NITP: Next Implicit Token Prediction for LLM Pre-training
Pith reviewed 2026-06-30 12:20 UTC · model grok-4.3
The pith
NITP augments next-token prediction with dense supervision from shallow-layer representations to constrain LLM latent spaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
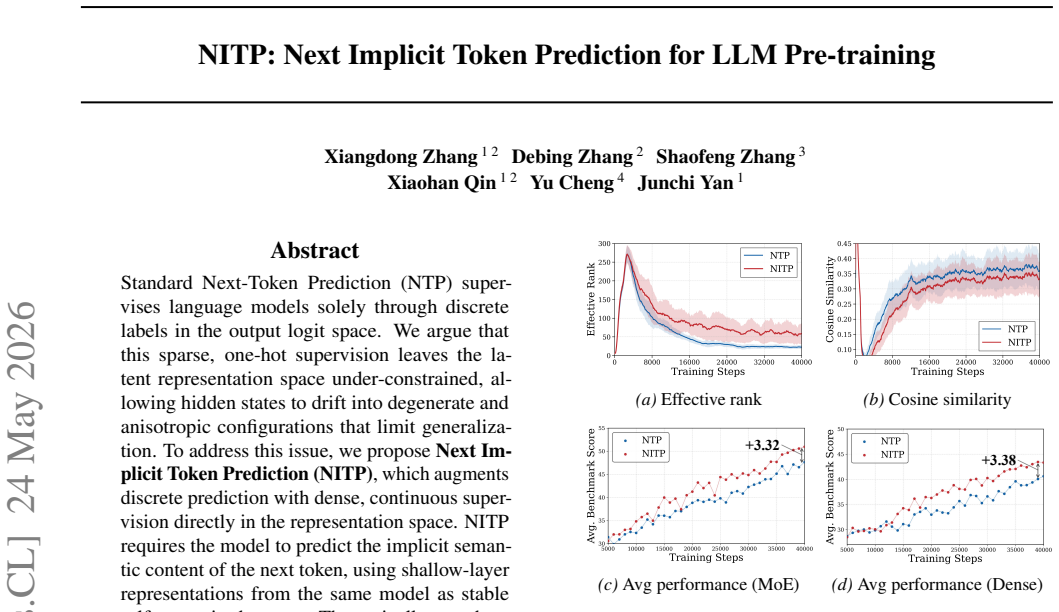
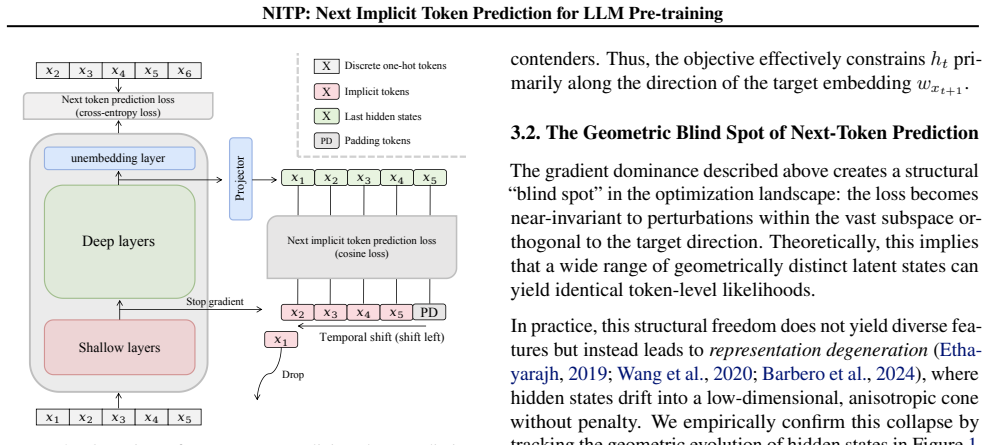
NITP trains the model to predict the implicit semantic content of the next token, using shallow-layer representations from the same model as stable self-supervised targets. This augments discrete next-token prediction with dense continuous supervision directly in the representation space. Theoretical analysis shows that NITP regularizes the optimization landscape by mitigating under-constrained degrees of freedom and encouraging a compact, structured representation geometry.
