Pantheon360: Taming Digital Twin Generation via 3D-Aware 360{deg} Video Diffusion
Pith reviewed 2026-06-29 22:44 UTC · model grok-4.3
The pith
A 3D cache from sparse 360 inputs acts as a geometric scaffold to produce consistent panoramic videos via diffusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Pantheon360 synthesizes high-fidelity 360° videos from sparse 360° inputs by using an explicit 3D Cache reconstructed from the input as a geometric scaffold for any user-defined camera path. This allows the diffusion model to focus on photorealistic texture refinement while the 3D Cache enforces global geometric consistency. Experiments show that Pantheon360 achieves superior visual quality and unmatched geometric coherence, enabling reliable and flexible 360° scene generation for downstream simulation and digital-twin applications.
What carries the argument
Explicit 3D Cache reconstructed from sparse 360° inputs, serving as a geometric scaffold that enforces consistency inside the diffusion process.
If this is right
- 360° videos can be generated with superior visual quality from sparse panoramic inputs.
- Geometric coherence holds across arbitrary user-defined camera paths inside the scene.
- The resulting videos support downstream simulation and digital-twin applications without additional multi-view capture.
- Trajectory design simplifies because panoramic coverage supplies global context from the start.
Where Pith is reading between the lines
- Fewer input views may suffice for building usable digital twins than current multi-camera pipelines require.
- The cache-guided approach could integrate with existing robotics simulators to test navigation in reconstructed environments.
- Extending the cache to handle time-varying elements might enable consistent video of moving scenes.
Load-bearing premise
The 3D Cache reconstructed from sparse 360° inputs can reliably serve as a geometric scaffold that enforces global consistency for arbitrary user-defined camera paths inside the diffusion process.
What would settle it
Generating videos along novel camera trajectories and then measuring visible geometric distortions or inconsistencies absent from the original input views would falsify the claim.
Figures


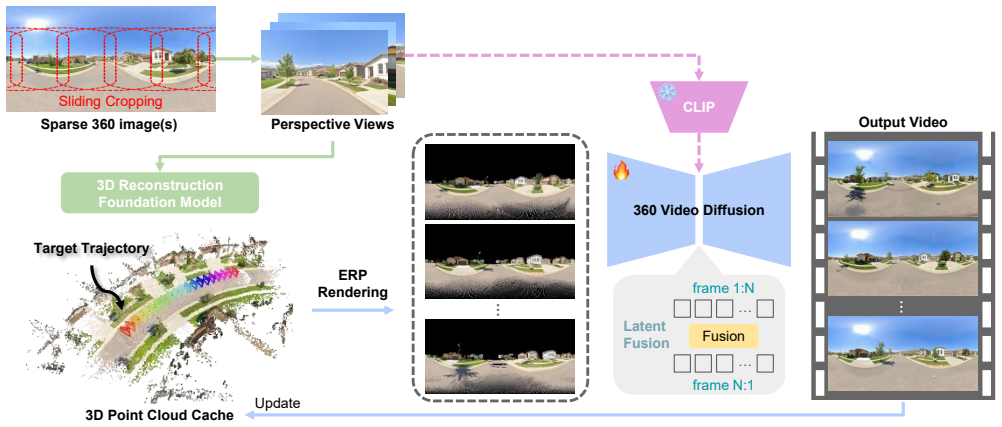
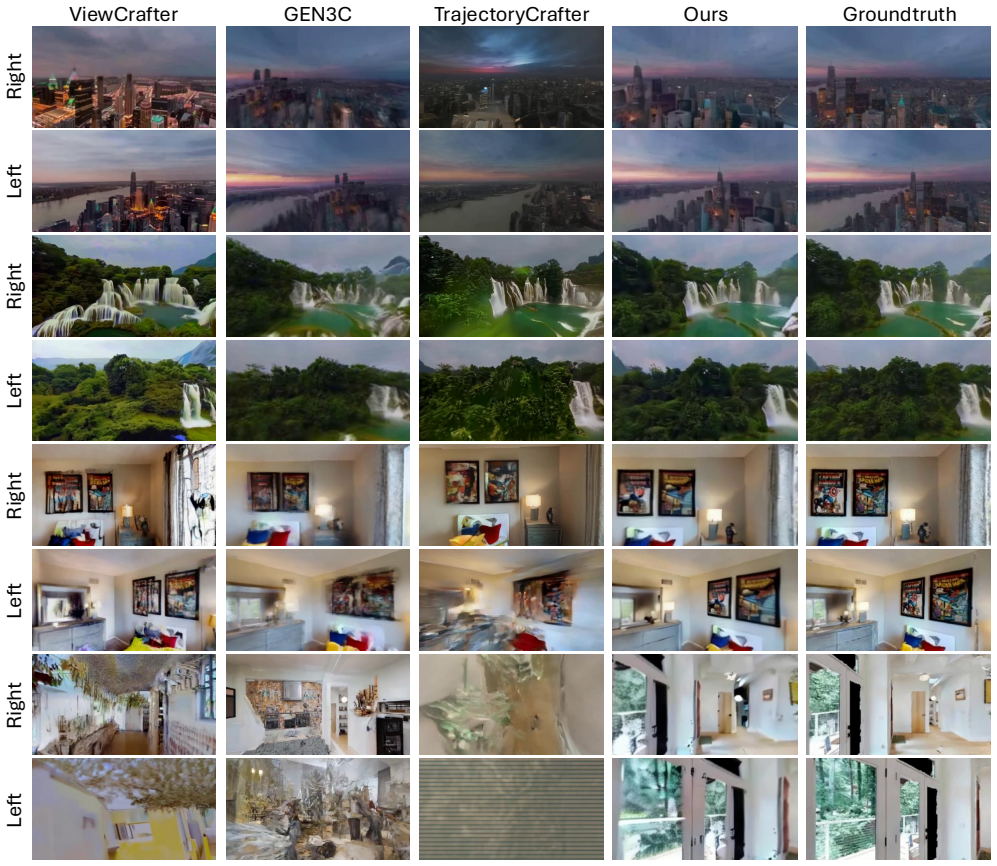









read the original abstract
Generating complete digital twins from videos requires precise camera control, global scene coverage, and strict spatial-temporal consistency constraints that remain challenging for perspective video generators due to their limited field of view (FoV). Their narrow FoV forces long or multi-view trajectories, amplifying cross-view inconsistency and temporal drift. We argue that 360{\deg} video generation offers a natural solution: panoramic coverage simplifies trajectory design and provides a strong global context for maintaining coherence. We introduce