DeltaCam: Differential Intrinsic Camera Modeling for Video Generation
Pith reviewed 2026-06-30 11:41 UTC · model grok-4.3
The pith
DeltaCam models camera intrinsics in video diffusion by operating on relative parameter changes learned from synthetic data instead of absolute values.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
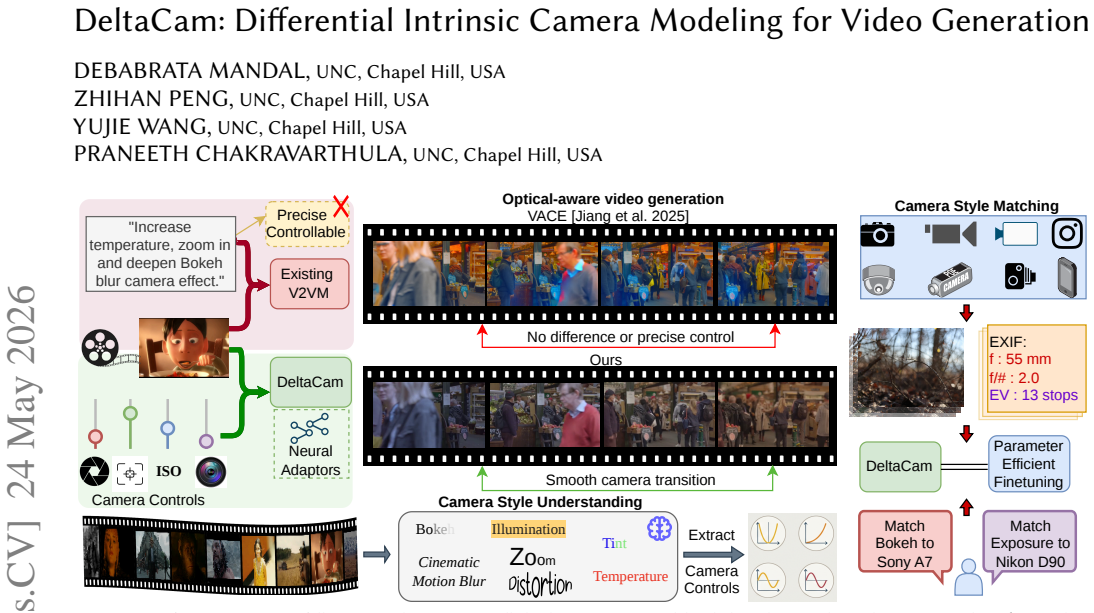
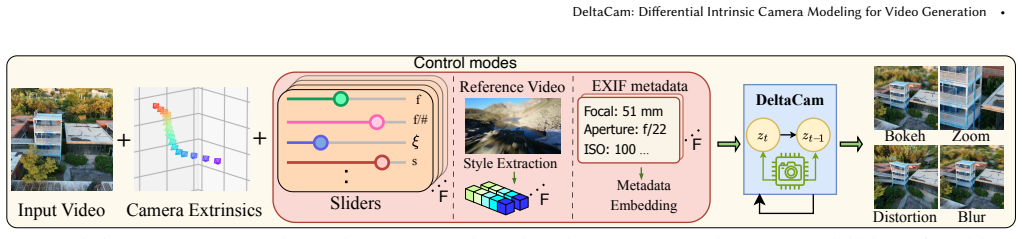
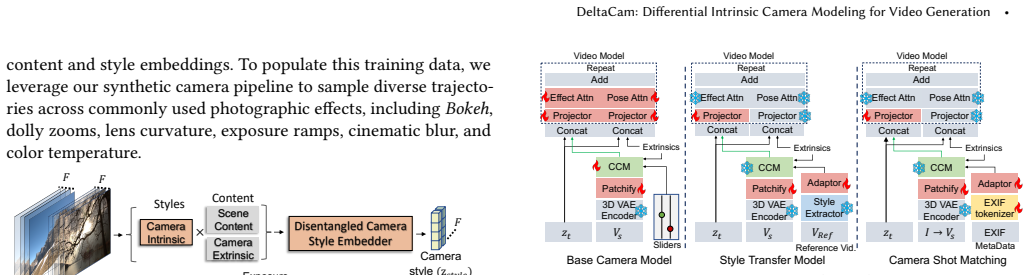
We introduce DeltaCam, a video diffusion framework that models camera behavior through Δ-parameterized neural camera adaptors, operating on relative changes in camera motion and intrinsics instead of absolute states. By learning this differential formulation from synthetic video data, we mitigate reliance on precise real-world camera labels and enable smooth, consistent control over imaging factors such as focal length, aperture, ISO, color temperature, and lens distortion. We extend this framework to real-world footage through two mechanisms: finetuning the controls on real image-metadata pairs for precise shot matching, and extracting disentangled embeddings for implicit video-to-video sty
What carries the argument
Δ-parameterized neural camera adaptors that process relative changes in camera intrinsics and motion
If this is right
- Reduces dependence on accurate real-world camera labels by training primarily on synthetic data
- Enables explicit control over focal length, aperture, ISO, color temperature and lens distortion with temporal consistency
- Supports real-world adaptation through finetuning on image-metadata pairs and disentangled embeddings for style transfer
- Separates scene content from intrinsic imaging behavior to support camera-consistent editing
- Produces video generation and editing operations that maintain photographic effects across frames
Where Pith is reading between the lines
- The differential formulation may extend to other scarce-label controls in video models, such as dynamic lighting or material properties.
