Proper Scoring Rules for Agentic Uncertainty Quantification
Pith reviewed 2026-06-30 12:57 UTC · model grok-4.3
The pith
The Trajectory Proper Score elicits the full prefix-conditioned success-probability process for agent trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Trajectory Proper Score (TPS) is a predictor-agnostic family of strictly proper trajectory-level scoring rules built on prequential proper scoring. The paper proves that TPS strictly elicits the success-probability process q_t = P^π(Y=1 | H_t) under complete observation within the chosen score family and weight schedule. It extends the construction to administratively censored trajectories by projecting the complete-data score onto the observable stopped prefix, producing an exact q_Z-weighted reduced score and a tractable approximation when q_Z is unestimated. It further shows that Trajectory ECE is resolution-blind and that scalarized Trajectory Brier elicits only the collapsed scalar,
What carries the argument
Trajectory Proper Score (TPS), a family of strictly proper trajectory-level scoring rules that weight per-step contributions to elicit the full prefix-conditioned success-probability trace.
If this is right
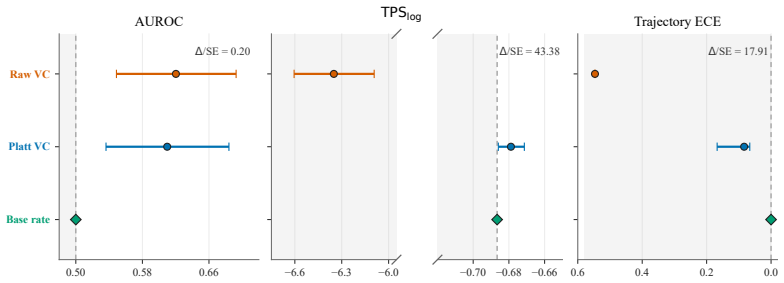
- TPS rankings can differ substantially from AUROC or AUPRC rankings once probabilities are recalibrated to match the true success process.
- Trajectory ECE fails to detect miscalibration that affects the full conditional trace even when resolution is low.
- Scalarized trajectory Brier scores only the marginal success probability and ignores prefix dependence.
- The censored approximation allows evaluation on stopped trajectories while remaining close to the complete-data score when q_Z is estimated.
Where Pith is reading between the lines
- The same projection technique for handling censoring could apply to sequential prediction tasks outside language-model agents whenever observations stop before the terminal outcome.
- Adopting TPS as a primary metric would encourage development of uncertainty signals that remain calibrated across varying history lengths rather than only at the end of a trajectory.
- The distinction between eliciting the full process versus a collapsed summary suggests re-examination of other multi-step evaluation settings such as planning or dialogue where intermediate probabilities matter.
Load-bearing premise
Any per-step uncertainty signal can be calibrated into a probability of eventual success, and the projection onto administratively censored prefixes preserves the elicitation property without further assumptions on the censoring process.
What would settle it
A controlled experiment under complete observation in which a miscalibrated per-step predictor receives a strictly better TPS than a perfectly calibrated predictor for the same score family and weight schedule.
