CRPO: Character-centric Group Relative Policy Optimization for Role-aware Reasoning in Role-playing Agents
Pith reviewed 2026-06-29 21:48 UTC · model grok-4.3
The pith
CRPO realigns RL for role-playing agents by decoupling task logic from stylistic rewards to preserve character fidelity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
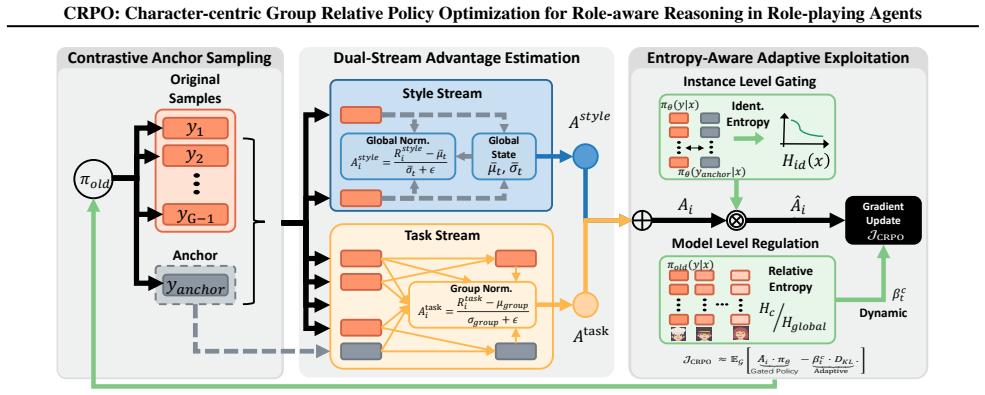
CRPO is a framework that realigns RL objectives with the role-playing task. It improves character distinctiveness through three mechanisms: decoupling task logic from stylistic rewards to resolve gradient conflicts, dynamically adapting optimization constraints based on character complexity, and utilizing generic responses as negative baselines to prevent the model from reverting to a common distribution. Extensive experiments demonstrate that CRPO outperforms existing methods in consistency, emotion and others.
What carries the argument
Character-centric Group Relative Policy Optimization (CRPO), which decouples task logic from stylistic rewards, adapts constraints dynamically, and uses generic responses as negative baselines.
If this is right
- Role-playing agents maintain higher character distinctiveness and emotional consistency while retaining RL reasoning gains.
- Gradient conflicts between utility and style objectives are resolved by the separation of reward signals.
- Optimization constraints adjust automatically to character complexity, reducing the need for manual tuning.
- Generic responses serve as effective negative baselines that block collapse to a common output distribution.
- The approach yields measurable gains over prior methods on consistency and emotion metrics.
Where Pith is reading between the lines
- The same decoupling pattern could extend to other multi-objective RL settings where utility and style or persona compete.
- Agents trained this way might support longer interactive sessions without gradual loss of persona traits.
- The negative baseline technique may generalize to preventing mode collapse in other persona-conditioned generation tasks.
Load-bearing premise
The decoupling of task logic from stylistic rewards, along with dynamic constraint adaptation, can be implemented scalably across characters without new instabilities or per-character hyperparameter search.
What would settle it
Running the paper's role-playing benchmarks with CRPO and finding no measurable gain in character consistency or emotion metrics relative to standard GRPO would falsify the central improvement claim.
Figures




read the original abstract
Recent advancements in Reinforcement Learning (RL), particularly Group Relative Policy Optimization (GRPO), have significantly enhanced the reasoning capabilities of Large Language Models. However, applying these problem-centric optimization methods to role-playing agents often leads to a loss of character fidelity and style collapse, as they prioritize context-specific utility over persona alignment. To address this, we propose Character-Centric Group Relative Policy Optimization (CRPO), a framework designed to realign RL objectives with the role-playing task. CRPO improves character distinctiveness through three mechanisms: decoupling task logic from stylistic rewards to resolve gradient conflicts, dynamically adapting optimization constraints based on character complexity, and utilizing generic responses as negative baselines to prevent the model from reverting to a common distribution. Extensive experiments demonstrate that CRPO outperforms existing methods in consistency, emotion and others.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Character-Centric Group Relative Policy Optimization (CRPO) to adapt Group Relative Policy Optimization (GRPO) for role-playing agents. It claims that CRPO addresses the loss of character fidelity and style collapse in standard RL methods by decoupling task logic from stylistic rewards, dynamically adapting optimization constraints based on character complexity, and using generic responses as negative baselines. The authors assert that extensive experiments show CRPO outperforms existing methods in terms of consistency, emotion, and other metrics.