- Similar relative-change adaptors could be tested in single-image generation or 3D synthesis pipelines where absolute metadata is also limited.
- A direct test would measure performance on parameter values outside the synthetic training range to check for generalization limits.
- keywords:[
Load-bearing premise
The assumption that training on synthetic video data combined with finetuning on real image-metadata pairs and disentangled embeddings will produce controls that transfer effectively to real-world footage while maintaining temporal consistency and disentanglement from scene content.
What would settle it
A demonstration that generated real-world videos show temporal drift in focus or exposure, or that camera effects bleed into scene appearance, would falsify the transfer claim.
Figures






read the original abstract
Incorporating camera intrinsics into video generation models offers a principled way to control not only scene dynamics but also the imaging process that governs visual appearance. Prior work has primarily focused on extrinsic control, such as camera pose and motion, while treating intrinsic camera parameters as implicit or fixed. A key bottleneck is the lack of large-scale video datasets with accurate and diverse temporally varying camera metadata, which makes learning absolute camera parameterizations difficult. As a result, current models struggle to incorporate photographic camera behavior, including depth-of-field transitions, exposure variations, lens distortions, and color processing, in a controllable and temporally consistent manner. We introduce DeltaCam, a video diffusion framework that models camera behavior through $\Delta$-parameterized neural camera adaptors, operating on relative changes in camera motion and intrinsics instead of absolute states. By learning this differential formulation from synthetic video data, we mitigate reliance on precise real-world camera labels and enable smooth, consistent control over imaging factors such as focal length, aperture, ISO, color temperature, and lens distortion. We extend this framework to real-world footage through two mechanisms: finetuning the controls on real image-metadata pairs for precise shot matching, and extracting disentangled embeddings for implicit video-to-video style transfer without requiring explicit camera parameters. By effectively separating scene content from intrinsic imaging behavior, DeltaCam enables camera-consistent video generation and editing operations that are difficult to achieve with existing models. Ultimately, our results establish a practical and scalable approach for bridging synthetic control and real-world photographic emulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DeltaCam, a video diffusion framework that employs Δ-parameterized neural camera adaptors to model relative changes (deltas) in camera motion and intrinsics rather than absolute states. It trains this differential formulation on synthetic video data to reduce dependence on precise real-world camera labels, then extends it to real footage via finetuning on image-metadata pairs and extraction of disentangled embeddings, with the goal of enabling temporally consistent control over factors including focal length, aperture, ISO, color temperature, and lens distortion while separating imaging behavior from scene content.
Significance. If the differential formulation and transfer mechanisms prove effective, the work would address a documented bottleneck in video generation—the scarcity of large-scale datasets with accurate, temporally varying camera metadata—potentially enabling more controllable emulation of photographic effects without requiring exhaustive real-world annotations.
major comments (2)
- [Abstract] Abstract: the central claims that the Δ-parameterized adaptors 'mitigate reliance on precise real-world camera labels' and 'enable smooth, consistent control' are presented without any derivations, quantitative metrics, ablations, error analysis, or validation results on real footage, rendering the soundness of the transfer from synthetic training to real-world temporal consistency and disentanglement impossible to assess.