What carries the argument
Next Implicit Token Prediction (NITP) that uses shallow-layer representations as self-supervised targets for the implicit semantic content of the next token.
If this is right
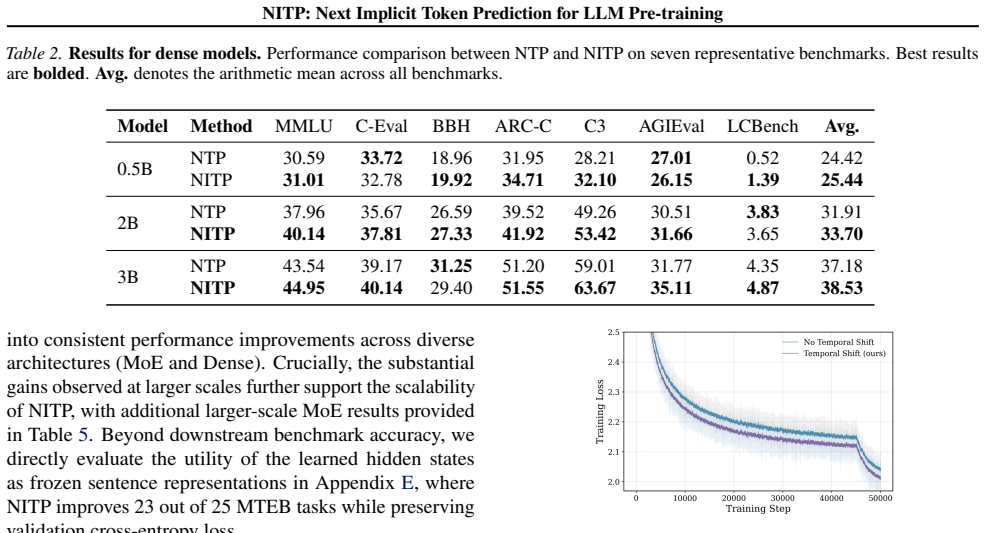
- Consistent downstream gains across dense and MoE models ranging from 0.5B to 9B parameters.
- 5.7% absolute improvement on MMLU-Pro for a 9B MoE model.
- Additional gains of 6.4% on C3 and 4.3% on CommonsenseQA.
- Approximately 2% extra training FLOPs with no added inference cost.
Where Pith is reading between the lines
- The claimed regularization of representation geometry could be directly tested by tracking anisotropy metrics on hidden states before and after NITP training.
- Similar dense supervision from early layers might transfer to non-language modalities where next-token-style objectives exist.
- The low overhead suggests NITP could be stacked with other representation-level regularizers without compounding compute costs.
Load-bearing premise
Shallow-layer representations from the same model provide stable self-supervised targets for the implicit semantic content of the next token without introducing instability or circular dependencies during training.
What would settle it
Running the same pre-training run with and without NITP on a 9B-scale model and finding no improvement (or degradation) on MMLU-Pro or C3 relative to the NTP baseline.
