PEDESTRIANQA: A Benchmark for Vision-Language Models on Pedestrian Intention and Trajectory Prediction
Pith reviewed 2026-06-30 13:22 UTC · model grok-4.3
The pith
Finetuning vision-language models on PedestrianQA improves intention classification, trajectory forecasting accuracy, and rationale quality without task-specific architectures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that richly annotated pedestrian sequences expressed in natural language from existing video datasets supply sufficient visual dynamics and contextual cues, so that finetuning VLMs on the PedestrianQA QA formulation significantly improves intention classification, trajectory forecasting accuracy, and the quality of explanatory rationales, establishing VLMs as a unified and explainable framework for safety-critical pedestrian behavior modeling.
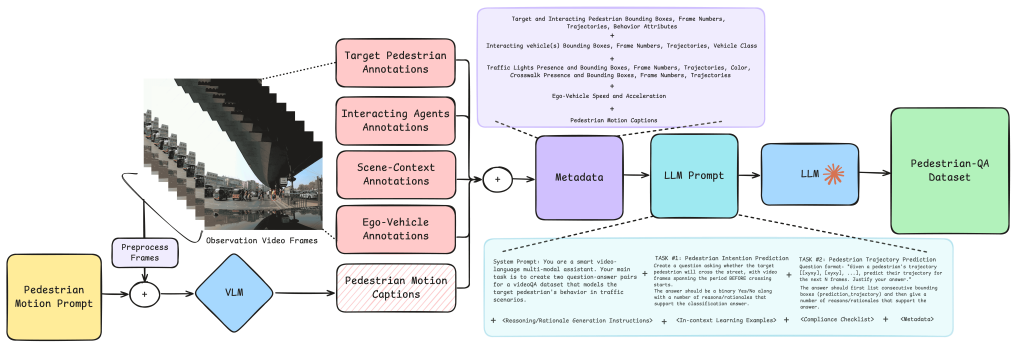
What carries the argument
PedestrianQA, a video-based dataset that formulates pedestrian intention and trajectory prediction as question-answering tasks augmented with structured rationales drawn from annotated sequences in PIE, JAAD, TITAN, and IDD-PeD.
If this is right
- VLMs can handle both intention classification and trajectory forecasting within one model instead of separate specialized architectures.
- Generated rationales become more reliable and informative, supporting interpretability in autonomous driving decisions.
- Performance improvements transfer across the four evaluated datasets without additional per-dataset engineering.
- The QA framing enables direct use of existing VLM training pipelines for pedestrian behavior tasks.
Where Pith is reading between the lines
- Similar QA reformulations could be applied to other multi-agent prediction problems such as vehicle trajectory forecasting.
- High-quality rationales might support downstream uses like regulatory auditing or human-in-the-loop verification of autonomous systems.
- If the dataset annotations contain systematic biases from the source videos, the learned rationales could propagate those biases into deployed models.
Load-bearing premise
Richly annotated pedestrian sequences from existing video datasets expressed in natural language supply sufficient unbiased visual dynamics and contextual cues for VLMs to learn accurate predictions and rationales without specialized per-task architectures.
What would settle it
A controlled experiment showing no statistically significant gains in intention classification accuracy or reduction in trajectory forecasting error after finetuning multiple VLMs on PedestrianQA versus strong baselines without the dataset would falsify the central claim.
Figures



read the original abstract
Pedestrian intention and trajectory prediction are critical for the safe deployment of autonomous driving systems, directly influencing navigation decisions in complex traffic environments. Recent advances in large vision-language models offer a powerful new paradigm for these tasks by combining high-capacity visual understanding with flexible natural language reasoning. In this work, we introduce PedestrianQA, a large-scale video-based dataset that formulates pedestrian intention and trajectory prediction as question-answering tasks augmented with structured rationales. PedestrianQA expresses richly annotated pedestrian sequences, in natural language, enabling VLMs to learn from visual dynamics, contextual cues, and interactions among traffic agents while generating concise explanations of their predictions without needing specialized architectures tailored for each task. Empirical evaluations across PIE, JAAD, TITAN, and IDD-PeD show that finetuning state-of-the-art VLMs on PedestrianQA significantly improves intention classification, trajectory forecasting accuracy, and the quality of explanatory rationales, demonstrating the strong potential of VLMs as a unified and explainable framework for safety-critical pedestrian behavior modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PedestrianQA, a large-scale video-based dataset reformulating pedestrian intention and trajectory prediction as question-answering tasks augmented with structured rationales, derived from PIE, JAAD, TITAN, and IDD-PeD. It claims that fine-tuning state-of-the-art vision-language models on PedestrianQA significantly improves intention classification, trajectory forecasting accuracy, and the quality of explanatory rationales, positioning VLMs as a unified and explainable framework for safety-critical pedestrian behavior modeling without specialized per-task architectures.