- [Abstract] Abstract: the two real-world extension mechanisms (finetuning on image-metadata pairs and disentangled embeddings) are described only at a high level; no details are given on how they prevent drift, content leakage, or loss of disentanglement for parameters such as aperture, ISO, or lens distortion once outside the synthetic distribution.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the abstract. The abstract is a concise summary of contributions, with full derivations, metrics, ablations, and validation results provided in the main manuscript sections. We respond point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims that the Δ-parameterized adaptors 'mitigate reliance on precise real-world camera labels' and 'enable smooth, consistent control' are presented without any derivations, quantitative metrics, ablations, error analysis, or validation results on real footage, rendering the soundness of the transfer from synthetic training to real-world temporal consistency and disentanglement impossible to assess.
Authors: The abstract serves as a high-level summary of the paper's contributions. The derivations of the Δ-parameterized adaptors and the differential formulation are detailed in Section 3.1 with supporting equations. Quantitative metrics, ablations, error analysis, and real-world validation results appear in Sections 4 and 5, including ablation tables on synthetic data for temporal consistency, parameter accuracy metrics, and real-footage transfer experiments with FID scores, consistency measures, and user studies demonstrating disentanglement. These sections provide the evidence needed to assess the claims. revision: no
-
Referee: [Abstract] Abstract: the two real-world extension mechanisms (finetuning on image-metadata pairs and disentangled embeddings) are described only at a high level; no details are given on how they prevent drift, content leakage, or loss of disentanglement for parameters such as aperture, ISO, or lens distortion once outside the synthetic distribution.
Authors: The mechanisms are summarized concisely in the abstract due to space limits. Complete details, including regularization terms in finetuning to prevent drift and adversarial plus reconstruction losses for disentangled embeddings to avoid content leakage, are given in Sections 3.3 and 3.4. These apply to parameters such as aperture, ISO, color temperature, and lens distortion. Ablation studies in Section 4.3 validate their effectiveness on real data outside the synthetic distribution. revision: no
Circularity Check
No circularity: DeltaCam modeling choice and training procedure are independent of outputs
full rationale
The abstract and described framework introduce a differential Δ-parameterized adaptor trained on synthetic video data, followed by separate finetuning on real image-metadata pairs and disentangled embeddings. No load-bearing step reduces a claimed prediction or result to a fitted input by construction, a self-definition, or a self-citation chain. The central claims rest on the modeling decision and data sources rather than tautological equivalence; the derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic video data can be used to learn camera intrinsic controls that transfer to real-world footage via finetuning and embeddings.
invented entities (1)
-
Δ-parameterized neural camera adaptors
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Sherwin Bahmani, Ivan Skorokhodov, Guocheng Qian, Aliaksandr Siarohin, Willi Menapace, Andrea Tagliasacchi, David B Lindell, and Sergey Tulyakov. 2025. Ac3d: Analyzing and improving 3d camera control in video diffusion transformers. In Proceedings of the Computer Vision and Pattern Recognition Conference. 22875– 22889
2025
- [2]
-
[3]
Edurne Bernal-Berdun, Ana Serrano, Belen Masia, Matheus Gadelha, Yannick Hold-Geoffroy, Xin Sun, and Diego Gutierrez. 2025. PreciseCam: Precise Camera Control for Text-to-Image Generation. InProceedings of the Computer Vision and Pattern Recognition Conference. 2724–2733. •Mandal et al. SourceCogVideoXVACEOursGTSourceCogVideoXVACEOursGT Bokeh Shutter spee...
2025
-
[4]
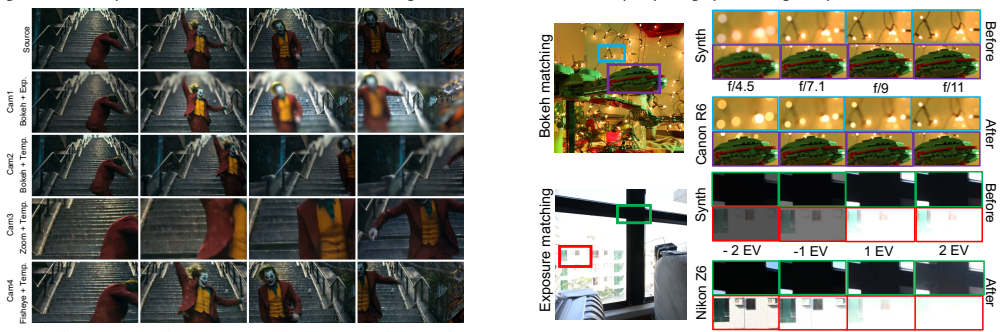
SynthSynthNikon Z6 Bokeh matchingExposure matching f/4.5f/7.1f/9f/11 -2 EV-1 EV1 EV2 EV a) Real vs Synthetic Camera Datasets Canon R6 BeforeBeforeAfterAfter Fig
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, et al. SynthSynthNikon Z6 Bokeh matchingExposure matching f/4.5f/7.1f/9f/11 -2 EV-1 EV1 EV2 EV a) Real vs Synthetic Camera Datasets Canon R6 BeforeBeforeAfterAfter Fig. 10.Real Camera Shot Matching. Our came...
