RouteScan: A Non-Intrusive Approach to Auditing MoE LLMs Safety via Expert Routing Telemetry
Pith reviewed 2026-06-30 00:30 UTC · model grok-4.3
The pith
RouteScan detects harmful prompts in MoE LLMs solely from GPU expert routing telemetry without any access to content.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
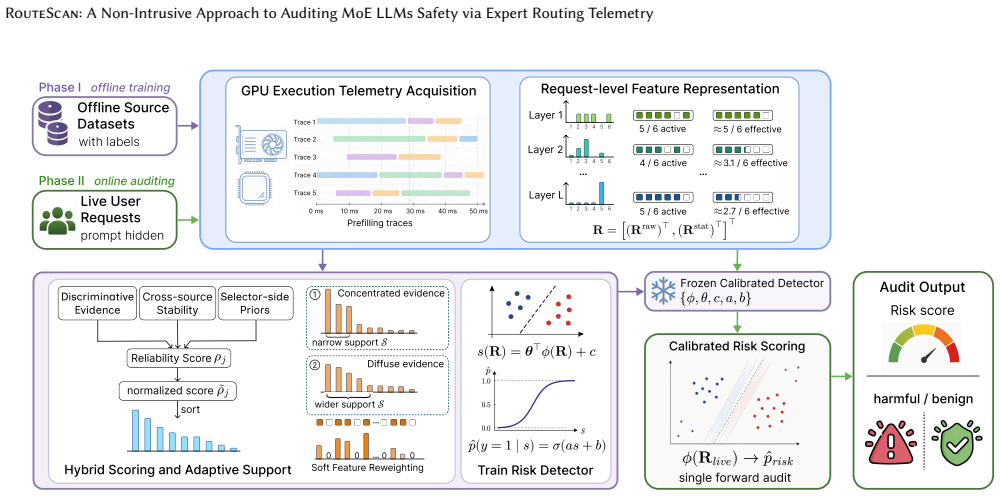
RouteScan utilizes the number of active GPU threads allocated to expert modules during the prefilling phase as a discriminative micro-architectural fingerprint, and builds a lightweight detection pipeline that isolates cross-domain invariant risk indicators for the precise identification of malicious prompts.
What carries the argument
Number of active GPU threads allocated to expert modules during prefilling, acting as a cross-domain invariant risk indicator.
If this is right
- Strong generalization with AUROC exceeding 0.93 on unseen harmful domains
- AUROC of 0.96 under novel jailbreak wrappers
- Collected telemetry provides limited information for prompt reconstruction
- Applies to open-source MoE LLMs with distinct routing designs
- Provides a practical privacy advantage over content-based auditing methods
Where Pith is reading between the lines
- This method could enable real-time safety monitoring in cloud deployments without logging user data.
- The approach might extend to detecting other types of anomalous behavior beyond harmfulness.
- Hardware vendors could incorporate similar telemetry-based checks into future accelerator designs.
Load-bearing premise
The number of active GPU threads allocated to expert modules during the prefilling phase forms a cross-domain invariant risk indicator that reliably separates harmful from benign prompts across different MoE routing designs and without access to prompt content.
What would settle it
Finding that the thread allocation counts for harmful prompts match those of benign prompts on an unseen MoE model or that the telemetry allows reliable reconstruction of prompt text.
