MindAlign: Bridging EEG, Vision, and Language for Zero-Shot Visual Decoding
Pith reviewed 2026-06-30 14:49 UTC · model grok-4.3
The pith
A two-stage tri-modal contrastive method aligns EEG, image, and text embeddings to decode visual categories from brain signals without training examples for the target classes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
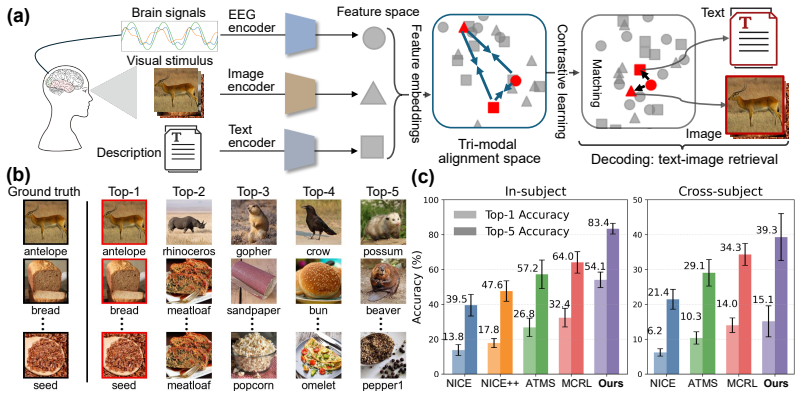
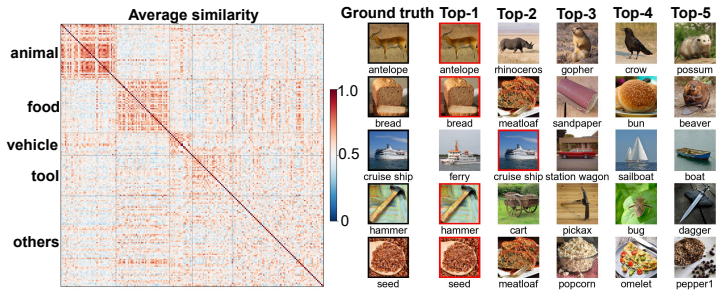
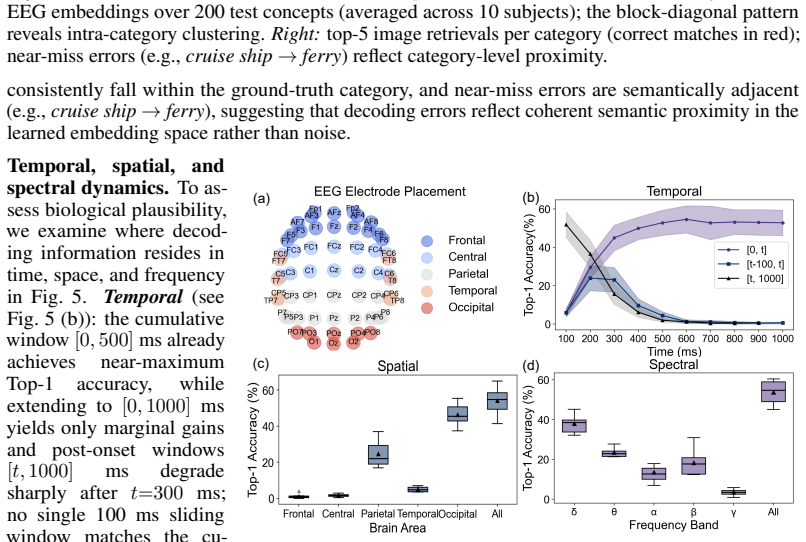
By pre-training an EEG encoder via masked reconstruction and then performing joint contrastive alignment of EEG, image, and LLM text embeddings, the method produces a latent space in which EEG signals can be matched to novel visual categories at 54.1 percent top-1 accuracy on a 200-way benchmark, exceeding prior EEG-only baselines by a wide margin while preserving neurophysiologically plausible structure.
