X-DiffVLA: X-Embodied Diffusion Action Heads for Vision-Language-Action Models
Pith reviewed 2026-06-30 00:15 UTC · model grok-4.3
The pith
X-DiffVLA introduces a unified diffusion action head that learns cross-embodied policies without per-robot fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
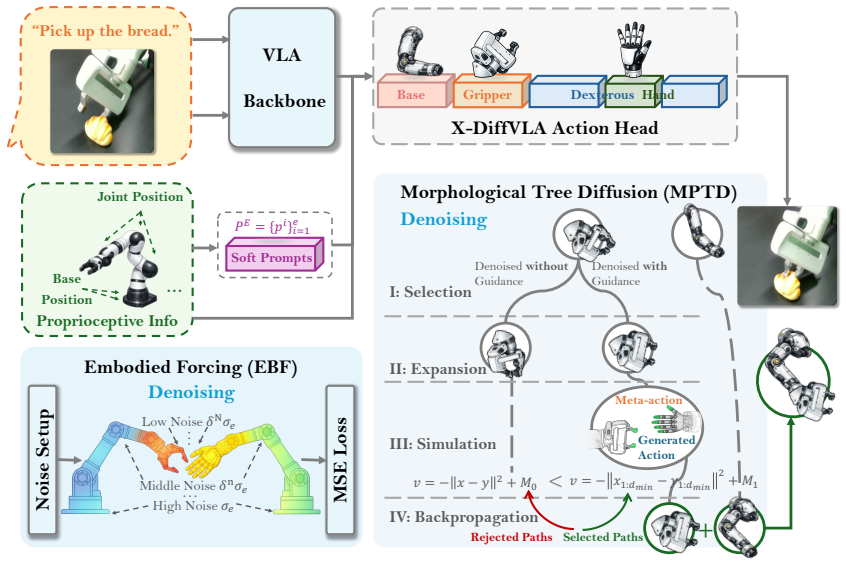
X-DiffVLA is a diffusion-based VLA model with a single cross-embodied action head that exploits the generative capacity of diffusion to model both diversity and hidden correlations present in datasets collected from multiple robot bodies. Embodiment Forcing, implemented as classifier-free guidance, implicitly directs the generated actions toward the functional components that belong to each embodiment. Morphological Tree Diffusion organizes the diffusion process over a tree of morphological relations so that demonstrations from different end-effectors reinforce one another. Together these components produce state-of-the-art results on RoboCasa and Isaac Gym benchmarks that span grippers to d
What carries the argument
Unified cross-embodied action head that combines Embodiment Forcing (classifier-free guidance for implicit component steering) and Morphological Tree Diffusion (tree-structured correlation of behaviors across end-effectors).
If this is right
- Yields 15.3 percent higher success on RoboCasa and 12.5 percent on Isaac Gym compared with prior VLA baselines.
- Maintains performance across end-effectors ranging from parallel grippers to multi-fingered dexterous hands.
- Supports direct deployment after training on combined datasets rather than separate fine-tuning runs.
- Extends to real-robot settings while preserving the reported robustness.
Where Pith is reading between the lines
- The same implicit guidance approach may reduce the volume of embodiment-specific data needed when adding a new robot body to an existing fleet.
- Tree-structured diffusion could be applied to other heterogeneous control problems such as multi-agent teams with differing kinematics.
- If the correlation mechanism generalizes, mixed-embodiment pre-training might become the default route for building broad robot foundation models.
Load-bearing premise
The two new techniques can extract fine-grained structural and behavioral patterns from mixed-embodiment data without any explicit embodiment labels or supervision.
What would settle it
On a held-out embodiment whose morphology differs from all training examples, the success rate of the unified model falls below that of an otherwise identical model fine-tuned only on that embodiment's data.
