StreamChar: Long-Horizon Streaming Character Audio-Video Generation with Decoupled Orchestration
Pith reviewed 2026-06-29 22:13 UTC · model grok-4.3
The pith
StreamChar decouples LLM orchestration from DiT denoising to stream character audio-video in real time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
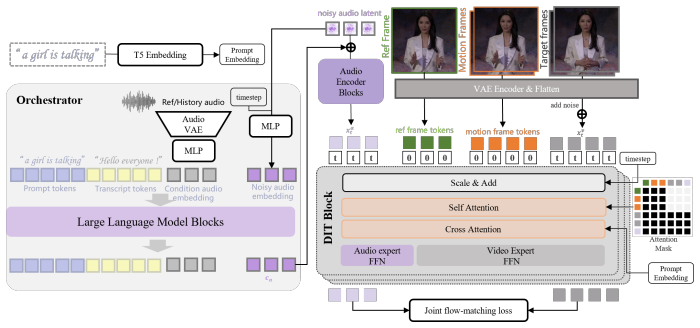
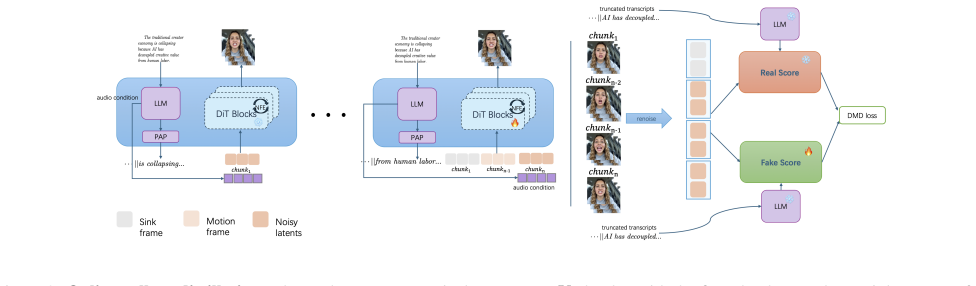
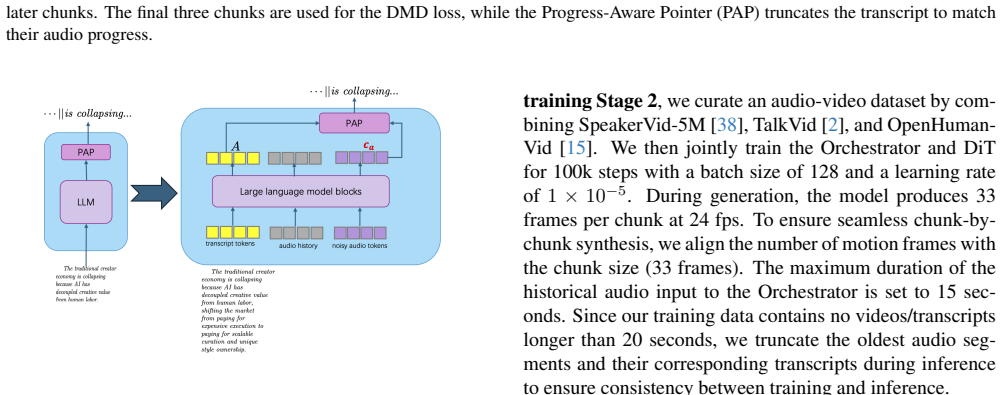
StreamChar separates long-horizon orchestration from short-window audio-video denoising. An LLM-based orchestrator produces frame-aligned audio conditions from the transcript and historical context, and a joint audio-video DiT performs local bidirectional denoising with reference and motion-frame conditioning. Efficiency comes from a two-stage distillation pipeline that first compresses the sampler then fine-tunes under online chunk rollouts, aided by a progress-aware pointer for partial-transcript alignment and sink-chunk memory as a persistent visual anchor.
What carries the argument
Decoupled orchestration in which an LLM produces frame-aligned audio conditions that drive a joint audio-video DiT denoiser.
If this is right
- The system runs in real time on a single H100 GPU under both short-clip and long-horizon protocols.