Significance. If the results hold, this work would offer a targeted improvement to RL-based fine-tuning for role-playing LLMs, helping to balance reasoning capabilities with persona consistency, which is a key challenge in deploying such agents.
major comments (1)
- [Abstract] Abstract: The abstract states that 'extensive experiments demonstrate that CRPO outperforms existing methods in consistency, emotion and others' but provides no quantitative results, baselines, metrics, statistical tests, or implementation details. This absence makes it impossible to assess or verify the central empirical claim.
Simulated Author's Rebuttal
We thank the referee for their review and for highlighting the need for greater specificity in the abstract. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states that 'extensive experiments demonstrate that CRPO outperforms existing methods in consistency, emotion and others' but provides no quantitative results, baselines, metrics, statistical tests, or implementation details. This absence makes it impossible to assess or verify the central empirical claim.
Authors: We agree that the current abstract is too high-level and does not provide enough quantitative grounding for the central claim. In the revised version we will expand the final sentence of the abstract to report the primary evaluation metrics (character consistency, emotion alignment, and style distinctiveness), the key baselines (standard GRPO and SFT), and the magnitude of the observed improvements (e.g., relative gains and statistical significance where computed). This change will make the empirical contribution verifiable directly from the abstract while preserving its brevity. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description present CRPO as a new framework with three high-level mechanisms (decoupling rewards, dynamic constraints, generic baselines) without any equations, fitted parameters, or derivation steps that reduce to self-defined quantities or prior self-citations. No load-bearing claims rely on the authors' own previous work in a way that creates definitional equivalence or forced predictions. The central claim remains independent of its inputs based on the available text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training-free group relative policy optimization.arXiv preprint arXiv:2510.08191,
Cai, Y ., Cai, S., Shi, Y ., Xu, Z., Chen, L., Qin, Y ., Tan, X., Li, G., Li, Z., Lin, H., Mao, Y ., Li, K., and Sun, X. Training-free group relative policy optimization.arXiv preprint arXiv:2510.08191,
-
[2]
SocialBench: Sociality evaluation of role-playing conversational agents
Chen, H., Chen, H., Yan, M., Xu, W., Xing, G., Shen, W., Quan, X., Li, C., Zhang, J., and Huang, F. SocialBench: Sociality evaluation of role-playing conversational agents. In Ku, L.-W., Martins, A., and Srikumar, V . (eds.),Findings of the Association for Computational Linguistics: ACL 2024, pp. 2108– 2126, Bangkok, Thailand, August
2024
-
[4]
Plan Then Action:High-Level Planning Guidance Reinforcement Learning for LLM Reasoning
Dou, Z., Zhao, Q., Wan, Z., Zhang, D., Wang, W., Raiyan, T., Chen, B., Pan, Q., Ouyang, Y ., Gao, Z., et al. Plan then action: High-level planning guidance reinforcement learning for llm reasoning.arXiv preprint arXiv:2510.01833,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
ORPP: Self-optimizing role-playing prompts to enhance language model capabilities
Duan, Y ., Tang, Y ., Chen, K., Nie, L., and Zhang, M. ORPP: Self-optimizing role-playing prompts to enhance language model capabilities. In Christodoulopoulos, C., Chakraborty, T., Rose, C., and Peng, V . (eds.), Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 28585– 28600, Suzhou, China, November
2025
-
[6]
Association for Computational Linguistics. ISBN 979-8-89176-332-6. doi: 10.18653/v1/2025.emnlp-main.1453. Feng, X., Dou, L., and Kong, L. Reasoning does not necessarily improve role-playing ability. In Che, W., Nabende, J., Shutova, E., and Pilehvar, M. T. (eds.),Findings of the Association for Computational Linguistics: ACL 2025, pp. 10301–10314, Vienna,...