Figures
read the original abstract
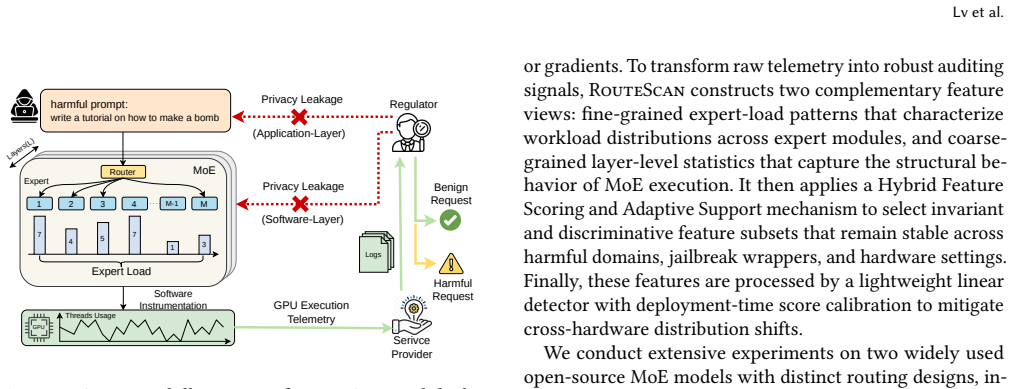
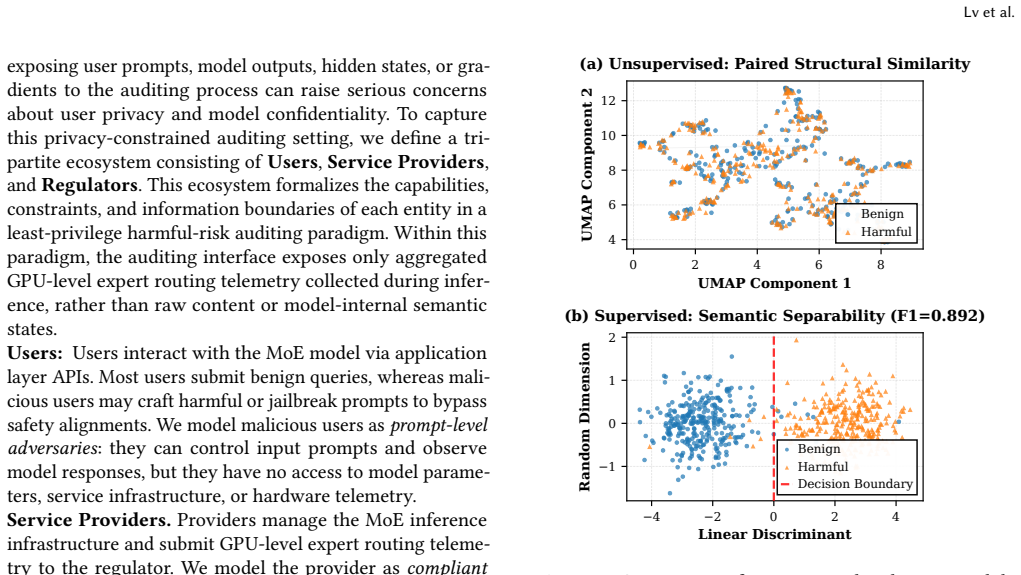
Mixture-of-Experts (MoE) architectures have become an increasingly important paradigm for scaling Large Language Models (LLMs). As MoE models are increasingly deployed in real-world services, safety auditing becomes necessary to verify whether these models produce or facilitate harmful behaviors during operation. However, existing content-based auditing methods typically require access to user prompts, model inputs, or generated outputs, potentially exposing sensitive user information and creating a fundamental tension between LLM safety and user privacy. On the other hand, we observe that, in MoE models, sparse expert routing maps different inputs to activate different expert-execution patterns, producing measurable footprints in low-level GPU execution telemetry. Inspired by this observation, we propose RouteScan, a non-intrusive auditing framework for detecting harmful behaviors through GPU-level expert routing telemetry. Specifically, RouteScan utilizes the number of active GPU threads allocated to expert modules during the prefilling phase as a discriminative micro-architectural fingerprint, and builds a lightweight detection pipeline that isolates cross-domain invariant risk indicators for the precise identification of malicious prompts. Comprehensive evaluations on open-source MoE LLMs with distinct routing designs demonstrate that RouteScan achieves strong generalization, with an AUROC exceeding 0.93 on unseen harmful domains and 0.96 under novel jailbreak wrappers. Moreover, empirical inversion tests show that the collected expert routing telemetry provides limited information for prompt reconstruction, suggesting a practical privacy advantage over content-based auditing methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RouteScan, a non-intrusive auditing method for Mixture-of-Experts LLMs that detects harmful prompts solely from the count of active GPU threads allocated to expert modules during the prefilling phase. It claims this telemetry yields cross-domain invariant risk indicators, achieving AUROC exceeding 0.93 on unseen harmful domains and 0.96 under novel jailbreak wrappers across distinct routing designs, while inversion tests indicate limited prompt reconstructability and thus a privacy advantage over content-based methods.
