When Self-Belief Misleads: Active Label Acquisition for Reinforcement Learning with Verifiable Rewards
Pith reviewed 2026-06-29 22:56 UTC · model grok-4.3
The pith
Active selection of ground-truth labels via Corrective Advantage Gap stabilizes RL training on pseudo-labels with small annotation budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
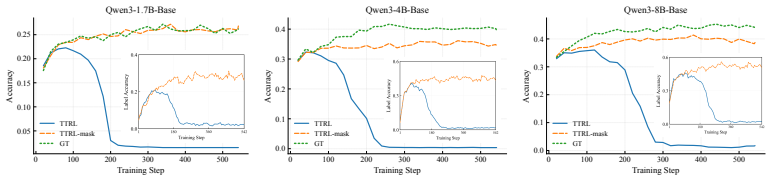
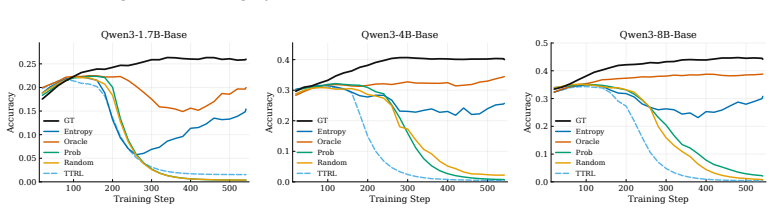
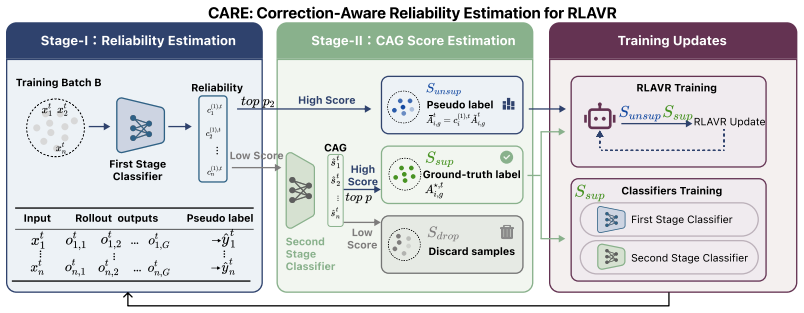
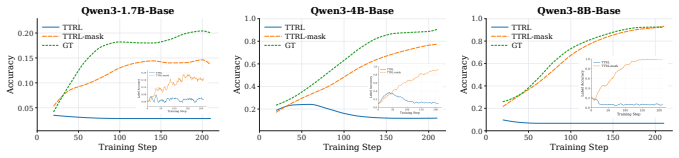
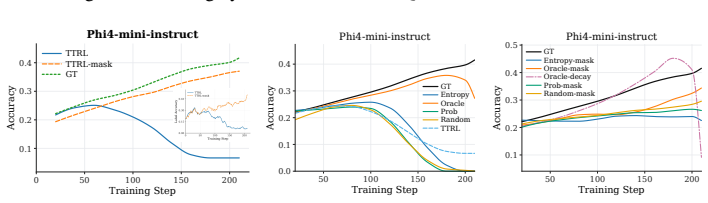
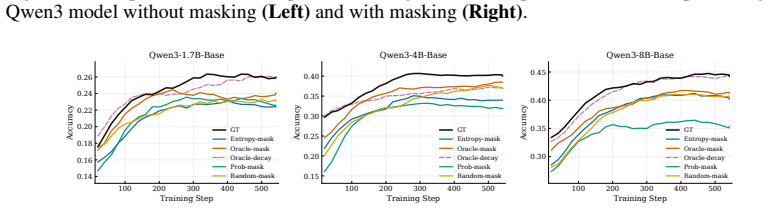
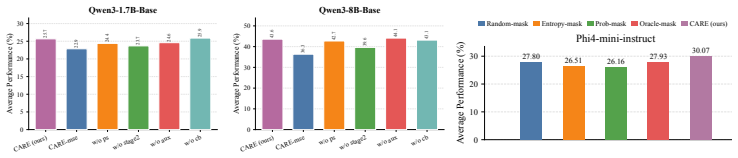
RLAVR actively acquires ground-truth labels for a small set of selected samples and integrates them with pseudo-labels, thereby stabilizing training dynamics and improving performance under limited annotation budgets. The Corrective Advantage Gap metric identifies samples whose labeling carries high supervision value, and CARE translates this oracle criterion into a usable pre-query acquisition policy.
