SetupX: Can LLM Agents Learn from Past Failures in Functionality-Correct Code Repository Setup?
Pith reviewed 2026-06-29 20:42 UTC · model grok-4.3
The pith
SetupX lets LLM agents transfer setup fixes across repositories using experience units, safe rollbacks, and separated verification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
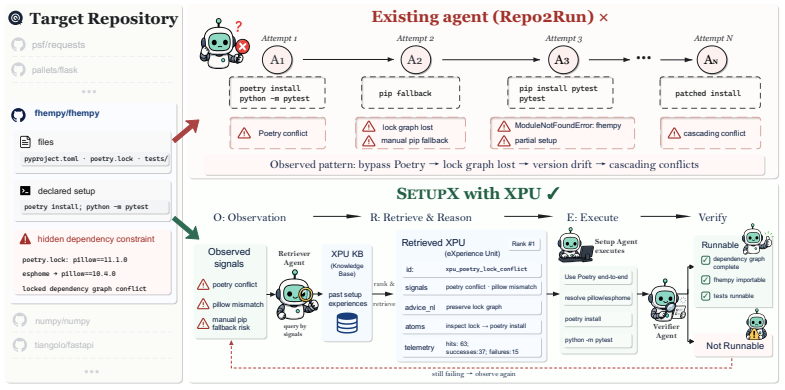
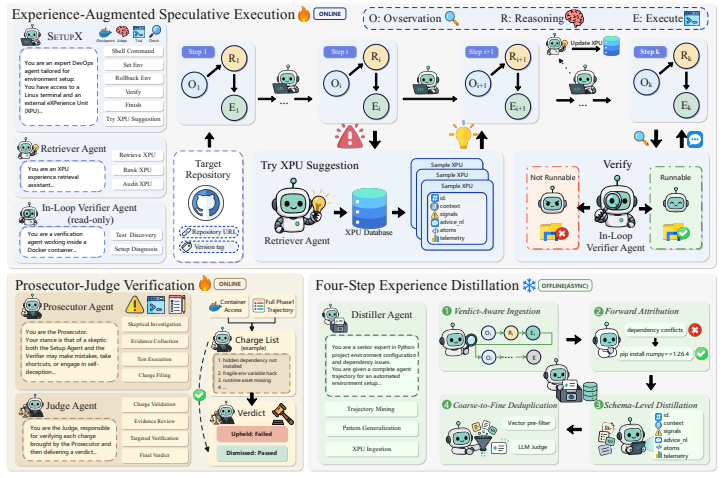
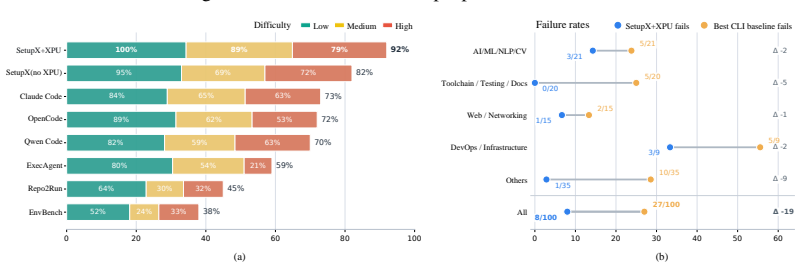
SetupX is an experiential learning framework whose three components are the Self-Evolving Experience Representation (XPU) that stores and transfers setup signals, guidance, and actions; Experience-Augmented Speculative Execution that uses a LIFO Docker snapshot stack for safe trial-and-repair; and the Prosecutor-Judge Verification Protocol that separates evidence gathering from judgment. On carefully-crafted benchmarks the system records a 92 percent pass rate and exceeds the strongest baseline by more than 19 percent, with the largest gains appearing in multi-repository tasks that require coordinating interconnected services across containers.
What carries the argument
Self-Evolving Experience Representation (XPU), a dual-modality knowledge unit that encodes setup signals, textual guidance, and executable actions to transfer verified environment fixes to unseen repositories.
If this is right
- Verified fixes from one repository can be applied directly to new repositories without starting from scratch.
- Non-invertible state changes during setup can be explored safely because any trial can be rolled back to a prior known-good snapshot.
- Setup outcomes can be judged more reliably because evidence collection is kept separate from the final decision.
