Jailbreak to Protect: Buffering and Reinforcing via Temporary Jailbreaking for Safe Fine-Tuning in Large Language Models
Pith reviewed 2026-06-30 12:55 UTC · model grok-4.3
The pith
Temporary jailbreaking saturates safety-degrading gradients while preserving task-relevant gradients, enabling safe LLM fine-tuning without extra safety data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
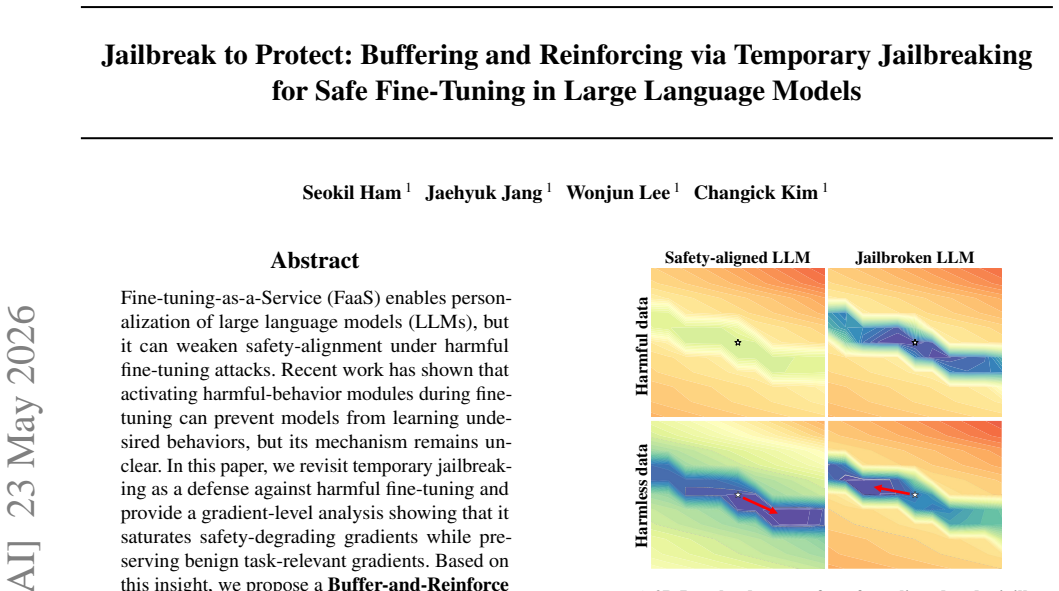
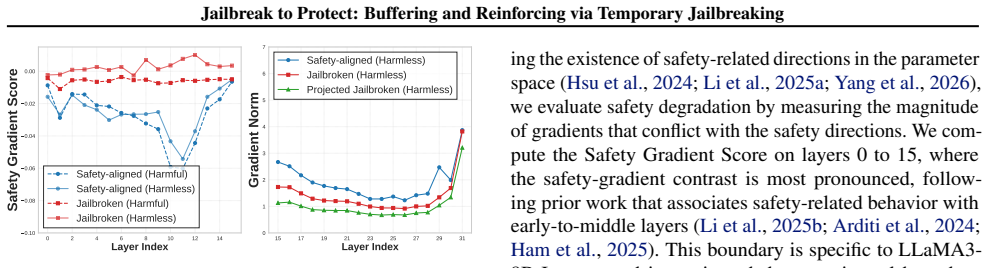
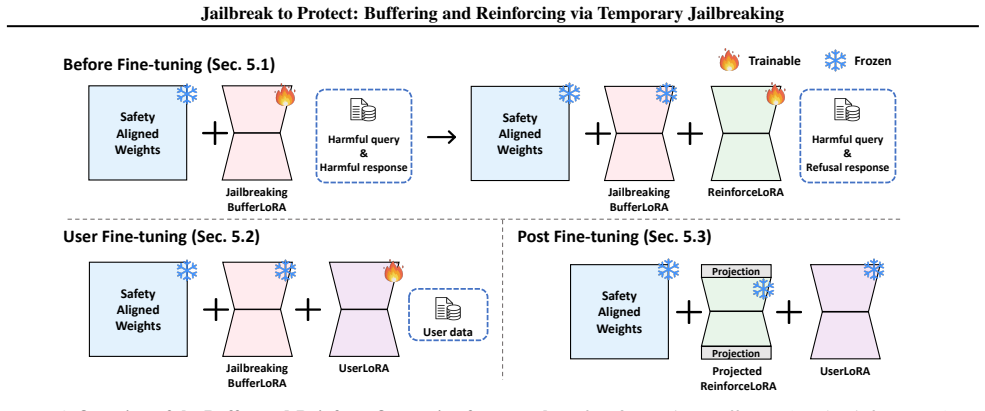
Temporary jailbreaking saturates safety-degrading gradients while preserving benign task-relevant gradients. Based on this insight, the Buffer-and-Reinforce framework buffers harmful updates during user fine-tuning via BufferLoRA (a removable adapter that induces the jailbroken state) and reinforces safety after adaptation by merging ReinforceLoRA, trained to recover refusal behavior, with UserLoRA through QR decomposition-based merging.