Significance. If the central claim holds after addressing potential confounds, the work would offer a practical privacy-preserving auditing technique for deployed MoE models, directly addressing the safety-privacy tension in real-world LLM services. The inclusion of empirical inversion tests is a positive element that supports the privacy aspect of the contribution.
major comments (2)
- [Abstract] Abstract: the reported AUROC values (>0.93 unseen domains, >0.96 jailbreaks) are presented without any indication that sequence length, token distribution, or batch-size effects were matched or regressed out between harmful and benign sets; because the thread-count signal is produced by sparse routing on input tokens, systematic differences in prompt length or syntactic complexity between classes would directly confound the claimed cross-domain invariance.
- [Evaluation] The core assumption that the active-GPU-thread count during prefilling isolates a content-independent risk indicator that generalizes across routing designs rests on an empirical observation rather than a derivation; without explicit length-matched controls or ablations in the evaluation, the generalization numbers cannot be interpreted as evidence for semantic harm detection rather than superficial statistics.
minor comments (1)
- The manuscript should supply the precise definitions of the MoE models, routing mechanisms, and datasets used, along with error bars and baseline comparisons, to allow replication of the reported AUROCs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The points raised about potential confounds from sequence length and related factors are important, and we will revise the manuscript to include explicit controls and ablations addressing them.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported AUROC values (>0.93 unseen domains, >0.96 jailbreaks) are presented without any indication that sequence length, token distribution, or batch-size effects were matched or regressed out between harmful and benign sets; because the thread-count signal is produced by sparse routing on input tokens, systematic differences in prompt length or syntactic complexity between classes would directly confound the claimed cross-domain invariance.
Authors: We agree that the abstract does not indicate controls for sequence length, token distribution, or batch-size effects. Our original experiments used diverse prompts from standard datasets without explicit length matching or regression. We will add new experiments using length-matched harmful and benign prompt sets, perform regression to isolate effects, and update both the abstract and evaluation section to report these controls. This will clarify that the reported AUROCs reflect the routing signal beyond superficial statistics. revision: yes
-
Referee: [Evaluation] The core assumption that the active-GPU-thread count during prefilling isolates a content-independent risk indicator that generalizes across routing designs rests on an empirical observation rather than a derivation; without explicit length-matched controls or ablations in the evaluation, the generalization numbers cannot be interpreted as evidence for semantic harm detection rather than superficial statistics.
Authors: The contribution is empirical, relying on cross-domain and cross-model generalization results rather than a closed-form derivation. We acknowledge that without length-matched controls the results could be influenced by superficial prompt statistics. To strengthen the interpretation, the revision will include dedicated ablations with length-matched prompt pairs, token-distribution balancing, and batch-size controls, allowing direct comparison of AUROC before and after these adjustments. This will provide clearer evidence on whether the signal captures semantic risk indicators. revision: yes
Circularity Check
No significant circularity; empirical observation and evaluation, not a derivation.
full rationale
The paper proposes RouteScan as an empirical auditing method based on the observed correlation between expert routing telemetry (specifically active GPU thread counts during prefilling) and prompt harmfulness. No equations, derivations, or fitted parameters are presented that reduce the claimed risk indicator to its own inputs by construction. The approach is validated through direct experiments on open-source MoE models with reported AUROC metrics on held-out data; no self-citation chains or uniqueness theorems are invoked as load-bearing. This is a standard empirical contribution whose central claim stands or falls on the external validity of the telemetry-harm correlation, not on internal definitional reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sparse expert routing in MoE models produces measurable and domain-invariant footprints in GPU thread allocation that can be isolated as risk indicators for harmful prompts.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, 12 RouteScan: A Non-Intrusive Approach to Auditing MoE LLMs Safety via Expert Routing Telemetry Sam Altman, Shyamal Anadkat, et al . 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Gabriel Alon and Michael Kamfonas. 2023. Detecting Language Model Attacks with Perplexity. (2023). arXiv:2308.14132 [cs.CL]https: //arxiv.org/abs/2308.14132
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Rishabh Bhardwaj, Duc Anh Do, and Soujanya Poria. 2024. Language models are homer simpson! safety re-alignment of fine-tuned language models through task arithmetic. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 14138–14149
2024
-
[4]
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J Pappas, and Eric Wong. 2025. Jailbreaking black box large language models in twenty queries. In2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML). IEEE, 23–42
2025
-
[5]
Guorui Chen, Yifan Xia, Xiaojun Jia, Zhijiang Li, Philip Torr, and Jindong Gu. 2025. LLM Jailbreak Detection for (Almost) Free!. In EMNLP (Findings). Association for Computational Linguistics, 5777– 5807
2025
-
[6]
Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y
Damai Dai, Chengqi Deng, Chenggang Zhao, R.x. Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y. Wu, Zhenda Xie, Y.k. Li, Panpan Huang, Fuli Luo, Chong Ruan, Zhifang Sui, and Wenfeng Liang. 2024. DeepSeekMoE: Towards Ultimate Expert Spe- cialization in Mixture-of-Experts Language Models. InProceedings of the 62nd Annual Meeting of the Ass...
