuanhan Zhang, Jingwen He, Wei-Shi Zheng, Yu Qiao, and Ziwei Liu. VBench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness.arXiv preprint arXiv:2503.21755, 2025. 15 Appendix A Derivation of the Energy-Balanced Compensation Factor To maintain spectral consistency dur...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.