Pantheon360: Taming Digital Twin Generation via 3D-Aware 360{\deg} Video Diffusion, a controllable 360{\deg} video generation framework that synthesizes high-fidelity videos from sparse 360{\deg} inputs. The key idea is an explicit 3D Cache, reconstructed from the input, which serves as a geometric scaffold for any user-defined camera path. This allows the diffusion model to focus on photorealistic texture refinement while the 3D Cache enforces global geometric consistency. Experiments show that Pantheon360 achieves superior visual quality and unmatched geometric coherence, enabling reliable and flexible 360{\deg} scene generation for downstream simulation and digital-twin applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce Pantheon360, a controllable 3D-aware 360° video diffusion framework that reconstructs an explicit 3D Cache from sparse 360° inputs to act as a geometric scaffold; this allows the diffusion model to synthesize photorealistic textures while the cache enforces global geometric consistency for arbitrary user-defined camera paths, yielding superior visual quality and unmatched coherence for digital-twin applications.
Significance. If the 3D Cache mechanism is shown to reliably enforce consistency for paths distant from the input views, the work would be significant for cs.CV by offering a practical separation of geometry enforcement from texture synthesis in panoramic generation, addressing FoV limitations of perspective models and supporting downstream simulation tasks.
major comments (2)
- [Abstract] Abstract: the performance claims of 'superior visual quality and unmatched geometric coherence' and 'reliable and flexible 360° scene generation' are stated without any metrics, baselines, quantitative results, or experimental details, which is load-bearing for assessing whether the central contribution holds.
- [Method] Method (3D Cache description): the claim that the 3D Cache 'enforces global geometric consistency' for arbitrary user-defined camera paths is central; the manuscript must specify the exact conditioning mechanism inside the diffusion process (hard constraint vs. soft guidance) and provide failure-case analysis for reconstruction errors, holes, or depth inaccuracies common with sparse panoramic inputs.
minor comments (1)
- [Abstract] Abstract: the phrasing 'taming digital twin generation' is informal and could be replaced with a more precise description of the technical contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below and will make the requested clarifications and additions in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the performance claims of 'superior visual quality and unmatched geometric coherence' and 'reliable and flexible 360° scene generation' are stated without any metrics, baselines, quantitative results, or experimental details, which is load-bearing for assessing whether the central contribution holds.