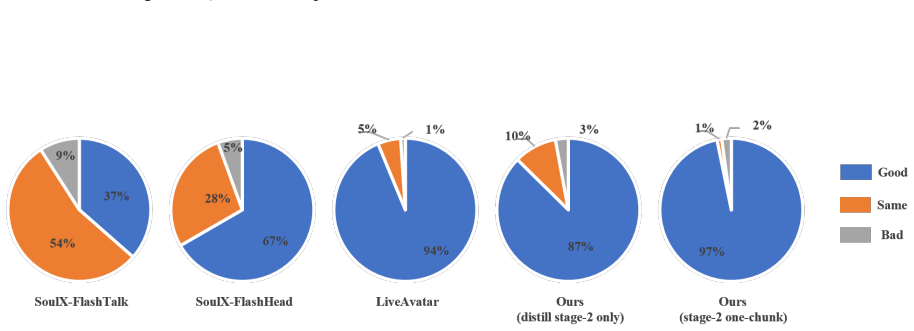
- Transcript fidelity and audio-visual synchronization remain higher than recent joint and audio-driven baselines.
- Visual drift is reduced over extended sequences through the persistent sink-chunk memory anchor.
- A favorable system-level trade-off is obtained among fidelity, synchronization, quality, and stability.
- The design supports chunk-wise autoregressive generation without the usual accumulation of misalignment.
Where Pith is reading between the lines
- The separation of orchestration from denoising could allow the LLM component to be swapped for different languages or speaking styles without retraining the denoiser.
- The sink-chunk memory pattern may generalize to other chunked generation tasks that need persistent identity across many steps.
- Real-time single-GPU performance opens direct use in live interactive character systems where latency must stay under playback budget.
- The two-stage distillation approach suggests a route to further speed gains if the student model is later quantized or pruned.
Load-bearing premise
The two-stage distillation pipeline combined with the progress-aware pointer and sink-chunk memory will preserve quality and prevent drift across long horizons without post-hoc tuning.
What would settle it
A long-horizon rollout test that measures accumulating transcript-audio misalignment or visual drift exceeding the levels reported for the long-horizon protocol, or that fails to sustain real-time playback on a single H100 GPU.
Figures



read the original abstract
Real-time streaming joint audio-video generation for character animation requires a generator to speak the requested transcript, maintain visual identity across chunks, and run within a strict playback budget. These requirements are difficult to satisfy simultaneously: chunk-wise autoregressive generation can accumulate transcript-audio misalignment and visual drift, while the few-step distillation needed for low latency often degrades spatial diversity and temporal quality. We present StreamChar, a streaming framework that separates long-horizon orchestration from short-window audio-video denoising. An LLM-based orchestrator uses the transcript and historical context to produce frame-aligned audio conditions, and a joint audio-video DiT performs local bidirectional denoising with reference and motion-frame conditioning. For efficient deployment, we use a two-stage distillation pipeline that first compresses the sampler and then fine-tunes the student under online chunk rollouts. A progress-aware pointer aligns partial transcripts with generated audio during rollout training, and a sink-chunk memory provides a persistent visual anchor for reducing long-horizon drift. Experiments on short-clip and long-horizon protocols show that StreamChar runs in real time on a single H100 GPU and provides a favorable system-level trade-off among transcript fidelity, audio-visual synchronization, visual quality, and streaming stability compared with recent joint and audio-driven baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces StreamChar, a streaming framework for long-horizon character audio-video generation. It decouples long-horizon orchestration (LLM-based orchestrator producing frame-aligned audio conditions from transcript and context) from short-window generation (joint audio-video DiT with reference/motion conditioning). Efficiency comes from a two-stage distillation pipeline; alignment and stability are addressed via a progress-aware pointer and sink-chunk memory. Experiments on short-clip and long-horizon protocols are claimed to demonstrate real-time single-H100-GPU operation together with favorable system-level trade-offs in transcript fidelity, audio-visual synchronization, visual quality, and streaming stability versus recent joint and audio-driven baselines.
Significance. If the quantitative results and ablations support the claims, the decoupled orchestration plus targeted mechanisms for chunked rollout would constitute a practical advance for real-time streaming audio-visual character animation, directly addressing the tension between latency, identity preservation, and long-horizon consistency that limits current joint or audio-driven generators.
major comments (2)
- [Abstract] Abstract: the central empirical claim—that StreamChar achieves real-time single-H100 operation and a favorable trade-off among transcript fidelity, AV synchronization, visual quality, and streaming stability—is stated without any numerical metrics, error bars, dataset sizes, or baseline scores. This absence makes the headline result impossible to evaluate from the provided text.
- [Experiments] Experiments section (and method description of the two-stage distillation, progress-aware pointer, and sink-chunk memory): the headline trade-off is asserted to rest on these three components successfully preventing drift and quality loss during chunked rollout, yet no ablation isolating their individual contributions to the four reported metrics is supplied. Without such isolation it cannot be determined whether the observed trade-off is robust or dependent on unstated hyper-parameter choices.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract and experimental analysis can be strengthened with additional quantitative details and ablations, and we will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim—that StreamChar achieves real-time single-H100 operation and a favorable trade-off among transcript fidelity, AV synchronization, visual quality, and streaming stability—is stated without any numerical metrics, error bars, dataset sizes, or baseline scores. This absence makes the headline result impossible to evaluate from the provided text.
