Linac: linear algebra with CUDA over finite fields
Pith reviewed 2026-06-29 19:27 UTC · model grok-4.3
The pith
Linac provides a CUDA-based parallel implementation of Gaussian elimination over finite fields for quantum field theory amplitude reconstruction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
With Linac, we present a high-performance, open-source, parallel implementation of Gaussian elimination over finite fields and floating-point arithmetic developed for applications to analytic reconstruction of scattering amplitudes in quantum field theory.
What carries the argument
Parallel Gaussian elimination executed on CUDA GPUs, using finite fields (integers modulo a prime) in place of floating-point numbers to maintain numerical stability.
If this is right
- Large linear systems from polynomial equations can be solved at higher throughput by moving the elimination step to GPUs.
- Finite-field arithmetic offers a precision-preserving alternative that scales without the rounding errors that appear in floating-point at large sizes.
- Analytic reconstruction workflows in quantum field theory gain a new open-source component for the linear-algebra stage.
- The same code base supports both finite-field and floating-point paths, allowing direct comparison within one framework.
Where Pith is reading between the lines
- The same GPU finite-field approach could be tested on linear systems from other domains that currently rely on high-precision floating-point arithmetic.
- Integration with existing amplitude generators would reveal whether the reported performance gain translates into end-to-end speedups for full calculations.
- Extensions to other elimination variants or preconditioners could be explored once the core CUDA kernels are public.
Load-bearing premise
The parallelism in Gaussian elimination maps efficiently onto GPU hardware and finite-field arithmetic preserves the necessary information for the polynomial systems that arise in scattering amplitude reconstruction.
What would settle it
A direct timing comparison on representative QFT-derived linear systems showing that the GPU version runs slower than a standard CPU implementation, or a case where finite-field results deviate from known floating-point answers in a physically relevant way.
Figures
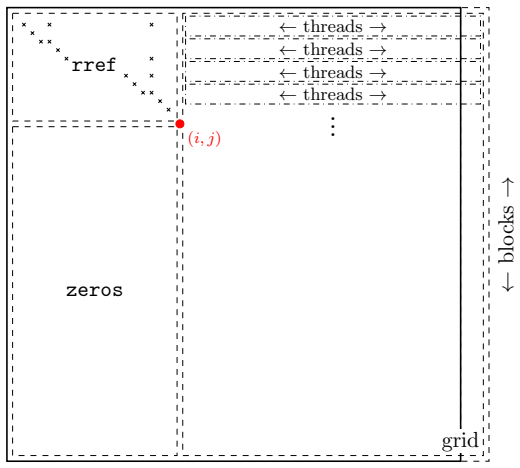
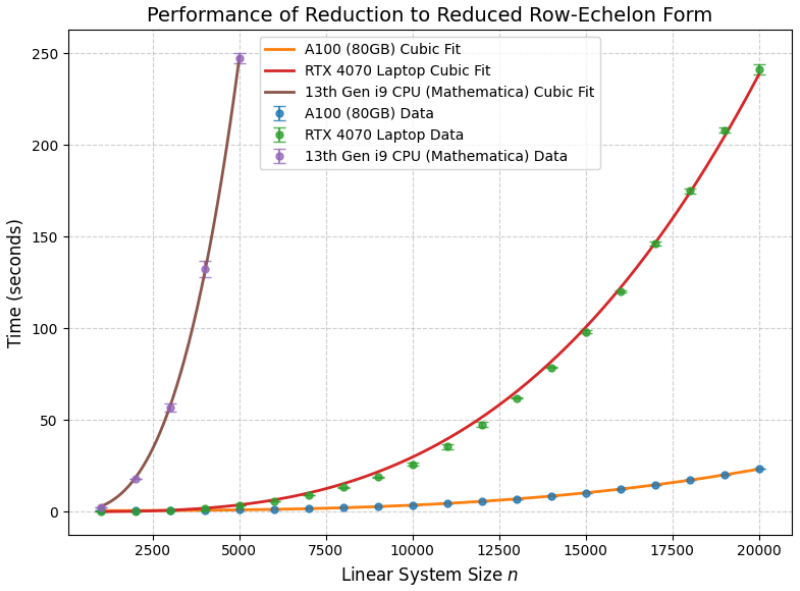
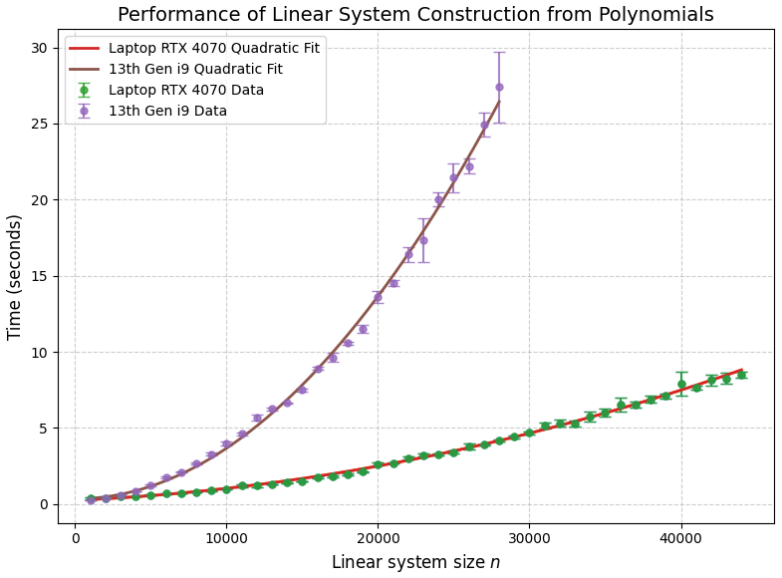
read the original abstract