-
[7]
Ruyi Ding, Tianhong Xu, Xinyi Shen, Aidong Adam Ding, and Yunsi Fei. 2025. MoEcho: Exploiting Side-Channel Attacks to Compromise User Privacy in Mixture-of-Experts LLMs. InCCS. ACM, 2159–2173
2025
-
[8]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch Trans- formers: Scaling to Trillion Parameter Models with Simple and Effi- cient Sparsity.J. Mach. Learn. Res.23 (2022), 120:1–120:39
2022
-
[9]
Zekun Fei, Zihao Wang, Weijie Liu, Ruiqi He, Jianing Geng, Zheli Liu, and XiaoFeng Wang. 2026. Misrouter: Exploiting Routing Mechanisms for Input-Only Attacks on Mixture-of-Experts LLMs. arXiv:2605.04446 [cs.CR]https://arxiv.org/abs/2605.04446
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Ronald A Fisher. 1936. The use of multiple measurements in taxonomic problems.Annals of eugenics7, 2 (1936), 179–188
1936
- [11]
- [12]
-
[13]
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, and Madian Khabsa. 2023. Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations. arXiv:2312.06674 [cs.CL]https://arxiv.org/abs/2312.06674
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Neel Jain, Avi Schwarzschild, Yuxin Wen, Gowthami Somepalli, John Kirchenbauer, Ping yeh Chiang, Micah Goldblum, Anirud- dha Saha, Jonas Geiping, and Tom Goldstein. 2023. Baseline De- fenses for Adversarial Attacks Against Aligned Language Models. arXiv:2309.00614 [cs.LG]https://arxiv.org/abs/2309.00614
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Sunjun Kweon, Junu Kim, Jiyoun Kim, Sujeong Im, Eunbyeol Cho, Seongsu Bae, Jungwoo Oh, Gyubok Lee, Jong Hak Moon, Seng Chan You, Seungjin Baek, Chang Hoon Han, Yoon Bin Jung, Yohan Jo, and Edward Choi. 2024. Publicly Shareable Clinical Large Language Model Built on Synthetic Clinical Notes. InACL (Findings) (Findings of ACL). Association for Computational...
2024
-
[16]
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. 2021. GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding. InICLR. OpenReview.net
2021
- [17]
-
[18]
Oswald, Michael Schwarz, Catherine Easdon, Claudio Canella, and Daniel Gruss
Moritz Lipp, Andreas Kogler, David F. Oswald, Michael Schwarz, Catherine Easdon, Claudio Canella, and Daniel Gruss. 2021. PLATY- PUS: Software-based Power Side-Channel Attacks on x86. InSP. IEEE, 355–371
2021
-
[19]
Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, et al. 2024. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model.arXiv preprint arXiv:2405.04434(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. 2023. Au- toDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models.ArXivabs/2310.04451 (2023).https://api. semanticscholar.org/CorpusID:263831566
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Ka Man Lo, Zeyu Huang, Zihan Qiu, Zili Wang, and Jie Fu. 2025. A Closer Look into Mixture-of-Experts in Large Language Models. In NAACL (Findings) (Findings of ACL). Association for Computational Linguistics, 4427–4447
2025
-
[22]
Huijie Lv, Xiao Wang, Yuan Zhang, Caishuang Huang, Shihan Dou, Junjie Ye, Tao Gui, Qi Zhang, and Xuanjing Huang. 2024. CodeChameleon: Personalized Encryption Framework for Jailbreak- ing Large Language Models.ArXivabs/2402.16717 (2024).https: //api.semanticscholar.org/CorpusID:268032340
-
[23]
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, et al
-
[24]
Harmbench: A standardized evaluation framework for auto- mated red teaming and robust refusal.arXiv preprint arXiv:2402.04249 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Leland McInnes, John Healy, Nathaniel Saul, and Lukas Großberger
-
[26]
UMAP: Uniform manifold approximation and projection.Journal of Open Source Software, 3(29):861, 2018
UMAP: Uniform Manifold Approximation and Projection.Jour- nal of Open Source Software3, 29 (2018), 861. doi:10.21105/joss.00861
-
[27]