What carries the argument
The Corrective Advantage Gap (CAG) metric, which quantifies sample-level supervision value to decide which examples merit ground-truth labels.
If this is right
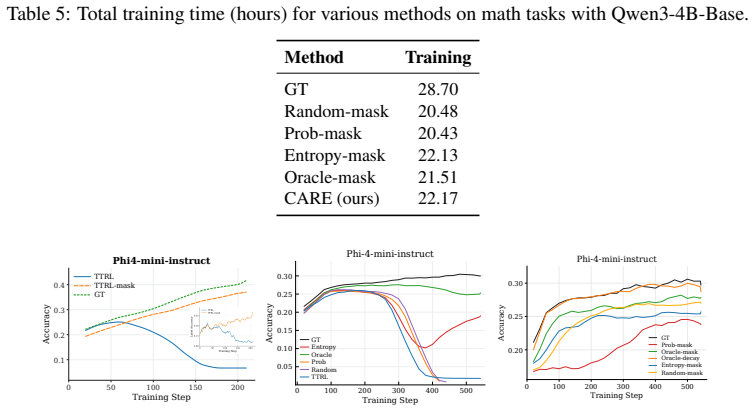
- Training remains stable rather than collapsing when a small fraction of pseudo-labels is replaced by CAG-selected ground-truth labels.
- Final task performance rises across model scales and domains when annotation budgets are constrained.
- CARE supplies a deployable policy that approximates the ideal CAG criterion without needing ground-truth information at query time.
Where Pith is reading between the lines
- The same selection logic could be tested in other reward-sparse RL settings where pseudo-labels are the default but costly verification is available for a few cases.
- One could measure whether CAG scores correlate with downstream annotation efficiency in new task families beyond those studied.
- Dynamic adjustment of the annotation budget based on running CAG estimates might further reduce total labeling cost while preserving gains.
Load-bearing premise
The Corrective Advantage Gap metric can identify samples whose labeling will meaningfully improve training stability and final performance.
What would settle it
An experiment in which random sample selection for ground-truth labels yields equal or better stability and performance than CAG-guided selection would show the metric adds no value.
Figures



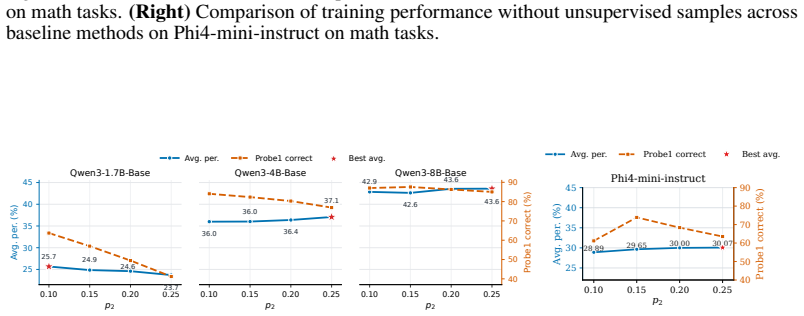
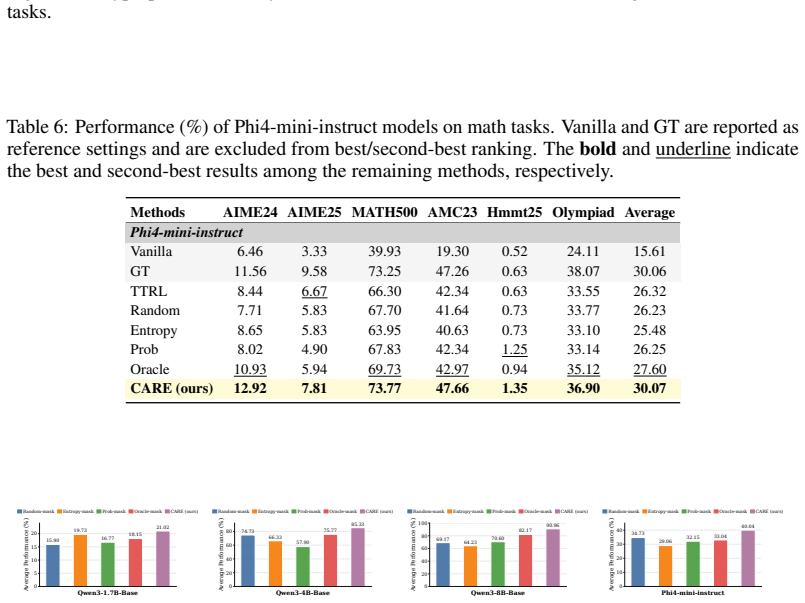

read the original abstract
Large Language Models (LLMs) have achieved remarkable advancements in reasoning capabilities empowered by Reinforcement Learning with Verifiable Rewards (RLVR). Nonetheless, RLVR intrinsically relies on ground-truth labels for reward computation, the acquisition of which is often prohibitively expensive in real-world scenarios. While unsupervised RLVR paradigms attempt to circumvent this by training on pseudo-labels, they are notoriously susceptible to training collapse. Moreover, different samples often exhibit varying annotation values. In this paper, we propose Reinforcement Learning with Active Verifiable Rewards (RLAVR), which actively acquires ground-truth labels for a small set of selected samples and integrates them with pseudo-labels, thereby stabilizing training dynamics and improving performance under limited annotation budgets. To identify valuable samples, we propose the Corrective Advantage Gap (CAG) metric and analyze