What carries the argument
BufferLoRA as a removable adapter that induces temporary jailbreaking to reduce harmful updates, combined with ReinforceLoRA merged via QR decomposition to restore safety post-adaptation.
If this is right
- The framework achieves superior safety and utility compared with baselines while using no additional safety data during user fine-tuning.
- It incurs only minimal computational cost because the adapters are low-rank and the merge uses QR decomposition.
- Safety reinforcement occurs after user adaptation, so the method can be applied on top of existing user fine-tuning pipelines.
- The same temporary-jailbreak buffering can be removed after the user phase without leaving permanent changes to the base model.
Where Pith is reading between the lines
- The gradient-saturation idea might extend to defending against other undesired behaviors such as bias amplification or capability misuse during fine-tuning.
- Service providers could embed the BufferLoRA creation step into standard LoRA fine-tuning APIs with negligible added latency.
- Testing whether the QR merge preserves performance on out-of-distribution tasks would clarify the method's robustness beyond the reported experiments.
Load-bearing premise
The gradient-level analysis holds in practice across models and tasks so that the temporary jailbreaking state can be reliably created, removed, and merged via QR decomposition without unintended side effects on final safety or performance.
What would settle it
An experiment in which models protected by the Buffer-and-Reinforce framework still produce substantially more harmful outputs after exposure to harmful fine-tuning data, or show clear drops in task performance after the QR merge step.
Figures
read the original abstract
Fine-tuning-as-a-Service (FaaS) enables personalization of large language models (LLMs), but it can weaken safety-alignment under harmful fine-tuning attacks. Recent work has shown that activating harmful-behavior modules during fine-tuning can prevent models from learning undesired behaviors, but its mechanism remains unclear. In this paper, we revisit temporary jailbreaking as a defense against harmful fine-tuning and provide a gradient-level analysis showing that it saturates safety-degrading gradients while preserving benign task-relevant gradients. Based on this insight, we propose a Buffer-and-Reinforce fine-tuning framework that buffers harmful updates during user fine-tuning and reinforces safety after adaptation. Specifically, BufferLoRA induces temporary jailbreaking as a removable adapter to reduce harmful updates during user fine-tuning. After adaptation, ReinforceLoRA, trained to recover refusal behavior under the temporarily jailbroken state, is integrated with UserLoRA via QR decomposition-based merging to reinforce safety while preserving user-task performance. Extensive experiments show that our framework achieves superior safety and utility with no additional safety data during user fine-tuning and minimal computational cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Buffer-and-Reinforce framework for safe fine-tuning of LLMs under harmful fine-tuning attacks in FaaS settings. It provides a gradient-level analysis asserting that temporary jailbreaking saturates safety-degrading gradients while preserving benign task-relevant gradients. BufferLoRA induces a temporary jailbroken state as a removable adapter during user fine-tuning to buffer harmful updates. ReinforceLoRA is then trained to recover refusal behavior under the jailbroken state and merged with UserLoRA via QR decomposition to reinforce safety while preserving task performance. The framework requires no additional safety data during user fine-tuning and incurs minimal computational cost. Extensive experiments are claimed to demonstrate superior safety-utility tradeoffs.