Solving linear systems of polynomial equations is a ubiquitous problem in both mathematics and physics. The standard approach, Gaussian elimination, scales cubically with system size and often constitutes a computational bottleneck. The algorithm's inherent parallelism makes it well-suited for modern computing architectures, namely graphics processing units (GPUs), which offer significantly higher throughput than CPUs. Additionally, the use of finite fields -- integers modulo a prime -- in place of floating-point arithmetic offers a scalable solution to the issue of numerical precision loss, which becomes increasingly problematic at large system sizes. With Linac, we present a high-performance, open-source, parallel implementation of Gaussian elimination over finite fields and floating-point arithmetic. This tool has been developed for applications to analytic reconstruction of scattering amplitudes in quantum field theory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Linac, an open-source CUDA implementation of Gaussian elimination over finite fields and floating-point arithmetic. It targets the solution of linear systems of polynomial equations that arise in analytic reconstruction of scattering amplitudes in quantum field theory, claiming that GPU parallelism combined with finite-field arithmetic yields high performance while avoiding numerical precision loss.
Significance. If validated, a reliable GPU-accelerated finite-field linear algebra library could reduce a key computational bottleneck in QFT amplitude calculations. The approach of replacing floating-point with modular arithmetic to control precision is conceptually attractive for large sparse polynomial systems. However, the manuscript supplies no empirical evidence, so any significance assessment remains prospective rather than demonstrated.
major comments (2)
- [Abstract] Abstract: the central claims of 'high-performance' and a 'scalable solution to the issue of numerical precision loss' are asserted without any timing data, scaling curves, error analysis, or comparison against CPU baselines or existing packages (e.g., LinBox). This absence leaves the performance and accuracy assertions unverified.
- [Abstract] Abstract and application section: the claim that finite-field arithmetic provides an accuracy-preserving replacement for floating-point arithmetic is made for the specific sparse, high-degree polynomial matrices arising in QFT amplitude reconstruction, yet no tests on representative QFT-sized systems are reported. This is load-bearing for the stated use case.
Simulated Author's Rebuttal
We thank the referee for the careful review and for identifying the lack of empirical support for the performance and accuracy claims. We agree that these assertions require substantiation and will revise the manuscript to include the requested benchmarks, scaling studies, and application-specific tests.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of 'high-performance' and a 'scalable solution to the issue of numerical precision loss' are asserted without any timing data, scaling curves, error analysis, or comparison against CPU baselines or existing packages (e.g., LinBox). This absence leaves the performance and accuracy assertions unverified.