the sample-level supervision value. Building on this, we introduce Correction-Aware Reliability Estimation for RLAVR (CARE), which translates the oracle CAG criterion into a practical pre-query acquisition policy to substantially improve training stability. Extensive experiments across diverse domains, model families, and model scales demonstrate the effectiveness and generality of our approach. Our code is available at https://github.com/Lumina04/CARE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RLAVR, an active-label-acquisition framework for Reinforcement Learning with Verifiable Rewards (RLVR). It introduces the Corrective Advantage Gap (CAG) metric to quantify the value of obtaining a ground-truth label for a given sample and the CARE policy to translate an oracle CAG into a practical pre-query selection rule that operates on model outputs alone. The selected ground-truth labels are then mixed with pseudo-labels to stabilize training and improve final performance under constrained annotation budgets. The central empirical claim is that this approach outperforms random or heuristic selection across multiple domains, model families, and scales.
Significance. If the central claim holds, the work supplies a concrete, budget-aware mechanism for mitigating the well-known collapse of unsupervised RLVR while keeping annotation costs low. The public release of code is a clear strength that supports reproducibility and follow-on work.
major comments (2)
- [Methods (CARE derivation and pre-query policy)] The mapping from the oracle CAG to the practical CARE policy is the load-bearing step for the central claim. Because CARE must approximate CAG without ground-truth rewards, any circular dependence on the same pseudo-labels used for policy training would invalidate the reported gains; the manuscript does not supply a derivation or ablation that isolates this approximation from the training signal.
- [Experiments (ablation and selection-quality analysis)] The title itself flags that self-belief can mislead, yet the experimental section does not report a controlled test (e.g., oracle-CAG vs. CARE-CAG selection on the same seed) that would demonstrate the approximation remains corrective rather than merely reinforcing existing model errors.
minor comments (2)
- [Abstract and §3] Notation for the CAG metric is introduced without an explicit equation reference in the abstract or early sections, making it difficult to trace how the metric is computed from advantage estimates.