Authors: We agree that the abstract would be strengthened by including concrete quantitative support. In the revision we will add a concise sentence reporting the key metrics (e.g., PSNR/SSIM gains and geometric consistency scores versus the strongest baselines) while remaining within the abstract word limit. Full tables, baselines, and experimental protocols already appear in the Experiments section and will be cross-referenced. revision: yes
-
Referee: [Method] Method (3D Cache description): the claim that the 3D Cache 'enforces global geometric consistency' for arbitrary user-defined camera paths is central; the manuscript must specify the exact conditioning mechanism inside the diffusion process (hard constraint vs. soft guidance) and provide failure-case analysis for reconstruction errors, holes, or depth inaccuracies common with sparse panoramic inputs.
Authors: We will expand the Method section to state that the 3D Cache is injected as soft guidance: multi-scale depth and feature maps from the cache are concatenated with the noisy latent and fed into the U-Net via cross-attention and skip connections at every denoising step. We will also add a new subsection with qualitative failure-case examples (reconstruction holes, depth errors on distant surfaces) together with the corresponding generated frames, showing both the limitations and how the diffusion model mitigates them. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's core construction reconstructs an explicit 3D Cache directly from the sparse 360° input videos and uses it as conditioning for the diffusion process. This separation treats the cache as an independent geometric input rather than deriving it from the model's own outputs or predictions. No equations, self-citations, or uniqueness claims are shown that reduce the claimed geometric consistency to a fitted parameter, self-definition, or prior author work. The derivation chain is therefore self-contained against external reconstruction inputs.
Axiom & Free-Parameter Ledger
invented entities (1)
-
3D Cache
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Di- verse plausible 360-degree image outpainting for efficient 3dcg background creation
Naofumi Akimoto, Yuhi Matsuo, and Yoshimitsu Aoki. Di- verse plausible 360-degree image outpainting for efficient 3dcg background creation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11441–11450, 2022. 3
2022
-
[3]
Met3r: Measuring multi- view consistency in generated images
Mohammad Asim, Christopher Wewer, Thomas Wimmer, Bernt Schiele, and Jan Eric Lenssen. Met3r: Measuring multi- view consistency in generated images. InComputer Vision and Pattern Recognition (CVPR), 2024. 5
2024
-
[4]
Lindell, and Sergey Tulyakov
Sherwin Bahmani, Ivan Skorokhodov, Guocheng Qian, Ali- aksandr Siarohin, Willi Menapace, Andrea Tagliasacchi, David B. Lindell, and Sergey Tulyakov. Ac3d: Analyzing and improving 3d camera control in video diffusion transformers,
-
[5]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 2, 3, 13
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Video generation models as world simula- tors.OpenAI Technical Report, 2024
Tim Brooks et al. Video generation models as world simula- tors.OpenAI Technical Report, 2024. 2
2024
-
[7]
Luxi Chen, Zihan Zhou, Min Zhao, Yikai Wang, Ge Zhang, Wenhao Huang, Hao Sun, Ji-Rong Wen, and Chongxuan Li. Flexworld: Progressively expanding 3d scenes for flexiable- view synthesis.arXiv preprint arXiv:2503.13265, 2025. 2
-
[8]
Mvsplat360: Feed-forward 360 scene synthesis from sparse views.Ad- vances in Neural Information Processing Systems, 37:107064– 107086, 2024
Yuedong Chen, Chuanxia Zheng, Haofei Xu, Bohan Zhuang, Andrea Vedaldi, Tat-Jen Cham, and Jianfei Cai. Mvsplat360: Feed-forward 360 scene synthesis from sparse views.Ad- vances in Neural Information Processing Systems, 37:107064– 107086, 2024. 2
2024
-
[9]