-
[7]
ISBN 979-8-89176-256-5
Association for Computational Linguistics. ISBN 979-8-89176-256-5. doi: 10.18653/ v1/2025.findings-acl.537. Gallego, V . Humanish-Roleplay-Llama-3.1-8B. https://huggingface.co/vicgalle/ Humanish-Roleplay-Llama-3.1-8B,
2025
-
[8]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
GLM, T., Zeng, A., Xu, B., Wang, B., Zhang, C., Yin, D., Zhang, D., Rojas, D., Feng, G., et al. Chatglm: A family of large language models from glm-130b to glm-4 all tools.arXiv preprint arXiv:2406.12793,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
Association for Computational Linguistics. ISBN 979-8-89176-251-0. doi: 10.18653/ v1/2025.acl-long.731. Hu, J., Liu, J. K., Xu, H., and Shen, W. Reinforce++: Stabilizing critic-free policy optimization with global ad- vantage normalization.arXiv preprint arXiv:2501.03262,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Kool, W., van Hoof, H., and Welling, M
doi: 10.1145/3773279. Kool, W., van Hoof, H., and Welling, M. Buy 4 REINFORCE samples, get a baseline for free! InICLR 2019 Workshop drlStructPred,
-
[11]
Sgpo: Self-generated preference optimization based on self-improver.arXiv preprint arXiv:2507.20181,
Lee, H., Jo, D., Yun, S., and Kim, S. Sgpo: Self-generated preference optimization based on self-improver.arXiv preprint arXiv:2507.20181,
-
[12]
Understanding Generalization in Role-Playing Models via Information Theory
Li, Y ., Lang, H., Huang, F., Qian, T., and Li, Y . Understanding generalization in role-playing models via information theory.arXiv preprint arXiv:2512.17270,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Outcome-Grounded Advantage Reshaping for Fine-Grained Credit Assignment in Mathematical Reasoning
Li, Z., Kang, L., Xiao, F., Xing, L., Si, Q., Li, Z., Gong, W., Yang, D., Xiao, Y ., and Guo, H. Outcome- grounded advantage reshaping for fine-grained credit assignment in mathematical reasoning.arXiv preprint arXiv:2601.07408,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
MOA: Multi-Objective Alignment for Role-Playing Agents
Liao, C., Wang, K., Wu, Y ., Huang, F., and Li, Y . Moa: Multi-objective alignment for role-playing agents.arXiv preprint arXiv:2512.09756,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
Liu, S.-Y ., Dong, X., Lu, X., Diao, S., Belcak, P., Liu, M., Chen, M.-H., Yin, H., Wang, Y .-C. F., Cheng, K.-T., et al. Gdpo: Group reward-decoupled normalization policy optimization for multi-reward rl optimization.arXiv preprint arXiv:2601.05242,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Understanding R1-Zero-Like Training: A Critical Perspective
Liu, Z., Chen, C., Li, W., Qi, P., Pang, T., Du, C., Lee, W. S., and Lin, M. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
RoleMRC: A fine-grained composite benchmark for role-playing and instruction- following
Lu, J., Li, J., Shen, G., Gui, L., An, S., He, Y ., Yin, D., and Sun, X. RoleMRC: A fine-grained composite benchmark for role-playing and instruction- following. In Che, W., Nabende, J., Shutova, E., and Pilehvar, M. T. (eds.),Findings of the Association for Computational Linguistics: ACL 2025, pp. 21008– 21030, Vienna, Austria, July
2025
-
[18]
Association for Computational Linguistics. ISBN 979-8-89176-256-5. doi: 10.18653/v1/2025.findings-acl.1082. Lu, K., Yu, B., Zhou, C., and Zhou, J. Large language models are superpositions of all characters: Attaining arbitrary role-play via self-alignment. In Ku, L.-W., Martins, A., and Srikumar, V . (eds.),Proceedings of the 62nd Annual Meeting of the As...