Authors: We agree that the current manuscript asserts these properties on the basis of the algorithmic design and CUDA implementation without providing supporting measurements. The revised version will incorporate timing data on representative hardware, strong- and weak-scaling curves, floating-point versus finite-field error analysis, and direct comparisons against CPU baselines and libraries such as LinBox. revision: yes
-
Referee: [Abstract] Abstract and application section: the claim that finite-field arithmetic provides an accuracy-preserving replacement for floating-point arithmetic is made for the specific sparse, high-degree polynomial matrices arising in QFT amplitude reconstruction, yet no tests on representative QFT-sized systems are reported. This is load-bearing for the stated use case.
Authors: The referee correctly notes that no tests on QFT-scale systems are presented. Although the library was developed with these matrices in mind, the manuscript does not demonstrate the claimed accuracy preservation or performance on systems of the relevant size and sparsity. We will add such benchmarks in the revision, using polynomial systems drawn from actual amplitude-reconstruction workflows. revision: yes
Circularity Check
No circularity: software implementation paper with no derivation chain
full rationale
The manuscript presents an open-source CUDA implementation of Gaussian elimination over finite fields and floats, developed for QFT amplitude reconstruction. No equations, predictions, fitted parameters, or first-principles derivations are claimed. The abstract and description focus on algorithmic parallelism and numerical advantages without reducing any result to self-definition, self-citation load-bearing premises, or renaming of known patterns. The reader's assessment of 0.0 is confirmed; the work is a software artifact whose performance claims would require external benchmarks rather than internal circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Albrecht et al., A Roadmap for HEP Software and Computing R&D for the 2020s
HEP Software Foundation Collaboration, J. Albrecht et al., A Roadmap for HEP Software and Computing R&D for the 2020s . Comput. Softw. Big Sci. 3 (2019) no. 1, 7, arXiv:1712.06982 [physics.comp-ph]
-
[2]
Amoroso et al., Challenges in Monte Carlo Event Generator Software for High-Luminosity LHC
HSF Physics Event Generator WG Collaboration, S. Amoroso et al., Challenges in Monte Carlo Event Generator Software for High-Luminosity LHC . Comput. Softw. Big Sci. 5 (2021) no. 1, 12, arXiv:2004.13687 [hep-ph]
-
[3]
Monte Carlo integration on GPU
J. Kanzaki, Monte Carlo integration on GPU . Eur. Phys. J. C 71 (2011) 1559, arXiv:1010.2107 [physics.comp-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2011
- [4]
-
[5]
M. H. Seymour and S. Sule, An NLO-Matched Initial and Final State Parton Shower on a GPU . arXiv:2511.19633 [hep-ph]
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
E. Bothmann, W. Giele, S. Hoeche, J. Isaacson, and M. Knobbe, Many-gluon tree amplitudes on modern GPUs: A case study for novel event generators . SciPost Phys. Codeb. 2022 (2022) 3, arXiv:2106.06507 [hep-ph]
- [7]
-
[8]
A. Valassi, New GPU developments in the Madgraph CUDACPP plugin: kernel splitting, helicity streams, cuBLAS color sums . arXiv:2510.05392 [physics.comp-ph]
- [9]
-
[10]
pySecDec: a toolbox for the numerical evaluation of multi-scale integrals
S. Borowka, G. Heinrich, S. Jahn, S. P. Jones, M. Kerner, J. Schlenk, and T. Zirke, pySecDec: A toolbox for the numerical evaluation of multi-scale integrals . Comput. Phys. Commun. 222 (2018) 313–326, arXiv:1703.09692 [hep-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