Figures
read the original abstract
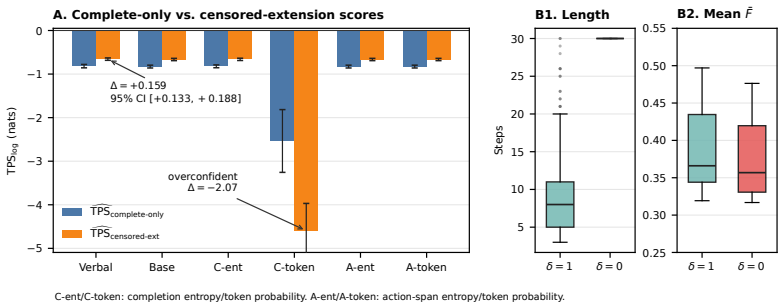
Language-model agents increasingly emit uncertainty signals throughout a trajectory, but existing agentic UQ evaluations often conflate ranking usefulness with probabilistic truthfulness. AUROC, AUPRC, risk-coverage, Trajectory ECE, and scalarized trajectory scores evaluate discrimination, binwise calibration, or collapsed summaries, but do not strictly elicit the full prefix-conditioned success-probability trace $q_t = P^{\pi}(Y=1 | H_t)$. Building on prequential proper scoring, we introduce the Trajectory Proper Score (TPS), a predictor-agnostic family of strictly proper trajectory-level scoring rules for any per-step uncertainty signal calibrated into a probability of eventual success. We prove that TPS strictly elicits the success-probability process under complete observation, within the chosen score family and weight schedule. We extend the construction to administratively censored trajectories by projecting the complete-data score onto the observable stopped prefix, yielding an exact $q_Z$-weighted reduced score and a tractable approximation when $q_Z$ is unestimated. We further show that common trajectory evaluators target weaker objects than the full prefix-conditioned probability process: Trajectory ECE is resolution-blind, while scalarized Trajectory Brier elicits only the collapsed scalar, not the full trace. Experiments on StrategyQA, Tau2-Bench, HotpotQA, and WebShop show that these theoretical distinctions are operationally visible: probability recalibration can substantially change TPS while leaving rank metrics nearly unchanged, and the tractable censored approximation can change the verdict relative to complete-only evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Trajectory Proper Score (TPS), a family of strictly proper scoring rules for per-step uncertainty signals in LM agent trajectories. It claims to prove that TPS strictly elicits the full prefix-conditioned success-probability process q_t = P^π(Y=1 | H_t) under complete observation within a chosen score family and weight schedule. The construction is extended to administratively censored trajectories via projection onto the stopped prefix, yielding an exact q_Z-weighted reduced score (with a tractable approximation when q_Z is unestimated). It further argues that Trajectory ECE is resolution-blind and scalarized Trajectory Brier elicits only the collapsed scalar, not the full trace. Experiments on StrategyQA, Tau2-Bench, HotpotQA, and WebShop illustrate that recalibration affects TPS but not rank metrics, and the censored approximation can alter verdicts.
Significance. If the proofs of strict elicitation hold and the censored projection preserves the property, this supplies a theoretically grounded, predictor-agnostic tool for evaluating the full uncertainty trace in agent trajectories, going beyond discrimination (AUROC) or binwise calibration. The explicit grounding in prequential proper scoring literature and the provision of proofs for the complete-observation case are strengths that could support more reliable UQ evaluation in agentic AI.
major comments (1)
- [Abstract / censored extension] Abstract and censored-trajectories section: The projection of complete-data TPS onto administratively censored prefixes is load-bearing for the central claim of applicability to real agent trajectories (e.g., WebShop, HotpotQA), which are stopped at random time Z. The abstract asserts an 'exact q_Z-weighted reduced score' that extends the elicitation property, yet no independence or exogeneity condition on the censoring process Z (relative to H_t or Y) is stated. If Z can depend on the history or outcome, the conditional expectation of the reduced score need not be uniquely maximized at the true q_t process. Please state the precise theorem, including any required assumptions on Z, and clarify whether the tractable approximation (when q_Z is unestimated) retains strict elicitation.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying the need to make the assumptions on the censoring process explicit. This strengthens the applicability claims for real-world agent trajectories.
read point-by-point responses
-
Referee: [Abstract / censored extension] Abstract and censored-trajectories section: The projection of complete-data TPS onto administratively censored prefixes is load-bearing for the central claim of applicability to real agent trajectories (e.g., WebShop, HotpotQA), which are stopped at random time Z. The abstract asserts an 'exact q_Z-weighted reduced score' that extends the elicitation property, yet no independence or exogeneity condition on the censoring process Z (relative to H_t or Y) is stated. If Z can depend on the history or outcome, the conditional expectation of the reduced score need not be uniquely maximized at the true q_t process. Please state the precise theorem, including any required assumptions on Z, and clarify whether the tractable approximation (when q_Z is unestimated) retains strict elicitation.