What carries the argument
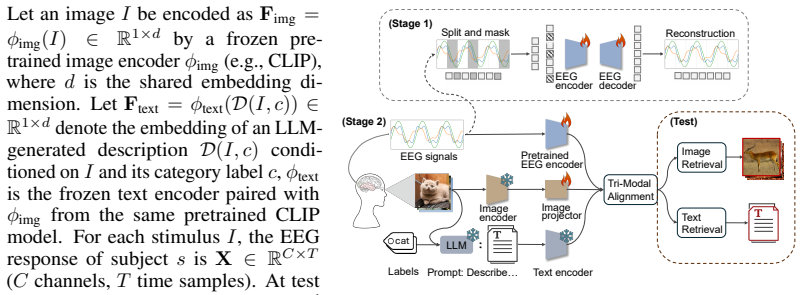
A two-stage tri-modal contrastive alignment in which an EEG encoder (graph attention plus convolutional embeddings plus subject adaptation) is first pre-trained by masked reconstruction and then jointly contrasted against image and LLM-text representations so that text supplies semantic structure while EEG-image pairing remains the primary objective.
If this is right
- EEG signals become usable for zero-shot retrieval among hundreds of object categories without per-category training data.
- The same encoder transfers to MEG recordings with comparable gains.
- Compact embedding geometries (rather than the largest available vision models) yield the strongest decoding performance.
- Decoded representations respect the temporal hierarchy of visual cortex responses.
- Subject-specific adaptation layers allow the model to maintain performance across individuals.
Where Pith is reading between the lines
- If the text regularizer proves robust across languages or description styles, the same pipeline could be applied to other non-invasive signals such as fNIRS without new labeled datasets.
- The observed superiority of compact embeddings suggests that deployment on wearable EEG hardware may be feasible without large on-device models.
- Because the method already shows alignment with known visual processing stages, targeted experiments could test whether the learned embeddings predict specific perceptual phenomena such as category typicality or viewpoint invariance.
- Extending the pre-training stage to include more unlabeled EEG corpora from clinical or consumer devices could further reduce the amount of task-specific data required.
Load-bearing premise
LLM-generated text descriptions supply a semantic regularizer that improves EEG-to-image alignment without adding noise or bias that would degrade the primary visual decoding signal.
What would settle it
An independent replication on the identical Things-EEG2 200-way split that finds no statistically significant lift above the prior 32.4 percent top-1 baseline after the same two-stage training procedure.
Figures

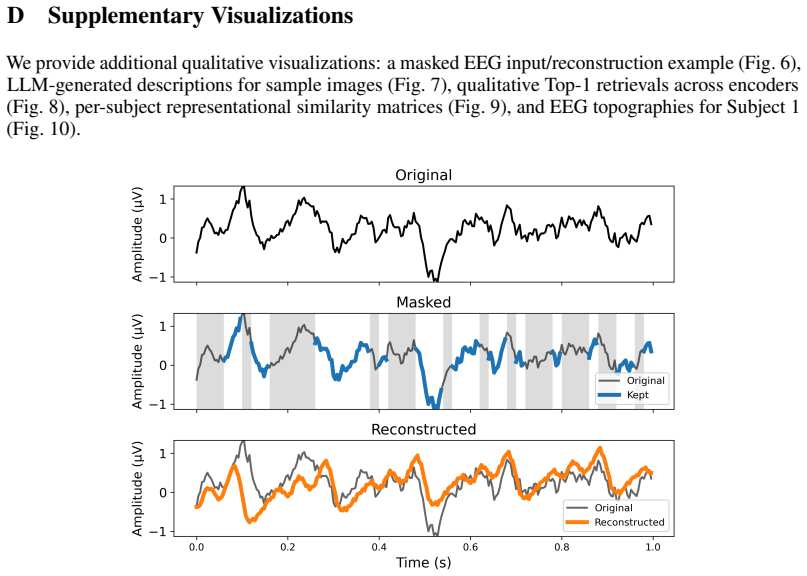


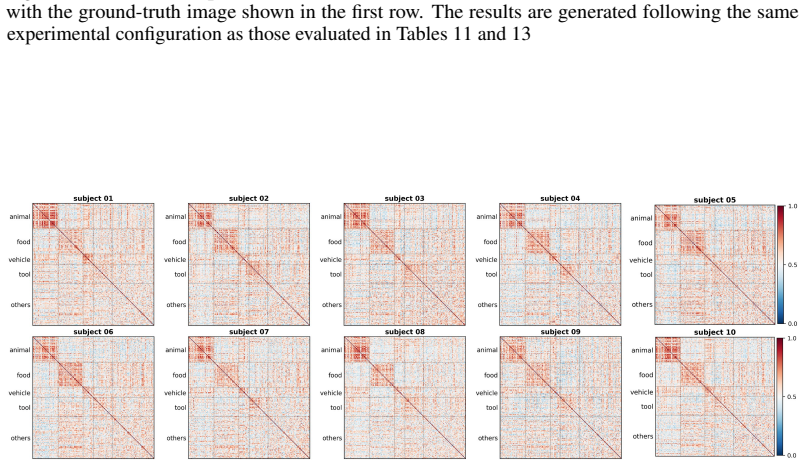
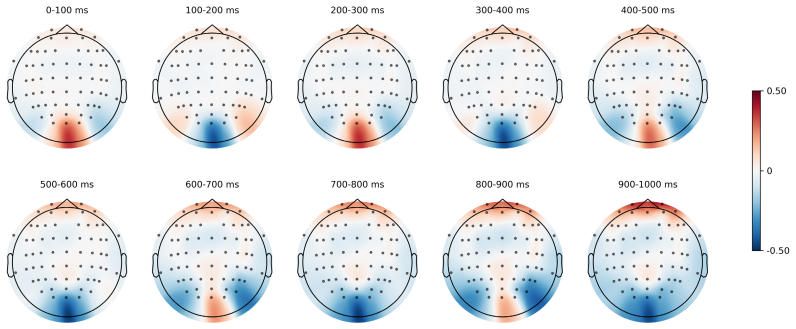
read the original abstract
Visual decoding from brain signals is a key challenge at the intersection of computer vision and neuroscience, requiring methods that bridge neural representations and computational models of vision. We introduce a tri-modal contrastive framework for EEG-based visual decoding that aligns EEG, visual, and textual representations within a unified latent space. Our approach follows a two-stage design. First, we pre-train an EEG encoder via masked reconstruction on unlabeled trials, learning spatio-temporal regularities that transfer robustly to downstream tasks. Second, we jointly align EEG, image, and LLM-generated textual descriptions through contrastive learning, where text supervision acts as a semantic regularizer that injects linguistic structure into the shared space without overwhelming the primary EEG-image signal. The encoder integrates subject-specific