- [Experiments] The claim of 'extensive experiments across diverse domains, model families, and model scales' would be strengthened by a table that enumerates the exact datasets, model sizes, and annotation budgets used.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below. Where the manuscript is missing requested elements, we commit to adding them in revision.
read point-by-point responses
-
Referee: [Methods (CARE derivation and pre-query policy)] The mapping from the oracle CAG to the practical CARE policy is the load-bearing step for the central claim. Because CARE must approximate CAG without ground-truth rewards, any circular dependence on the same pseudo-labels used for policy training would invalidate the reported gains; the manuscript does not supply a derivation or ablation that isolates this approximation from the training signal.
Authors: We agree that a clear isolation of the CARE approximation is essential. CARE is constructed exclusively from model outputs (token probabilities and response consistency) and does not ingest the pseudo-labels or reward signals used inside the RLVR training loop; the oracle CAG is defined as the expected advantage correction under a verified label, and CARE approximates the sign and magnitude of this gap via an entropy-based reliability score. Nevertheless, the current manuscript presents only a high-level description. We will add a dedicated appendix containing the full step-by-step derivation together with an ablation that replaces CARE with a variant that leaks training-signal information, thereby quantifying any circularity effect. revision: yes
-
Referee: [Experiments (ablation and selection-quality analysis)] The title itself flags that self-belief can mislead, yet the experimental section does not report a controlled test (e.g., oracle-CAG vs. CARE-CAG selection on the same seed) that would demonstrate the approximation remains corrective rather than merely reinforcing existing model errors.
Authors: A direct oracle-CAG versus CARE-CAG comparison on identical seeds would indeed be the cleanest demonstration. Because oracle CAG requires ground-truth labels for the entire candidate pool, a full-scale version is incompatible with the limited-budget regime studied in the paper. We will nevertheless add a controlled post-hoc analysis on a fully labeled subset of each benchmark: we compute both oracle and CARE rankings on the same seed, measure the overlap of selected samples, and report the downstream performance gap when the two policies are used for label acquisition. This will quantify how closely CARE tracks the corrective signal without reinforcing model errors. revision: yes
Circularity Check
No significant circularity; derivation relies on external experiments
full rationale
The provided abstract and description introduce CAG as a metric and CARE as a translation of an oracle criterion into a policy, but contain no equations, no fitted parameters renamed as predictions, and no self-citation chains that reduce the central claim to its own inputs by construction. Experiments across domains, models, and scales are presented as validation, making the work self-contained against external benchmarks. No load-bearing self-definitional or fitted-input steps are quotable from the text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pseudo-labels generated by the model can be productively combined with a small number of ground-truth labels without causing training collapse