Meta. 2025. Llama-4-Scout-17B-16E-Original.https://huggingface.co/ meta-llama/Llama-4-Scout-17B-16E-Original. Computer software
2025
-
[28]
Jakob Mökander, Maria Axente, Federico Casolari, and Luciano Floridi
-
[29]
Conformity Assessments and Post-market Monitoring: A Guide to the Role of Auditing in the Proposed European AI Regulation.Minds Mach.32, 2 (2022), 241–268
2022
-
[30]
Morris, Volodymyr Kuleshov, Vitaly Shmatikov, and Alexan- der M
John X. Morris, Volodymyr Kuleshov, Vitaly Shmatikov, and Alexan- der M. Rush. 2023. Text Embeddings Reveal (Almost) As Much As Text. InEMNLP. Association for Computational Linguistics, 12448–12460
2023
-
[31]
Abu- Ghazaleh
Hoda Naghibijouybari, Ajaya Neupane, Zhiyun Qian, and Nael B. Abu- Ghazaleh. 2018. Rendered Insecure: GPU Side Channel Attacks are Practical. InCCS. ACM, 2139–2153
2018
-
[32]
Amir Nuriyev and Gabriel Kulp. 2026. Expert Selections In MoE Models Reveal (Almost) As Much As Text. arXiv:2602.04105 [cs.CL] doi:10.48550/arXiv.2602.04105
-
[33]
John Platt et al. 1999. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods.Advances in large margin classifiers10, 3 (1999), 61–74
1999
-
[34]
Weiwei Qi, Shuo Shao, Wei Gu, Tianhang Zheng, Puning Zhao, Zhan Qin, and Kui Ren. 2026. Majic: Markovian adaptive jailbreaking via iterative composition of diverse innovative strategies. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 32755–32763
2026
-
[35]
Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. 2024. Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!. InThe Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=hTEGyKf0dZ
2024
-
[36]
Cheng Qian, Hainan Zhang, Lei Sha, and Zhiming Zheng. 2025. HSF: Defending against Jailbreak Attacks with Hidden State Filtering. In 13 Lv et al. WWW (Companion Volume). ACM, 2078–2087
2025
-
[37]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2019. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.J. Mach. Learn. Res.21 (2019), 140:1–140:67.https: //api.semanticscholar.org/CorpusID:204838007
2019
-
[38]
Samyam Rajbhandari, Conglong Li, Zhewei Yao, Minjia Zhang, Reza Yazdani Aminabadi, Ammar Ahmad Awan, Jeff Rasley, and Yux- iong He. 2022. DeepSpeed-MoE: Advancing Mixture-of-Experts In- ference and Training to Power Next-Generation AI Scale. InICML (Proceedings of Machine Learning Research). PMLR, 18332–18346
2022
-
[39]
Protection Regulation. 2016. Regulation (EU) 2016/679 of the European Parliament and of the Council.Regulation (eu)679, 2016 (2016), 10–3
2016
-
[40]
Pap- pas
Alexander Robey, Eric Wong, Hamed Hassani, and George J. Pap- pas. 2025. SmoothLLM: Defending Large Language Models Against Jailbreaking Attacks.Trans. Mach. Learn. Res.2025 (2025)
2025
-
[41]
C. E. Shannon. 1948. A mathematical theory of communication.The Bell System Technical Journal27, 3 (1948), 379–423. doi:10.1002/j.1538- 7305.1948.tb01338.x
-
[42]
Le, Geoffrey E
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc V. Le, Geoffrey E. Hinton, and Jeff Dean. 2017. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. InICLR (Poster). OpenReview.net
2017
-
[43]
Alexandra Souly, Qingyuan Lu, Dillon Bowen, Tu Trinh, Elvis Hsieh, Sana Pandey, Pieter Abbeel, Justin Svegliato, Scott Emmons, Olivia Watkins, and Sam Toyer. 2024. A StrongREJECT for Empty Jailbreaks. InNeurIPS
2024
-
[44]
Gemini Team. 2024. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
2024.Synthetic Clinical Notes Embedded
Technoculture. 2024.Synthetic Clinical Notes Embedded
2024
-
[46]
Rogers, Don Maxwell, Paolo Rech, Sudharshan S
Devesh Tiwari, Saurabh Gupta, James H. Rogers, Don Maxwell, Paolo Rech, Sudharshan S. Vazhkudai, Daniel Oliveira, Dave Londo, Nathan DeBardeleben, Philippe Olivier Alexandre Navaux, Luigi Carro, and Arthur S. Bland. 2015. Understanding GPU errors on large-scale HPC systems and the implications for system design and operation. In HPCA. IEEE Computer Societ...