- Complex setups that coordinate multiple interconnected services across containers become feasible at scale.
Where Pith is reading between the lines
- The same transfer-and-rollback pattern could be reused for other agent tasks that involve persistent external state, such as database migration or cloud resource configuration.
- A growing collection of XPU units might eventually serve as shared community knowledge rather than remaining private to each agent run.
- Pairing SetupX with code-generation agents would create a pipeline that both writes and deploys working software without manual environment work.
Load-bearing premise
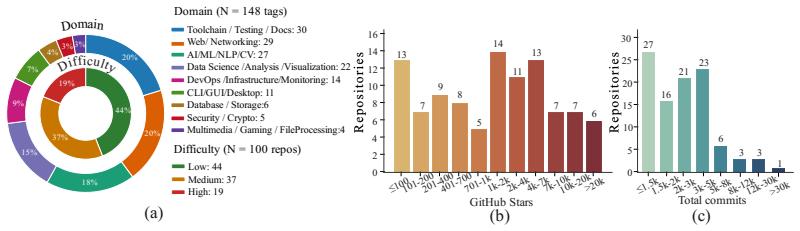
The carefully-crafted benchmarks represent the distribution of real-world repository setup failures and the Prosecutor-Judge protocol produces judgments that generalize beyond the test cases.
What would settle it
Run SetupX on a fresh collection of repositories drawn independently from the original benchmarks and measure whether the pass rate remains above 80 percent across multi-container and single-container tasks.
Figures
read the original abstract
Functionality-correct repository setup aims to configure execution environments (e.g., dependencies, build scripts) to successfully execute a repository's documented features. It presents significant challenges due to diverse, repository-specific failures, including dependency incompatibilities, missing toolchains, incomplete installations, and verification-strategy mismatches. Existing LLM agents struggle to robustly resolve these issues, specifically failing to support (1) cross-repository experience transfer, (2) multi-step trial-and-repair under non-invertible state changes, and (3) robust verification of setup outcomes to distinguish setup-induced failures from repository bugs. To address this, we introduce SetupX, an experiential learning-based setup framework. First, we construct a Self-Evolving Experience Representation (XPU), a dual-modality knowledge unit encoding setup signals, textual guidance, executable actions to dynamically transfer verified environment fixes to unseen repositories. Second, we employ Experience-Augmented Speculative Execution backed by a LIFO Docker snapshot stack, enabling the agent to proactively trial fixes and safely roll back to known-good states. Third, we introduce a Prosecutor-Judge Verification Protocol that separates evidence collection from final judgment, enabling more reliable setup verification beyond superficial build-time metrics. Evaluation results on carefully-crafted benchmarks show SetupX achieves highest performance (e.g., 92% pass rate) and outperforms the strongest baseline by over 19%. Crucially, SetupX excels in complex multi-repository setup requiring coordinating multiple interconnected services across different containers. The code repository is available at https://github.com/OpenDataBox/SetupX.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SetupX, an experiential learning framework for LLM agents performing functionality-correct repository setup. It defines three components: a Self-Evolving Experience Representation (XPU) that encodes setup signals, guidance, and actions for cross-repository transfer; Experience-Augmented Speculative Execution using a LIFO Docker snapshot stack for safe trial-and-repair under non-invertible changes; and a Prosecutor-Judge Verification Protocol that separates evidence collection from judgment. The central claim is that SetupX attains a 92% pass rate on carefully-crafted benchmarks, outperforming the strongest baseline by more than 19%, with particular advantage on complex multi-repository setups that coordinate services across containers. The code is released at https://github.com/OpenDataBox/SetupX.
Significance. If the performance numbers are supported by transparent benchmark construction, statistical controls, and representative failure distributions, the work would offer a concrete advance in LLM-agent reliability for software-engineering tasks by showing how retrieved experience and reversible execution can mitigate common setup failures. The public code release is a clear strength that supports reproducibility and extension. The current absence of those experimental details, however, prevents any assessment of whether the result generalizes beyond the reported test cases.
major comments (2)
- [Abstract] Abstract (evaluation paragraph): the headline claim of a 92% pass rate and >19% improvement supplies no information on the number of repositories, the selection or generation process for the 'carefully-crafted benchmarks,' the distribution of failure modes (dependency incompatibilities, non-invertible state changes, verification mismatches), statistical significance, or controls for prompt sensitivity; these omissions are load-bearing for interpreting whether the result supports the stated advantages over baselines.