Text2light: Zero-shot text-driven hdr panorama generation.ACM Trans- actions on Graphics (TOG), 41(6):1–16, 2022
Zhaoxi Chen, Guangcong Wang, and Ziwei Liu. Text2light: Zero-shot text-driven hdr panorama generation.ACM Trans- actions on Graphics (TOG), 41(6):1–16, 2022. 3
2022
-
[10]
Panogrf: Generalizable spherical radiance fields for wide-baseline panoramas
Zheng Chen, Yan-Pei Cao, Yuan-Chen Guo, Chen Wang, Ying Shan, and Song-Hai Zhang. Panogrf: Generalizable spherical radiance fields for wide-baseline panoramas. InAdvances in Neural Information Processing Systems (NeurIPS), pages 6961–6985, 2023. 3
2023
-
[11]
Splatter-360: Generalizable 360 gaussian splatting for wide- baseline panoramic images
Zheng Chen, Chenming Wu, Zhelun Shen, Chen Zhao, We- icai Ye, Haocheng Feng, Errui Ding, and Song-Hai Zhang. Splatter-360: Generalizable 360 gaussian splatting for wide- baseline panoramic images. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21590– 21599, 2025. 3
2025
-
[12]
Splannequin: Freezing monocular mannequin-challenge footage with dual-detection splatting
Hao-Jen Chien, Yi-Chuan Huang, Chung-Ho Wu, Wei-Lun Chao, and Yu-Lun Liu. Splannequin: Freezing monocular mannequin-challenge footage with dual-detection splatting. arXiv preprint arXiv:2512.05113, 2025. 2
-
[13]
Spherenet: Learning spherical representations for detection and classification in omnidirectional images
Benjamin Coors, Alexandru Paul Condurache, and Andreas Geiger. Spherenet: Learning spherical representations for detection and classification in omnidirectional images. In European Conference on Computer Vision (ECCV), pages 518–533. Springer, 2018. 3
2018
-
[14]
Human-compatible driving agents through data-regularized self-play reinforce- ment learning.Reinforcement Learning Journal, 1, 2024
Daphne Cornelisse and Eugene Vinitsky. Human-compatible driving agents through data-regularized self-play reinforce- ment learning.Reinforcement Learning Journal, 1, 2024. 2
2024
-
[15]
Shichao Dong et al. Leveraging large-scale pretrained vision foundation models for label-efficient 3d point cloud segmen- tation.arXiv preprint arXiv:2311.01989, 2023. 2
-
[16]
Digital twin generation from visual data: A survey.arXiv preprint arXiv:2504.13159, 2025
Shichao Dong et al. Digital twin generation from visual data: A survey.arXiv preprint arXiv:2504.13159, 2025. 2
-
[17]
Pano popups: Indoor 3d reconstruction with a plane-aware network
Marc Eder, Pierre Moulon, and Li Guan. Pano popups: Indoor 3d reconstruction with a plane-aware network. InInterna- tional Conference on 3D Vision (3DV), pages 76–84. IEEE,
-
[18]
Spec- tromotion: Dynamic 3d reconstruction of specular scenes
Cheng-De Fan, Chen-Wei Chang, Yi-Ruei Liu, Jie-Ying Lee, Jiun-Long Huang, Yu-Chee Tseng, and Yu-Lun Liu. Spec- tromotion: Dynamic 3d reconstruction of specular scenes. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 21328–21338, 2025. 2, 3
2025
-
[19]
Explo- rative inbetweening of time and space
Haiwen Feng, Zheng Ding, Zhihao Xia, Simon Niklaus, Vic- toria Abrevaya, Michael J Black, and Xuaner Zhang. Explo- rative inbetweening of time and space. InEuropean Confer- ence on Computer Vision, pages 378–395. Springer, 2024. 4, 5, 13, 14
2024
-
[20]
Mengyang Feng, Jinlin Liu, Miaomiao Cui, and Xuansong Xie. Diffusion360: Seamless 360 degree panoramic im- age generation based on diffusion models.arXiv preprint arXiv:2311.13141, 2023. 3
-
[21]
Flowr: Flowing from sparse to dense 3d reconstructions
Tobias Fischer, Samuel Rota Bul`o, Yung-Hsu Yang, Nikhil Keetha, Lorenzo Porzi, Norman M ¨uller, Katja Schwarz, Jonathon Luiten, Marc Pollefeys, and Peter Kontschieder. Flowr: Flowing from sparse to dense 3d reconstructions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 27702–27712, 2025. 2
2025
-
[22]
3dtrajmaster: Mastering 3d trajectory for multi-entity motion in video generation, 2025