-
[5]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127(2023). DeltaCam: Differential Intrinsic Camera Modeling for Video Generation• SourceReferenceReconstructed Bokeh Lens Distortion Exposure Motion Blur Zooming Color Temperature ReferenceReconstructed Fig. 11.Camera style extraction.We show style...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Tsai-Shien Chen, Chieh Hubert Lin, Hung-Yu Tseng, Tsung-Yi Lin, and Ming Yang. 2023. Motion-Conditioned Diffusion Model for Controllable Video Syn- thesis.ArXivabs/2304.14404 (2023). https://api.semanticscholar.org/CorpusID: SourceTransferred Bokeh Zooming SourceTransferred Fig. 14.Camera Style transfer.Video-to-video camera style transfer using style ext...
-
[7]
I-Sheng Fang, Yue-Hua Han, and Jun-Cheng Chen. 2024. Camera settings as tokens: Modeling photography on latent diffusion models. InSIGGRAPH Asia 2024 Conference Papers. 1–11
2024
-
[8]
Daniel Geng, Charles Herrmann, Junhwa Hur, Forrester Cole, Serena Zhang, Tobias Pfaff, Tatiana Lopez-Guevara, Carl Doersch, Yusuf Aytar, Michael Ru- binstein, Chen Sun, Oliver Wang, Andrew Owens, and Deqing Sun. 2024. Mo- tion Prompting: Controlling Video Generation with Motion Trajectories.2025 IEEE/CVF Conference on Computer Vision and Pattern Recogniti...
2024
-
[9]
Yuchao Gu, Yipin Zhou, Bichen Wu, Licheng Yu, Jia-Wei Liu, Rui Zhao, Jay Zhangjie Wu, David Junhao Zhang, Mike Zheng Shou, and Kevin Tang. 2024. Videoswap: Customized video subject swapping with interactive semantic point correspondence. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7621–7630
2024
-
[10]
Zekai Gu, Rui Yan, Jiahao Lu, Peng Li, Zhiyang Dou, Chenyang Si, Zhen Dong, Qifeng Liu, Cheng Lin, Ziwei Liu, et al. 2025. Diffusion as shader: 3d-aware video diffusion for versatile video generation control. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers. 1–12
2025
- [11]
-
[12]
Yuliang Guo, Sparsh Garg, S Mahdi H Miangoleh, Xinyu Huang, and Liu Ren
-
[13]
InProceedings of the Computer Vision and Pattern Recognition Conference
Depth any camera: Zero-shot metric depth estimation from any camera. InProceedings of the Computer Vision and Pattern Recognition Conference. 26996– 27006
-
[14]
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, David-Pur Moshe, Eitan Richardson, E. I. Levin, Guy Shiran, Nir Zabari, Ori Gordon, Poriya Panet, Sapir Weissbuch, Victor Kulikov, Yaki Bitterman, Zeev Melumian, and Ofir Bibi. 2024. LTX-Video: Realtime Video Latent Diffusion.ArXivabs/2501.00103 (2024). https://api.semanticscholar.org/CorpusID:275212083
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [15]
-
[16]
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuan- han Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. 2023. VBench: Comprehensive Benchmark Suite for Video Generative Models.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)...