-
[19]
Maaten, L
18653/v1/2024.acl-long.423. Maaten, L. v. d. and Hinton, G. Visualizing data using t-sne.Journal of machine learning research, 9(Nov): 2579–2605,
2024
-
[20]
Ngrpo: Negative-enhanced group relative policy optimization
Nan, G., Chen, S., Huang, J., Lu, M., Wang, D., Xie, C., Xiong, W., Zeng, X., Zhou, Q., Li, Y ., et al. Ngrpo: Negative-enhanced group relative policy optimization. arXiv preprint arXiv:2509.18851,
-
[21]
Deriving character logic from storyline as codified decision trees
Peng, L., Zhou, K., Yun, L., Hou, Y ., and Shang, J. Deriving character logic from storyline as codified decision trees. arXiv preprint arXiv:2601.10080,
-
[22]
Qwen, :, Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., Lin, H., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
RiskPO: Risk-based policy optimization with verifiable reward for LLM post-training
Ren, T., Jiang, J., Yang, H., Tian, W., and Peng, Y . RiskPO: Risk-based policy optimization with verifiable reward for LLM post-training. InNeurIPS 2025 Workshop MLxOR: Mathematical Foundations and Operational Integration of Machine Learning for Uncertainty-Aware Decision- Making,
2025
-
[24]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Simoni, M., Fontana, A., Rossolini, G., Saracino, A., and Mori, P. Gtpo: Stabilizing group relative policy optimization via gradient and entropy control.arXiv preprint arXiv:2508.03772,
-
[27]
The rise of darkness: Safety-utility trade- offs in role-playing dialogue agents
Tang, Y ., Chen, K., Bai, X., Niu, Z.-Y ., Wang, B., Liu, J., and Zhang, M. The rise of darkness: Safety-utility trade- offs in role-playing dialogue agents. In Che, W., Nabende, J., Shutova, E., and Pilehvar, M. T. (eds.),Findings of the Association for Computational Linguistics: ACL 2025, pp. 16313–16337, Vienna, Austria, July 2025a. Association for Com...
-
[28]
SCOPE-RL: Stable and Quantitative Control of Policy Entropy in RL Post-Training
Wang, C., Li, Z., Bai, J., Zhang, Y ., Cui, S., Zhao, Z., and Wang, Y . Arbitrary entropy policy optimization breaks the exploration bottleneck of reinforcement learning.arXiv preprint arXiv:2510.08141, 2025a. Wang, H., Ma, C., Reid, I., and Yaqub, M. Kalman filter enhanced grpo for reinforcement learning-based language model reasoning.arXiv preprint arXi...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.findings-acl.878 2024
-
[29]
Xie, X., Wang, X., Wang, W., Chen, S., and Lin, W. Dagrpo: Rectifying gradient conflict in reasoning via distinctiveness-aware group relative policy optimization. arXiv preprint arXiv:2512.06337,
-
[30]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025a. Yang, A., Xiao, B., Wang, B., Zhang, B., Bian, C., Yin, C., Lv, C., et al. Baichuan 2: Open large-scale language models.arXiv preprint arXiv:2309.10305, 2025b. Yang, S., Lu, Z., Yang, Y ., Lv, B., Shen, Y ., and Liu, N. Hycora: Hyper-contr...
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
CPO: Addressing reward ambiguity in role- playing dialogue via comparative policy optimization
Ye, J., Wang, R., Wu, Y ., Ma, V ., Fang, F., Huang, F., and Li, Y . CPO: Addressing reward ambiguity in role- playing dialogue via comparative policy optimization. In Christodoulopoulos, C., Chakraborty, T., Rose, C., and Peng, V . (eds.),Findings of the Association for Computational Linguistics: EMNLP 2025, pp. 297– 323, Suzhou, China, November
2025
-
[32]
Association for Computational Linguistics. ISBN 979-8-89176-335-7. doi: 10.18653/v1/2025.findings-emnlp.18. Yu, H., Qi, Z., Zhao, Y ., Nottingham, K., Xuan, K., Majumder, B. P., Zhu, H., Liang, P. P., and You, J. Sotopia-rl: Reward design for social intelligence.arXiv preprint arXiv:2508.03905, 2025a. Yu, Q., Zhang, Z., Zhu, R., Yuan, Y ., Zuo, X., Yue, Y...