- [Prosecutor-Judge Verification Protocol section] Section describing the Prosecutor-Judge Verification Protocol: the protocol is presented only at a high level with no accompanying ablation, false-positive analysis, or comparison against standard build-time metrics that would demonstrate its ability to distinguish setup-induced failures from repository bugs; without such evidence the reliability of the 92% figure cannot be assessed.
minor comments (2)
- [Abstract] The term 'carefully-crafted benchmarks' is used without a definition or concrete examples of how multi-repository cases were constructed.
- [Abstract] The abstract states that SetupX 'excels in complex multi-repository setup' but does not quantify this advantage with separate metrics or a dedicated table row.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency in our evaluation reporting and verification protocol. We address each major comment below and commit to revisions that improve clarity without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract (evaluation paragraph): the headline claim of a 92% pass rate and >19% improvement supplies no information on the number of repositories, the selection or generation process for the 'carefully-crafted benchmarks,' the distribution of failure modes (dependency incompatibilities, non-invertible state changes, verification mismatches), statistical significance, or controls for prompt sensitivity; these omissions are load-bearing for interpreting whether the result supports the stated advantages over baselines.
Authors: We agree that the abstract evaluation paragraph would benefit from additional context to help readers assess the headline claims. The manuscript body (Section 4) already details the benchmark construction, repository count, failure mode distributions, and controls for variance including multiple runs. In the revision we will expand the abstract's evaluation paragraph to concisely report the number of repositories, summarize the benchmark selection/generation process, note the primary failure mode distribution, and indicate that results incorporate statistical controls and averaging over runs to address prompt sensitivity. revision: yes
-
Referee: [Prosecutor-Judge Verification Protocol section] Section describing the Prosecutor-Judge Verification Protocol: the protocol is presented only at a high level with no accompanying ablation, false-positive analysis, or comparison against standard build-time metrics that would demonstrate its ability to distinguish setup-induced failures from repository bugs; without such evidence the reliability of the 92% figure cannot be assessed.
Authors: We acknowledge that the current presentation of the Prosecutor-Judge Verification Protocol remains largely descriptive. While the protocol's design rationale is explained in the section, we agree that supporting empirical evidence would strengthen the claim. In the revised manuscript we will add an ablation comparing the full protocol against standard build-time metrics, report false-positive rates observed in our experiments, and include concrete examples illustrating how the separation of evidence collection and judgment helps distinguish setup failures from repository bugs. revision: yes