Authors: We agree that the abstract would benefit from explicit numerical support. The experiments section already contains the relevant metrics (e.g., real-time FPS on H100, transcript fidelity, AV sync error, visual quality scores, and stability measures versus baselines). In the revision we will extract and insert the key headline numbers, dataset sizes, and baseline comparisons directly into the abstract while preserving its length. revision: yes
-
Referee: [Experiments] Experiments section (and method description of the two-stage distillation, progress-aware pointer, and sink-chunk memory): the headline trade-off is asserted to rest on these three components successfully preventing drift and quality loss during chunked rollout, yet no ablation isolating their individual contributions to the four reported metrics is supplied. Without such isolation it cannot be determined whether the observed trade-off is robust or dependent on unstated hyper-parameter choices.
Authors: The referee is correct that the current manuscript presents only the full-system results and does not include component-wise ablations for the two-stage distillation, progress-aware pointer, and sink-chunk memory. We will add a dedicated ablation subsection that isolates each mechanism's contribution to transcript fidelity, AV synchronization, visual quality, and streaming stability, reporting the four metrics for each variant. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents a streaming audio-video generation framework using an LLM orchestrator, joint DiT denoiser, two-stage distillation, progress-aware pointer, and sink-chunk memory. No equations, fitted parameters, or self-citations are described that reduce any claimed prediction or result to its inputs by construction. The method description relies on standard LLM and diffusion components, with performance claims resting on external experimental comparisons rather than internal reductions or self-referential definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Boyuan Chen, Diego Marti Monso, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann
-
[2]
arXiv preprint arXiv:2407.01392 (2024)
Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion. arXiv:2407.01392 [cs.LG] https://arxiv.org/abs/2407.01392
-
[3]
Shunian Chen, Hejin Huang, Yexin Liu, Zihan Ye, Pengcheng Chen, Chenghao Zhu, Michael Guan, Rongsheng Wang, Junying Chen, Guan- bin Li, Ser-Nam Lim, Harry Yang, and Benyou Wang. 2025. TalkVid: A Large-Scale Diversi- fied Dataset for Audio-Driven Talking Head Synthe- sis. arXiv:2508.13618 [cs.CV]https://arxiv. org/abs/2508.13618
-
[4]
Joon Son Chung and Andrew Zisserman. 2016. Out of Time: Automated Lip Sync in the Wild. InWorkshop on Multi-view Lip-reading, ACCV
2016
-
[5]
Justin Cui, Jie Wu, Ming Li, Tao Yang, Xiaojie Li, Rui Wang, Andrew Bai, Yuanhao Ban, and Cho-Jui Hsieh
-
[6]
Self-Forcing++: Towards Minute-Scale High-Quality Video Generation
Self-Forcing++: Towards Minute-Scale High- Quality Video Generation. arXiv:2510.02283 [cs.CV] https://arxiv.org/abs/2510.02283
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Zhihao Du, Qian Chen, Shiliang Zhang, Kai Hu, Heng Lu, Yexin Yang, Hangrui Hu, Siqi Zheng, Yue Gu, Ziyang Ma, Zhifu Gao, and Zhijie Yan. 2024. CosyV oice: A Scalable Multilingual Zero-shot Text- to-speech Synthesizer based on Supervised Seman- tic Tokens. arXiv:2407.05407 [cs.SD]https:// arxiv.org/abs/2407.05407
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Xin Gao, Li Hu, Siqi Hu, Mingyang Huang, Chaonan Ji, Dechao Meng, Jinwei Qi, Penchong Qiao, Zhen Shen, Yafei Song, Ke Sun, Linrui Tian, Guangyuan Wang, Qi Wang, Zhongjian Wang, Jiayu Xiao, Sheng Xu, Bang Zhang, Peng Zhang, Xindi Zhang, Zhe Zhang, Jingren Zhou, and Lian Zhuo. 2025. Wan-S2V: Audio-Driven Cinematic Video Genera- tion. arXiv:2508.18621 [cs.CV...