2023
-
[17]
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu
-
[18]
InProceedings of the IEEE/CVF International Conference on Computer Vision
Vace: All-in-one video creation and editing. InProceedings of the IEEE/CVF International Conference on Computer Vision. 17191–17202
- [19]
-
[20]
Teng Li, Guangcong Zheng, Rui Jiang, Shuigen Zhan, Tao Wu, Yehao Lu, Yining Lin, Chuanyun Deng, Yepan Xiong, Min Chen, et al . 2025. Realcam-i2v: Real- world image-to-video generation with interactive complex camera control. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 28785– 28796
2025
- [21]
-
[22]
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. 2021. Sdedit: Guided image synthesis and editing with stochastic differential equations.arXiv preprint arXiv:2108.01073(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[23]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El- Nouby, et al. 2023. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Hao Ouyang, Zifan Shi, Chenyang Lei, Ka Lung Law, and Qifeng Chen. 2021. Neural camera simulators. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 7700–7709
2021
-
[25]
Courville
Ethan Perez, Florian Strub, Harm de Vries, Vincent Dumoulin, and Aaron C. Courville. 2017. FiLM: Visual Reasoning with a General Conditioning Layer. InAAAI Conference on Artificial Intelligence. https://api.semanticscholar.org/ CorpusID:19119291
2017
-
[26]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand- hini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
-
[27]
In International conference on machine learning
Learning transferable visual models from natural language supervision. In International conference on machine learning. PmLR, 8748–8763
- [28]
-
[29]
Thomas Ressler-Antal, Frank Fundel, Malek Ben Alaya, Stefan Andreas Baumann, Felix Krause, Ming Gui, and Björn Ommer. 2025. DisMo: Disentangled Motion Representations for Open-World Motion Transfer. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[30]
Tim Seizinger, Florin-Alexandru Vasluianu, Marcos V Conde, Zongwei Wu, and Radu Timofte. 2025. Bokehlicious: Photorealistic bokeh rendering with con- trollable apertures. InProceedings of the IEEE/CVF International Conference on Computer Vision. 8908–8917
2025
-
[31]
Vincent Sitzmann, Semon Rezchikov, Bill Freeman, Josh Tenenbaum, and Fredo Durand. 2021. Light field networks: Neural scene representations with single- evaluation rendering.Advances in Neural Information Processing Systems34 (2021), 19313–19325
2021
-
[32]
Jiaming Song, Chenlin Meng, and Stefano Ermon. 2020. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[33]
SaiKiran Tedla, Kelly Zhu, Trevor Canham, Felix Taubner, Michael S Brown, Kiriakos N Kutulakos, and David B Lindell. 2025. Generating the Past, Present and Future from a Motion-Blurred Image.ACM Transactions on Graphics (TOG) 44, 6 (2025), 1–15
2025
-
[34]
Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Xiaofeng Meng, Ningying Zhang, Pandeng Li, Ping Wu, Ruihang Chu, Rui Feng, Shiwei Zhang, Siyang Sun, Tao Fang, Tianxing Wang...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Qinghe Wang, Yawen Luo, Xiaoyu Shi, Xu Jia, Huchuan Lu, Tianfan Xue, Xintao Wang, Pengfei Wan, Di Zhang, and Kun Gai. 2025. CineMaster: A 3D-Aware and Controllable Framework for Cinematic Text-to-Video Generation.Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers(2025). https://api.semant...
2025
-
[36]
Xi Wang, Robin Courant, Marc Christie, and Vicky Kalogeiton. 2025. AKiRa: Augmentation Kit on Rays for optical video generation. InProceedings of the Computer Vision and Pattern Recognition Conference. 2609–2619
2025
-
[37]
Yujie Wei, Shiwei Zhang, Zhiwu Qing, Hangjie Yuan, Zhiheng Liu, Yu Liu, Yingya Zhang, Jingren Zhou, and Hongming Shan. 2024. Dreamvideo: Composing your dream videos with customized subject and motion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6537–6549
2024
- [38]
-
[39]
Jinbo Xing, Long Mai, Cusuh Ham, Jiahui Huang, Aniruddha Mahapatra, Chi- Wing Fu, Tien-Tsin Wong, and Feng Liu. 2025. Motioncanvas: Cinematic shot design with controllable image-to-video generation. InProceedings of the Spe- cial Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers. 1–11
2025
-
[40]
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al . 2024. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Wangbo Yu, Jinbo Xing, Li Yuan, Wenbo Hu, Xiaoyu Li, Zhipeng Huang, Xiangjun Gao, Tien-Tsin Wong, Ying Shan, and Yonghong Tian. 2024. Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis.arXiv preprint arXiv:2409.02048(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Yu Yuan, Xijun Wang, Yichen Sheng, Prateek Chennuri, Xingguang Zhang, and Stanley Chan. 2025. Generative photography: Scene-consistent camera control for realistic text-to-image synthesis. InProceedings of the Computer Vision and Pattern Recognition Conference. 7920–7930
2025
-
[43]
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. 2023. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision. 3836–3847
2023
- [44]
- [45]
-
[46]
Zhenghong Zhou, Jie An, and Jiebo Luo. 2025. Latent-Reframe: Enabling Cam- era Control for Video Diffusion Models without Training. InProceedings of the IEEE/CVF International Conference on Computer Vision. 12779–12789
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.