Significance. If the empirical claims hold with rigorous quantitative support, this could represent a meaningful contribution by providing a new benchmark and showing that VLMs can deliver a flexible, unified approach to pedestrian prediction tasks with built-in explainability, potentially benefiting autonomous driving safety research.
major comments (1)
- [Abstract] Abstract: The central claim that finetuning VLMs on PedestrianQA 'significantly improves intention classification, trajectory forecasting accuracy, and the quality of explanatory rationales' is asserted without any quantitative results, baselines, metrics, or experimental details. This prevents assessment of the improvements and is load-bearing for the paper's main contribution.
Simulated Author's Rebuttal
We thank the referee for the comment on the abstract. We agree the central claims require quantitative support in the abstract itself to allow proper assessment.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that finetuning VLMs on PedestrianQA 'significantly improves intention classification, trajectory forecasting accuracy, and the quality of explanatory rationales' is asserted without any quantitative results, baselines, metrics, or experimental details. This prevents assessment of the improvements and is load-bearing for the paper's main contribution.
Authors: We agree this is a valid observation. The abstract currently states the improvements without numbers or metrics. In the revised version we will add concise quantitative results (e.g., intention classification accuracy gains on PIE/JAAD, ADE/FDE reductions for trajectory prediction, and rationale quality scores) drawn from the experimental section so readers can evaluate the claims directly. revision: yes
Circularity Check
No significant circularity; empirical benchmark on public datasets
full rationale
The paper introduces PedestrianQA as a new QA-formulated dataset derived from existing public video datasets (PIE, JAAD, TITAN, IDD-PeD) and reports empirical gains from finetuning VLMs. No derivation chain, equations, fitted parameters renamed as predictions, or load-bearing self-citations are present in the provided text. Claims rest on standard train/eval splits and external benchmarks rather than self-referential constructions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Existing video datasets provide sufficient visual dynamics and interactions when augmented with natural language annotations
- domain assumption VLMs can learn pedestrian intention and trajectory from QA format without task-specific architectures
invented entities (1)
-
PedestrianQA dataset
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Pedestrian intention and trajectory prediction in unstructured traffic using idd-ped,
R. Bokkasam, S. Gangisetty, A. H. A. Hafez, and C. V . Jawahar, “Pedestrian intention and trajectory prediction in unstructured traffic using idd-ped,” inICRA, 2025
2025
-
[2]
Are they going to cross? a benchmark dataset and baseline for pedestrian crosswalk behavior,
A. Rasouli, I. Kotseruba, and J. K. Tsotsos, “Are they going to cross? a benchmark dataset and baseline for pedestrian crosswalk behavior,” inICCVW, 2017
2017
-
[3]
Pie: A large-scale dataset and models for pedestrian intention estimation and trajectory prediction,
A. Rasouli, I. Kotseruba, T. Kunic, and J. K. Tsotsos, “Pie: A large-scale dataset and models for pedestrian intention estimation and trajectory prediction,” inICCV, 2019
2019
-
[4]
Can reasons help improve pedestrian intent estimation? a cross-modal approach,
V . Khindkar, V . Balasubramanian, C. Arora, A. Subramanian, and C. Jawahar, “Can reasons help improve pedestrian intent estimation? a cross-modal approach,” inIROS, 2024
2024
-
[5]
Pedestrian vision language model for intentions prediction,
F. Munir, S. Azam, T. Mihaylova, V . Kyrki, and T. P. Kucner, “Pedestrian vision language model for intentions prediction,”IEEE Open Journal of Intelligent Transportation Systems, 2025
2025
-
[6]
Titan: Future forecast using action priors,
S. Malla, B. Dariush, and C. Choi, “Titan: Future forecast using action priors,” inCVPR, 2020
2020
-
[7]
Lg-traj: Llm guided pedestrian trajectory prediction,
P. S. Chib and P. Singh, “Lg-traj: Llm guided pedestrian trajectory prediction,”arXiv preprint arXiv:2403.08032, 2024
-
[8]
Instructblip: Towards general-purpose vision-language models with instruction tuning,