Figures

read the original abstract
Standard next-token prediction (NTP) supervises language models solely through discrete labels in the output logit space. We argue that this sparse one-hot supervision leaves the latent representation space under-constrained, allowing hidden states to drift into degenerate and anisotropic configurations that can limit generalization. To address this issue, we propose Next Implicit Token Prediction (NITP), which augments discrete prediction with dense continuous supervision directly in the representation space. NITP trains the model to predict the implicit semantic content of the next token, using shallow-layer representations from the same model as stable self-supervised targets. We provide theoretical analysis showing that NITP regularizes the optimization landscape by mitigating under-constrained degrees of freedom and encouraging a compact, structured representation geometry. Empirically, across dense and MoE models ranging from 0.5B to 9B parameters, NITP consistently improves downstream performance with negligible computational overhead. On a 9B MoE model, NITP achieves a 5.7% absolute improvement on MMLU-Pro, along with gains of 6.4% on C3 and 4.3% on CommonsenseQA, with approximately 2% additional training FLOPs and no additional inference cost. Our implementation is available at https://github.com/aHapBean/NITP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard next-token prediction (NTP) leaves the latent representation space under-constrained, leading to degenerate and anisotropic hidden states. It proposes Next Implicit Token Prediction (NITP), which augments NTP with dense continuous supervision by training the model to predict the implicit semantic content of the next token using shallow-layer representations from the same model as stable self-supervised targets. The paper provides a theoretical analysis showing that NITP regularizes the optimization landscape and reports empirical results across dense and MoE models (0.5B to 9B parameters) with consistent downstream gains, including a 5.7% absolute improvement on MMLU-Pro for a 9B MoE model, at roughly 2% additional training FLOPs and no inference cost. Code is released at https://github.com/aHapBean/NITP.
Significance. If the stability of the moving targets and the claimed regularization effect hold under joint optimization, NITP would offer a low-overhead method to improve representation geometry during pre-training of both dense and MoE models. The reported gains on multiple benchmarks and the public implementation supporting reproducibility are concrete strengths.
major comments (2)
- [Abstract] Abstract: The central claim that shallow-layer representations serve as 'stable' self-supervised targets is load-bearing for both the theoretical regularization argument and the empirical gains. Because these targets are computed from shallow layers updated by the same optimizer on the same forward pass, they are non-stationary; the manuscript supplies no measurement of target drift (e.g., cosine similarity of shallow states on held-out prefixes across training steps), no ablation separating stability from the claimed benefit, and no analysis showing that joint dynamics avoid oscillatory or collapsed solutions.
- [Abstract] Abstract: The theoretical analysis is invoked to show that NITP 'regularizes the optimization landscape by mitigating under-constrained degrees of freedom,' yet the provided text contains no equations, derivations, or formal statements of the analysis, preventing evaluation of whether the claimed mitigation follows from the construction or is contradicted by the moving-target supervision.
minor comments (1)
- [Abstract] Abstract: Experimental details (baselines, number of runs, variance, exact model configurations, and training hyperparameters) are absent, making it difficult to assess the reported improvements such as the 5.7% MMLU-Pro gain.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the two major comments below. Both points identify substantive gaps in the submitted version, and we will incorporate the requested evidence and formalization in a revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that shallow-layer representations serve as 'stable' self-supervised targets is load-bearing for both the theoretical regularization argument and the empirical gains. Because these targets are computed from shallow layers updated by the same optimizer on the same forward pass, they are non-stationary; the manuscript supplies no measurement of target drift (e.g., cosine similarity of shallow states on held-out prefixes across training steps), no ablation separating stability from the claimed benefit, and no analysis showing that joint dynamics avoid oscillatory or collapsed solutions.
Authors: We agree that the targets are non-stationary by construction. Our use of the term 'stable' was intended to reflect the empirical observation that shallow-layer representations change more slowly than deeper ones, but this was not quantified. We will add (i) measurements of target drift via cosine similarity on held-out prefixes across training checkpoints, (ii) an ablation that isolates the effect of target stability (e.g., by freezing shallow layers at selected points), and (iii) monitoring of loss curves and representation metrics to check for oscillatory or collapsed behavior under joint optimization. These additions will be included in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: The theoretical analysis is invoked to show that NITP 'regularizes the optimization landscape by mitigating under-constrained degrees of freedom,' yet the provided text contains no equations, derivations, or formal statements of the analysis, preventing evaluation of whether the claimed mitigation follows from the construction or is contradicted by the moving-target supervision.