A GPU compatible quasi-Monte Carlo integrator interfaced to pySecDec
S. Borowka, G. Heinrich, S. Jahn, S. P. Jones, M. Kerner, and J. Schlenk, A GPU compatible quasi-Monte Carlo integrator interfaced to pySecDec . Comput. Phys. Commun. 240 (2019) 120–137, arXiv:1811.11720 [physics.comp-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[12]
G. Heinrich, S. Jahn, S. P. Jones, M. Kerner, F. Langer, V. Magerya, A. P¨ oldaru, J. Schlenk, and E. Villa, Expansion by regions with pySecDec . Comput. Phys. Commun. 273 (2022) 108267, arXiv:2108.10807 [hep-ph]
-
[13]
G. Heinrich, S. P. Jones, M. Kerner, V. Magerya, A. Olsson, and J. Schlenk, Numerical scattering amplitudes with pySecDec . Comput. Phys. Commun. 295 (2024) 108956, arXiv:2305.19768 [hep-ph] . 26
-
[14]
Feldman, New GPU-Accelerated Supercomputers Change the Balance of Power on the TOP500 , TOP500 News, 2018
M. Feldman, New GPU-Accelerated Supercomputers Change the Balance of Power on the TOP500 , TOP500 News, 2018. https://www.top500.org/news/new-gpu-accelerated-supercomputers-change- the-balance-of-power-on-the-top500/
2018
-
[15]
De Laurentis, Numerical techniques for analytical high-multiplicity scattering amplitudes
G. De Laurentis, Numerical techniques for analytical high-multiplicity scattering amplitudes. PhD thesis, Durham U., 2020
2020
-
[16]
A novel approach to integration by parts reduction
A. von Manteuffel and R. M. Schabinger, A novel approach to integration by parts reduction. Phys. Lett. B 744 (2015) 101–104, arXiv:1406.4513 [hep-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[17]
Scattering amplitudes over finite fields and multivariate functional reconstruction
T. Peraro, Scattering amplitudes over finite fields and multivariate functional reconstruction. JHEP 12 (2016) 030, arXiv:1608.01902 [hep-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2016
- [18]
-
[19]
Kira - A Feynman Integral Reduction Program
P. Maierh¨ ofer, J. Usovitsch, and P. Uwer,Kira—A Feynman integral reduction program. Comput. Phys. Commun. 230 (2018) 99–112, arXiv:1705.05610 [hep-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
Integral Reduction with Kira 2.0 and Finite Field Methods
J. Klappert, F. Lange, P. Maierh¨ ofer, and J. Usovitsch, Integral reduction with Kira 2.0 and finite field methods . Comput. Phys. Commun. 266 (2021) 108024, arXiv:2008.06494 [hep-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[21]
J. Klappert and F. Lange, Reconstructing rational functions with FireFly . Comput. Phys. Commun. 247 (2020) 106951, arXiv:1904.00009 [cs.SC]
-
[22]
J. Klappert, S. Y. Klein, and F. Lange, Interpolation of dense and sparse rational functions and other improvements in FireFly . Comput. Phys. Commun. 264 (2021) 107968, arXiv:2004.01463 [cs.MS]
-
[23]
FiniteFlow: multivariate functional reconstruction using finite fields and dataflow graphs
T. Peraro, FiniteFlow: multivariate functional reconstruction using finite fields and dataflow graphs. JHEP 07 (2019) 031, arXiv:1905.08019 [hep-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[24]
Magerya, Rational Tracer: a Tool for Faster Rational Function Reconstruction
V. Magerya, Rational Tracer: a Tool for Faster Rational Function Reconstruction . arXiv:2211.03572 [physics.data-an]
-
[25]
S. Abreu, J. Dormans, F. Febres Cordero, H. Ita, M. Kraus, B. Page, E. Pascual, M. S. Ruf, and V. Sotnikov, Caravel: A C++ framework for the computation of multi-loop amplitudes with numerical unitarity . Comput. Phys. Commun. 267 (2021) 108069, arXiv:2009.11957 [hep-ph]