adaptation, graph-attention over channels, and temporal-spatial convolutional embeddings. On the Things-EEG2 200-way zero-shot benchmark, our framework achieves 54.1% Top-1 and 83.4% Top-5 accuracy, substantially exceeding the strongest prior baseline (32.4% / 64.0%), with paired Wilcoxon tests confirming significance (p < 0.01) over all in-subject baselines. We validate generalization on Things-MEG. Analysis reveals that compact embedding geometries (CN-CLIP) outperform much larger backbones, and that decoding aligns with established neurophysiology of visual processing. This work is a critical step towards robust, semantically-grounded visual decoding from non-invasive temporal neural signals. The source code is publicly available in https://github.com/anon-eeg/eeg_image_decoding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MindAlign, a tri-modal contrastive framework for zero-shot visual decoding from EEG. It employs a two-stage pipeline: (1) masked reconstruction pre-training of an EEG encoder to learn spatio-temporal features, and (2) joint contrastive alignment of EEG, image, and LLM-generated textual embeddings, with text acting as a semantic regularizer. On the Things-EEG2 200-way zero-shot benchmark the method reports 54.1% Top-1 / 83.4% Top-5 accuracy, exceeding the strongest prior baseline (32.4% / 64.0%) with paired Wilcoxon significance (p < 0.01); generalization to Things-MEG is claimed and code is released.
Significance. If the reported gains are shown to derive from EEG-visual alignment rather than linguistic artifacts, the work would mark a substantial empirical advance in non-invasive visual decoding by demonstrating that compact multimodal embeddings can substantially outperform prior EEG-only approaches while aligning with known neurophysiology. Public code release strengthens reproducibility.
major comments (2)
- [Abstract and two-stage design] Abstract / two-stage design description: the claim that LLM-generated textual descriptions 'inject linguistic structure into the shared space without overwhelming the primary EEG-image signal' is load-bearing for the 22-point accuracy improvement. No ablation that removes the text modality, varies caption sources, or blinds caption generation is reported, leaving open the possibility that class-specific correlations between generated captions and image categories (rather than EEG signal) drive the result.
- [Results (Things-EEG2)] Results section on Things-EEG2 benchmark: the paired Wilcoxon tests establish statistical significance over in-subject baselines, yet without quantitative controls (e.g., caption-only or image-only contrastive runs, or cross-LLM consistency checks) it is impossible to isolate whether the 54.1% Top-1 figure reflects neurophysiological information or injected linguistic bias.
minor comments (2)
- [Abstract] The abstract states validation on Things-MEG but supplies no numerical results; including these metrics would clarify the generalization claim.
- [Methods (encoder architecture)] Notation for the graph-attention and temporal-spatial convolutional components of the encoder would benefit from an explicit diagram or equation reference to aid replication.
