Spectral Retrieval: Multi-Scale Sinc Convolution over Token Embeddings for Localized Retrieval in LLM Multi-Agent Systems
Pith reviewed 2026-06-30 12:03 UTC · model grok-4.3
The pith
Spectral Retrieval applies multi-scale sinc convolution to token embeddings to localize relevance and improve retrieval scores over standard MaxSim or mean pooling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
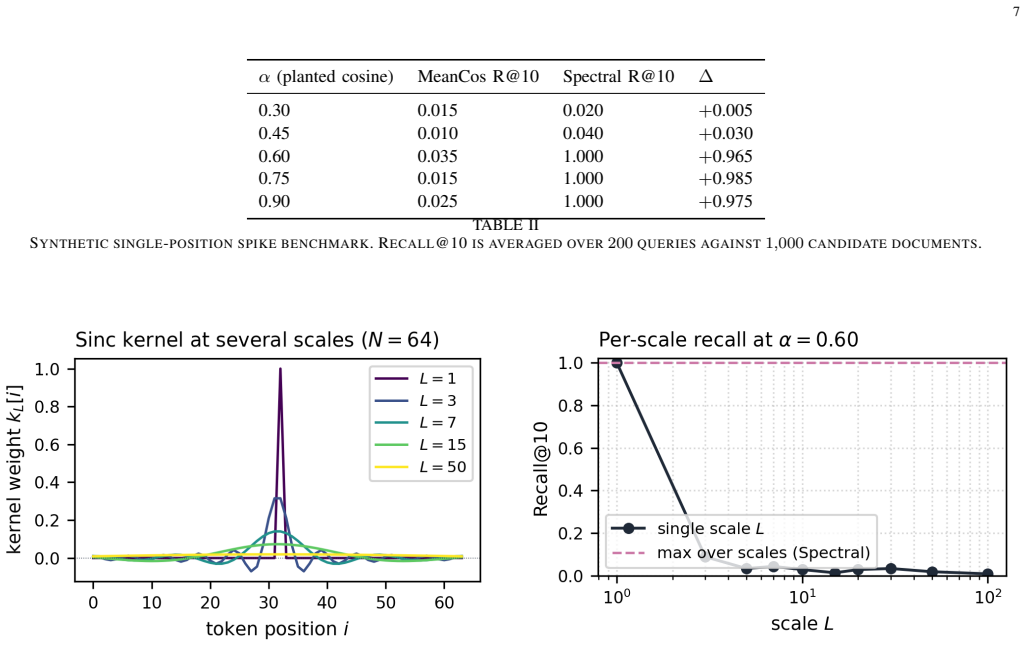
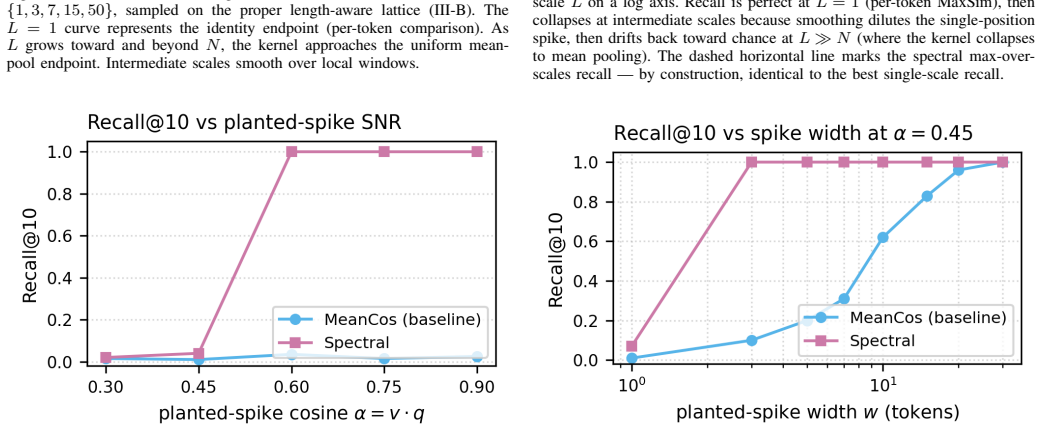
Spectral Retrieval reuses per-token embeddings from a late-interaction index and applies multi-scale sinc convolutions. At L=1 the kernel is the identity recovering MaxSim, and as L increases it approaches uniform mean pooling. The max cosine over positions and scales yields a score provably no less informative than the endpoints. On synthetic benchmarks with planted spikes, it reaches perfect recall once signal exceeds noise, and on LIMIT-small it achieves Recall@10 of 0.90, MRR 0.79, Success@10 0.84 with frozen all-mpnet-base-v2 encoder.
What carries the argument
Multi-scale sinc convolution over token embeddings, which allows interpolation between identity filter for MaxSim and uniform filter for mean pooling while computing position-aware max cosine scores.
If this is right
- Retrieval remains effective when relevant information is confined to short document subspans instead of being averaged out.
- The method requires no retraining of the underlying encoder to achieve higher performance on localized retrieval tasks.
- It integrates directly into multi-agent LLM setups by enabling tighter, role-specific retrieval windows over shared corpora.