Xiao Fu, Xian Liu, Xintao Wang, Sida Peng, Menghan Xia, Xiaoyu Shi, Ziyang Yuan, Pengfei Wan, Di Zhang, and Dahua Lin. 3dtrajmaster: Mastering 3d trajectory for multi-entity motion in video generation, 2025. 2
2025
-
[24]
Cameractrl: Enabling camera control for text-to-video generation, 2025
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for text-to-video generation, 2025. 2
2025
-
[25]
Hao He, Ceyuan Yang, Shanchuan Lin, Yinghao Xu, Meng Wei, Liangke Gui, Qi Zhao, Gordon Wetzstein, Lu Jiang, and Hongsheng Li. Cameractrl ii: Dynamic scene exploration via camera-controlled video diffusion models.arXiv preprint arXiv:2503.10592, 2025. 2
-
[26]
CameraCtrl: Enabling Camera Control for Text-to-Video Generation
Hao He et al. Cameractrl: Enabling camera control for text- to-video generation.arXiv preprint arXiv:2404.02101, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Generative camera dolly: Extreme monocular dynamic novel view synthesis, 2024
Basile Van Hoorick, Rundi Wu, Ege Ozguroglu, Kyle Sar- gent, Ruoshi Liu, Pavel Tokmakov, Achal Dave, Changxi Zheng, and Carl V ondrick. Generative camera dolly: Extreme monocular dynamic novel view synthesis, 2024. 2
2024
-
[28]
Training-free camera control for video generation, 2025
Chen Hou and Zhibo Chen. Training-free camera control for video generation, 2025. 2
2025
-
[29]
Vivid4d: Improving 4d reconstruction from monocular video by video inpainting
Jiaxin Huang, Sheng Miao, Bangbang Yang, Yuewen Ma, and Yiyi Liao. Vivid4d: Improving 4d reconstruction from monocular video by video inpainting. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12592–12604, 2025. 2
2025
-
[30]
ViPE: Video Pose Engine for 3D Geometric Perception
Jiahui Huang, Qunjie Zhou, Hesam Rabeti, Aleksandr Ko- rovko, Huan Ling, Xuanchi Ren, Tianchang Shen, Jun Gao, Dmitry Slepichev, Chen-Hsuan Lin, Jiawei Ren, Kevin Xie, Joydeep Biswas, Laura Leal-Taixe, and Sanja Fidler. Vipe: Video pose engine for 3d geometric perception. InNVIDIA Research Whitepapers arXiv:2508.10934, 2025. 5, 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
CamPVG: Camera-Controlled Panoramic Video Generation with Epipolar-Aware Diffusion
Chenhao Ji, Zidong Tan, Yiyang Shen, and Fuchen Tan. Cam- pvg: Camera-controlled panoramic video generation with epipolar-aware diffusion.arXiv preprint arXiv:2509.19979,
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Bench2drive: Towards multi-ability bench- marking of closed-loop end-to-end autonomous driving
Xiaosong Jia, Zhenjie Yang, Qifeng Li, Zhiyuan Zhang, and Junchi Yan. Bench2drive: Towards multi-ability bench- marking of closed-loop end-to-end autonomous driving. In NeurIPS 2024 Datasets and Benchmarks Track, 2024. 2
2024
-
[33]
Scalable deep reinforcement learning for vision-based robotic manipulation
Dmitry Kalashnikov, Alex Irpan, Peter Pastor, Julian Ibarz, Alexander Herzog, Eric Jang, Deirdre Quillen, Ethan Holly, Mrinal Kalakrishnan, Vincent Vanhoucke, and Sergey Levine. Scalable deep reinforcement learning for vision-based robotic manipulation. InProceedings of The 2nd Conference on Robot Learning, pages 651–673. PMLR, 2018. 2
2018
-
[34]
Cubediff: Repurposing diffusion-based image models for panorama generation
Nikolai Kalischek, Michael Oechsle, Fabian Manhardt, Philipp Henzler, Konrad Schindler, and Federico Tombari. Cubediff: Repurposing diffusion-based image models for panorama generation. InThe Thirteenth International Con- ference on Learning Representations, 2025. 3
2025
-
[35]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023. 2
2023
-
[36]
Jie-Ying Lee, Yi-Ruei Liu, Shr-Ruei Tsai, Wei-Cheng Chang, Chung-Ho Wu, Jiewen Chan, Zhenjun Zhao, Chieh Hubert Lin, and Yu-Lun Liu. Skyfall-gs: Synthesizing immersive 3d urban scenes from satellite imagery.arXiv preprint arXiv:2510.15869, 2025. 3
-
[37]
Ground- ing image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and J´erˆome Revaud. Ground- ing image matching in 3d with mast3r. InEuropean Con- ference on Computer Vision (ECCV), pages 71–91. Springer,