Figures



read the original abstract
Learning universal policies from cross-embodied data remains a fundamental challenge in robotics. Although Vision-Language-Action (VLA) models are pre-trained on large and diverse datasets, they typically rely on embodiment-specific fine-tuning to achieve strong performance in downstream tasks. This requirement severely limits their generalization capability and restricts knowledge transfer across embodiments performing similar tasks. To overcome these limitations, we focus on cross-embodied settings with shared robotic bases and heterogeneous end-effectors, and propose X-DiffVLA, a diffusion-based VLA model featuring a unified cross-embodied action head. X-DiffVLA can leverage the generative strengths of diffusion models to capture both the diversity and latent correlations in cross-embodied datasets. Specifically, we introduce Embodiment Forcing, a classifier-free guidance technique to implicitly steer action generation toward embodiment-specific functional components, capturing fine-grained structural nuances without explicit supervision. In addition, a Morphological Tree Diffusion approach is designed to strengthen behavioral correlations across diverse end-effectors, maximizing the transferability of heterogeneous demonstrations. Experimental results across RoboCasa and Isaac Gym, covering different embodiments from grippers to dexterous hands, show that X-DiffVLA achieves state-of-the-art performance, with improvements of 15.3% and 12.5%, respectively. Real-world evaluations further validate the robustness of the proposed framework and its effectiveness in scalable cross-embodied policy learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes X-DiffVLA, a diffusion-based vision-language-action model featuring a unified cross-embodied action head. It introduces Embodiment Forcing (classifier-free guidance to implicitly steer toward embodiment-specific components) and Morphological Tree Diffusion (to capture behavioral correlations across heterogeneous end-effectors) for cross-embodied settings with shared bases but varied grippers to dexterous hands. Experiments on RoboCasa and Isaac Gym report state-of-the-art results with 15.3% and 12.5% improvements, plus real-world validation.
Significance. If the results hold, the framework could meaningfully advance generalization in VLA models by reducing embodiment-specific fine-tuning requirements and enabling better transfer across heterogeneous demonstrations via diffusion-based implicit modeling.
major comments (2)
- [Method (Embodiment Forcing and Morphological Tree Diffusion subsections)] The central claim that Embodiment Forcing and Morphological Tree Diffusion implicitly capture fine-grained structural nuances and behavioral correlations without explicit supervision or embodiment labels is load-bearing for the cross-embodiment generalization argument, yet the manuscript provides no ablation studies removing these components or comparing against supervised embodiment-aware baselines to quantify their contribution.
- [Experiments] Table reporting results on RoboCasa and Isaac Gym: the 15.3% and 12.5% improvements are stated without error bars, number of random seeds, statistical tests, or full baseline implementation details (including whether baselines received equivalent hyperparameter search), undermining assessment of whether the gains are robust or due to post-hoc selection.
minor comments (2)
- [Abstract] The abstract states real-world evaluations validate robustness but supplies no quantitative metrics, task descriptions, or embodiment details for those experiments.
- [Method] Notation for the morphological tree structure and diffusion process could be formalized with an equation or algorithm box for clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback on our manuscript. We address the major comments point by point below and commit to revisions that strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Method (Embodiment Forcing and Morphological Tree Diffusion subsections)] The central claim that Embodiment Forcing and Morphological Tree Diffusion implicitly capture fine-grained structural nuances and behavioral correlations without explicit supervision or embodiment labels is load-bearing for the cross-embodiment generalization argument, yet the manuscript provides no ablation studies removing these components or comparing against supervised embodiment-aware baselines to quantify their contribution.
Authors: We agree that ablation studies are necessary to isolate and quantify the contributions of Embodiment Forcing and Morphological Tree Diffusion. While the overall performance gains support the design choices, the manuscript does not currently include component-wise ablations or direct comparisons to supervised embodiment-aware baselines. We will add these experiments in the revised manuscript, including variants that disable each proposed component and, where feasible, comparisons against supervised alternatives. revision: yes
-
Referee: [Experiments] Table reporting results on RoboCasa and Isaac Gym: the 15.3% and 12.5% improvements are stated without error bars, number of random seeds, statistical tests, or full baseline implementation details (including whether baselines received equivalent hyperparameter search), undermining assessment of whether the gains are robust or due to post-hoc selection.