- Performance on controlled synthetic data with single-position spikes reaches Recall@10 of 1.0 when spike strength exceeds token noise floor.
Where Pith is reading between the lines
- Similar convolution approaches might apply to other embedding-based tasks beyond retrieval, such as question answering over long documents.
- Testing on datasets with varying degrees of localization could reveal the scales at which the method provides the most benefit.
- The provable informativeness of the max score suggests it could be used as a drop-in replacement in existing late-interaction systems.
Load-bearing premise
That the planted single-position spikes in the synthetic benchmark and the relevance structure in LIMIT-small represent how relevance localizes in real-world documents used by multi-agent LLM systems.
What would settle it
If applying Spectral Retrieval to a new dataset where relevance is uniformly distributed across entire documents shows no improvement or a decrease in Recall@10 compared to mean pooling, that would indicate the method's benefit is limited to localized cases.
Figures

read the original abstract
[Abridged] - Spectral Retrieval is a plug-in re-ranking stage that interpolates between per-token MaxSim and mean-pool retrieval through a multi-scale sinc convolution over token embeddings. In standard dense retrieval each document is one mean-pooled vector; when relevance localises into a short subspan, the signal averages into noise. Spectral Retrieval reuses per-token embeddings from a late-interaction index and convolves them with a normalised sinc kernel at multiple scales. At L=1 the kernel acts as the identity, recovering per-token MaxSim; as L grows it approaches a uniform filter, recovering mean pooling. The maximum cosine over positions and scales yields a score provably no less informative than either endpoint. On a controlled synthetic benchmark with 1,000 documents and planted single-position spikes, mean-pool retrieval sits at chance (Recall@10 ~ 0.02) regardless of spike strength, while Spectral Retrieval reaches Recall@10 = 1.0 once the planted cosine exceeds the corpus-level token noise floor. On LIMIT-small with a frozen all-mpnet-base-v2 encoder, Spectral Retrieval lifts Recall@10 from 0.33 to 0.90, MRR from 0.22 to 0.79, and strict Success@10 from 0.12 to 0.84, without retraining. The method fits naturally into multi-agent LLM systems, where each agent benefits from a tighter, role-specific retrieval window over a shared corpus.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Spectral Retrieval as a plug-in re-ranking stage for dense retrieval that applies multi-scale normalized sinc convolutions to per-token embeddings. It claims to interpolate between per-token MaxSim (at L=1, identity kernel) and mean pooling (large L, uniform filter), with the maximum cosine over all positions and scales being provably no less informative than either endpoint. On a synthetic benchmark with planted single-position spikes, it reaches perfect Recall@10 once spike strength exceeds noise; on LIMIT-small with frozen all-mpnet-base-v2, it lifts Recall@10 from 0.33 to 0.90, MRR from 0.22 to 0.79, and Success@10 from 0.12 to 0.84 without retraining, positioning the method for LLM multi-agent systems.
Significance. If the empirical gains are robust, the approach offers a lightweight way to improve localized retrieval without retraining encoders, which could be practically useful in multi-agent LLM setups. The reported lifts on the given benchmarks are substantial, but the theoretical non-inferiority claim adds no new information beyond the explicit inclusion of the endpoint regimes.
major comments (1)
- [Abstract] Abstract: the claim that 'the maximum cosine over positions and scales yields a score provably no less informative than either endpoint' is tautological by construction. The scale parameter L is defined to include L=1 (recovering MaxSim) and large L (recovering mean pooling) as special cases, so the max score is definitionally at least as large as the better endpoint without any property of the normalized sinc kernel, multi-scale sampling, or convolution being required.
minor comments (2)
- The manuscript should clarify the exact sampling of scales, the normalization procedure for the sinc kernel, and any additional non-tautological properties derived from the spectral construction to support reproducibility.
- The synthetic benchmark and LIMIT-small results would benefit from an error analysis or ablation isolating the contribution of intermediate scales versus the endpoints.
Simulated Author's Rebuttal
We thank the referee for their detailed review and for identifying the issue with the theoretical claim in the abstract. We address the comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'the maximum cosine over positions and scales yields a score provably no less informative than either endpoint' is tautological by construction. The scale parameter L is defined to include L=1 (recovering MaxSim) and large L (recovering mean pooling) as special cases, so the max score is definitionally at least as large as the better endpoint without any property of the normalized sinc kernel, multi-scale sampling, or convolution being required.
Authors: We agree with the referee that the non-inferiority of the max score to the endpoint regimes follows directly from the construction of the scale set and is therefore tautological; it does not depend on any property of the normalized sinc kernel or the convolution operation. The claim adds no new theoretical information. We will revise the abstract to remove this phrasing entirely and instead focus on the practical interpolation behavior and the empirical gains shown on the synthetic and LIMIT-small benchmarks. revision: yes
Circularity Check
Max-over-scales non-inferiority claim is tautological by construction from including endpoints
specific steps
-
self definitional
[Abstract]
"The maximum cosine over positions and scales yields a score provably no less informative than either endpoint. ... At L=1 the kernel acts as the identity, recovering per-token MaxSim; as L grows it approaches a uniform filter, recovering mean pooling."