2015
- [47]
-
[48]
Xunguang Wang, Daoyuan Wu, Zhenlan Ji, Zongjie Li, Pingchuan Ma, Shuai Wang, Yingjiu Li, Yang Liu, Ning Liu, and Juergen Rahmel. 2025. SelfDefend: LLMs Can Defend Themselves against Jailbreaking in a Practical Manner. InUSENIX Security Symposium. USENIX Association, 2441–2460
2025
- [49]
-
[50]
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. 2023. Jailbroken: How Does LLM Safety Training Fail?. InNeurIPS
2023
-
[51]
Zeming Wei, Yifei Wang, Ang Li, Yichuan Mo, and Yisen Wang. 2026. Jailbreak and guard aligned language models with only few in-context demonstrations.IEEE Transactions on Pattern Analysis and Machine Intelligence(2026)
2026
-
[52]
Laura Weidinger, Jonathan Uesato, Maribeth Rauh, Conor Griffin, Po- Sen Huang, John Mellor, Amelia Glaese, Myra Cheng, Borja Balle, Atoosa Kasirzadeh, Courtney Biles, Sasha Brown, Zac Kenton, Will Hawkins, Tom Stepleton, Abeba Birhane, Lisa Anne Hendricks, Laura Rimell, William Isaac, Julia Haas, Sean Legassick, Geoffrey Irving, and Iason Gabriel. 2022. T...
2022
-
[53]
Yueqi Xie, Minghong Fang, Renjie Pi, and Neil Gong. 2024. GradSafe: Detecting Jailbreak Prompts for LLMs via Safety-Critical Gradient Analysis. InACL (1). Association for Computational Linguistics, 507– 518
2024
-
[54]
Yueqi Xie, Jingwei Yi, Jiawei Shao, Justin Curl, Lingjuan Lyu, Qifeng Chen, Xing Xie, and Fangzhao Wu. 2023. Defending ChatGPT against jailbreak attack via self-reminders.Nat. Mac. Intell.5, 12 (2023), 1486– 1496
2023
- [55]
-
[56]
Kedong Xiu and Sai Qian Zhang. 2025. CapRecover: A Cross-Modality Feature Inversion Attack Framework on Vision Language Models. In Proceedings of the 33rd ACM International Conference on Multimedia. 3808–3816
2025
-
[57]
Zhiyuan Xu, Joseph Gardiner, Sana Belguith, and Lichao Wu. 2026. RouteHijack: Routing-Aware Attack on Mixture-of-Experts LLMs. (2026). arXiv:2605.02946 [cs.LG]https://arxiv.org/abs/2605.02946
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[58]
Xiaobei Yan, Xiaoxuan Lou, Guowen Xu, Han Qiu, Shangwei Guo, Chip-Hong Chang, and Tianwei Zhang. 2023. MERCURY: An Auto- mated Remote Side-channel Attack to Nvidia Deep Learning Acceler- ator. InICFPT. IEEE, 188–197
2023
-
[59]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, et al. 2024. Qwen2 Technical Report.CoRRabs/2407.10671 (2024). https://doi.org/10.48550/arXiv.2407.10671
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.10671 2024
- [60]
-
[61]
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. 2023. A survey of large language models.arXiv preprint arXiv:2303.182231, 2 (2023), 1–124
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[62]
Ligeng Zhu, Zhijian Liu, and Song Han. 2019. Deep leakage from gradients.Advances in neural information processing systems32 (2019)
2019
-
[63]
Barret Zoph, Irwan Bello, Sameer Kumar, Nan Du, Yanping Huang, Jeff Dean, Noam Shazeer, and William Fedus. 2022. St-moe: De- signing stable and transferable sparse expert models.arXiv preprint arXiv:2202.08906(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[64]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. 2023. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043 (2023). A Implementation of Telemetry Acquisition A.1 Lightweight Software Instrumentation To accurately quantify the dynamic expert load, we im- plemented l...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.