-
[38]
Plataniotis, Sergey Tulyakov, and Jian Ren
Hanwen Liang, Junli Cao, Vidit Goel, Guocheng Qian, Sergei Korolev, Demetri Terzopoulos, Konstantinos N. Plataniotis, Sergey Tulyakov, and Jian Ren. Wonderland: Navigating 3d scenes from a single image, 2025. 2
2025
-
[39]
Cylin- painting: Seamless 360° panoramic image outpainting and beyond.IEEE Transactions on Image Processing, 33:290– 305, 2023
Kang Liao, Lang Nie, Shujuan Huang, Chunyu Lin, Jing Zhang, Yao Zhao, Moncef Gabbouj, and Dacheng Tao. Cylin- painting: Seamless 360° panoramic image outpainting and beyond.IEEE Transactions on Image Processing, 33:290– 305, 2023. 3
2023
-
[40]
Longsplat: Robust unposed 3d gaussian splatting for casual long videos
Chin-Yang Lin, Cheng Sun, Fu-En Yang, Min-Hung Chen, Yen-Yu Lin, and Yu-Lun Liu. Longsplat: Robust unposed 3d gaussian splatting for casual long videos. InICCV, 2025. 2
2025
-
[41]
Fangfu Liu, Wenqiang Sun, Hanyang Wang, Yikai Wang, Haowen Sun, Junliang Ye, Jun Zhang, and Yueqi Duan. Re- conx: Reconstruct any scene from sparse views with video diffusion model.arXiv preprint arXiv:2408.16767, 2024. 2
-
[42]
Robust dynamic radiance fields
Yu-Lun Liu, Chen Gao, Andreas Meuleman, Hung-Yu Tseng, Ayush Saraf, Changil Kim, Yung-Yu Chuang, Johannes Kopf, and Jia-Bin Huang. Robust dynamic radiance fields. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13–23, 2023. 2
2023
-
[43]
Genex: Generating an explorable world
Taiming Lu, Tianmin Shu, Junfei Xiao, Luoxin Ye, Jiahao Wang, Cheng Peng, Chen Wei, Daniel Khashabi, Rama Chel- lappa, Alan Yuille, and Jieneng Chen. Genex: Generating an explorable world. In13th International Conference on Learning Representations (ICLR), 2025. 2, 3, 7
2025
-
[44]
You see it, you got it: Learning 3d creation on pose-free videos at scale
Baorui Ma, Huachen Gao, Haoge Deng, Zhengxiong Luo, Tiejun Huang, Lulu Tang, and Xinlong Wang. You see it, you got it: Learning 3d creation on pose-free videos at scale. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 2016–2029, 2025. 2
2016
- [45]
-
[46]
Habitat: A Platform for Embodied AI Research
Manolis Savva*, Abhishek Kadian*, Oleksandr Maksymets*, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, Devi Parikh, and Dhruv Batra. Habitat: A Platform for Embodied AI Research. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019. 5, 6, 7, 8
2019
-
[47]
Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 65(1):99–106, 2021
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 65(1):99–106, 2021. 2
2021
-
[48]
Efficient synthetic defect on 3d object reconstruction and generation pipeline for digital twins smart factory.Sensors, 25(22):6908, 2024
Rafay Mohiuddin et al. Efficient synthetic defect on 3d object reconstruction and generation pipeline for digital twins smart factory.Sensors, 25(22):6908, 2024. 2
2024
-
[49]
Bips: Bi-modal indoor panorama synthesis via residual depth-aided adversarial learn- ing
Changgyoon Oh, Wonjune Cho, Yujeong Chae, Daehee Park, Lin Wang, and Kuk-Jin Yoon. Bips: Bi-modal indoor panorama synthesis via residual depth-aided adversarial learn- ing. InEuropean Conference on Computer Vision, pages 352–371. Springer, 2022. 3
2022
-
[50]
Greire Payen de La Garanderie, Amir Atapour Abarghouei, and Toby P. Breckon. Eliminating the blind spot: Adapting 3d object detection and monocular depth estimation to 360 panoramic imagery. InEuropean Conference on Computer Vision (ECCV), pages 789–807. Springer, 2018. 3
2018
-
[51]
Panos- platt3r: Leveraging perspective pretraining for generalized unposed wide-baseline panorama reconstruction
Jiahui Ren, Mochu Xiang, Jiajun Zhu, and Yuchao Dai. Panos- platt3r: Leveraging perspective pretraining for generalized unposed wide-baseline panorama reconstruction. InProceed- ings of the IEEE/CVF International Conference on Computer Vision, pages 28959–28969, 2025. 3, 7
