TapSampling: Inference-Time Sampling with a Task-Progress-Understanding Verifier for Robotic Manipulation
Pith reviewed 2026-06-29 21:54 UTC · model grok-4.3
The pith
TapSampling improves generalist robotic policies at inference time by sampling multiple actions and selecting them with a task-progress verifier.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
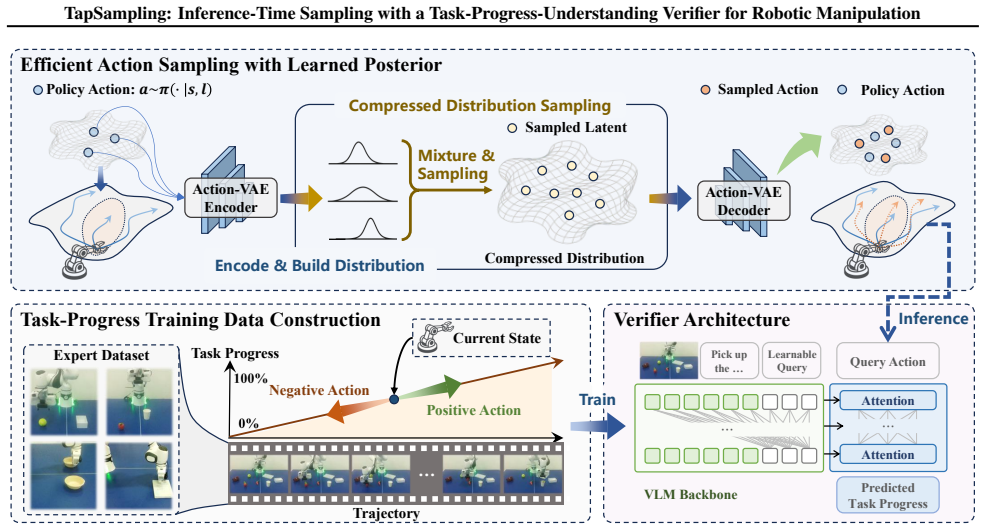
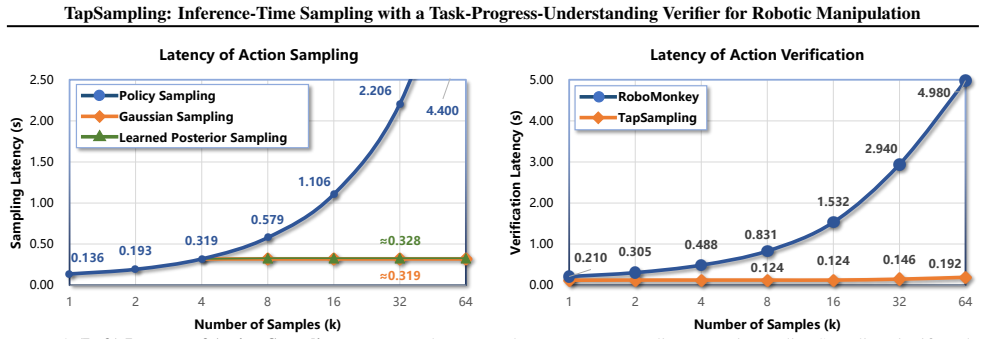
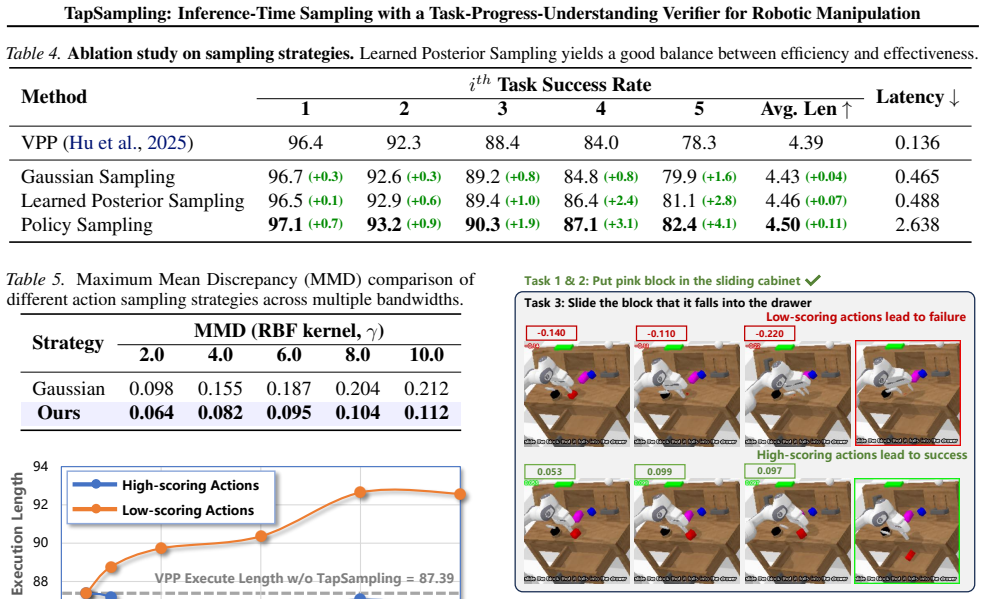
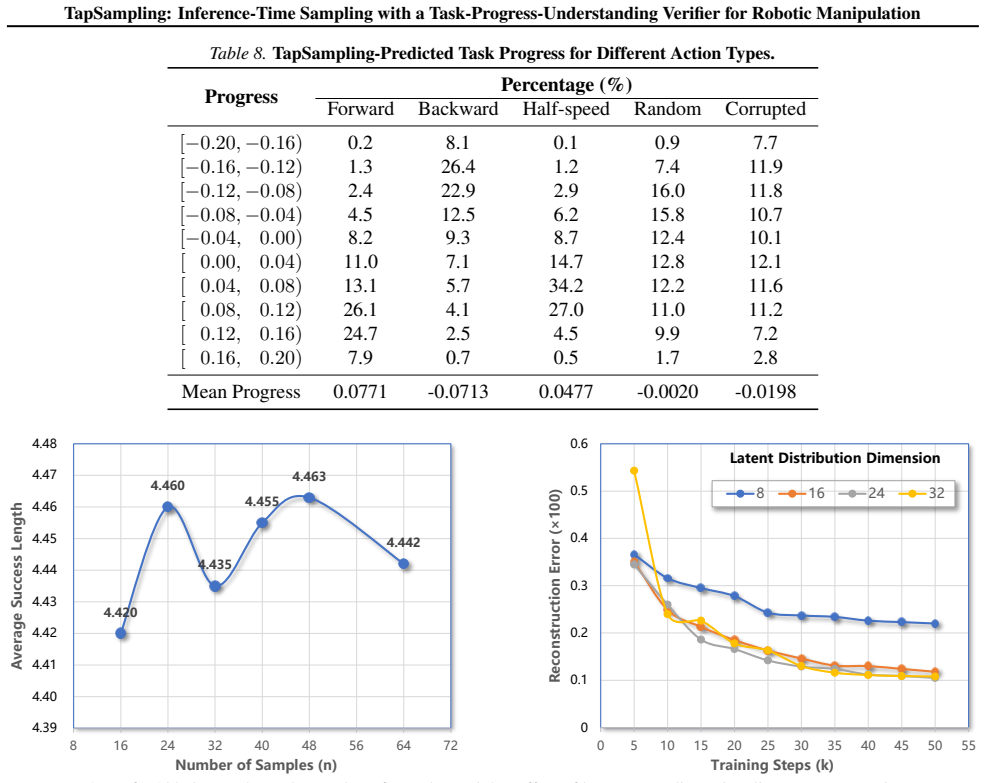
TapSampling is a plug-and-play framework for inference-time sampling. It introduces an Action-VAE that maps policy-generated actions into a low-dimensional latent space from which multiple samples can be drawn and decoded into candidate actions that approximate the true action distribution. It then formulates action verification as task-progress outcome prediction, training a semantically grounded verifier on the intrinsic sequential structure of robotic datasets to enable interpretable selection of the action that contributes most to task completion.