Significance. If the gradient analysis holds and the QR merging reliably preserves the claimed gradient separation without side effects, the approach would provide a practical, low-overhead defense for safe personalization of LLMs that avoids collecting extra safety data. The temporary-adapter plus post-hoc merging strategy is a distinct contribution relative to prior safety-alignment work during fine-tuning.
major comments (2)
- [Framework description (QR merging step)] The central claim rests on the assertion that QR decomposition merging of ReinforceLoRA with UserLoRA preserves refusal behavior without reintroducing harmful directions or degrading preserved benign gradients. No explicit orthogonality argument, bound, or post-merging gradient analysis is supplied to show why this separation is guaranteed (see the framework description of the merging step and the gradient analysis section).
- [Gradient-level analysis] The gradient-level analysis is presented as showing saturation of safety-degrading gradients by temporary jailbreaking, yet the description supplies no equations, quantitative measures of saturation, or proof that this property survives removal of BufferLoRA and subsequent QR merging across models (see the gradient analysis and experimental validation sections).
minor comments (2)
- [Abstract] The abstract refers to 'extensive experiments' without naming the models, attack types, or baselines; adding these details would improve readability.
- [Abstract] The invented terms BufferLoRA and ReinforceLoRA appear without a one-sentence definition on first use in the abstract; a brief parenthetical would aid clarity.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which help improve the clarity and rigor of our work. We address each major comment below and indicate the revisions we plan to make.
read point-by-point responses
-
Referee: [Framework description (QR merging step)] The central claim rests on the assertion that QR decomposition merging of ReinforceLoRA with UserLoRA preserves refusal behavior without reintroducing harmful directions or degrading preserved benign gradients. No explicit orthogonality argument, bound, or post-merging gradient analysis is supplied to show why this separation is guaranteed (see the framework description of the merging step and the gradient analysis section).
Authors: We agree that a more formal justification for the QR merging step would strengthen the manuscript. In the current version, we rely on the mathematical property of QR decomposition to ensure orthogonality between the merged components and provide empirical evidence through post-merging evaluations. However, we will add an explicit description of the orthogonality argument in the framework section and include additional post-merging gradient analysis in the revision. revision: yes
-
Referee: [Gradient-level analysis] The gradient-level analysis is presented as showing saturation of safety-degrading gradients by temporary jailbreaking, yet the description supplies no equations, quantitative measures of saturation, or proof that this property survives removal of BufferLoRA and subsequent QR merging across models (see the gradient analysis and experimental validation sections).
Authors: The gradient analysis in the manuscript is primarily empirical, demonstrating through experiments that temporary jailbreaking reduces the magnitude of safety-degrading gradients while maintaining task-relevant ones. We do provide quantitative measures in the form of gradient norm comparisons in the experimental sections. We acknowledge the lack of formal equations and proofs, and will incorporate a more detailed mathematical formulation of the saturation effect along with validation of its persistence after BufferLoRA removal and QR merging in the revised manuscript. revision: yes
Circularity Check
No circularity: derivation relies on gradient analysis and empirical merging without reduction to inputs by construction
full rationale