-
[26]
Mangan, FiniteFieldSolve: Exactly solving large linear systems in high-energy theory
J. Mangan, FiniteFieldSolve: Exactly solving large linear systems in high-energy theory. Comput. Phys. Commun. 300 (2024) 109171, arXiv:2311.01671 [hep-th]
-
[27]
Hostetter, Galois: A performant NumPy extension for Galois fields , 11, 2020
M. Hostetter, Galois: A performant NumPy extension for Galois fields , 11, 2020. https://github.com/mhostetter/galois
2020
-
[28]
Lu-gpu: Efficient algorithms for solving dense linear systems on graphics hardware.,
N. Galoppo, N. Govindaraju, M. Henson, and D. Manocha, “Lu-gpu: Efficient algorithms for solving dense linear systems on graphics hardware.,” vol. 2005, p. 3. 01, 2005. 27
2005
-
[29]
G. De Laurentis and B. Page, Ans¨ atze for scattering amplitudes from p-adic numbers and algebraic geometry . JHEP 12 (2022) 140, arXiv:2203.04269 [hep-th]
- [30]
- [31]
-
[32]
M. Cederwall, J. Hutomo, S. M. Kuzenko, K. Lechner, and D. P. Sorokin, Some remarks on invariants . arXiv:2509.14350 [hep-th]
-
[33]
C. R. Harris, K. J. Millman, S. J. van der Walt, R. Gommers, P. Virtanen, D. Cournapeau, E. Wieser, J. Taylor, S. Berg, N. J. Smith, R. Kern, M. Picus, S. Hoyer, M. H. van Kerkwijk, M. Brett, A. Haldane, J. F. del R´ ıo, M. Wiebe, P. Peterson, P. G´ erard-Marchant, K. Sheppard, T. Reddy, W. Weckesser, H. Abbasi, C. Gohlke, and T. E. Oliphant, Array progra...
-
[34]
mpmath development team, mpmath: a Python library for arbitrary-precision floating-point arithmetic (version 1.4.0) , 2026
T. mpmath development team, mpmath: a Python library for arbitrary-precision floating-point arithmetic (version 1.4.0) , 2026. https://mpmath.org/
2026
-
[35]
G. D. Laurentis, GDeLaurentis/linac: v1.0.1, May, 2026. https://doi.org/10.5281/zenodo.20327732
-
[36]
G. D. Laurentis, GDeLaurentis/antares: v0.7.1, Mar., 2026. https://doi.org/10.5281/zenodo.18894183
-
[37]
NVIDIA Corporation & affiliates, CUDA C++ Programming Guide , https://docs.nvidia.com/cuda/cuda-c-programming-guide/index .html#
-
[38]
G. De Laurentis, H. Ita, M. Klinkert, and V. Sotnikov, Double-virtual NNLO QCD corrections for five-parton scattering. I. The gluon channel . Phys. Rev. D 109 (2024) no. 9, 094023, arXiv:2311.10086 [hep-ph]
-
[39]
G. De Laurentis, H. Ita, B. Page, and V. Sotnikov, Compact two-loop QCD corrections for Vjj production in proton collisions . JHEP 06 (2025) 093, arXiv:2503.10595 [hep-ph]
-
[40]
Two-loop leading-color QCD corrections for Higgs plus two-jet production in the heavy-top limit
G. De Laurentis, H. Ita, V. Kuschke, M. Ruf, and V. Sotnikov, Two-loop leading-color QCD corrections for Higgs plus two-jet production in the heavy-top limit. arXiv:2605.04009 [hep-ph]
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
G. D. Laurentis, GDeLaurentis/syngular: v0.6.0, Mar., 2026. https://doi.org/10.5281/zenodo.18881385
-
[42]
G. De Laurentis, H. Ita, and V. Sotnikov, Double-virtual NNLO QCD corrections for five-parton scattering. II. The quark channels . Phys. Rev. D 109 (2024) no. 9, 094024, arXiv:2311.18752 [hep-ph]
-
[43]
G. D. Laurentis, GDeLaurentis/lips: v0.6.1, May, 2026. https://doi.org/10.5281/zenodo.20041968. 28
-
[44]
G. D. Laurentis, GDeLaurentis/pyadic: v0.3.0, Mar., 2026. https://doi.org/10.5281/zenodo.18881428
-
[45]
Decker, G.-M
W. Decker, G.-M. Greuel, G. Pfister, and H. Sch¨ onemann, Singular 4-4-0 — A computer algebra system for polynomial computations , http://www.singular.uni-kl.de, 2024. 29
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.