Authors: We concur that reporting variability, statistical rigor, and implementation transparency is required to substantiate the claimed improvements. The current manuscript presents point estimates without these details. In the revision we will include error bars, specify the number of random seeds, report statistical tests, and expand the baseline implementation details (including hyperparameter search procedures) to enable a clearer evaluation of robustness. revision: yes
Circularity Check
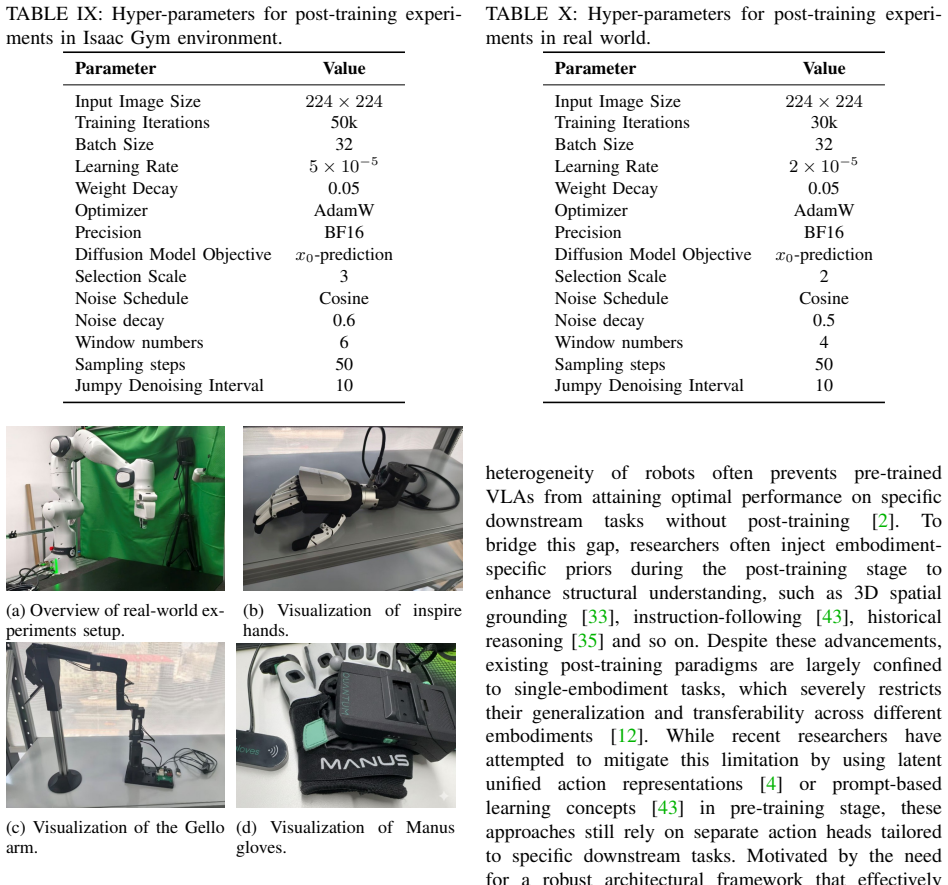
No significant circularity detected
full rationale
The paper presents X-DiffVLA as an empirical architecture for cross-embodied VLA policies, validated on external benchmarks (RoboCasa, Isaac Gym) with reported performance gains. No equations, derivations, or parameter-fitting steps are described in the provided text; Embodiment Forcing and Morphological Tree Diffusion are introduced as modeling choices whose value is asserted via experiment rather than by construction from the target metrics. No self-citation chains, uniqueness theorems, or renamed known results appear as load-bearing elements. The central claims therefore remain independent of the inputs they evaluate.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Latent action diffusion for cross-embodiment manipulation.arXiv preprint arXiv:2506.14608, 2025
Erik Bauer, Elvis Nava, and Robert K Katzschmann. Latent action diffusion for cross-embodiment manipulation.arXiv preprint arXiv:2506.14608, 2025
-
[2]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Casta ˜neda, Nikita Cher- niadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Kevin Black, Noah Brown, Danny Driess, Ad- nan Esmail, Michael Equi, Chelsea Finn, Nic- colo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. Univla: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Diffusion forcing: Next-token prediction meets full- sequence diffusion.Advances in Neural Informa- tion Processing Systems, 37:24081–24125, 2024
Boyuan Chen, Diego Mart ´ı Mons´o, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full- sequence diffusion.Advances in Neural Informa- tion Processing Systems, 37:24081–24125, 2024
2024
-
[6]
Guangyan Chen, Meiling Wang, Qi Shao, Zichen Zhou, Weixin Mao, Te Cui, Minzhao Zhu, Yinan Deng, Luojie Yang, Zhanqi Zhang, et al. See once, then act: Vision-language-action model with task learning from one-shot video demonstrations.arXiv preprint arXiv:2512.07582, 2025
-
[7]
Conrft: A reinforced fine-tuning method for vla models via consistency policy
Yuhui Chen, Shuai Tian, Shugao Liu, Yingting Zhou, Haoran Li, and Dongbin Zhao. Conrft: A reinforced fine-tuning method for vla models via consistency policy. InProceedings of Robotics: Science and Systems, 2025
2025
-
[8]
Diffusion policy: Vi- suomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10- 11):1684–1704, 2025
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Vi- suomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10- 11):1684–1704, 2025
2025
-
[9]
Efficient selectivity and backup op- erators in monte-carlo tree search
R ´emi Coulom. Efficient selectivity and backup op- erators in monte-carlo tree search. InInternational conference on computers and games, pages 72–83. Springer, 2006
2006
-
[10]
Diffusion models in vision: A survey.IEEE transactions on pattern analysis and machine intelligence, 45(9):10850– 10869, 2023
Florinel-Alin Croitoru, Vlad Hondru, Radu Tudor Ionescu, and Mubarak Shah. Diffusion models in vision: A survey.IEEE transactions on pattern analysis and machine intelligence, 45(9):10850– 10869, 2023
2023
-
[11]
GraspVLA: a Grasping Foundation Model Pre-trained on Billion-scale Synthetic Action Data