The paper's central claims rest on a gradient-level analysis of temporary jailbreaking (saturating safety-degrading gradients while preserving task gradients) and a Buffer-and-Reinforce framework using BufferLoRA, ReinforceLoRA, and QR-based merging. No equations, fitted parameters, or self-citations are shown that make any prediction equivalent to its inputs by definition. The QR merging step is presented as a practical integration technique rather than a tautological renaming or self-referential fit. The derivation chain is therefore self-contained against external benchmarks and experiments, consistent with a normal non-circular outcome.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Temporary jailbreaking via a removable adapter saturates safety-degrading gradients while preserving task gradients
invented entities (2)
-
BufferLoRA
no independent evidence
-
ReinforceLoRA
no independent evidence
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Refusal in language models is mediated by a single direction
Arditi, A., Obeso, O., Syed, A., Paleka, D., Panickssery, N., Gurnee, W., and Nanda, N. Refusal in language models is mediated by a single direction. Advances in Neural Information Processing Systems, 37: 0 136037--136083, 2024
2024
-
[3]
Bianchi, F., Suzgun, M., Attanasio, G., R \"o ttger, P., Jurafsky, D., Hashimoto, T., and Zou, J. Y. Safety-tuned llamas: Lessons from improving the safety of large language models that follow instructions. In International Conference on Learning Representations, volume 2024, pp.\ 34196--34216, 2024
2024
-
[4]
J., and Wong, E
Chao, P., Robey, A., Dobriban, E., Hassani, H., Pappas, G. J., and Wong, E. Jailbreaking black box large language models in twenty queries. In 2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), pp.\ 23--42. IEEE, 2025
2025
-
[5]
Vulnerability-aware alignment: Mitigating uneven forgetting in harmful fine-tuning
Chen, L., Han, X., Shen, L., Bai, J., and Wong, K.-F. Vulnerability-aware alignment: Mitigating uneven forgetting in harmful fine-tuning. In International Conference on Machine Learning, pp.\ 8172--8183. PMLR, 2025
2025
-
[6]
R., and He, P
Chuang, Y.-S., Xie, Y., Luo, H., Kim, Y., Glass, J. R., and He, P. Dola: Decoding by contrasting layers improves factuality in large language models. In International Conference on Learning Representations, volume 2024, pp.\ 54158--54183, 2024
2024
-
[7]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., and Schulman, J. Training verifiers to solve math word problems, 2021. URL https://arxiv.org/abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Mogu: A framework for enhancing safety of llms while preserving their usability
Du, Y., Zhao, S., Zhao, D., Ma, M., Chen, Y., Huo, L., Yang, Q., Xu, D., and Qin, B. Mogu: A framework for enhancing safety of llms while preserving their usability. Advances in Neural Information Processing Systems, 37: 0 87569--87591, 2024
2024
-
[9]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Badnets: Evaluating backdooring attacks on deep neural networks
Gu, T., Liu, K., Dolan-Gavitt, B., and Garg, S. Badnets: Evaluating backdooring attacks on deep neural networks. Ieee Access, 7: 0 47230--47244, 2019
2019
-
[11]
Ham, S., Choi, Y., Yang, Y., Cho, S., Kim, Y., and Kim, C. Safety-aligned weights are not enough: Refusal-teacher-guided finetuning enhances safety and downstream performance under harmful finetuning attacks, 2025. URL https://arxiv.org/abs/2506.07356
-
[12]
Safeswitch: Steering unsafe llm behavior via internal activation signals
Han, P., Qian, C., Chen, X., Zhang, Y., Zhang, D., and Ji, H. Safeswitch: Steering unsafe llm behavior via internal activation signals. In Conference on Empirical Methods in Natural Language Processing, 2025. URL https://api.semanticscholar.org/CorpusID:276094149
2025
-
[13]
Hsiung, L., Pang, T., Tang, Y.-C., Song, L., Ho, T.-Y., Chen, P.-Y., and Yang, Y. Why llm safety guardrails collapse after fine-tuning: A similarity analysis between alignment and fine-tuning datasets, 2025. URL https://arxiv.org/abs/2506.05346
-
[14]
Safe lora: The silver lining of reducing safety risks when finetuning large language models
Hsu, C.-Y., Tsai, Y.-L., Lin, C.-H., Chen, P.-Y., Yu, C.-M., and Huang, C.-Y. Safe lora: The silver lining of reducing safety risks when finetuning large language models. Advances in Neural Information Processing Systems, 37: 0 65072--65094, 2024
2024
-
[15]
J., yelong shen, Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., and Chen, W