invented entities (2)
-
Corrective Advantage Gap (CAG)
no independent evidence
-
CARE acquisition policy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J Hewett, Mojan Javaheripi, Piero Kauffmann, et al. Phi-4 technical report.arXiv preprint arXiv:2412.08905, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
The Unreasonable Effectiveness of Entropy Minimization in LLM Reasoning
Shivam Agarwal, Zimin Zhang, Lifan Yuan, Jiawei Han, and Hao Peng. The unreasonable effectiveness of entropy minimization in llm reasoning.arXiv preprint arXiv:2505.15134, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Active learning: A survey
Charu C Aggarwal, Xiangnan Kong, Quanquan Gu, Jiawei Han, and Philip S Yu. Active learning: A survey. InData classification, pages 599–634. Chapman and Hall/CRC, 2014
2014
-
[4]
The internal state of an llm knows when it’s lying
Amos Azaria and Tom Mitchell. The internal state of an llm knows when it’s lying. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 967–976, 2023
2023
-
[5]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Activellm: Large language model-based active learning for textual few-shot scenarios.Transactions of the Association for Computational Linguistics, 14:1–22, 2026
Markus Bayer, Justin Lutz, and Christian Reuter. Activellm: Large language model-based active learning for textual few-shot scenarios.Transactions of the Association for Computational Linguistics, 14:1–22, 2026
2026
-
[7]
Maximizing expected model change for active learning in regression
Wenbin Cai, Ya Zhang, and Jun Zhou. Maximizing expected model change for active learning in regression. In2013 IEEE 13th international conference on data mining, pages 51–60. IEEE, 2013
2013
-
[8]
Yang Chen, Zhuolin Yang, Zihan Liu, Chankyu Lee, Peng Xu, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. Acereason-nemotron: Advancing math and code reasoning through reinforcement learning.arXiv preprint arXiv:2505.16400, 2025
-
[9]
Efficient process reward model training via active learning.arXiv preprint arXiv:2504.10559, 2025
Keyu Duan, Zichen Liu, Xin Mao, Tianyu Pang, Changyu Chen, Qiguang Chen, Michael Qizhe Shieh, and Longxu Dou. Efficient process reward model training via active learning.arXiv preprint arXiv:2504.10559, 2025. 10
-
[10]
Duo: Diverse, uncertain, on-policy query generation and selection for reinforcement learning from human feedback
Xuening Feng, Zhaohui Jiang, Timo Kaufmann, Puchen Xu, Eyke Hüllermeier, Paul Weng, and Yifei Zhu. Duo: Diverse, uncertain, on-policy query generation and selection for reinforcement learning from human feedback. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 16604–16612, 2025
2025
-
[11]
Deep Active Learning over the Long Tail
Yonatan Geifman and Ran El-Yaniv. Deep active learning over the long tail.arXiv preprint arXiv:1711.00941, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
Mukesh Ghimire, Aosong Feng, Liwen You, Youzhi Luo, Fang Liu, and Xuan Zhu. Prism: A unified framework for post-training llms without verifiable rewards.arXiv preprint arXiv:2601.04700, 2026
-
[13]
rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking
Xinyu Guan, Li Lyna Zhang, Yifei Liu, Ning Shang, Youran Sun, Yi Zhu, Fan Yang, and Mao Yang. Rstar-math: Small llms can master math reasoning with self-evolved deep thinking.arXiv preprint arXiv:2501.04519, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