Shengliang Deng, Mi Yan, Songlin Wei, Haixin Ma, Yuxin Yang, Jiayi Chen, Zhiqi Zhang, Taoyu Yang, Xuheng Zhang, Wenhao Zhang, et al. Graspvla: a grasping foundation model pre-trained on billion-scale synthetic action data.arXiv preprint arXiv:2505.03233, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Shichao Fan, Kun Wu, Zhengping Che, Xinhua Wang, Di Wu, Fei Liao, Ning Liu, Yixue Zhang, Zhen Zhao, Zhiyuan Xu, et al. Xr-1: Towards versatile vision-language-action models via learn- ing unified vision-motion representations.arXiv preprint arXiv:2511.02776, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Octo: An open-source generalist robot policy
Dibya Ghosh, Homer Rich Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, et al. Octo: An open-source generalist robot policy. InRobotics: Science and Systems, 2024
2024
-
[14]
Generative adver- sarial networks.Communications of the ACM, 63 (11):139–144, 2020
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adver- sarial networks.Communications of the ACM, 63 (11):139–144, 2020
2020
-
[15]
De- noising diffusion probabilistic models.Advances in neural information processing systems, 33:6840– 6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. De- noising diffusion probabilistic models.Advances in neural information processing systems, 33:6840– 6851, 2020
2020
-
[16]
Video diffusion models.Advances in neu- ral information processing systems, 35:8633–8646, 2022
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models.Advances in neu- ral information processing systems, 35:8633–8646, 2022
2022
-
[17]
Fastdiff: A fast conditional diffusion model for high-quality speech synthesis
R Huang, MWY Lam, J Wang, D Su, D Yu, Y Ren, and Z Zhao. Fastdiff: A fast conditional diffusion model for high-quality speech synthesis. InIJCAI International Joint Conference on Artificial Intelli- gence, pages 4157–4163. IJCAI: International Joint Conferences on Artificial Intelligence Organization, 2022
2022
-
[18]
Diffuse-cloc: Guided diffusion for physics-based character look-ahead control.ACM Transactions on Graphics (TOG), 44(4):1–12, 2025
Xiaoyu Huang, Takara Truong, Yunbo Zhang, Fangzhou Yu, Jean Pierre Sleiman, Jessica Hod- gins, Koushil Sreenath, and Farbod Farshidian. Diffuse-cloc: Guided diffusion for physics-based character look-ahead control.ACM Transactions on Graphics (TOG), 44(4):1–12, 2025
2025
-
[19]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Nic- colo Fusai, et al.π 0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Planning with diffusion for flexible behavior synthesis
Michael Janner, Yilun Du, Joshua Tenenbaum, and Sergey Levine. Planning with diffusion for flexible behavior synthesis. InInternational Conference on Machine Learning, pages 9902–9915. PMLR, 2022
2022
-
[21]
Openvla: An open-source vision- language-action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, et al. Openvla: An open-source vision- language-action model. InConference on Robot Learning, pages 2679–2713. PMLR, 2025
2025
-
[22]
Mat: Morphological adaptive transformer for universal morphology policy learning.IEEE Trans- actions on Cognitive and Developmental Systems, 16(4):1611–1621, 2024
Boyu Li, Haoran Li, Yuanheng Zhu, and Dongbin Zhao. Mat: Morphological adaptive transformer for universal morphology policy learning.IEEE Trans- actions on Cognitive and Developmental Systems, 16(4):1611–1621, 2024
2024
-
[23]
Boyu Li, Siyuan He, Hang Xu, Haoqi Yuan, Yu Zang, Liwei Hu, Junpeng Yue, Zhenxiong Jiang, Pengbo Hu, B ¨orje F Karlsson, et al. Du- althor: A dual-arm humanoid simulation platform for contingency-aware planning.arXiv preprint arXiv:2506.16012, 2025
-
[24]