Simulated Author's Rebuttal
Thank you for the detailed review. We appreciate the emphasis on isolating the contributions of each modality. Below we respond to the major comments and outline planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and two-stage design] Abstract / two-stage design description: the claim that LLM-generated textual descriptions 'inject linguistic structure into the shared space without overwhelming the primary EEG-image signal' is load-bearing for the 22-point accuracy improvement. No ablation that removes the text modality, varies caption sources, or blinds caption generation is reported, leaving open the possibility that class-specific correlations between generated captions and image categories (rather than EEG signal) drive the result.
Authors: We agree that the absence of ablations isolating the text modality leaves the contribution of linguistic supervision open to question. The two-stage design positions text as a semantic regularizer, but to rigorously demonstrate that gains derive from EEG-visual alignment, we will add the suggested ablations: (1) a bi-modal EEG-image contrastive baseline, (2) caption-only alignment runs, and (3) consistency checks across different LLMs for caption generation. These will be included in the revised manuscript to quantify the incremental benefit of the tri-modal setup. revision: yes
-
Referee: [Results (Things-EEG2)] Results section on Things-EEG2 benchmark: the paired Wilcoxon tests establish statistical significance over in-subject baselines, yet without quantitative controls (e.g., caption-only or image-only contrastive runs, or cross-LLM consistency checks) it is impossible to isolate whether the 54.1% Top-1 figure reflects neurophysiological information or injected linguistic bias.
Authors: The statistical tests confirm that our method outperforms prior EEG-only baselines. However, we recognize that without the additional controls mentioned, it is difficult to fully attribute the performance to neurophysiological signals versus potential linguistic artifacts. We will incorporate the quantitative controls (caption-only, image-only, and cross-LLM checks) into the results section of the revised version to address this concern directly. revision: yes
Circularity Check
No circularity: empirical benchmark results independent of inputs
full rationale
The paper reports measured Top-1/Top-5 accuracies on the Things-EEG2 200-way zero-shot benchmark after a two-stage training procedure (masked reconstruction pre-training followed by tri-modal contrastive alignment). These are direct empirical outcomes on held-out test data rather than quantities derived from equations, fitted parameters renamed as predictions, or self-citations. No load-bearing mathematical derivations, uniqueness theorems, or ansatzes are present in the provided text that reduce to the inputs by construction. The LLM text descriptions function as an auxiliary regularizer in the contrastive loss but do not create a self-definitional loop with the reported accuracies.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Contrastive loss aligns representations such that matching EEG-image-text triples are closer than non-matching ones in the shared space.
- domain assumption LLM-generated textual descriptions provide a reliable semantic regularizer without overwhelming the EEG-image signal.
Reference graph
Works this paper leans on
-
[1]
Decoding the brain: From neural representations to mechanistic models
Mackenzie Weygandt Mathis, Adriana Perez Rotondo, Edward F Chang, Andreas S Tolias, and Alexander Mathis. Decoding the brain: From neural representations to mechanistic models. Cell, 187(21):5814–5832, 2024
2024
-
[2]
Using goal-driven deep learning models to understand sensory cortex.Nature neuroscience, 19(3):356–365, 2016
Daniel LK Yamins and James J DiCarlo. Using goal-driven deep learning models to understand sensory cortex.Nature neuroscience, 19(3):356–365, 2016
2016
-
[3]
Decoding the visual and subjective contents of the human brain.Nature neuroscience, 8(5):679–685, 2005
Yukiyasu Kamitani and Frank Tong. Decoding the visual and subjective contents of the human brain.Nature neuroscience, 8(5):679–685, 2005
2005
-
[4]
Identifying natural images from human brain activity.Nature, 452(7185):352–355, 2008