Authors: The submitted version omitted the theoretical analysis section. The full manuscript contains a dedicated section with the formal argument, including the loss formulation, a derivation showing how the additional continuous supervision term reduces the effective degrees of freedom in the representation space, and a discussion of its interaction with the moving targets. We will restore and expand this section in the revision, explicitly addressing whether the regularization holds under non-stationary targets. revision: yes
Circularity Check
NITP targets defined from model's own shallow layers reduce supervision to internal states
specific steps
-
self definitional
[Abstract]
"NITP trains the model to predict the implicit semantic content of the next token, using shallow-layer representations from the same model as stable self-supervised targets."
The target for the 'implicit semantic content' at position t+1 is the shallow-layer representation computed by the identical model on the same pass; therefore the added loss term is constructed from the model's internal states rather than an independent signal, rendering the regularization effect partly definitional.
full rationale
The core NITP mechanism defines its dense supervision signal directly from the shallow-layer hidden states of the model under training on the same forward pass. This makes the claimed regularization of the representation geometry dependent on the model's own evolving parameters rather than an external or fixed target, so the 'mitigation of under-constrained degrees of freedom' follows in part by construction of the loss. Empirical gains are reported but the theoretical analysis rests on the unverified stability assertion for these moving targets.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Ainslie, J., Lee-Thorp, J., De Jong, M., Zemlyanskiy, Y., Lebr \'o n, F., and Sanghai, S. Gqa: Training generalized multi-query transformer models from multi-head checkpoints. arXiv preprint arXiv:2305.13245, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Transformers need glasses! information over-squashing in language tasks
Barbero, F., Banino, A., Kapturowski, S., Kumaran, D., Madeira Ara \'u jo, J., Vitvitskyi, O., Pascanu, R., and Veli c kovi \'c , P. Transformers need glasses! information over-squashing in language tasks. Advances in Neural Information Processing Systems, 37: 0 98111--98142, 2024
2024
-
[4]
Representation learning: A review and new perspectives
Bengio, Y., Courville, A., and Vincent, P. Representation learning: A review and new perspectives. IEEE transactions on pattern analysis and machine intelligence, 35 0 (8): 0 1798--1828, 2013
2013
-
[5]
Next token prediction towards multimodal intelligence: A comprehensive survey
Chen, L., Wang, Z., Ren, S., Li, L., Zhao, H., Li, Y., Cai, Z., Guo, H., Zhang, L., Xiong, Y., et al. Next token prediction towards multimodal intelligence: A comprehensive survey. arXiv preprint arXiv:2412.18619, 2024
-
[6]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Opencompass: A universal evaluation platform for foundation models
Contributors, O. Opencompass: A universal evaluation platform for foundation models. https://github.com/open-compass/opencompass, 2023
2023
-
[9]
Ethayarajh, K. How contextual are contextualized word representations? comparing the geometry of bert, elmo, and gpt-2 embeddings. arXiv preprint arXiv:1909.00512, 2019
-
[10]
Representation degeneration problem in training natural language generation models
Gao, J., He, D., Tan, X., Qin, T., Wang, L., and Liu, T.-Y. Representation degeneration problem in training natural language generation models. arXiv preprint arXiv:1907.12009, 2019
-
[11]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Gao, L., Biderman, S., Black, S., Golding, L., Hoppe, T., Foster, C., Phang, J., He, H., Thite, A., Nabeshima, N., et al. The pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[12]
Better & Faster Large Language Models via Multi-token Prediction