How far can unsupervised rlvr scale llm training? arXiv preprint arXiv:2603.08660, 2026
Bingxiang He, Yuxin Zuo, Zeyuan Liu, Shangziqi Zhao, Zixuan Fu, Junlin Yang, Cheng Qian, Kaiyan Zhang, Yuchen Fan, Ganqu Cui, et al. How far can unsupervised rlvr scale llm training? arXiv preprint arXiv:2603.08660, 2026
-
[16]
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Paper...
2024
-
[17]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[18]
Reinforcement learning from human feedback with active queries.arXiv preprint arXiv:2402.09401, 2024
Kaixuan Ji, Jiafan He, and Quanquan Gu. Reinforcement learning from human feedback with active queries.arXiv preprint arXiv:2402.09401, 2024
-
[19]
Query-by-committee improvement with diversity and density in batch active learning.Information Sciences, 454:401–418, 2018
Seho Kee, Enrique Del Castillo, and George Runger. Query-by-committee improvement with diversity and density in batch active learning.Information Sciences, 454:401–418, 2018
2018
-
[20]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
2023
-
[21]
Tool verification for test-time reinforcement learning.arXiv preprint arXiv:2603.02203, 2026
Ruotong Liao, Nikolai Röhrich, Xiaohan Wang, Yuhui Zhang, Yasaman Samadzadeh, V olker Tresp, and Serena Yeung-Levy. Tool verification for test-time reinforcement learning.arXiv preprint arXiv:2603.02203, 2026
-
[22]
Zihan Lin, Xiaohan Wang, Jie Cao, Jiajun Chai, Guojun Yin, Wei Lin, and Ran He. Rest: Reshaping token-level policy gradients for tool-use large language models.arXiv preprint arXiv:2509.21826, 2025
-
[23]
Zihan Lin, Xiaohan Wang, Hexiong Yang, Jiajun Chai, Jie Cao, Guojun Yin, Wei Lin, and Ran He. Awpo: Enhancing tool-use of large language models through adaptive integration of reasoning rewards.arXiv preprint arXiv:2512.19126, 2025
-
[24]
Dual active learning for reinforcement learning from human feedback.arXiv preprint arXiv:2410.02504,
Pangpang Liu, Chengchun Shi, and Will Wei Sun. Dual active learning for reinforcement learning from human feedback.arXiv preprint arXiv:2410.02504, 2024
-
[25]
Contextual Rollout Bandits for Reinforcement Learning with Verifiable Rewards
Xiaodong Lu, Xiaohan Wang, Jiajun Chai, Guojun Yin, Wei Lin, Zhijun Chen, Yu Luo, Fuzhen Zhuang, Yikun Ban, and Deqing Wang. Contextual rollout bandits for reinforcement learning with verifiable rewards.arXiv preprint arXiv:2602.08499, 2026. 11
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
MemReward: Graph-Based Experience Memory for LLM Reward Prediction with Limited Labels
Tianyang Luo, Tao Feng, Zhigang Hua, Yan Xie, Shuang Yang, Ge Liu, and Jiaxuan You. Memreward: Graph-based experience memory for llm reward prediction with limited labels. arXiv preprint arXiv:2603.19310, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models
Potsawee Manakul, Adian Liusie, and Mark Gales. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 9004–9017, 2023
2023
-
[28]
Sample efficient reinforcement learning from human feedback via active exploration
Viraj Mehta, Vikramjeet Das, Ojash Neopane, Yijia Dai, Ilija Bogunovic, Jeff Schneider, and Willie Neiswanger. Sample efficient reinforcement learning from human feedback via active exploration. 2023
2023
-
[29]
Active learning with expected error reduction.arXiv preprint arXiv:2211.09283, 2022