Kendrick N Kay, Thomas Naselaris, Ryan J Prenger, and Jack L Gallant. Identifying natural images from human brain activity.Nature, 452(7185):352–355, 2008
2008
-
[5]
Visual image reconstruction from human brain activity using a combination of multiscale local image decoders.Neuron, 60(5):915–929, 2008
Yoichi Miyawaki, Hajime Uchida, Okito Yamashita, Masa-aki Sato, Yusuke Morito, Hiroki C Tanabe, Norihiro Sadato, and Yukiyasu Kamitani. Visual image reconstruction from human brain activity using a combination of multiscale local image decoders.Neuron, 60(5):915–929, 2008
2008
-
[6]
Performance-optimized hierarchical models predict neural responses in higher visual cortex.Proceedings of the national academy of sciences, 111(23):8619–8624, 2014
Daniel LK Yamins, Ha Hong, Charles F Cadieu, Ethan A Solomon, Darren Seibert, and James J DiCarlo. Performance-optimized hierarchical models predict neural responses in higher visual cortex.Proceedings of the national academy of sciences, 111(23):8619–8624, 2014
2014
-
[7]
Deep neural networks: a new framework for modeling biological vision and brain information processing.Annual review of vision science, 1:417–446, 2015
Nikolaus Kriegeskorte. Deep neural networks: a new framework for modeling biological vision and brain information processing.Annual review of vision science, 1:417–446, 2015
2015
-
[8]
Brains and algorithms partially converge in natural language processing.Communications biology, 5(1):134, 2022
Charlotte Caucheteux and Jean-Rémi King. Brains and algorithms partially converge in natural language processing.Communications biology, 5(1):134, 2022
2022
-
[9]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[10]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024
2024
-
[11]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
A large and rich eeg dataset for modeling human visual object recognition.NeuroImage, 264:119754, 2022
Alessandro T Gifford, Kshitij Dwivedi, Gemma Roig, and Radoslaw M Cichy. A large and rich eeg dataset for modeling human visual object recognition.NeuroImage, 264:119754, 2022
2022
-
[13]
Human eeg recordings for 1,854 concepts presented in rapid serial visual presentation streams
Tijl Grootswagers, Ivy Zhou, Amanda K Robinson, Martin N Hebart, and Thomas A Carlson. Human eeg recordings for 1,854 concepts presented in rapid serial visual presentation streams. Scientific Data, 9(1):3, 2022
2022
-
[14]
Decoding natural images from eeg for object recognition.arXiv preprint arXiv:2308.13234, 2023
Y . Song et al. Decoding natural images from eeg for object recognition.arXiv preprint arXiv:2308.13234, 2023
-
[15]
Recognizing natural images from eeg with language-guided contrastive learning.IEEE Transactions on Neural Networks and Learning Systems, 2025
Yonghao Song, Yijun Wang, Huiguang He, and Xiaorong Gao. Recognizing natural images from eeg with language-guided contrastive learning.IEEE Transactions on Neural Networks and Learning Systems, 2025
2025
-
[16]
Visual decoding and reconstruction via eeg embeddings with guided diffusion, 2024
Dongyang Li, Chen Wei, Shiying Li, Jiachen Zou, Haoyang Qin, and Quanying Liu. Vi- sual decoding and reconstruction via eeg embeddings with guided diffusion.arXiv preprint arXiv:2403.07721, 2024
-
[17]
Bridging the vision-brain gap with an uncertainty-aware blur prior
Haitao Wu, Qing Li, Changqing Zhang, Zhen He, and Xiaomin Ying. Bridging the vision-brain gap with an uncertainty-aware blur prior. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2246–2257, 2025. 11
2025
-
[18]
Neural-mcrl: Neural multimodal contrastive representation learning for eeg-based visual decoding
Yueyang Li, Zijian Kang, Shengyu Gong, Wenhao Dong, Weiming Zeng, Hongjie Yan, Wai Ting Siok, and Nizhuan Wang. Neural-mcrl: Neural multimodal contrastive representation learning for eeg-based visual decoding. In2025 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6. IEEE, 2025
2025
-
[19]
Mapping human brain function with meg and eeg: methods and validation.NeuroImage, 23:S289–S299, 2004
Felix Darvas, D Pantazis, E Kucukaltun-Yildirim, and RM Leahy. Mapping human brain function with meg and eeg: methods and validation.NeuroImage, 23:S289–S299, 2004
2004
-
[20]
Classification of eeg signals based on pattern recognition approach