-
[33]
doi: 10.18653/v1/2024.emnlp-main.697
Association for Computational Linguistics. doi: 10.18653/v1/2024.emnlp-main.697. Zhang, B., Huang, Y ., Cui, W., and Zhang, H. Thinking before speaking: A role-playing model with mindset. arXiv preprint arXiv:2409.13752,
-
[34]
Mt-bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues
Zhang, X., Wen, S., Wu, W., and Huang, L. Edge-grpo: Entropy-driven grpo with guided error correction for advantage diversity.arXiv preprint arXiv:2507.21848, 2025a. Zhang, X., Wu, S., Zhu, Y ., Tan, H., Yu, S., He, Z., and Jia, J. Scaf-grpo: Scaffolded group relative policy optimization for enhancing llm reasoning.arXiv preprint arXiv:2510.19807, 2025b. ...
-
[35]
Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y ., Fried, D., Neubig, G., and Sap, M. Sotopia: Interactive evaluation for social intelligence in language agents.arXiv preprint arXiv:2310.11667, 2024b. Ziegler, D. M., Stiennon, N., Wu, J., Brown, T. B., Radford, A., Amodei, D., Christiano, P., and Irving, G. Fine-tuning la...
-
[36]
brave”, “historical figure
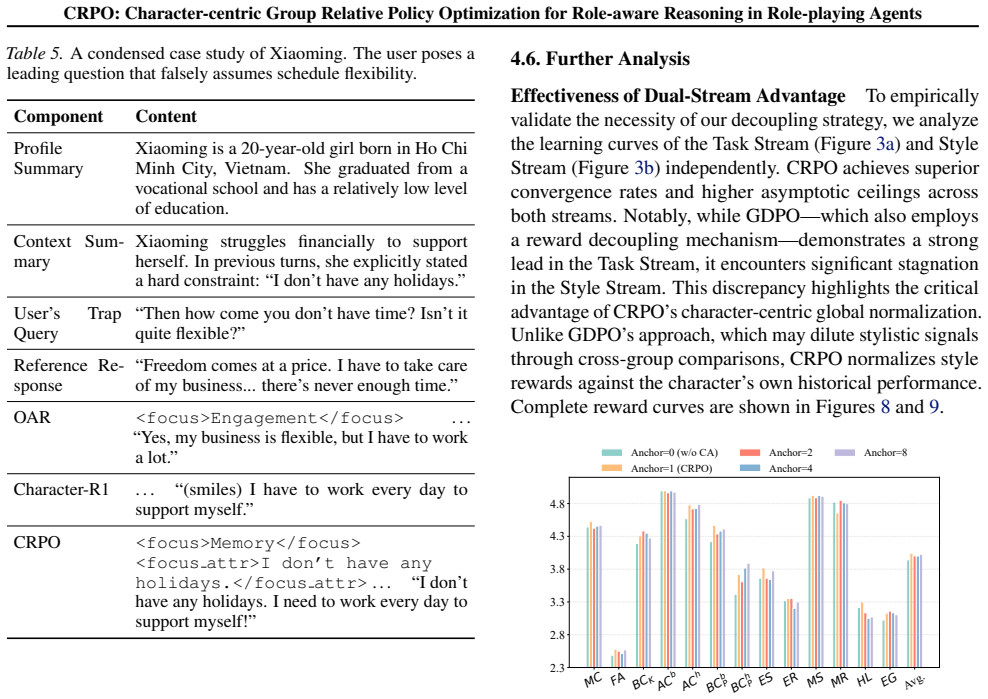
Following Character-R1 (Tang et al., 2026), these focus dimensions correspond to the evaluation dimensions in CharacterBench and thus have natural annotations. {Character Profile} You FIRST think about the reasoning process as an internal monologue and then provide the final answer. The reasoning process MUST BE enclosed within <think> </think> tags. Duri...