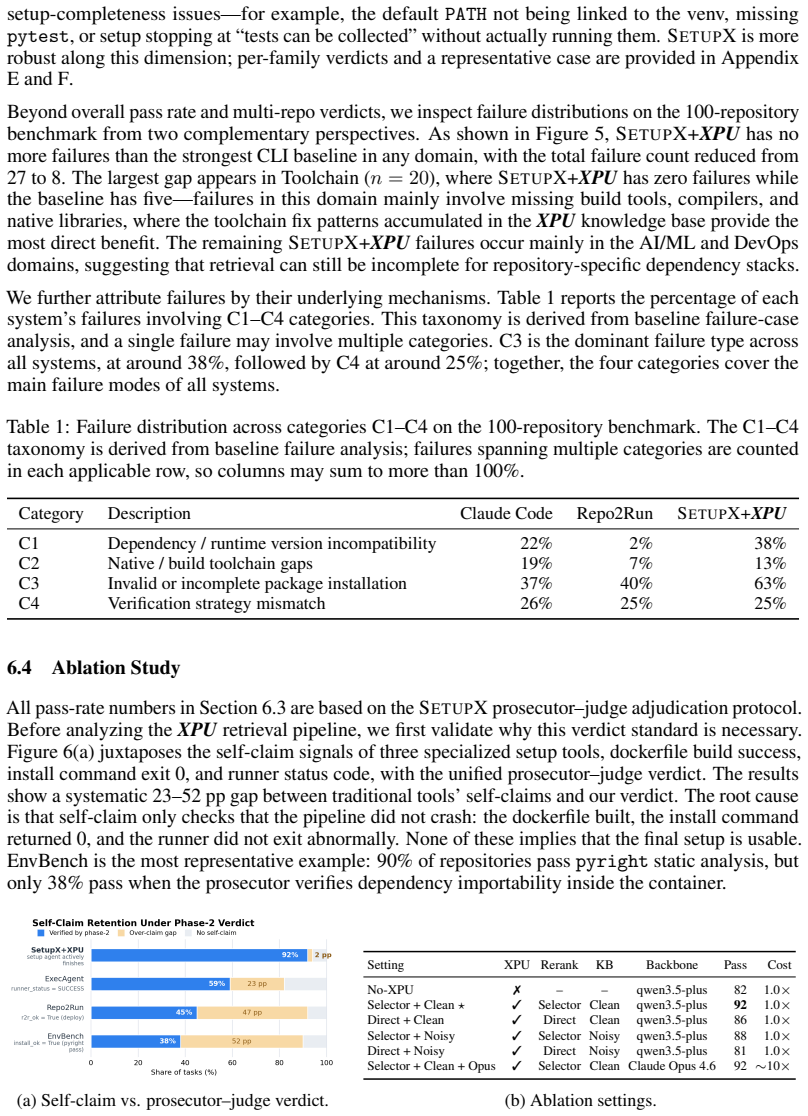
Circularity Check
No circularity: empirical measurements on held-out benchmarks
full rationale
The paper introduces SetupX components (XPU representation, LIFO snapshots, Prosecutor-Judge protocol) and reports measured pass rates (92%) on external benchmarks. No equations, fitted parameters, or self-citations are present in the provided text that reduce any claimed result to its inputs by construction. Performance figures are direct empirical observations rather than predictions derived from the framework itself. This matches the default case of a self-contained empirical systems paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- experience retrieval threshold or similarity metric
axioms (1)
- domain assumption Docker container snapshots can be created and restored without side effects on the host system
invented entities (2)
-
XPU (Self-Evolving Experience Representation)
no independent evidence
-
Prosecutor-Judge Verification Protocol
no independent evidence
Reference graph
Works this paper leans on
-
[1]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
S. Hong, M. Zhuge, J. Chen, X. Zheng, Y . Cheng, C. Zhang, J. Wang, Z. Wang, S. K. S. Yau, Z. Lin, L. Zhou, C. Ran, L. Xiao, C. Wu, and J. Schmidhuber, “Metagpt: Meta programming for a multi-agent collaborative framework,” 2024. [Online]. Available: https://arxiv.org/abs/2308.00352
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Swe-agent: Agent-computer interfaces enable automated software engineering,
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “Swe-agent: Agent-computer interfaces enable automated software engineering,” inAdvances in Neural Information Processing Systems 37: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024, A. Globersons,...
2024
-
[3]
Swe-bench: Can language models resolve real-world github issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. R. Narasimhan, “Swe-bench: Can language models resolve real-world github issues?” inThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. [Online]. Available: https://openreview.net/forum?id=VTF8yNQM66
2024
-
[4]
Deveval: A manually-annotated code generation benchmark aligned with real-world code repositories,
J. Li, G. Li, Y . Zhao, Y . Li, H. Liu, H. Zhu, L. Wang, K. Liu, Z. Fang, L. Wang, J. Ding, X. Zhang, Y . Zhu, Y . Dong, Z. Jin, B. Li, F. Huang, and Y . Li, “Deveval: A manually-annotated code generation benchmark aligned with real-world code repositories,” 2024. [Online]. Available: https://arxiv.org/abs/2405.19856
-
[5]
Claude code,
Anthropic, “Claude code,” https://claude.com/product/claude-code, 2025, accessed: 2025-05- 22
2025
-
[6]
Openhands: An open platform for AI software developers as generalist agents,
X. Wang, B. Li, Y . Song, F. F. Xu, X. Tang, M. Zhuge, J. Pan, Y . Song, B. Li, J. Singh, H. H. Tran, F. Li, R. Ma, M. Zheng, B. Qian, Y . Shao, N. Muennighoff, Y . Zhang, B. Hui, J. Lin, and et al., “Openhands: An open platform for AI software developers as generalist agents,” inThe Thirteenth International Conference on Learning Representations, ICLR 20...