Hu, E. J., yelong shen, Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., and Chen, W. Lo RA : Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=nZeVKeeFYf9
2022
-
[16]
F., and Liu, L
Huang, T., Hu, S., Ilhan, F., Tekin, S. F., and Liu, L. Lisa: Lazy safety alignment for large language models against harmful fine-tuning attack. Advances in Neural Information Processing Systems, 37: 0 104521--104555, 2024 a
2024
-
[17]
Vaccine: Perturbation-aware alignment for large language models against harmful fine-tuning attack
Huang, T., Hu, S., and Liu, L. Vaccine: Perturbation-aware alignment for large language models against harmful fine-tuning attack. Advances in Neural Information Processing Systems, 37: 0 74058--74088, 2024 b
2024
-
[18]
Antidote: Post-fine-tuning safety alignment for large language models against harmful fine-tuning attack
Huang, T., Bhattacharya, G., Joshi, P., Kimball, J., and Liu, L. Antidote: Post-fine-tuning safety alignment for large language models against harmful fine-tuning attack. In Forty-second International Conference on Machine Learning, 2025 a . URL https://openreview.net/forum?id=Arepl4R86m
2025
-
[19]
Booster: Tackling harmful fine-tuning for large language models via attenuating harmful perturbation
Huang, T., Hu, S., Ilhan, F., Tekin, S., and Liu, L. Booster: Tackling harmful fine-tuning for large language models via attenuating harmful perturbation. In International Conference on Learning Representations, volume 2025, pp.\ 67202--67226, 2025 b
2025
-
[20]
T., Wortsman, M., Schmidt, L., Hajishirzi, H., and Farhadi, A
Ilharco, G., Ribeiro, M. T., Wortsman, M., Schmidt, L., Hajishirzi, H., and Farhadi, A. Editing models with task arithmetic. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=6t0Kwf8-jrj
2023
-
[21]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Inan, H., Upasani, K., Chi, J., Rungta, R., Iyer, K., Mao, Y., Tontchev, M., Hu, Q., Fuller, B., Testuggine, D., and Khabsa, M. Llama guard: Llm-based input-output safeguard for human-ai conversations, 2023. URL https://arxiv.org/abs/2312.06674
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Safepath: Preventing harmful reasoning in chain-of-thought via early alignment
Jeung, W., Sangyeon, Y., Kahng, M., and No, A. Safepath: Preventing harmful reasoning in chain-of-thought via early alignment. Advances in Neural Information Processing Systems, 38: 0 99641--99670, 2026
2026
-
[23]
Beavertails: Towards improved safety alignment of llm via a human-preference dataset
Ji, J., Liu, M., Dai, J., Pan, X., Zhang, C., Bian, C., Chen, B., Sun, R., Wang, Y., and Yang, Y. Beavertails: Towards improved safety alignment of llm via a human-preference dataset. Advances in Neural Information Processing Systems, 36: 0 24678--24704, 2023
2023
-
[24]
A., Zhou, J., Wang, K., Li, B., et al
Ji, J., Hong, D., Zhang, B., Chen, B., Dai, J., Zheng, B., Qiu, T. A., Zhou, J., Wang, K., Li, B., et al. Pku-saferlhf: Towards multi-level safety alignment for llms with human preference. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 31983--32016, 2025
2025
-
[25]
Y., and Poovendran, R
Jiang, F., Xu, Z., Li, Y., Niu, L., Xiang, Z., Li, B., Lin, B. Y., and Poovendran, R. Safechain: Safety of language models with long chain-of-thought reasoning capabilities. In Findings of the Association for Computational Linguistics: ACL 2025, pp.\ 23303--23320, 2025
2025
-
[26]
and Li, B
Kang, M. and Li, B. R^ 2 -Guard: Robust reasoning enabled llm guardrail via knowledge-enhanced logical reasoning. In International Conference on Learning Representations, volume 2025, pp.\ 63859--63876, 2025
2025
-
[27]
LoRA fine-tuning efficiently undoes safety training in Llama 2-Chat 70B, 2023
Lermen, S., Rogers-Smith, C., and Ladish, J. Lora fine-tuning efficiently undoes safety training in llama 2-chat 70b, 2024. URL https://arxiv.org/abs/2310.20624
-
[28]
M., Backes, M., Zhang, Y., and Wang, Y
Li, M., Si, W. M., Backes, M., Zhang, Y., and Wang, Y. Salo RA : Safety-alignment preserved low-rank adaptation. In The Thirteenth International Conference on Learning Representations, 2025 a . URL https://openreview.net/forum?id=GOoVzE9nSj
2025
-
[29]
Safety layers in aligned large language models: The key to llm security
Li, S., Yao, L., Zhang, L., and Li, Y. Safety layers in aligned large language models: The key to llm security. In International Conference on Learning Representations, volume 2025, pp.\ 98163--98189, 2025 b