W. Daiet al., “Instructblip: Towards general-purpose vision-language models with instruction tuning,” inNeurIPS, 2023
2023
-
[9]
S. Baiet al., “Qwen2.5-vl technical report,”arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
J. Zhuet al., “Internvl3: Exploring advanced training and test- time recipes for open-source multimodal models,”arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Visual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” 2023
2023
-
[12]
G. Team, “Gemma 3 technical report,”arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
GPT3.int8(): 8-bit matrix multiplication for transformers at scale,
T. Dettmers, M. Lewis, Y . Belkada, and L. Zettlemoyer, “GPT3.int8(): 8-bit matrix multiplication for transformers at scale,” inNeurIPS, 2022
2022
-
[14]
Flashattention: Fast and memory-efficient exact attention with io-awareness,
T. Dao, D. Y . Fu, S. Ermon, A. Rudra, and C. R´e, “Flashattention: Fast and memory-efficient exact attention with io-awareness,” inNeurIPS, 2022
2022
-
[15]
Vision-language models for edge networks: A comprehensive survey,
A. Sharshar, L. U. Khan, W. Ullah, and M. Guizani, “Vision-language models for edge networks: A comprehensive survey,”IEEE Internet of Things Journal, 2025
2025
-
[16]
Vision language models in autonomous driving: A survey and outlook,
X. Zhouet al., “Vision language models in autonomous driving: A survey and outlook,”IEEE Transactions on Intelligent Vehicles, 2024
2024
-
[17]
B. Jiang, S. Chen, Q. Zhang, W. Liu, and X. Wang, “Alphadrive: Un- leashing the power of vlms in autonomous driving via reinforcement learning and reasoning,”arXiv preprint arXiv:2503.07608, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Pip-net: Pedestrian intention prediction in the wild,
M. Azarmi, M. Rezaei, and H. Wang, “Pip-net: Pedestrian intention prediction in the wild,”IEEE Transactions on Intelligent Transporta- tion Systems, 2025
2025
-
[19]
Spatiotemporal relationship reasoning for pedestrian intent prediction,
B. Liu, E. Adeli, Z. Cao, K.-H. Lee, A. Shenoi, A. Gaidon, and J. C. Niebles, “Spatiotemporal relationship reasoning for pedestrian intent prediction,”IEEE RA-L, 2020
2020
-
[20]
Pedx: Benchmark dataset for metric 3-d pose esti- mation of pedestrians in complex urban intersections,
W. Kimet al., “Pedx: Benchmark dataset for metric 3-d pose esti- mation of pedestrians in complex urban intersections,”IEEE RA-L, 2019
2019
-
[21]
Pedestrian stop and go forecasting with hybrid feature fusion,
D. Guo, T. Mordan, and A. Alahi, “Pedestrian stop and go forecasting with hybrid feature fusion,” inICRA, 2022
2022
-
[22]
Drivelm: Driving with graph visual question answer- ing,
C. Simaet al., “Drivelm: Driving with graph visual question answer- ing,” inECCV, 2023
2023
-
[23]
DriveVLM: The convergence of autonomous driving and large vision-language models,
X. Tianet al., “DriveVLM: The convergence of autonomous driving and large vision-language models,” inCoRL, 2024
2024
-
[24]
Abductive ego-view accident video understanding for safe driving perception,
J. Fanget al., “Abductive ego-view accident video understanding for safe driving perception,” inCVPR, 2024
2024
-
[25]
Roadsocial: A diverse videoqa dataset and benchmark for road event understanding from social video narratives,
C. Parikh, D. Rawat, R. R. T., T. Ghosh, and R. K. Sarvadevabhatla, “Roadsocial: A diverse videoqa dataset and benchmark for road event understanding from social video narratives,” inCVPR, 2025
2025
-
[26]
Rank2tell: A multimodal driving dataset for joint importance ranking and reasoning,
E. Sachdevaet al., “Rank2tell: A multimodal driving dataset for joint importance ranking and reasoning,” inWACV, 2024
2024
-
[27]
Nuscenes-qa: A multi-modal visual question answering benchmark for autonomous driving scenario,
T. Qian, J. Chen, L. Zhuo, Y . Jiao, and Y .-G. Jiang, “Nuscenes-qa: A multi-modal visual question answering benchmark for autonomous driving scenario,”AAAI, 2024
2024
-
[28]
Lingoqa: Visual question answering for autonomous driving,
A. Marcuet al., “Lingoqa: Visual question answering for autonomous driving,” inECCV, 2024
2024
-
[29]
Drama: Joint risk localization and captioning in driving,
S. Malla, C. Choi, I. Dwivedi, J. H. Choi, and J. Li, “Drama: Joint risk localization and captioning in driving,” inWACV, 2023
2023
-
[30]
Language prompt for autonomous driving,
D. Wu, W. Han, Y . Liu, T. Wang, C. zhong Xu, X. Zhang, and J. Shen, “Language prompt for autonomous driving,” inAAAI, 2025