Hafeez Ullah Amin, Wajid Mumtaz, Ahmad Rauf Subhani, Mohamad Naufal Mohamad Saad, and Aamir Saeed Malik. Classification of eeg signals based on pattern recognition approach. Frontiers in computational neuroscience, 11:103, 2017
2017
-
[21]
A review of issues related to data acquisition and analysis in eeg/meg studies.Brain sciences, 7(6):58, 2017
Aina Puce and Matti S Hämäläinen. A review of issues related to data acquisition and analysis in eeg/meg studies.Brain sciences, 7(6):58, 2017
2017
-
[22]
A common, high-dimensional model of the representational space in human ventral temporal cortex.Neuron, 72(2):404–416, 2011
James V Haxby, J Swaroop Guntupalli, Andrew C Connolly, Yaroslav O Halchenko, Bryan R Conroy, M Ida Gobbini, Michael Hanke, and Peter J Ramadge. A common, high-dimensional model of the representational space in human ventral temporal cortex.Neuron, 72(2):404–416, 2011
2011
-
[23]
Changde Du, Kaicheng Fu, Jinpeng Li, and Huiguang He. Decoding visual neural representa- tions by multimodal learning of brain-visual-linguistic features.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(9):10760–10777, 2023
2023
-
[24]
Yassine El Ouahidi, Jonathan Lys, Philipp Thölke, Nicolas Farrugia, Bastien Pasdeloup, Vincent Gripon, Karim Jerbi, and Giulia Lioi. Reve: A foundation model for eeg–adapting to any setup with large-scale pretraining on 25,000 subjects.arXiv preprint arXiv:2510.21585, 2025
-
[25]
Wenchao Yang, Weidong Yan, Wenkang Liu, Yulan Ma, and Yang Li. Thd-bar: Topology hierarchical derived brain autoregressive modeling for eeg generic representations.arXiv preprint arXiv:2511.13733, 2025
-
[26]
Spiced: A synaptic homeostasis-inspired framework for unsupervised continual eeg decoding
Yangxuan Zhou, Sha Zhao, Jiquan Wang, Haiteng Jiang, Shijian Li, Tao Li, and Gang Pan. Spiced: A synaptic homeostasis-inspired framework for unsupervised continual eeg decoding. arXiv preprint arXiv:2509.17439, 2025
-
[27]
Encoding and decoding in fmri.Neuroimage, 56(2):400–410, 2011
Thomas Naselaris, Kendrick N Kay, Shinji Nishimoto, and Jack L Gallant. Encoding and decoding in fmri.Neuroimage, 56(2):400–410, 2011
2011
-
[28]
Natural speech reveals the semantic maps that tile human cerebral cortex.Nature, 532 (7600):453–458, 2016
Alexander G Huth, Wendy A De Heer, Thomas L Griffiths, Frédéric E Theunissen, and Jack L Gallant. Natural speech reveals the semantic maps that tile human cerebral cortex.Nature, 532 (7600):453–458, 2016
2016
-
[29]
Brain-score: Which artificial neural network for object recognition is most brain-like?BioRxiv, page 407007, 2018
Martin Schrimpf, Jonas Kubilius, Ha Hong, Najib J Majaj, Rishi Rajalingham, Elias B Issa, Kohitij Kar, Pouya Bashivan, Jonathan Prescott-Roy, Franziska Geiger, et al. Brain-score: Which artificial neural network for object recognition is most brain-like?BioRxiv, page 407007, 2018
2018
-
[30]
Deep learning human mind for automated visual classification
Concetto Spampinato, Simone Palazzo, Isaak Kavasidis, Daniela Giordano, Nasim Souly, and Mubarak Shah. Deep learning human mind for automated visual classification. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6809–6817, 2017
2017
-
[31]
Yohann Benchetrit, Hubert Banville, and Jean-Rémi King. Brain decoding: toward real-time reconstruction of visual perception.arXiv preprint arXiv:2310.19812, 2023
-
[32]
Paul S Scotti, Mihir Tripathy, Cesar Kadir Torrico Villanueva, Reese Kneeland, Tong Chen, Ashutosh Narang, Charan Santhirasegaran, Jonathan Xu, Thomas Naselaris, Kenneth A Norman, et al. Mindeye2: Shared-subject models enable fmri-to-image with 1 hour of data.arXiv preprint arXiv:2403.11207, 2024
-
[33]
Mindbridge: A cross-subject brain decoding framework
Shizun Wang, Songhua Liu, Zhenxiong Tan, and Xinchao Wang. Mindbridge: A cross-subject brain decoding framework. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11333–11342, 2024. 12
2024
-
[34]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[35]
Enigma: A unified lightweight eeg-to-image model for multi-subject visual decoding
Reese Kneeland, Wangshu Jiang, Ugo Bruzadin Nunes, Si Kai Lee, Paul Steven Scotti, Arnaud Delorme, and Jonathan Xu. Enigma: A unified lightweight eeg-to-image model for multi-subject visual decoding. InNeurIPS 2025 Workshop on Foundation Models for the Brain and Body, 2025