What carries the argument
Action-VAE for generating multiple candidate actions from a compressed latent distribution, paired with a task-progress outcome predictor that ranks candidates by expected progress toward task completion.
If this is right
- Substantial performance gains appear across multiple generalist policies without policy finetuning.
- Improvements hold in both simulated and real-world robotic manipulation environments.
- The framework operates independently of the underlying policy architecture.
- Action selection becomes interpretable through explicit task-progress predictions.
Where Pith is reading between the lines
- The approach implies that many existing policies already encode useful action distributions that remain underutilized under single-shot inference.
- Similar verifier-guided sampling could be tested on non-robotic sequential decision tasks where outcome predictors can be trained from ordered data.
- If the verifier generalizes across tasks, the method might support rapid adaptation of fixed policies to new environments by changing only the selection criterion.
Load-bearing premise
The task-progress outcome predictor, trained on the intrinsic sequential structure of robotic datasets, can reliably rank candidate actions by their expected contribution to task completion.
What would settle it
Controlled trials in which actions ranked highest by the verifier produce no higher task success rates than randomly selected or lower-ranked candidates from the same policy.
Figures




read the original abstract
Existing embodied control research demonstrates remarkable performance improvements by scaling training data and model size. We instead explore inference-time strategy as an alternative axis. Non-deterministic generative models, such as diffusion and autoregressive models, have been widely adopted in the field of embodied control. However, the single-shot inference paradigm limits their performance. In this paper, we propose \textbf{TapSampling}, a plug-and-play framework for inference-time sampling. First, we introduce an Action-VAE that represents actions in a low-dimensional latent space by mapping policy-generated initial actions into a compressed posterior distribution, from which any number of latent samples can be drawn and decoded into candidate actions that approximate the true action distribution. Second, we formulate action verification as task-progress outcome prediction, using the intrinsic sequential structure of robotic datasets to train a semantically grounded verifier for interpretable action selection. Furthermore, TapSampling is a policy-agnostic framework. Extensive experiments in both simulated and real-world environments demonstrate that our method substantially improves multiple generalist policies without further policy finetuning. Code and models are available at the project page.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TapSampling, a plug-and-play inference-time sampling framework for robotic manipulation. It first trains an Action-VAE to map policy-generated actions into a low-dimensional latent space from which multiple candidate actions can be sampled and decoded. It then trains a task-progress outcome predictor on the intrinsic sequential structure of robotic datasets to serve as a verifier that ranks candidates by expected contribution to task completion. The central claim is that this two-stage procedure substantially improves the performance of multiple generalist policies in both simulated and real-world environments without any policy fine-tuning.
Significance. If the reported gains are robust across policies and environments, the work demonstrates a practical inference-time alternative to further scaling of training data or model size in embodied control. The policy-agnostic design and use of existing dataset structure for verifier training are notable strengths; the public release of code and models supports reproducibility.
minor comments (2)
- [Abstract] Abstract: the phrase 'substantially improves' is used without any quantitative metrics, baselines, or effect sizes; the full manuscript should make these explicit in the abstract or early results section.
- The manuscript mentions a project page for code and models but provides no URL or access instructions.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of TapSampling, the recognition of its policy-agnostic design and use of dataset structure, and the recommendation for minor revision. No major comments were listed in the report.