2025
-
[31]
System card: Claude opus 4 & claude sonnet 4,
Anthropic, “System card: Claude opus 4 & claude sonnet 4,” 2025. [Online]. Available: www.anthropic.com/claude/sonnet
2025
-
[32]
Benchmark for evaluating pedestrian action prediction,
I. Kotseruba, A. Rasouli, and J. K. Tsotsos, “Benchmark for evaluating pedestrian action prediction,” inWACV, 2021
2021
-
[33]
Pre- dicting pedestrian crossing intention with feature fusion and spatio- temporal attention,
D. Yang, H. Zhang, E. Yurtsever, K. Redmill, and U. Ozguner, “Pre- dicting pedestrian crossing intention with feature fusion and spatio- temporal attention,”IEEE Transactions on Intelligent Vehicles, 2022
2022
-
[34]
Learning Transferable Visual Models From Natural Language Supervision
A. Radfordet al., “Learning transferable visual models from natural language supervision,”arXiv preprint arXiv:2103.00020, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[35]
Exploring the limits of transfer learning with a unified text-to-text transformer,
C. Raffelet al., “Exploring the limits of transfer learning with a unified text-to-text transformer,”JMLR, 2020
2020
-
[36]
Predicting pedestrian inten- tions with multimodal intentformer: A co-learning approach,
N. Sharma, C. Dhiman, and S. Indu, “Predicting pedestrian inten- tions with multimodal intentformer: A co-learning approach,”Pattern Recogn., 2025
2025
-
[37]
Optimizing vision-language model for road crossing intention estimation,
R. Uziel and O. Bialer, “Optimizing vision-language model for road crossing intention estimation,” inWACV, 2025
2025
-
[38]
Gpt-4v takes the wheel: Promises and challenges for pedestrian behavior prediction,
J. Huang, P. Jiang, A. Gautam, and S. Saripalli, “Gpt-4v takes the wheel: Promises and challenges for pedestrian behavior prediction,” AAAI, 2024
2024
-
[39]
Pedestrian intention pre- diction via vision-language foundation models,
M. Azarmi, M. Rezaei, and H. Wang, “Pedestrian intention pre- diction via vision-language foundation models,”arXiv preprint arXiv:2507.04141, 2025
-
[40]
BLIP-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,
J. Li, D. Li, S. Savarese, and S. Hoi, “BLIP-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,” inICML, 2023
2023
-
[41]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,” inICLR, 2021
2021
-
[42]
Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality,
W. Chianget al., “Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality,” March 2023. [Online]. Available: https://lmsys.org/blog/2023-03-30-vicuna/
2023
-
[43]
Llava-next: A strong zero-shot video understanding model,
Y . Zhanget al., “Llava-next: A strong zero-shot video understanding model,” 2024. [Online]. Available: https://llava-vl.github.io/blog/ 2024-04-30-llava-next-video/
2024
-
[44]
Kwai keye-vl technical report,
K. K. Team, “Kwai keye-vl technical report,”arXiv preprint arXiv:2507.01949, 2025
-
[45]
Roformer: Enhanced transformer with rotary position embedding,
J. Su, M. Ahmed, Y . Lu, S. Pan, W. Bo, and Y . Liu, “Roformer: Enhanced transformer with rotary position embedding,”Neurocomput., 2024
2024
-
[46]
Perception, reason, think, and plan: A survey on large multimodal reasoning models,
Y . Liet al., “Perception, reason, think, and plan: A survey on large multimodal reasoning models,”arXiv preprint arXiv:2505.04921, 2025
-
[47]
Dolphins: Multimodal language model for driving,
Y . Ma, Y . Cao, J. Sun, M. Pavone, and C. Xiao, “Dolphins: Multimodal language model for driving,” inECCV, 2024
2024
-
[48]
OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models
A. Awadallaet al., “Openflamingo: An open-source framework for training large autoregressive vision-language models,”arXiv preprint arXiv:2308.01390, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
OmniDrive: A holistic vision-language dataset for autonomous driving with counterfactual reasoning,
S. Wanget al., “OmniDrive: A holistic vision-language dataset for autonomous driving with counterfactual reasoning,” inCVPR, 2025
2025
-
[50]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” inInternational Conference on Learning Representations, 2022. [Online]. Available: https://openreview.net/forum?id=nZeVKeeFYf9
2022
-
[51]
CLAIR: Evaluating image captions with large language models,
D. Chan, S. Petryk, J. Gonzalez, T. Darrell, and J. Canny, “CLAIR: Evaluating image captions with large language models,” in”EMNLP”, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.