Gloeckle, F., Idrissi, B. Y., Rozi \`e re, B., Lopez-Paz, D., and Synnaeve, G. Better & faster large language models via multi-token prediction. arXiv preprint arXiv:2404.19737, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Bootstrap your own latent-a new approach to self-supervised learning
Grill, J.-B., Strub, F., Altch \'e , F., Tallec, C., Richemond, P., Buchatskaya, E., Doersch, C., Avila Pires, B., Guo, Z., Gheshlaghi Azar, M., et al. Bootstrap your own latent-a new approach to self-supervised learning. Advances in neural information processing systems, 33: 0 21271--21284, 2020
2020
-
[14]
Minillm: Knowledge distillation of large language models
Gu, Y., Dong, L., Wei, F., and Huang, M. Minillm: Knowledge distillation of large language models. In International Conference on Learning Representations, volume 2024, pp.\ 32694--32717, 2024 a
2024
-
[15]
Xiezhi: An ever-updating benchmark for holistic domain knowledge evaluation
Gu, Z., Zhu, X., Ye, H., Zhang, L., Wang, J., Zhu, Y., Jiang, S., Xiong, Z., Li, Z., Wu, W., et al. Xiezhi: An ever-updating benchmark for holistic domain knowledge evaluation. In Proceedings of the AAAI conference on artificial intelligence, volume 38, pp.\ 18099--18107, 2024 b
2024
-
[16]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
and Su, W
He, H. and Su, W. J. A law of next-token prediction in large language models. Physical Review E, 112 0 (3): 0 035317, 2025
2025
-
[18]
Measuring Massive Multitask Language Understanding
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[19]
Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., Casas, D. d. L., Hendricks, L. A., Welbl, J., Clark, A., et al. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models
Huang, Y., Bai, Y., Zhu, Z., Zhang, J., Zhang, J., Su, T., Liu, J., Lv, C., Zhang, Y., Fu, Y., et al. C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models. Advances in Neural Information Processing Systems, 36: 0 62991--63010, 2023
2023
-
[21]
Tinybert: Distilling bert for natural language understanding
Jiao, X., Yin, Y., Shang, L., Jiang, X., Chen, X., Li, L., Wang, F., and Liu, Q. Tinybert: Distilling bert for natural language understanding. In Findings of the association for computational linguistics: EMNLP 2020, pp.\ 4163--4174, 2020
2020
-
[22]
Scaling Laws for Neural Language Models
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[23]
When choosing plausible alternatives, clever hans can be clever
Kavumba, P., Inoue, N., Heinzerling, B., Singh, K., Reisert, P., and Inui, K. When choosing plausible alternatives, clever hans can be clever. arXiv preprint arXiv:1911.00225, 2019
-
[24]
Lee, S., Kang, M., Lee, J., Hwang, S. J., and Kawaguchi, K. Self-distillation for further pre-training of transformers. arXiv preprint arXiv:2210.02871, 2022
-
[25]
Less is more: Task-aware layer-wise distillation for language model compression
Liang, C., Zuo, S., Zhang, Q., He, P., Chen, W., and Zhao, T. Less is more: Task-aware layer-wise distillation for language model compression. In International Conference on Machine Learning, pp.\ 20852--20867. PMLR, 2023
2023
-
[26]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Liu, A., Feng, B., Wang, B., Wang, B., Liu, B., Zhao, C., Dengr, C., Ruan, C., Dai, D., Guo, D., et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model. arXiv preprint arXiv:2405.04434, 2024 a
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437, 2024 b
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
L-mtp: Leap multi-token prediction beyond adjacent context for large language models
Liu, X., Xia, X., Zhao, W., Zhang, M., Yu, X., Su, X., Yang, S., Ng, S.-K., and Chua, T.-S. L-mtp: Leap multi-token prediction beyond adjacent context for large language models. arXiv preprint arXiv:2505.17505, 2025
-
[29]
Liu, Z., Kong, C., Liu, Y., and Sun, M. Fantastic semantics and where to find them: Investigating which layers of generative llms reflect lexical semantics. arXiv preprint arXiv:2403.01509, 2024 c
-
[30]