Authors: We agree that the conditions on Z require explicit statement. In the revision we will add a formal theorem to the censored-trajectories section: under the standard non-informative administrative censoring assumption (Z is independent of Y conditional on the observed history up to min(t, Z), i.e., the stopping decision does not depend on the future success process), the conditional expectation of the projected score is uniquely maximized at the true q_t process, yielding the exact q_Z-weighted reduced score. This matches the administrative-censoring setting used in the experiments. We will also clarify that the tractable approximation (replacing q_Z by its empirical estimate or a default) does not retain strict elicitation in general, as it can introduce bias when the estimate is misspecified; it is presented only as a practical surrogate whose ranking behavior is examined empirically. The abstract will be updated to reference these assumptions. revision: yes
Circularity Check
No significant circularity; derivation builds on external proper-scoring literature
full rationale
The central claim is a mathematical proof that TPS elicits the prefix process q_t under complete observation, using an explicitly chosen score family and weight schedule. The extension to censored trajectories is a direct projection construction yielding a q_Z-weighted reduced score. No step reduces a claimed prediction or uniqueness result to a quantity defined by the authors' own prior fits or self-citations. The paper cites established prequential scoring literature as external foundation rather than load-bearing self-reference. The weight schedule is presented as a modeling choice, not a fitted parameter renamed as prediction. This satisfies the criteria for a self-contained derivation against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- weight schedule
axioms (2)
- standard math Prequential proper scoring rules elicit true conditional probabilities
- domain assumption Per-step uncertainty signals can be calibrated to prefix-conditioned success probabilities
Reference graph
Works this paper leans on
-
[1]
Saup: Situation awareness uncertainty propagation on llm agent, 2024
Qiwei Zhao, Xujiang Zhao, Yanchi Liu, Wei Cheng, Yiyou Sun, Mika Oishi, Takao Osaki, Katsushi Matsuda, Huaxiu Yao, and Haifeng Chen. Saup: Situation awareness uncertainty propagation on llm agent, 2024. URLhttps://arxiv.org/abs/2412.01033
-
[2]
Uprop: Investigating the uncertainty propagation of llms in multi-step agentic decision-making, 2025
Jinhao Duan, James Diffenderfer, Sandeep Madireddy, Tianlong Chen, Bhavya Kailkhura, and Kaidi Xu. Uprop: Investigating the uncertainty propagation of llms in multi-step agentic decision-making, 2025. URLhttps://arxiv.org/abs/2506.17419
-
[3]
Agentic uncertainty quantification, 2026
Jiaxin Zhang, Prafulla Kumar Choubey, Kung-Hsiang Huang, Caiming Xiong, and Chien-Sheng Wu. Agentic uncertainty quantification, 2026. URL https://arxiv.org/abs/2601.15703
-
[4]
Steca: Step-level trajectory calibration for llm agent learning, 2025
Hanlin Wang, Jian Wang, Chak Tou Leong, and Wenjie Li. Steca: Step-level trajectory calibration for llm agent learning, 2025. URLhttps://arxiv.org/abs/2502.14276
-
[5]
Position: Uncertainty quantification needs reassessment for large-language model agents, 2025
Michael Kirchhof, Gjergji Kasneci, and Enkelejda Kasneci. Position: Uncertainty quantification needs reassessment for large-language model agents, 2025. URL https://arxiv.org/abs/ 2505.22655
-
[6]
URLhttps://doi.org/10.1198/016214506000001437
Tilmann Gneiting and Adrian Raftery. Strictly proper scoring rules, prediction, and es- timation.Journal of the American Statistical Association, 102:359–378, 03 2007. doi: 10.1198/016214506000001437
- [7]
-
[8]
Loss functions for binary class probability estimation and classification: Structure and applications
Andreas Buja, Werner Stuetzle, and Yi Shen. Loss functions for binary class probability estimation and classification: Structure and applications. 01 2005
2005
-
[9]
Allan H. Murphy. A new vector partition of the probability score.Journal of Applied Meteorology, 12:595–600, 1973. URL https://api.semanticscholar.org/CorpusID: 121053719
1973
-
[10]
Degroot and Stephen E
Morris H. Degroot and Stephen E. Fienberg. The comparison and evaluation of forecasters. The Statistician, 32:12–22, 1983. URL https://api.semanticscholar.org/CorpusID: 109884250
1983
-
[11]
Jochen Br¨ocker. Reliability, sufficiency, and the decomposition of proper scores.Quarterly Journal of the Royal Meteorological Society, 135(643):1512–1519, 2009. ISSN 1477-870X. doi: 10.1002/qj.456. URLhttp://dx.doi.org/10.1002/qj.456
-
[12]
Survival regression with proper scoring rules and monotonic neural networks
David Rindt, Robert Hu, David Steinsaltz, and Dino Sejdinovic. Survival regression with proper scoring rules and monotonic neural networks. In Gustau Camps-Valls, Francisco J. R. Ruiz, and Isabel Valera, editors,Proceedings of The 25th International Conference on Artificial Intelligence and Statistics, volume 151 ofProceedings of Machine Learning Research...