Zhixuan Liang, Yizhuo Li, Tianshuo Yang, Chengyue Wu, Sitong Mao, Tian Nian, Liuao Pei, Shunbo Zhou, Xiaokang Yang, Jiangmiao Pang, et al. Discrete diffusion vla: Bringing discrete diffusion to action decoding in vision-language- action policies.arXiv preprint arXiv:2508.20072, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Robomamba: Efficient vision-language- action model for robotic reasoning and manipula- tion.Advances in Neural Information Processing Systems, 37:40085–40110, 2024
Jiaming Liu, Mengzhen Liu, Zhenyu Wang, Pengju An, Xiaoqi Li, Kaichen Zhou, Senqiao Yang, Renrui Zhang, Yandong Guo, and Shanghang Zhang. Robomamba: Efficient vision-language- action model for robotic reasoning and manipula- tion.Advances in Neural Information Processing Systems, 37:40085–40110, 2024
2024
-
[26]
HybridVLA: Collaborative Diffusion and Autoregression in a Unified Vision-Language-Action Model
Jiaming Liu, Hao Chen, Pengju An, Zhuoyang Liu, Renrui Zhang, Chenyang Gu, Xiaoqi Li, Ziyu Guo, Sixiang Chen, Mengzhen Liu, et al. Hybridvla: Collaborative diffusion and autoregression in a uni- fied vision-language-action model.arXiv preprint arXiv:2503.10631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foun- dation model for bimanual manipulation.arXiv preprint arXiv:2410.07864, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Videos are sample-efficient supervisions: Behavior cloning from videos via latent representations
Xin Liu, Haoran Li, and Dongbin Zhao. Videos are sample-efficient supervisions: Behavior cloning from videos via latent representations. InThe Thirty-ninth Annual Conference on Neural Infor- mation Processing Systems, 2025
2025
-
[29]
Being-H0: Vision- language-action pretraining from large-scale human videos.arXiv:2507.15597, 2025
Hao Luo, Yicheng Feng, Wanpeng Zhang, Sipeng Zheng, Ye Wang, Haoqi Yuan, Jiazheng Liu, Chaoyi Xu, Qin Jin, and Zongqing Lu. Being-h0: vision-language-action pretraining from large-scale human videos.arXiv preprint arXiv:2507.15597, 2025
-
[30]
Visualizing data using t-sne.Journal of machine learning research, 9(Nov):2579–2605, 2008
Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of machine learning research, 9(Nov):2579–2605, 2008
2008
-
[31]
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
Viktor Makoviychuk, Lukasz Wawrzyniak, Yun- rong Guo, Michelle Lu, Kier Storey, Miles Mack- lin, David Hoeller, Nikita Rudin, Arthur Allshire, Ankur Handa, et al. Isaac gym: High performance gpu-based physics simulation for robot learning. arXiv preprint arXiv:2108.10470, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[32]
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar, and Yuke Zhu. Robocasa: Large- scale simulation of everyday tasks for generalist robots.arXiv preprint arXiv:2406.02523, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, et al. Spatialvla: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Naturalspeech 2: Latent diffusion models are natural and zero-shot speech and singing synthesiz- ers
Kai Shen, Zeqian Ju, Xu Tan, Eric Liu, Yichong Leng, Lei He, Tao Qin, Sheng Zhao, and Jiang Bian. Naturalspeech 2: Latent diffusion models are natural and zero-shot speech and singing synthesiz- ers. InICLR, 2024
2024
-
[35]
MemoryVLA: Perceptual-Cognitive Memory in Vision-Language-Action Models for Robotic Manipulation
Hao Shi, Bin Xie, Yingfei Liu, Lin Sun, Fengrong Liu, Tiancai Wang, Erjin Zhou, Haoqiang Fan, Xiangyu Zhang, and Gao Huang. Memoryvla: Perceptual-cognitive memory in vision-language- action models for robotic manipulation.arXiv preprint arXiv:2508.19236, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
D (r, o) grasp: A unified representation of robot and object interaction for cross-embodiment dexterous grasping.arXiv e-prints, pages arXiv– 2410, 2024