2025
-
[36]
Deep learning with convolutional neural networks for eeg decoding and visualization
Robin Tibor Schirrmeister, Jost Tobias Springenberg, Lukas Dominique Josef Fiederer, Martin Glasstetter, Katharina Eggensperger, Michael Tangermann, Frank Hutter, Wolfram Burgard, and Tonio Ball. Deep learning with convolutional neural networks for eeg decoding and visualization. Human brain mapping, 38(11):5391–5420, 2017
2017
-
[37]
Lstm-based eeg classification in motor imagery tasks.IEEE transactions on neural systems and rehabilitation engineering, 26(11):2086–2095, 2018
Ping Wang, Aimin Jiang, Xiaofeng Liu, Jing Shang, and Li Zhang. Lstm-based eeg classification in motor imagery tasks.IEEE transactions on neural systems and rehabilitation engineering, 26(11):2086–2095, 2018
2086
-
[38]
Eeg-based emotion recognition using regularized graph neural networks.IEEE Transactions on Affective Computing, 13(3):1290–1301, 2020
Peixiang Zhong, Di Wang, and Chunyan Miao. Eeg-based emotion recognition using regularized graph neural networks.IEEE Transactions on Affective Computing, 13(3):1290–1301, 2020
2020
-
[39]
Eeg-gnn: Graph neural networks for classification of electroencephalogram (eeg) signals
Andac Demir, Toshiaki Koike-Akino, Ye Wang, Masaki Haruna, and Deniz Erdogmus. Eeg-gnn: Graph neural networks for classification of electroencephalogram (eeg) signals. In2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), pages 1061–1067. IEEE, 2021
2021
-
[40]
Petar Veliˇckovi´c, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph attention networks.arXiv preprint arXiv:1710.10903, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
How Attentive are Graph Attention Networks?
Shaked Brody, Uri Alon, and Eran Yahav. How attentive are graph attention networks?arXiv preprint arXiv:2105.14491, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[42]
Predicting brain activity using trans- formers.bioRxiv, pages 2023–08, 2023
Hossein Adeli, Sun Minni, and Nikolaus Kriegeskorte. Predicting brain activity using trans- formers.bioRxiv, pages 2023–08, 2023
2023
-
[43]
The Wisdom of a Crowd of Brains: A Universal Brain Encoder
Roman Beliy, Navve Wasserman, Amit Zalcher, and Michal Irani. The wisdom of a crowd of brains: A universal brain encoder.arXiv preprint arXiv:2406.12179, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Neuro-3d: Towards 3d visual decoding from eeg signals
Zhanqiang Guo, Jiamin Wu, Yonghao Song, Jiahui Bu, Weijian Mai, Qihao Zheng, Wanli Ouyang, and Chunfeng Song. Neuro-3d: Towards 3d visual decoding from eeg signals. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 23870–23880, 2025
2025
-
[45]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022
2022
-
[46]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019
2019
-
[47]
Meta-learning in neural networks: A survey.IEEE transactions on pattern analysis and machine intelligence, 44 (9):5149–5169, 2021
Timothy Hospedales, Antreas Antoniou, Paul Micaelli, and Amos Storkey. Meta-learning in neural networks: A survey.IEEE transactions on pattern analysis and machine intelligence, 44 (9):5149–5169, 2021
2021
-
[48]
Learnable latent embeddings for joint behavioural and neural analysis.Nature, 617(7960):360–368, 2023
Steffen Schneider, Jin Hwa Lee, and Mackenzie Weygandt Mathis. Learnable latent embeddings for joint behavioural and neural analysis.Nature, 617(7960):360–368, 2023
2023
-
[49]
Foundation model of neural activity predicts response to new stimulus types.Nature, 640(8058):470–477, 2025
Eric Y Wang, Paul G Fahey, Zhuokun Ding, Stelios Papadopoulos, Kayla Ponder, Marissa A Weis, Andersen Chang, Taliah Muhammad, Saumil Patel, Zhiwei Ding, et al. Foundation model of neural activity predicts response to new stimulus types.Nature, 640(8058):470–477, 2025
2025
-
[50]
A foundation model to predict and capture human cognition.Nature, 644(8078):1002–1009, 2025
Marcel Binz, Elif Akata, Matthias Bethge, Franziska Brändle, Fred Callaway, Julian Coda- Forno, Peter Dayan, Can Demircan, Maria K Eckstein, Noémi Éltet˝o, et al. A foundation model to predict and capture human cognition.Nature, 644(8078):1002–1009, 2025. 13
2025
-
[51]