Circularity Check
No significant circularity
full rationale
The paper presents TapSampling as an empirical, policy-agnostic inference-time procedure: an Action-VAE compresses policy actions into a latent space for sampling candidates, followed by a task-progress outcome predictor trained on the sequential structure of robotic datasets for ranking. No equations, derivations, or first-principles claims appear in the abstract or description. No fitted parameters are renamed as predictions, no self-citations are invoked as load-bearing uniqueness theorems, and no ansatzes are smuggled. The central claim reduces to experimental improvement on multiple policies, which is an external, falsifiable assertion rather than a self-referential reduction. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
PaliGemma: A versatile 3B VLM for transfer
Beyer, L., Steiner, A., Pinto, A. S., Kolesnikov, A., Wang, X., Salz, D., Neumann, M., Alabdulmohsin, I., Tschan- nen, M., Bugliarello, E., et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M. R., Finn, C., Fusai, N., Galliker, M. Y ., Ghosh, D., Groom, L., Hausman, K., et al. π0.5: a vision-language-action model with open-world gener- alization. In9th Annual Conference on Robot Learning, 2025a. Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., F...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Bu, Q., Li, H., Chen, L., Cai, J., Zeng, J., Cui, H., Yao, M., and Qiao, Y . Towards synergistic, generalized, and efficient dual-system for robotic manipulation.arXiv preprint arXiv:2410.08001,
-
[5]
Dai, M., Liu, L., Bai, Y ., Liu, Y ., Wang, Z., SU, R., Chen, C., Lin, L., and Wu, X. Rover: Robot reward model as test-time verifier for vision-language-action model.arXiv preprint arXiv:2510.10975,
-
[6]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
Intelligence, P. π∗ 0.6: a vla that learns from experience.arXiv preprint arXiv:2511.14759,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
arXiv preprint arXiv:2407.14041 (2024)
Qi, Z., Bai, L., Xiong, H., and Xie, Z. Not all noises are cre- ated equally: Diffusion noise selection and optimization. arXiv preprint arXiv:2407.14041,
-
[8]
Team, Q. et al. Qwen2 technical report.arXiv preprint arXiv:2407.10671, 2(3),
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Tong, Y ., Zhu, D., Hu, Z., Yang, J., and Zhao, Z. Noise pro- jection: Closing the prompt-agnostic gap behind text-to- image misalignment in diffusion models.arXiv preprint arXiv:2510.14526,
-
[10]
Reasoning aware self-consistency: Leveraging reasoning paths for efficient llm sampling
Wan, G., Wu, Y ., Chen, J., and Li, S. Reasoning aware self-consistency: Leveraging reasoning paths for efficient llm sampling. InThe 2025 Annual Conference of the Nations of the Americas Chapter of the ACL,
2025
-
[11]
arXiv preprint arXiv:2512.02834 (2025)
Yang, S., Zhang, Y ., He, H., Pan, L., Li, X., Bai, C., and Li, X. Steering vision-language-action models as anti- exploration: A test-time scaling approach.arXiv preprint arXiv:2512.02834, 2025a. Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y ., Hong, W., Zhang, X., Feng, G., Yin, D., Yuxuan.Zhang, Wang, W., Cheng, Y ., Xu, B., Gu, X...
-
[12]
Zhai, S., Zhang, Q., Zhang, T., Huang, F., Zhang, H., Zhou, M., Zhang, S., Liu, L., Lin, S., and Pang, J. A vision- language-action-critic model for robotic real-world rein- forcement learning.arXiv preprint arXiv:2509.15937,
-
[13]
A Survey on Test-Time Scaling in Large Language Models: What, How, Where, and How Well?
Zhang, J., Luo, Y ., Anwar, A., Sontakke, S. A., Lim, J. J., Thomason, J., Biyik, E., and Zhang, J. ReWiND: Language-guided rewards teach robot policies without new demonstrations. In9th Annual Conference on Robot Learning, 2025a. Zhang, Q., Lyu, F., Sun, Z., Wang, L., Zhang, W., Hua, W., Wu, H., Guo, Z., Wang, Y ., Muennighoff, N., et al. A survey on tes...
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.