2025
-
[52]
Gen3c: 3d-informed world- consistent video generation with precise camera control
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas M¨uller, Alexander Keller, Sanja Fidler, and Jun Gao. Gen3c: 3d-informed world- consistent video generation with precise camera control. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, 2025. 2, 5, 6, 8
2025
-
[53]
Alexander Rusnak et al. Videoartgs: Building digital twins of articulated objects from monocular video.arXiv preprint arXiv:2509.17647, 2025. 2
-
[54]
Meng-Li Shih, Ying-Huan Chen, Yu-Lun Liu, and Brian Curless. Prior-enhanced gaussian splatting for dynamic scene reconstruction from casual video.arXiv preprint arXiv:2512.11356, 2025. 2
-
[55]
Jing Tan, Shuai Yang, Tong Wu, Jingwen He, Yuwei Guo, Ziwei Liu, and Dahua Lin. Imagine360: Immersive 360 video generation from perspective anchor.arXiv preprint arXiv:2412.03552, 2024. 2, 3
-
[56]
Beyond the Frame: Generating 360 Panoramic Videos from Perspective Videos
Zidong Tan, Chenhao Ji, Fuchen Tan, and Yiyang Shen. Be- yond the frame: Generating 360° panoramic videos from perspective videos.arXiv preprint arXiv:2504.07940, 2025. 2, 3, 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Mvdiffusion: Enabling holistic multi- view image generation with correspondence-aware diffusion,
Shitao Tang, Fuyang Zhang, Jiacheng Chen, Peng Wang, and Yasutaka Furukawa. Mvdiffusion: Enabling holistic multi- view image generation with correspondence-aware diffusion,
-
[58]
Distortion-aware convolutional filters for dense prediction in panoramic images
Keisuke Tateno, Nassir Navab, and Federico Tombari. Distortion-aware convolutional filters for dense prediction in panoramic images. InEuropean Conference on Computer Vision (ECCV), pages 707–722. Springer, 2018. 3
2018
-
[59]
Raft: Recurrent all-pairs field transforms for optical flow
Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. InEuropean conference on com- puter vision, pages 402–419. Springer, 2020. 14
2020
-
[60]
Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras.Advances in neural information processing systems, 34:16558–16569, 2021
Zachary Teed and Jia Deng. Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras.Advances in neural information processing systems, 34:16558–16569, 2021. 5
2021
-
[61]
Foundational models for 3d point clouds: A survey and outlook.arXiv preprint arXiv:2501.18594, 2025
Vishal Thengane et al. Foundational models for 3d point clouds: A survey and outlook.arXiv preprint arXiv:2501.18594, 2025. 2
-
[62]
From an image to a scene: Learning to imagine the world from a million 360 videos.Advances in Neural Information Process- ing Systems, 37:17743–17760, 2024
Matthew Wallingford, Anand Bhattad, Aditya Kusupati, Vivek Ramanujan, Matt Deitke, Aniruddha Kembhavi, Roozbeh Mottaghi, Wei-Chiu Ma, and Ali Farhadi. From an image to a scene: Learning to imagine the world from a million 360 videos.Advances in Neural Information Process- ing Systems, 37:17743–17760, 2024. 4, 6, 14
2024
-
[63]
Stylelight: Hdr panorama generation for lighting esti- mation and editing
Guangcong Wang, Yinuo Yang, Chen Change Loy, and Ziwei Liu. Stylelight: Hdr panorama generation for lighting esti- mation and editing. InEuropean Conference on Computer Vision (ECCV), pages 477–492. Springer, 2022. 3
2022
-
[64]
Customizing 360-degree panoramas through text-to-image diffusion models
Hai Wang, Xiaoyu Xiang, Yuchen Fan, and Jing-Hao Xue. Customizing 360-degree panoramas through text-to-image diffusion models. InProceedings of the IEEE/CVF Win- ter Conference on Applications of Computer Vision (WACV), pages 4933–4943, 2024. 3
2024
-
[65]
Videoscene: Distilling video diffusion model to generate 3d scenes in one step
Hanyang Wang, Fangfu Liu, Jiawei Chi, and Yueqi Duan. Videoscene: Distilling video diffusion model to generate 3d scenes in one step. In2025 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 16475– 16485. IEEE, 2025. 2