-
[9]
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, Eitan Richardson, Guy Shiran, Itay Chachy, Jonathan Chetboun, Michael Finkelson, Michael Kupchick, Nir Zabari, Nitzan Guetta, Noa Kotler, Ofir Bibi, Ori Gordon, Poriya Panet, Roi Benita, Shahar Armon, V...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Haorui He, Zengqiang Shang, Chaoren Wang, Xuyuan Li, Yicheng Gu, Hua Hua, Liwei Liu, Chen Yang, Jiaqi Li, Peiyang Shi, Yuancheng Wang, Kai Chen, Pengyuan Zhang, and Zhizheng Wu. 2024. Emilia: An Extensive, Multilingual, and Diverse Speech Dataset for Large-Scale Speech Generation. arXiv:2407.05361 [eess.AS]https : / / arxiv . org/abs/2407.05361
-
[11]
Martin Heusel, Hubert Ramsauer, Thomas Un- terthiner, Bernhard Nessler, and Sepp Hochreiter
-
[12]
In Advances in Neural Information Processing Systems (NeurIPS), V ol
GANs Trained by a Two Time-Scale Up- date Rule Converge to a Local Nash Equilibrium. In Advances in Neural Information Processing Systems (NeurIPS), V ol. 30
-
[13]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. De- noising Diffusion Probabilistic Models. InAdvances in Neural Information Processing Systems (NeurIPS), V ol. 33
2020
-
[14]
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. 2025. Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffu- sion. arXiv:2506.08009 [cs.CV]https://arxiv. org/abs/2506.08009
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Yubo Huang, Hailong Guo, Fangtai Wu, Shifeng Zhang, Shijie Huang, Qijun Gan, Lin Liu, Sirui Zhao, Enhong Chen, Jiaming Liu, and Steven Hoi. 2026. Live Avatar: Streaming Real-time Audio-Driven Avatar Generation with Infinite Length. arXiv:2512.04677 [cs.CV]https : / / arxiv . org/abs/2512.04677
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [16]
-
[17]
Chunyu Li, Jiaye Li, Ruiqiao Mei, Haoyuan Xia, Hao Zhu, Jingdong Wang, and Siyu Zhu. 2026. Hallo-Live: Real-Time Streaming Joint Audio- Video Avatar Generation with Asynchronous Dual- Stream and Human-Centric Preference Distillation. arXiv:2604.23632 [cs.CV]https : / / arxiv . org/abs/2604.23632
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Hui Li, Mingwang Xu, Yun Zhan, Shan Mu, Jiaye Li, Kaihui Cheng, Yuxuan Chen, Tan Chen, Mao Ye, Jingdong Wang, and Siyu Zhu. 2025. Open- HumanVid: A Large-Scale High-Quality Dataset for Enhancing Human-Centric Video Generation. arXiv:2412.00115 [cs.CV]https : / / arxiv . org/abs/2412.00115
- [19]
-
[20]
Kunhao Liu, Wenbo Hu, Jiale Xu, Ying Shan, and Shijian Lu. 2025. Rolling Forcing: Autoregressive Long Video Diffusion in Real Time.arXiv preprint arXiv:2509.25161(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Kai Liu, Wei Li, Lai Chen, Shengqiong Wu, Yan- hao Zheng, Jiayi Ji, Fan Zhou, Jiebo Luo, Ziwei Liu, Hao Fei, and Tat-Seng Chua. 2026. JavisDiT: Joint Audio-Video Diffusion Transformer with Hierarchical Spatio-Temporal Prior Synchronization
2026
-
[22]
Chetwin Low, Weimin Wang, and Calder Katyal
-
[23]
Ovi: Twin Backbone Cross-Modal Fusion for Audio-Video Generation
Ovi: Twin Backbone Cross-Modal Fusion for Audio-Video Generation. arXiv:2510.01284 [cs.MM] https://arxiv.org/abs/2510.01284
work page internal anchor Pith review Pith/arXiv arXiv
- [24]
- [25]
-
[26]
William Peebles and Saining Xie. 2023. Scalable Dif- fusion Models with Transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 4195–4205
2023
- [27]
-
[28]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. 2022. High- Resolution Image Synthesis with Latent Diffusion Models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 10684–10695
2022
-
[30]
Team Seedance, De Chen, Liyang Chen, Xin Chen, Ying Chen, Zhuo Chen, Zhuowei Chen, Feng Cheng, Tianheng Cheng, Yufeng Cheng, Mojie Chi, Xuyan Chi, Jian Cong, Qinpeng Cui, Fei Ding, Qide Dong, Yujiao Du, Haojie Duanmu, Junliang Fan, Jiarui Fang, Jing Fang, Zetao Fang, Chengjian Feng, Yu Gao, Diandian Gu, Dong Guo, Hanzhong Guo, Qiushan Guo, Boyang Hao, Hon...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Le Shen, Qian Qiao, Tan Yu, Ke Zhou, Tian- hang Yu, Yu Zhan, Zhenjie Wang, Ming Tao, Shunshun Yin, and Siyuan Liu. 2026. SoulX- FlashTalk: Real-Time Infinite Streaming of Audio- Driven Avatars via Self-Correcting Bidirectional Dis- tillation. arXiv:2512.23379 [cs.CV]https: // arxiv.org/abs/2512.23379
-
[32]
SII-GAIR, Sand. ai, Ethan Chern, Hansi Teng, Han- wen Sun, Hao Wang, Hong Pan, Hongyu Jia, Jiadi Su, Jin Li, Junjie Yu, Lijie Liu, Lingzhi Li, Lyuman- shan Ye, Min Hu, Qiangang Wang, Quanwei Qi, Steffi Chern, Tao Bu, Taoran Wang, Teren Xu, Tianning Zhang, Tiantian Mi, Weixian Xu, Wenqiang Zhang, Wentai Zhang, Xianping Yi, Xiaojie Cai, Xiaoyang Kang, Yan M...