2022
-
[13]
Paul Blanche, Michael W Kattan, and Thomas A Gerds. The c-index is not proper for the evalu- ation of $t$-year predicted risks.Biostatistics, 20(2):347–357, 04 2019. ISSN 1465-4644. doi: 10.1093/biostatistics/kxy006. URLhttps://doi.org/10.1093/biostatistics/kxy006
-
[14]
Proper scoring rules for survival analysis, 2023
Hiroki Yanagisawa. Proper scoring rules for survival analysis, 2023. URL https://arxiv. org/abs/2305.00621
-
[15]
Towards uncertainty-aware language agent,
Jiuzhou Han, Wray Buntine, and Ehsan Shareghi. Towards uncertainty-aware language agent,
- [16]
-
[17]
Uncertainty estimation in autoregressive structured prediction,
Andrey Malinin and Mark Gales. Uncertainty estimation in autoregressive structured prediction,
- [18]
-
[19]
Jinhao Duan, Hao Cheng, Shiqi Wang, Alex Zavalny, Chenan Wang, Renjing Xu, Bhavya Kailkhura, and Kaidi Xu. Shifting attention to relevance: Towards the predictive uncertainty quantification of free-form large language models, 2024. URL https://arxiv.org/abs/ 2307.01379
-
[20]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation, 2023. URL https://arxiv.org/ abs/2302.09664
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Verified uncertainty calibration, 2020
Ananya Kumar, Percy Liang, and Tengyu Ma. Verified uncertainty calibration, 2020. URL https://arxiv.org/abs/1909.10155
-
[22]
Juozas Vaicenavicius, David Widmann, Carl Andersson, Fredrik Lindsten, Jacob Roll, and Thomas B. Sch¨on. Evaluating model calibration in classification, 2019. URL https://arxiv. org/abs/1902.06977
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[23]
Jeremias Traub, Till J. Bungert, Carsten T. L¨uth, Michael Baumgartner, Klaus H. Maier-Hein, Lena Maier-Hein, and Paul F Jaeger. Overcoming common flaws in the evaluation of selective classification systems, 2024. URLhttps://arxiv.org/abs/2407.01032
-
[24]
Littman, and Anthony R
Leslie Pack Kaelbling, Michael L. Littman, and Anthony R. Cassandra. Planning and acting in partially observable stochastic domains.Artificial Intelligence, 101(1):99–134,
-
[25]
doi: https://doi.org/10.1016/S0004-3702(98)00023-X
ISSN 0004-3702. doi: https://doi.org/10.1016/S0004-3702(98)00023-X. URL https://www.sciencedirect.com/science/article/pii/S000437029800023X
-
[26]
A. P. Dawid. Present position and potential developments: Some personal views statistical theory the prequential approach.Royal Statistical Society. Journal. Series A: General, 147(2): 278–290, 03 1984. ISSN 0035-9238. doi: 10.2307/2981683. URL https://doi.org/10. 2307/2981683
-
[27]
Hwang, Soumya Sanyal, Sean Welleck, Xiang Ren, Allyson Ettinger, Zaid Harchaoui, and Yejin Choi
Nouha Dziri, Ximing Lu, Melanie Sclar, Xiang Lorraine Li, Liwei Jiang, Bill Yuchen Lin, Peter West, Chandra Bhagavatula, Ronan Le Bras, Jena D. Hwang, Soumya Sanyal, Sean Welleck, Xiang Ren, Allyson Ettinger, Zaid Harchaoui, and Yejin Choi. Faith and fate: Limits of transformers on compositionality, 2023. URLhttps://arxiv.org/abs/2305.18654
-
[28]
Hanley and Barbara J
James A. Hanley and Barbara J. McNeil. The meaning and use of the area under a receiver operating characteristic (roc) curve.Radiology, 143 1:29–36, 1982. URL https://api. semanticscholar.org/CorpusID:10511727
1982
-
[29]
R.S. Sutton and A.G. Barto. Reinforcement learning: An introduction.IEEE Transactions on Neural Networks, 9(5):1054–1054, 1998. doi: 10.1109/TNN.1998.712192
-
[30]
Heejung Bang and James M. Robins. Doubly robust estimation in missing data and causal inference models.Biometrics, 61(4):962–973, 12 2005. ISSN 0006-341X. doi: 10.1111/j. 1541-0420.2005.00377.x. URL https://doi.org/10.1111/j.1541-0420.2005.00377. x