2025
-
[30]
Targeted vaccine: Safety alignment for large language models against harmful fine-tuning via layer-wise perturbation
Liu, G., Lin, W., Mu, Q., Huang, T., Mo, R., Tao, Y., and Shen, L. Targeted vaccine: Safety alignment for large language models against harmful fine-tuning via layer-wise perturbation. IEEE Transactions on Information Forensics and Security, 2025 a
2025
-
[31]
Liu, G., Mu, Q., Huang, T., Wang, X., Shen, L., Lin, W., and Li, Z. Pharmacist: Safety alignment data curation for large language models against harmful fine-tuning, 2025 b . URL https://arxiv.org/abs/2510.10085
-
[32]
Safe delta: Consistently preserving safety when fine-tuning llms on diverse datasets
Lu, N., Liu, S., Wu, J., Chen, W., Zhang, Z., Ong, Y.-S., Wang, Q., and Tang, K. Safe delta: Consistently preserving safety when fine-tuning llms on diverse datasets. In International Conference on Machine Learning, pp.\ 40537--40559. PMLR, 2025
2025
-
[33]
Tree of attacks: Jailbreaking black-box llms automatically
Mehrotra, A., Zampetakis, M., Kassianik, P., Nelson, B., Anderson, H., Singer, Y., and Karbasi, A. Tree of attacks: Jailbreaking black-box llms automatically. Advances in Neural Information Processing Systems, 37: 0 61065--61105, 2024
2024
-
[34]
Mukhoti, J., Gal, Y., Torr, P., and Dokania, P. K. Fine-tuning can cripple your foundation model; preserving features may be the solution. Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URL https://openreview.net/forum?id=kfhoeZCeW7. Featured Certification
2024
-
[35]
J., Chen, R., Chen, X., Hirata, N
Perin, G. J., Chen, R., Chen, X., Hirata, N. S. T., Wang, Z., and Hong, J. Lox: Low-rank extrapolation robustifies LLM safety against fine-tuning. In Second Conference on Language Modeling, 2025. URL https://openreview.net/forum?id=ASS5YD4hL4
2025
-
[36]
Qi, X., Zeng, Y., Xie, T., Chen, P.-Y., Jia, R., Mittal, P., and Henderson, P. Fine-tuning aligned language models compromises safety, even when users do not intend to! In International Conference on Learning Representations, volume 2024, pp.\ 30988--31043, 2024
2024
-
[37]
N., Parisien, C., and Cohen, J
Rebedea, T., Dinu, R., Sreedhar, M. N., Parisien, C., and Cohen, J. Nemo guardrails: A toolkit for controllable and safe llm applications with programmable rails. In Proceedings of the 2023 conference on empirical methods in natural language processing: system demonstrations, pp.\ 431--445, 2023
2023
-
[38]
Representation noising: A defence mechanism against harmful finetuning
Rosati, D., Wehner, J., Williams, K., Bartoszcze, ., Atanasov, D., Gonzales, R., Majumdar, S., Maple, C., Sajjad, H., and Rudzicz, F. Representation noising: A defence mechanism against harmful finetuning. Advances in Neural Information Processing Systems, 37: 0 12636--12676, 2024
2024
-
[39]
Latent adversarial training improves robustness to persistent harmful behaviors in llms,
Sheshadri, A., Ewart, A., Guo, P., Lynch, A., Wu, C., Hebbar, V., Sleight, H., Stickland, A. C., Perez, E., Hadfield-Menell, D., et al. Latent adversarial training improves robustness to persistent harmful behaviors in llms. arXiv preprint arXiv:2407.15549, 2024
-
[40]
D., Ng, A
Socher, R., Perelygin, A., Wu, J., Chuang, J., Manning, C. D., Ng, A. Y., and Potts, C. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 conference on empirical methods in natural language processing, pp.\ 1631--1642, 2013
2013
-
[41]
A simple and effective pruning approach for large language models
Sun, M., Liu, Z., Bair, A., and Kolter, Z. A simple and effective pruning approach for large language models. In International Conference on Learning Representations, volume 2024, pp.\ 4942--4964, 2024
2024
-
[42]
Taori, R., Gulrajani, I., Zhang, T., Dubois, Y., Li, X., Guestrin, C., Liang, P., and Hashimoto, T. B. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023
2023
-
[43]
Gemma 2: Improving Open Language Models at a Practical Size
Team, G., Riviere, M., Pathak, S., Sessa, P. G., Hardin, C., Bhupatiraju, S., Hussenot, L., Mesnard, T., Shahriari, B., Ram \'e , A., et al. Gemma 2: Improving open language models at a practical size. arXiv preprint arXiv:2408.00118, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