-
[33]
SII-OpenMOSS Team, Donghua Yu, Mingshu Chen, Qi Chen, Qi Luo, Qianyi Wu, Qinyuan Cheng, Ruix- iao Li, Tianyi Liang, Wenbo Zhang, Wenming Tu, Xiangyu Peng, Yang Gao, Yanru Huo, Ying Zhu, Yinze Luo, Yiyang Zhang, Yuerong Song, Zhe Xu, Zhiyu Zhang, Chenchen Yang, Cheng Chang, Chushu Zhou, Hanfu Chen, Hongnan Ma, Jiaxi Li, Jingqi Tong, Junxi Liu, Ke Chen, Shi...
work page internal anchor Pith review doi:10.48550/arxiv 2026
- [34]
-
[35]
Thomas Unterthiner, Sjoerd van Steenkiste, Karol Ku- rach, Rapha ¨el Marinier, Marcin Michalski, and Syl- vain Gelly. 2019. Towards Accurate Generative Mod- els of Video: A New Metric and Challenges. InIn- ternational Conference on Learning Representations (ICLR)
2019
-
[36]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need. InAdvances in Neural Information Pro- cessing Systems (NeurIPS), V ol. 30
2017
-
[37]
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chao- jie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haim- ing Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fan...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, Deqing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang Wu, Peng Wang, Shuting Yu, Tingkun...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
One-step diffusion with distribution matching distillation.arXiv preprint arXiv:2311.18828, 2023
Tianwei Yin, Micha ¨el Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T. Freeman, and Taesung Park. 2024. One- step Diffusion with Distribution Match- ing Distillation. arXiv:2311.18828 [cs.CV] https://arxiv.org/abs/2311.18828
-
[40]
Tan Yu, Qian Qiao, Le Shen, Ke Zhou, Jincheng Hu, Dian Sheng, Bo Hu, Haoming Qin, Jun Gao, Changhai Zhou, Shunshun Yin, and Siyuan Liu
-
[41]
arXiv:2602.07449 [cs.CV]https : / / arxiv
SoulX-FlashHead: Oracle-guided Genera- tion of Infinite Real-time Streaming Talking Heads. arXiv:2602.07449 [cs.CV]https : / / arxiv . org/abs/2602.07449
-
[42]
Ailing Zeng, Casper Yang, Chauncey Ge, Eddie Zhang, Garvey Xu, Gavin Lin, Gilbert Gu, Jeremy Pi, Leo Li, Mingyi Shi, Shawn Wang, Sheng Bi, Steven Tang, Thorn Hang, Tobey Guo, Vincent Li, Xin Tong, Yikang Li, Yuchen Sun, Yue Zhao, Yuhan Lu, Yuwei Li, Zane Zhang, Zeshi Yang, and Zi Ye. 2026. LPM 1.0: Video-based Character Perfor- mance Model. arXiv:2604.078...
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [43]
-
[44]
Dian Zheng, Ziqi Huang, Hongbo Liu, Kai Zou, Yinan He, Fan Zhang, Lulu Gu, Yuanhan Zhang, Jingwen He, Wei-Shi Zheng, Yu Qiao, and Ziwei Liu. 2025. VBench-2.0: Advancing Video Gen- eration Benchmark Suite for Intrinsic Faithfulness. arXiv:2503.21755 [cs.CV]https : / / arxiv . org/abs/2503.21755 Ours Ours w/o sink chunk SoulX-FlashTalk SoulX-FlashHead LiveA...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.