work page doi:10.1111/j 2005
-
[31]
Victor Chernozhukov, Denis Chetverikov, Mert Demirer, Esther Duflo, Christian Hansen, Whitney Newey, and James Robins. Double/debiased machine learning for treatment and structural parameters.The Econometrics Journal, 21(1):C1–C68, 02 2018. ISSN 1368-4221. doi: 10.1111/ectj.12097. URLhttps://doi.org/10.1111/ectj.12097
-
[32]
Gemma 4 31B IT
Google DeepMind. Gemma 4 31B IT. https://huggingface.co/google/ gemma-4-31B-it, 2026. Hugging Face model card
2026
-
[33]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models, 2023. URL https: //arxiv.org/abs/2210.03629. 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. τ 2-bench: Evaluating conversational agents in a dual-control environment, 2025. URL https://arxiv. org/abs/2506.07982
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Did aristotle use a laptop? a question answering benchmark with implicit reasoning strategies, 2021
Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. Did aristotle use a laptop? a question answering benchmark with implicit reasoning strategies, 2021. URLhttps://arxiv.org/abs/2101.02235
-
[36]
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhut- dinov, and Christopher D. Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering, 2018. URLhttps://arxiv.org/abs/1809.09600
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[37]
Webshop: Towards scalable real-world web interaction with grounded language agents, 2023
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents, 2023. URL https://arxiv.org/ abs/2207.01206. Appendix A Proof of Theorem 4.1 (Complete Observation) We give the full proof of Theorem 4.1 and record three remarks clarifying the filtration argument, the prequentia...
-
[38]
Therefore the averaging pathology is not specific to the unweighted mean. No deterministic scalarization used in existing agentic UQ work, including last, average, minimum, or weighted average, strictly elicits the full prefix-conditioned success-probability process. The issue is not that the underlying scalar score is improper; the issue is that scalariz...
1905
-
[39]
Use it to discover a relevant page/paragraph and load current passage context
Search[query]: retrieval from the configured Wikipedia backend. Use it to discover a relevant page/paragraph and load current passage context
-
[40]
It scans the currently loaded passage from the last Search and returns a matching span
Lookup[keyword]: local context scan only (no network). It scans the currently loaded passage from the last Search and returns a matching span. When you have enough information, end with: Finish[yes] or Finish[no] At every step, use this exact format: <think>your reasoning about what to do next</think> <action>Search[...] or Lookup[...] or Finish[yes/no]</...
-
[41]
Use it to discover relevant pages/passages and load context
Search[query]: retrieval from the configured Wikipedia backend. Use it to discover relevant pages/passages and load context
-
[42]
It scans the currently loaded passage and returns a matching span
Lookup[keyword]: local context scan only (no network). It scans the currently loaded passage and returns a matching span
-
[43]
Finish[answer]: terminate with a free-form final answer string. At every step, use this exact format: <think>your reasoning about what to do next</think> <action>Search[...] or Lookup[...] or Finish[answer]</action> <confidence>0.XX</confidence> <explanation>one sentence explaining your confidence</explanation> Rules: - confidence is a number between 0.0 ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.