Y., Pezeshki, M., Mitliagkas, I., Lopez-Paz, D., and Ahuja, K
Mahajan, D., Goyal, S., Idrissi, B. Y., Pezeshki, M., Mitliagkas, I., Lopez-Paz, D., and Ahuja, K. Beyond multi-token prediction: Pretraining llms with future summaries. arXiv preprint arXiv:2510.14751, 2025
-
[31]
Language Models are Few-Shot Learners
Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., et al. Language models are few-shot learners. arXiv preprint arXiv:2005.14165, 1 0 (3): 0 3, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[32]
New insights and perspectives on the natural gradient method
Martens, J. New insights and perspectives on the natural gradient method. Journal of Machine Learning Research, 21 0 (146): 0 1--76, 2020
2020
-
[33]
Mteb: Massive text embedding benchmark
Muennighoff, N., Tazi, N., Magne, L., and Reimers, N. Mteb: Massive text embedding benchmark. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pp.\ 2014--2037, 2023
2014
-
[34]
Oord, A. v. d., Li, Y., and Vinyals, O. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[35]
Pal, K., Sun, J., Yuan, A., Wallace, B. C., and Bau, D. Future lens: Anticipating subsequent tokens from a single hidden state. arXiv preprint arXiv:2311.04897, 2023
-
[36]
The lambada dataset: Word prediction requiring a broad discourse context
Paperno, D., Kruszewski, G., Lazaridou, A., Pham, N.-Q., Bernardi, R., Pezzelle, S., Baroni, M., Boleda, G., and Fern \'a ndez, R. The lambada dataset: Word prediction requiring a broad discourse context. In Proceedings of the 54th annual meeting of the association for computational linguistics (volume 1: Long papers), pp.\ 1525--1534, 2016
2016
-
[37]
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., and Liu, P. J. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21 0 (140): 0 1--67, 2020
2020
-
[38]
FitNets: Hints for Thin Deep Nets
Romero, A., Ballas, N., Kahou, S. E., Chassang, A., Gatta, C., and Bengio, Y. Fitnets: Hints for thin deep nets. arxiv 2014. arXiv preprint arXiv:1412.6550, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[39]
and Vetterli, M
Roy, O. and Vetterli, M. The effective rank: A measure of effective dimensionality. In 2007 15th European signal processing conference, pp.\ 606--610. IEEE, 2007
2007
-
[40]
Your llm knows the future: Uncovering its multi-token prediction potential
Samragh, M., Kundu, A., Harrison, D., Nishu, K., Naik, D., Cho, M., and Farajtabar, M. Your llm knows the future: Uncovering its multi-token prediction potential. arXiv preprint arXiv:2507.11851, 2025
-
[41]
GLU Variants Improve Transformer
Shazeer, N. Glu variants improve transformer. arXiv preprint arXiv:2002.05202, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[42]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., and Dean, J. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[43]
Layer by Layer: Uncovering Hidden Representations in Language Models
Skean, O., Arefin, M. R., Zhao, D., Patel, N., Naghiyev, J., LeCun, Y., and Shwartz-Ziv, R. Layer by layer: Uncovering hidden representations in language models. arXiv preprint arXiv:2502.02013, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Investigating prior knowledge for challenging chinese machine reading comprehension
Sun, K., Yu, D., Yu, D., and Cardie, C. Investigating prior knowledge for challenging chinese machine reading comprehension. Transactions of the Association for Computational Linguistics, 8: 0 141--155, 2020 a
2020
-
[45]
Patient knowledge distillation for bert model compression
Sun, S., Cheng, Y., Gan, Z., and Liu, J. Patient knowledge distillation for bert model compression. arXiv preprint arXiv:1908.09355, 2019
-
[46]
Contrastive distillation on intermediate representations for language model compression
Sun, S., Gan, Z., Fang, Y., Cheng, Y., Wang, S., and Liu, J. Contrastive distillation on intermediate representations for language model compression. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp.\ 498--508, 2020 b
2020
-
[47]
W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., et al