2026
-
[37]
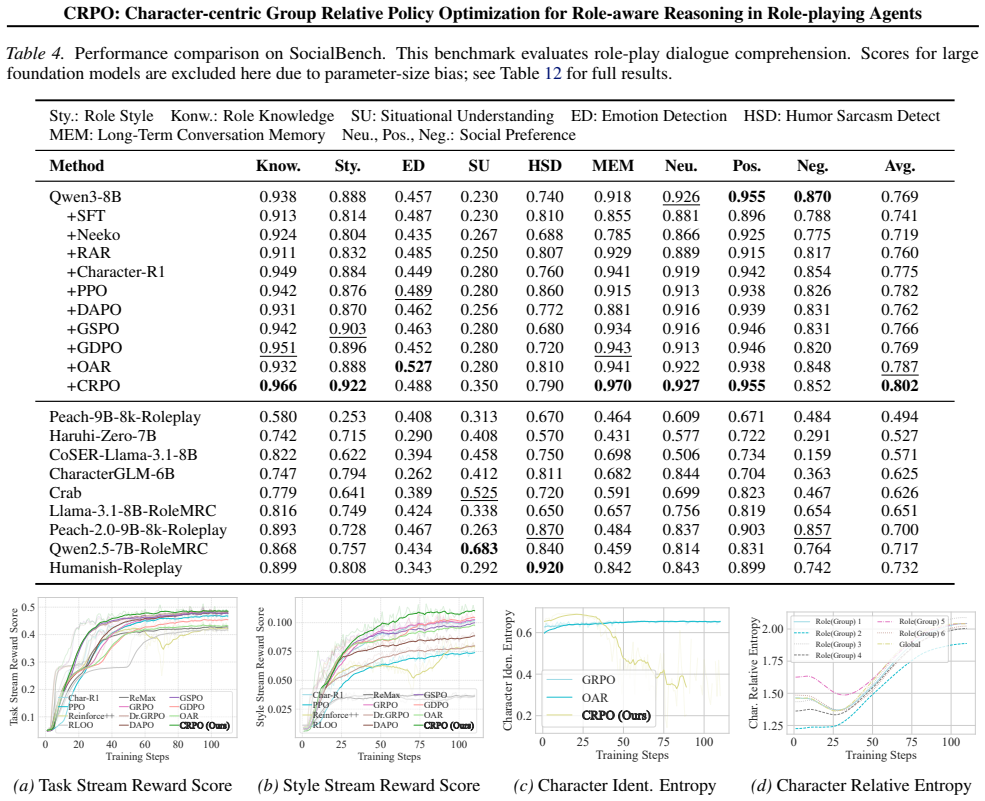
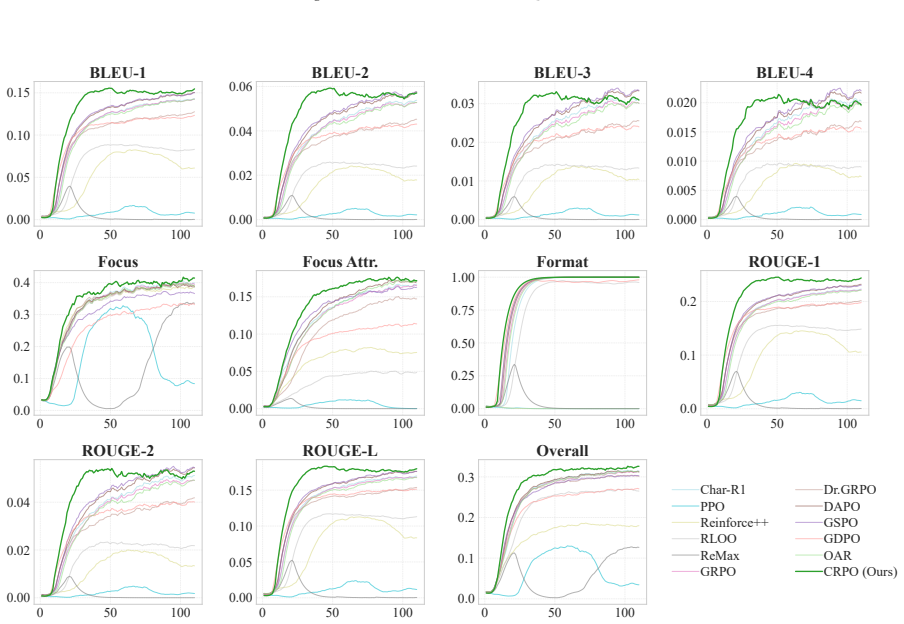
A fine-grained credit assignment that reshapes token-level advantages based on outcome influence. D. Experimental Result Details D.1. Performance on Comprehensive Role-Play Dialogue Generation As shown in Table 3, CRPO consistently outperforms all baselines across both Llama-3.2-3B and Qwen3-8B backbones, establishing a new state-of-the-art on CharacterBe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.