Stephen Mussmann, Julia Reisler, Daniel Tsai, Ehsan Mousavi, Shayne O’Brien, and Moises Goldszmidt. Active learning with expected error reduction.arXiv preprint arXiv:2211.09283, 2022
-
[30]
Teng Pan, Yuchen Yan, Zixuan Wang, Ruiqing Zhang, Gaiyang Han, Wanqi Zhang, Weiming Lu, Jun Xiao, and Yongliang Shen. Coverrl: Breaking the consensus trap in label-free reasoning via generator-verifier co-evolution.arXiv preprint arXiv:2603.17775, 2026
-
[31]
Maximizing confidence alone improves reasoning.arXiv preprint arXiv:2505.22660, 2025
Mihir Prabhudesai, Lili Chen, Alex Ippoliti, Katerina Fragkiadaki, Hao Liu, and Deepak Pathak. Maximizing confidence alone improves reasoning.arXiv preprint arXiv:2505.22660, 2025
-
[32]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[33]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Jinyan Su, Jennifer Healey, Preslav Nakov, and Claire Cardie. Between underthinking and overthinking: An empirical study of reasoning length and correctness in llms.arXiv preprint arXiv:2505.00127, 2025
-
[36]
Chuyi Tan, Peiwen Yuan, Xinglin Wang, Yiwei Li, Shaoxiong Feng, Yueqi Zhang, Jiayi Shi, Ji Zhang, Boyuan Pan, Yao Hu, et al. Diagnosing and mitigating system bias in self-rewarding rl.arXiv preprint arXiv:2510.08977, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
A new active labeling method for deep learning
Dan Wang and Yi Shang. A new active labeling method for deep learning. In2014 International joint conference on neural networks (IJCNN), pages 112–119. IEEE, 2014
2014
-
[38]
A survey on large language models for mathematical reasoning.ACM Computing Surveys, 58(8):1–35, 2026
Peng-Yuan Wang, Tian-Shuo Liu, Chenyang Wang, Ziniu Li, Yidi Wang, Shu Yan, Chengxing Jia, Xu-Hui Liu, Xinwei Chen, Jiacheng Xu, et al. A survey on large language models for mathematical reasoning.ACM Computing Surveys, 58(8):1–35, 2026
2026
-
[39]
Density weighted diversity based query strategy for active learning
Tingting Wang, Xufeng Zhao, Qiujian Lv, Bo Hu, and Degang Sun. Density weighted diversity based query strategy for active learning. In2021 IEEE 24th International Conference on Computer Supported Cooperative Work in Design (CSCWD), pages 156–161. IEEE, 2021
2021
-
[40]
Weiqin Wang, Yile Wang, Kehao Chen, and Hui Huang. Beyond majority voting: Towards fine-grained and more reliable reward signal for test-time reinforcement learning.arXiv preprint arXiv:2512.15146, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
On memorization of large language models in logical reasoning
Chulin Xie, Yangsibo Huang, Chiyuan Zhang, Da Yu, Xinyun Chen, Bill Yuchen Lin, Bo Li, Badih Ghazi, and Ravi Kumar. On memorization of large language models in logical reasoning. InProceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Li...
2025
-
[42]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Code to think, think to code: A survey on code-enhanced reasoning and reasoning-driven code intelligence in llms
Dayu Yang, Tianyang Liu, Daoan Zhang, Antoine Simoulin, Xiaoyi Liu, Yuwei Cao, Zhaopu Teng, Xin Qian, Grey Yang, Jiebo Luo, et al. Code to think, think to code: A survey on code-enhanced reasoning and reasoning-driven code intelligence in llms. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 2586–2616, 2025
2025
-
[44]