The score is defined as the max over a set of scales that explicitly contains the two endpoint regimes as special cases. The inequality 'max >= better endpoint' is therefore true by construction of the max operator and the scale sampling; it does not depend on the sinc kernel, multi-scale convolution, or any other claimed property of Spectral Retrieval.
full rationale
The paper's central theoretical guarantee reduces directly to the definition of the score. The abstract explicitly states that L=1 recovers MaxSim and large L recovers mean pooling, and the reported score is the maximum over all scales (including those endpoints). The 'provably no less informative' property therefore holds by set inclusion alone, without requiring any property of the sinc kernel, normalization, or convolution. No other circular steps are present; benchmark results use external frozen encoders and are not fitted from the paper's own outputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- scale parameter L
axioms (1)
- standard math Normalized sinc convolution at L=1 acts as identity and approaches uniform averaging as L increases.
Reference graph
Works this paper leans on
-
[1]
ColBERT: Efficient and effective passage search via contextualized late interaction over BERT,
O. Khattab and M. Zaharia, “ColBERT: Efficient and effective passage search via contextualized late interaction over BERT,” inProceed- ings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), 2020, pp. 39–48, arXiv:2004.12832
-
[2]
K. Santhanam, O. Khattab, J. Saad-Falcon, C. Potts, and M. Za- haria, “ColBERTv2: Effective and efficient retrieval via lightweight late interaction,” inProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), 2022, pp. 3715–3734, arXiv:2112.01488
-
[3]
On the theoretical limitations of embedding-based retrieval.arXiv preprint arXiv:2508.21038,
O. Weller, M. Boratko, I. Naim, and J. Lee, “On the theoretical limita- tions of embedding-based retrieval,” arXiv preprint arXiv:2508.21038, 2025
-
[4]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. Küt- tler, M. Lewis, W. tau Yih, T. Rocktäschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive NLP tasks,” inAdvances in Neural Information Processing Systems (NeurIPS), 2020, arXiv:2005.11401
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[5]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
N. Reimers and I. Gurevych, “Sentence-BERT: Sentence embeddings using siamese BERT-networks,” inProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th In- ternational Joint Conference on Natural Language Processing (EMNLP- IJCNLP), 2019, pp. 3982–3992, arXiv:1908.10084
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[6]
Dense Passage Retrieval for Open-Domain Question Answering
V . Karpukhin, B. O ˘guz, S. Min, P. Lewis, L. Wu, S. Edunov, D. Chen, and W. tau Yih, “Dense passage retrieval for open-domain question answering,” inProceedings of the 2020 Conference on Empirical Meth- ods in Natural Language Processing (EMNLP), 2020, pp. 6769–6781, arXiv:2004.04906
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[7]
Sequential consensus for multi-agent LLM debate via wald SPRT,
A. Morandi, “Sequential consensus for multi-agent LLM debate via wald SPRT,” Companion manuscript, in preparation, 2026
2026
-
[8]
SPLADE: Sparse lexical and expansion model for first stage ranking,
T. Formal, B. Piwowarski, and S. Clinchant, “SPLADE: Sparse lexical and expansion model for first stage ranking,” inProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), 2021, pp. 2288–2292, arXiv:2107.05720
-
[9]
A theory for multiresolution signal decomposition: The wavelet representation,
S. G. Mallat, “A theory for multiresolution signal decomposition: The wavelet representation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 11, no. 7, pp. 674–693, 1989
1989
-
[10]
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models
N. Thakur, N. Reimers, A. Rücklé, A. Srivastava, and I. Gurevych, “BEIR: A heterogeneous benchmark for zero-shot evaluation of in- formation retrieval models,” inAdvances in Neural Information Pro- cessing Systems, Datasets and Benchmarks Track (NeurIPS), 2021, arXiv:2104.08663
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
MS MARCO: A Human Generated MAchine Reading COmprehension Dataset
P. Bajaj, D. Campos, N. Craswell, L. Deng, J. Gao, X. Liu, R. Majumder, A. McNamara, B. Mitra, T. Nguyen, M. Rosenberg, X. Song, A. Stoica, S. Tiwary, and T. Wang, “MS MARCO: A human generated machine reading comprehension dataset,” 2016, arXiv:1611.09268
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[12]
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering
Z. Yang, P. Qi, S. Zhang, Y . Bengio, W. W. Cohen, R. Salakhutdinov, and C. D. Manning, “HotpotQA: A dataset for diverse, explainable multi- hop question answering,” inProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2018, pp. 2369–2380, arXiv:1809.09600
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[13]
Improving factuality and reasoning in language models through multiagent debate,
Y . Du, S. Li, A. Torralba, J. B. Tenenbaum, and I. Mordatch, “Improving factuality and reasoning in language models through multiagent debate,” inProceedings of the 41st International Conference on Machine Learn- ing (ICML), ser. Proceedings of Machine Learning Research, vol. 235, 2024, pp. 11 733–11 763. 12
2024
-
[14]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. H. Chi, Q. V . Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” inAdvances in Neural Information Processing Systems (NeurIPS), 2022, arXiv:2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.