2025
-
[66]
Vistadream: Sampling multiview consistent images for single-view scene reconstruction
Haiping Wang, Yuan Liu, Ziwei Liu, Wenping Wang, Zhen Dong, and Bisheng Yang. Vistadream: Sampling multiview consistent images for single-view scene reconstruction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 26772–26782, 2025. 2
2025
-
[67]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025. 2, 3, 4, 13
2025
-
[68]
Ning-Hsu Albert Wang and Yu-Lun Liu. Depth anywhere: Enhancing 360 monocular depth estimation via perspective distillation and unlabeled data augmentation.Advances in Neural Information Processing Systems, 37:127739–127764,
-
[69]
360dvd: Controllable panorama video generation with 360-degree video diffusion model
Qian Wang, Weiqi Li, Chong Mou, Xinhua Cheng, and Jian Zhang. 360dvd: Controllable panorama video generation with 360-degree video diffusion model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6913–6923, 2024. 3, 5
2024
-
[70]
Continuous 3d perception model with persistent state
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10510– 10522, 2025. 3
2025
-
[71]
Dust3r: Geometric 3d vi- sion made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vi- sion made easy. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 20697–20709, 2024. 2, 3, 13
2024
-
[72]
Cpa: Camera-pose-awareness diffusion transformer for video generation, 2024
Yuelei Wang, Jian Zhang, Pengtao Jiang, Hao Zhang, Jinwei Chen, and Bo Li. Cpa: Camera-pose-awareness diffusion transformer for video generation, 2024. 2
2024
-
[73]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chunhua Shen, and Tong He. π3: Scalable permutation-equivariant visual geometry learning.arXiv preprint arXiv:2507.13347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[74]
2, 3, 4, 5, 8, 13, 15
-
[75]
Motionctrl: A uni- fied and flexible motion controller for video generation, 2024
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. Motionctrl: A uni- fied and flexible motion controller for video generation, 2024. 2
2024
-
[76]
Motionctrl: A unified and flexible mo- tion controller for video generation.ACM Transactions on Graphics, 2024
Zhouxia Wang et al. Motionctrl: A unified and flexible mo- tion controller for video generation.ACM Transactions on Graphics, 2024. 2
2024
-
[77]
Daniel Watson, Saurabh Saxena, Lala Li, Andrea Tagliasacchi, and David J. Fleet. Controlling space and time with diffusion models, 2025. 2
2025
-
[78]
Aurafu- sion360: Augmented unseen region alignment for reference- based 360deg unbounded scene inpainting
Chung-Ho Wu, Yang-Jung Chen, Ying-Huan Chen, Jie-Ying Lee, Bo-Hsu Ke, Chun-Wei Tuan Mu, Yi-Chuan Huang, Chin-Yang Lin, Min-Hung Chen, Yen-Yu Lin, et al. Aurafu- sion360: Augmented unseen region alignment for reference- based 360deg unbounded scene inpainting. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 16366–16376, 2025. 3
2025
-
[79]
Cat4d: Create anything in 4d with multi-view video diffusion models
Rundi Wu, Ruiqi Gao, Ben Poole, Alex Trevithick, Changxi Zheng, Jonathan T Barron, and Aleksander Holynski. Cat4d: Create anything in 4d with multi-view video diffusion models. InProceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 26057–26068, 2025. 2
2025
-
[80]
Genfusion: Closing the loop between recon- struction and generation via videos
Sibo Wu, Congrong Xu, Binbin Huang, Andreas Geiger, and Anpei Chen. Genfusion: Closing the loop between recon- struction and generation via videos. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 6078–6088, 2025. 2
2025
-
[81]
Panodiffu- sion: 360-degree panorama outpainting via diffusion.arXiv preprint arXiv:2307.03177, 2023
Tianhao Wu, Chuanxia Zheng, and Tat-Jen Cham. Panodiffu- sion: 360-degree panorama outpainting via diffusion.arXiv preprint arXiv:2307.03177, 2023. 3
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.