Stéphane d’Ascoli, Jérémy Rapin, Yohann Benchetrit, Hubert Banville, and Jean-Rémi King. Tribe: Trimodal brain encoder for whole-brain fmri response prediction.arXiv preprint arXiv:2507.22229, 2025
-
[52]
Maeeg: Masked auto-encoder for eeg representation learning.arXiv preprint arXiv:2211.02625, 2022
Hsiang-Yun Sherry Chien, Hanlin Goh, Christopher M Sandino, and Joseph Y Cheng. Maeeg: Masked auto-encoder for eeg representation learning.arXiv preprint arXiv:2211.02625, 2022
-
[53]
Dreamdif- fusion: High-quality eeg-to-image generation with temporal masked signal modeling and clip alignment
Yunpeng Bai, Xintao Wang, Yan-Pei Cao, Yixiao Ge, Chun Yuan, and Ying Shan. Dreamdif- fusion: High-quality eeg-to-image generation with temporal masked signal modeling and clip alignment. InEuropean Conference on Computer Vision, pages 472–488. Springer, 2024
2024
-
[54]
Eegmamba: An eeg foundation model with mamba.Neural Networks, page 107816, 2025
Jiquan Wang, Sha Zhao, Zhiling Luo, Yangxuan Zhou, Shijian Li, and Gang Pan. Eegmamba: An eeg foundation model with mamba.Neural Networks, page 107816, 2025
2025
-
[55]
Neuript: Foundation model for neural interfaces
Zitao Fang, Chenxuan Li, Hongting Zhou, Shuyang Yu, Guodong Du, Ashwaq Qasem, Yang Lu, Jing Li, Junsong Zhang, and Sim Kuan Goh. Neuript: Foundation model for neural interfaces. arXiv preprint arXiv:2510.16548, 2025
-
[56]
The standardized eeg electrode array of the ifcn
Margitta Seeck, Laurent Koessler, Thomas Bast, Frans Leijten, Christoph Michel, Christoph Baumgartner, Bin He, and Sándor Beniczky. The standardized eeg electrode array of the ifcn. Clinical neurophysiology, 128(10):2070–2077, 2017
2070
-
[57]
Hebart, Oliver Contier, Lina Teichmann, Adam H
Martin N. Hebart, Oliver Contier, Lina Teichmann, Adam H. Rockter, Charles Y . Zheng, Alexis Kidder, Anna Corriveau, Maryam Vaziri-Pashkam, and Chris I. Baker. Things-data, a multimodal collection of large-scale datasets for investigating object representations in human brain and behavior.eLife, 12:e82580, 2023. doi: 10.7554/eLife.82580
-
[58]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[59]
Scaling vision transform- ers
Xiaohua Zhai, Alexander Kolesnikov, Neil Houlsby, and Lucas Beyer. Scaling vision transform- ers. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12104–12113, 2022
2022
-
[60]
Chinese clip: Contrastive vision-language pretraining in chinese,
An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, and Chang Zhou. Chinese clip: Contrastive vision-language pretraining in chinese.arXiv preprint arXiv:2211.01335, 2022
-
[61]
Kriegeskorte, M
N. Kriegeskorte, M. Mur, and P. Bandettini. Representational similarity analysis—connecting the branches of systems neuroscience.Frontiers in Systems Neuroscience, 2:4, 2008
2008
-
[62]
Am/eeg-fmri fusion primer: resolving human brain responses in space and time.Neuron, 107(5):772–781, 2020
Radoslaw M Cichy and Aude Oliva. Am/eeg-fmri fusion primer: resolving human brain responses in space and time.Neuron, 107(5):772–781, 2020
2020
-
[63]
Resolving human object recogni- tion in space and time.Nature neuroscience, 17(3):455–462, 2014
Radoslaw Martin Cichy, Dimitrios Pantazis, and Aude Oliva. Resolving human object recogni- tion in space and time.Nature neuroscience, 17(3):455–462, 2014
2014
-
[64]
The functional significance of delta oscillations in cognitive processing
Thalía Harmony. The functional significance of delta oscillations in cognitive processing. Frontiers in integrative neuroscience, 7:83, 2013
2013
-
[65]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 14 A Dataset We evaluate our method on two large-scale benchmarks: Things-EEG2 and Things-MEG. Table 7 provides the detailed information on the two datasets. Things-EEG2 provides 63-channel EEG recordings from 10 participants viewing natural obje...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[66]
All Components
and α=0.1. From the 16,540 training trials, 740 are held out for validation, fixed across runs and seeds. Final predictions average the three checkpoints with the lowest validation loss; all experiments are repeated over 3 seeds. Statistical testing.We assess significance with paired Wilcoxon signed-rank tests over the 10 per- subject scores (two-sided,α=...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.