Shenzhi Yang, Guangcheng Zhu, Xing Zheng, Yingfan MA, Zhongqi Chen, Bowen Song, Weiqiang Wang, Junbo Zhao, Gang Chen, and Haobo Wang. Trapo: A semi-supervised reinforcement learning framework for boosting llm reasoning.arXiv preprint arXiv:2512.13106, 2025
-
[45]
Hao Yi, Yulan Hu, Xin Li, Sheng Ouyang, Lizhong Ding, and Yong Liu. Learn more with less: Uncertainty consistency guided query selection for rlvr.arXiv preprint arXiv:2601.22595, 2026
-
[46]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Zhaoning Yu, Will Su, Leitian Tao, Haozhu Wang, Aashu Singh, Hanchao Yu, Jianyu Wang, Hongyang Gao, Weizhe Yuan, Jason Weston, et al. Restrain: From spurious votes to signals– self-driven rl with self-penalization.arXiv preprint arXiv:2510.02172, 2025
-
[48]
Anqi Zhang, Yulin Chen, Jane Pan, Chen Zhao, Aurojit Panda, Jinyang Li, and He He. Reasoning models know when they’re right: Probing hidden states for self-verification.arXiv preprint arXiv:2504.05419, 2025
-
[49]
Kongcheng Zhang, Qi Yao, Shunyu Liu, Yingjie Wang, Baisheng Lai, Jieping Ye, Mingli Song, and Dacheng Tao. Consistent paths lead to truth: Self-rewarding reinforcement learning for llm reasoning.arXiv preprint arXiv:2506.08745, 2025
-
[50]
Qingyang Zhang, Haitao Wu, Changqing Zhang, Peilin Zhao, and Yatao Bian. Right question is already half the answer: Fully unsupervised llm reasoning incentivization.arXiv preprint arXiv:2504.05812, 2025
-
[51]
Zizhuo Zhang, Jianing Zhu, Xinmu Ge, Zihua Zhao, Zhanke Zhou, Xuan Li, Xiao Feng, Jiangchao Yao, and Bo Han. Co-rewarding: Stable self-supervised rl for eliciting reasoning in large language models.arXiv preprint arXiv:2508.00410, 2025
-
[52]
Learning to Reason without External Rewards
Xuandong Zhao, Zhewei Kang, Aosong Feng, Sergey Levine, and Dawn Song. Learning to reason without external rewards.arXiv preprint arXiv:2505.19590, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Yujun Zhou, Zhenwen Liang, Haolin Liu, Wenhao Yu, Kishan Panaganti, Linfeng Song, Dian Yu, Xiangliang Zhang, Haitao Mi, and Dong Yu. Evolving language models without labels: Majority drives selection, novelty promotes variation.arXiv preprint arXiv:2509.15194, 2025
-
[54]
TTRL: Test-Time Reinforcement Learning
Yuxin Zuo, Kaiyan Zhang, Li Sheng, Shang Qu, Ganqu Cui, Xuekai Zhu, Haozhan Li, Yuchen Zhang, Xinwei Long, Ermo Hua, et al. Ttrl: Test-time reinforcement learning.arXiv preprint arXiv:2504.16084, 2025. 13 A Proofs A.1 Proof Lemma 6.1 Proof. Under the strict on-policy setting, the gradients induced by the ground-truth and pseudo- reward advantages can be w...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
20 ' \ " ,(9 . 5 , 11),N) ; \ndraw((10 . 5 , 9)--(11 , 9)) ; \ndraw((10 . 5 , 10)--(11 , 10)) ; \ndraw((10 . 7 5 , 9)-- (10 . 7 5 , 10)) ; \nlabel(\
**Scoring**: Pr o vide a scor e based on t he crit eria. The scor e should be a decimal fr om { 0 . 0 , 0 .2, 0 .4 , 0 . 6 , 0 . 8 , 1 . 0 } . 3 . **Strict Output R equir ement**: * **ONL Y** output t he scor e inside t he \ \bo x{} f ormat ( e.g., \ \bo x{0 . 8}). * **DO NO T** pr o vide an y r easoning, j ustification, or pr eamble. * **DO NO T** includ...
-
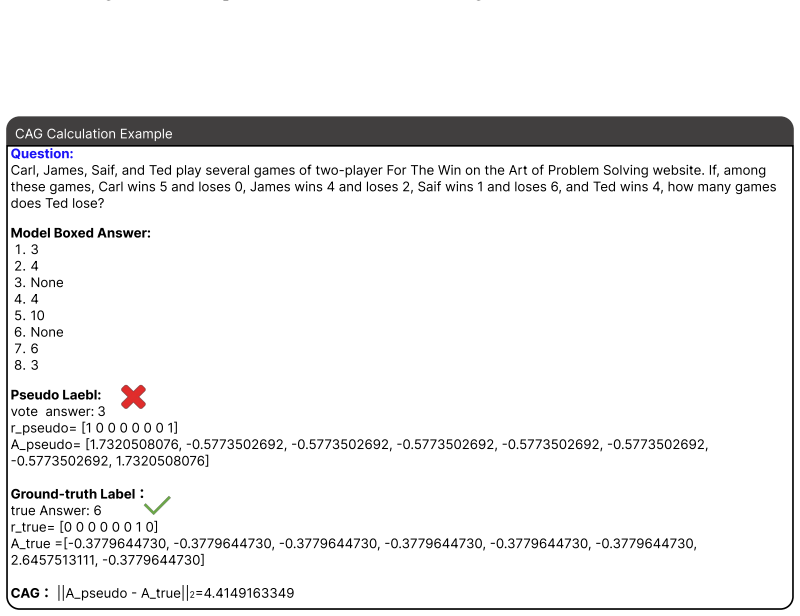
[56]
37 7 96447 30] C A G: ||A_ pseudo - A_true|| 2 =4 .4 149163349 Figure 15: CAG calculation example
6457 513111 , -0 . 37 7 96447 30] C A G: ||A_ pseudo - A_true|| 2 =4 .4 149163349 Figure 15: CAG calculation example. 24
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.