Suzgun, M., Scales, N., Sch \"a rli, N., Gehrmann, S., Tay, Y., Chung, H. W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., et al. Challenging big-bench tasks and whether chain-of-thought can solve them. In Findings of the Association for Computational Linguistics: ACL 2023, pp.\ 13003--13051, 2023
2023
-
[48]
Llm pretraining with continuous concepts
Tack, J., Lanchantin, J., Yu, J., Cohen, A., Kulikov, I., Lan, J., Hao, S., Tian, Y., Weston, J., and Li, X. Llm pretraining with continuous concepts. arXiv preprint arXiv:2502.08524, 2025
-
[49]
Commonsenseqa: A question answering challenge targeting commonsense knowledge
Talmor, A., Herzig, J., Lourie, N., and Berant, J. Commonsenseqa: A question answering challenge targeting commonsense knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp.\ 4149--4158, 2019
2019
-
[50]
Kimi K2: Open Agentic Intelligence
Team, K., Bai, Y., Bao, Y., Chen, G., Chen, J., Chen, N., Chen, R., Chen, Y., Chen, Y., Chen, Y., et al. Kimi k2: Open agentic intelligence. arXiv preprint arXiv:2507.20534, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Improving neural language generation with spectrum control
Wang, L., Huang, J., Huang, K., Hu, Z., Wang, G., and Gu, Q. Improving neural language generation with spectrum control. In International Conference on Learning Representations, 2020
2020
-
[52]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark
Wang, Y., Ma, X., Zhang, G., Ni, Y., Chandra, A., Guo, S., Ren, W., Arulraj, A., He, X., Jiang, Z., et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. Advances in Neural Information Processing Systems, 37: 0 95266--95290, 2024
2024
-
[53]
Understanding warmup-stable-decay learning rates: A river valley loss landscape perspective
Wen, K., Li, Z., Wang, J., Hall, D., Liang, P., and Ma, T. Understanding warmup-stable-decay learning rates: A river valley loss landscape perspective. arXiv preprint arXiv:2410.05192, 2024
-
[54]
Sheared llama: Accelerating language model pre-training via structured pruning
Xia, M., Gao, T., Zeng, Z., and Chen, D. Sheared llama: Accelerating language model pre-training via structured pruning. arXiv preprint arXiv:2310.06694, 2023
-
[55]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yue, Y., Chen, Z., Lu, R., Zhao, A., Wang, Z., Song, S., and Huang, G. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? arXiv preprint arXiv:2504.13837, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Be your own teacher: Improve the performance of convolutional neural networks via self distillation
Zhang, L., Song, J., Gao, A., Chen, J., Bao, C., and Ma, K. Be your own teacher: Improve the performance of convolutional neural networks via self distillation. In Proceedings of the IEEE/CVF international conference on computer vision, pp.\ 3713--3722, 2019
2019
-
[58]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Zhang, Y., Li, M., Long, D., Zhang, X., Lin, H., Yang, B., Xie, P., Yang, A., Liu, D., Lin, J., et al. Qwen3 embedding: Advancing text embedding and reranking through foundation models. arXiv preprint arXiv:2506.05176, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Representation degeneration problem in prompt-based models for natural language understanding
Zhao, Q., He, R., Zhang, J., Liu, C., and Wang, B. Representation degeneration problem in prompt-based models for natural language understanding. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pp.\ 13946--13957, 2024
2024
-
[60]
Agieval: A human-centric benchmark for evaluating foundation models
Zhong, W., Cui, R., Guo, Y., Liang, Y., Lu, S., Wang, Y., Saied, A., Chen, W., and Duan, N. Agieval: A human-centric benchmark for evaluating foundation models. In Findings of the Association for Computational Linguistics: NAACL 2024, pp.\ 2299--2314, 2024
2024
-
[61]
Zuhri, Z. M., Fuadi, E. H., and Aji, A. F. Predicting the order of upcoming tokens improves language modeling. arXiv preprint arXiv:2508.19228, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.