Zhenyu Wei, Zhixuan Xu, Jingxiang Guo, Yiwen Hou, Chongkai Gao, Zhehao Cai, Jiayu Luo, and Lin Shao. D (r, o) grasp: A unified representation of robot and object interaction for cross-embodiment dexterous grasping.arXiv e-prints, pages arXiv– 2410, 2024
2024
-
[37]
Adina Yakefu, Bin Xie, Chongyang Xu, En- wen Zhang, Erjin Zhou, Fan Jia, Haitao Yang, Haoqiang Fan, Haowei Zhang, Hongyang Peng, et al. Robochallenge: Large-scale real-robot eval- uation of embodied policies.arXiv preprint arXiv:2510.17950, 2025
-
[38]
Monte carlo tree dif- fusion for system 2 planning
Jaesik Yoon, Hyeonseo Cho, Doojin Baek, Yoshua Bengio, and Sungjin Ahn. Monte carlo tree dif- fusion for system 2 planning. InForty-second International Conference on Machine Learning
-
[39]
Demograsp: Univer- sal dexterous grasping from a single demonstration
Haoqi Yuan, Ziye Huang, Ye Wang, Chuan Mao, Chaoyi Xu, and Zongqing Lu. Demograsp: Univer- sal dexterous grasping from a single demonstration. arXiv preprint arXiv:2509.22149, 2025
-
[40]
Dexgraspnet 2.0: Learning generative dexterous grasping in large-scale synthetic cluttered scenes
Jialiang Zhang, Haoran Liu, Danshi Li, XinQiang Yu, Haoran Geng, Yufei Ding, Jiayi Chen, and He Wang. Dexgraspnet 2.0: Learning generative dexterous grasping in large-scale synthetic cluttered scenes. In8th Annual Conference on Robot Learn- ing, 2024
2024
-
[41]
Dreamvla: A vision-language-action model dreamed with comprehensive world knowledge
Wenyao Zhang, Hongsi Liu, Zekun Qi, Yun- nan Wang, XinQiang Yu, Jiazhao Zhang, Run- pei Dong, Jiawei He, He Wang, Zhizheng Zhang, et al. Dreamvla: A vision-language-action model dreamed with comprehensive world knowledge. In The Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[42]
Cot- vla: Visual chain-of-thought reasoning for vision- language-action models
Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, et al. Cot- vla: Visual chain-of-thought reasoning for vision- language-action models. InProceedings of the Computer Vision and Pattern Recognition Confer- ence, pages 1702–1713, 2025
2025
-
[43]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, et al. X- vla: Soft-prompted transformer as scalable cross- embodiment vision-language-action model.arXiv preprint arXiv:2510.10274, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Rt-2: Vision- language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision- language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023. APPENDIX A. Experiments Setup 1)RoboCasa:RoboCasa [32] is a large-scale simu- lation ...
2023
-
[45]
This setup aims to demonstrate that X-DiffVLA can perform cross-embodied post-training across a broader range of complex dexterous hand structures
Issac Gym:To further evaluate the generalization capabilities of X-DiffVLA, we introduce an additional experimental environment based on Isaac Gym. This setup aims to demonstrate that X-DiffVLA can perform cross-embodied post-training across a broader range of complex dexterous hand structures. Following the TABLE VIII: Task list of 30 validation tasks fo...
-
[46]
Our real- robot datasets are collected via teleoperation, employing a GELLO device for arm control and Manus gloves for dexterous hand manipulation
Real World:To evaluate the effectiveness of the X- DiffVLA action head, we conduct real-world validation using both Panda grippers and Inspire hands mounted on a FR3 robotic arm, as shown in Fig.5. Our real- robot datasets are collected via teleoperation, employing a GELLO device for arm control and Manus gloves for dexterous hand manipulation. We collect...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.