Panacea: Mitigating harmful fine-tuning for large language models via post-fine-tuning perturbation
Wang, Y., Huang, T., Shen, L., Yao, H., Luo, H., Liu, R., Tan, N., Huang, J., and Tao, D. Panacea: Mitigating harmful fine-tuning for large language models via post-fine-tuning perturbation. Advances in Neural Information Processing Systems, 38: 0 169951--169985, 2026
2026
-
[46]
Efficient adversarial training in llms with continuous attacks
Xhonneux, S., Sordoni, A., G \"u nnemann, S., Gidel, G., and Schwinn, L. Efficient adversarial training in llms with continuous attacks. Advances in Neural Information Processing Systems, 37: 0 1502--1530, 2024
2024
-
[47]
A., and Bansal, M
Yadav, P., Tam, D., Choshen, L., Raffel, C. A., and Bansal, M. Ties-merging: Resolving interference when merging models. Advances in neural information processing systems, 36: 0 7093--7115, 2023
2023
-
[48]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Asft: Anchoring safety during llm fine-tuning within narrow safety basin
Yang, S., Zhang, Q., Liu, Y., Huang, Y., Jia, X., Ning, K.-P., Yao, J.-Y., Wang, J., Hailiang, D., Song, Y., et al. Asft: Anchoring safety during llm fine-tuning within narrow safety basin. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pp.\ 34322--34330, 2026
2026
-
[50]
Nlsr: Neuron-level safety realignment of large language models against harmful fine-tuning
Yi, X., Zheng, S., Wang, L., de Melo, G., Wang, X., and He, L. Nlsr: Neuron-level safety realignment of large language models against harmful fine-tuning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pp.\ 25706--25714, 2025
2025
-
[51]
Robust llm safeguarding via refusal feature adversarial training
Yu, L., Do, V., Hambardzumyan, K., and Cancedda, N. Robust llm safeguarding via refusal feature adversarial training. In International Conference on Learning Representations, volume 2025, pp.\ 5254--5277, 2025
2025
-
[52]
Character-level convolutional networks for text classification
Zhang, X., Zhao, J., and LeCun, Y. Character-level convolutional networks for text classification. Advances in neural information processing systems, 28, 2015
2015
-
[53]
Intention analysis makes llms a good jailbreak defender
Zhang, Y., Ding, L., Zhang, L., and Tao, D. Intention analysis makes llms a good jailbreak defender. In Proceedings of the 31st International Conference on Computational Linguistics, pp.\ 2947--2968, 2025
2025
-
[54]
Llms encode harmfulness and refusal separately
Zhao, J., Huang, J., Wu, Z., Bau, D., and Shi, W. Llms encode harmfulness and refusal separately. Advances in Neural Information Processing Systems, 38: 0 140283--140318, 2026
2026
-
[55]
Merging loras like playing lego: Pushing the modularity of lora to extremes through rank-wise clustering
Zhao, Z., Zhu, D., Li, Z., Su, J., Wang, X., Wu, F., et al. Merging loras like playing lego: Pushing the modularity of lora to extremes through rank-wise clustering. In International Conference on Learning Representations, volume 2025, pp.\ 72896--72913, 2025
2025
-
[56]
On prompt-driven safeguarding for large language models
Zheng, C., Yin, F., Zhou, H., Meng, F., Zhou, J., Chang, K.-W., Huang, M., and Peng, N. On prompt-driven safeguarding for large language models. In International Conference on Machine Learning, pp.\ 61593--61613. PMLR, 2024
2024
-
[57]
Making harmful behaviors unlearnable for large language models
Zhou, X., Lu, Y., Ma, R., Wei, Y., Gui, T., Zhang, Q., and Huang, X.-J. Making harmful behaviors unlearnable for large language models. In Findings of the Association for Computational Linguistics: ACL 2024, pp.\ 10258--10273, 2024
2024
-
[58]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Zou, A., Wang, Z., Carlini, N., Nasr, M., Kolter, J. Z., and Fredrikson, M. Universal and transferable adversarial attacks on aligned language models, 2023. URL https://arxiv.org/abs/2307.15043
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[59]
Improving alignment and robustness with circuit breakers
Zou, A., Phan, L., Wang, J., Duenas, D., Lin, M., Andriushchenko, M., Wang, R., Kolter, Z., Fredrikson, M., and Hendrycks, D. Improving alignment and robustness with circuit breakers. Advances in Neural Information Processing Systems, 37: 0 83345--83373, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.