2025
-
[7]
Repo2run: Automated building executable environment for code repository at scale,
R. Hu, C. Peng, XinchenWang, J. Xu, and C. Gao, “Repo2run: Automated building executable environment for code repository at scale,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. [Online]. Available: https://openreview.net/forum?id=fZsd3KLMje
2025
-
[8]
You name it, I run it: An LLM agent to execute tests of arbitrary projects,
I. Bouzenia and M. Pradel, “You name it, I run it: An LLM agent to execute tests of arbitrary projects,”Proc. ACM Softw. Eng., vol. 2, no. ISSTA, pp. 1054–1076, 2025. [Online]. Available: https://doi.org/10.1145/3728922
-
[9]
Envbench: A benchmark for automated environment setup,
A. Eliseeva, A. Kovrigin, I. Kholkin, E. Bogomolov, and Y . Zharov, “Envbench: A benchmark for automated environment setup,”CoRR, vol. abs/2503.14443, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2503.14443
-
[10]
Reflexion: language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: language agents with verbal reinforcement learning,” inAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Ha...
2023
-
[11]
Expel: LLM agents are experiential learners,
A. Zhao, D. Huang, Q. Xu, M. Lin, Y . Liu, and G. Huang, “Expel: LLM agents are experiential learners,” inThirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artificial Intelligence, EAAI 2024, February...
-
[12]
V oyager: An open-ended embodied agent with large language models,
G. Wang, Y . Xie, Y . Jiang, A. Mandlekar, C. Xiao, Y . Zhu, L. Fan, and A. Anandkumar, “V oyager: An open-ended embodied agent with large language models,”Trans. Mach. Learn. Res., vol. 2024, 2024. [Online]. Available: https://openreview.net/forum?id=ehfRiF0R3a 10
2024
-
[13]
Skillcraft: Can LLM agents learn to use tools skillfully?
S. Chen, J. Gai, R. Zhou, J. Zhang, T. Zhu, J. Li, K. Wang, Z. Wang, Z. Chen, K. Kaleb, N. Miao, S. Gao, C. Lu, M. Li, J. He, and Y . W. Teh, “Skillcraft: Can LLM agents learn to use tools skillfully?”CoRR, vol. abs/2603.00718, 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2603.00718
-
[14]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,” inThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net,
2023
-
[15]
Available: https://openreview.net/forum?id=WE_vluYUL-X
[Online]. Available: https://openreview.net/forum?id=WE_vluYUL-X
-
[16]
An Empirical Analysis of the Python Package Index (PyPI)
E. Bommarito and M. J. B. II, “An empirical analysis of the python package index (pypi),” CoRR, vol. abs/1907.11073, 2019. [Online]. Available: http://arxiv.org/abs/1907.11073
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[17]
Watchman: monitoring dependency conflicts for python library ecosystem,
Y . Wang, M. Wen, Y . Liu, Y . Wang, Z. Li, C. Wang, H. Yu, S. Cheung, C. Xu, and Z. Zhu, “Watchman: monitoring dependency conflicts for python library ecosystem,” inICSE ’20: 42nd International Conference on Software Engineering, Seoul, South Korea, 27 June - 19 July, 2020, G. Rothermel and D. Bae, Eds. ACM, 2020, pp. 125–135. [Online]. Available: https:...
-
[18]
Autocoderover: Autonomous program improvement,
Y . Zhang, H. Ruan, Z. Fan, and A. Roychoudhury, “Autocoderover: Autonomous program improvement,” inProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2024, Vienna, Austria, September 16-20, 2024, M. Christakis and M. Pradel, Eds. ACM, 2024, pp. 1592–1604. [Online]. Available: https://doi.org/10.1145/365021...
-
[19]
SUPER: evaluating agents on setting up and executing tasks from research repositories,
B. Bogin, K. Yang, S. Gupta, K. Richardson, E. Bransom, P. Clark, A. Sabharwal, and T. Khot, “SUPER: evaluating agents on setting up and executing tasks from research repositories,” in Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, Miami, FL, USA, November 12-16, 2024, Y . Al-Onaizan, M. Bansal, and Y ....
-
[20]
Agent KB: leveraging cross-domain experience for agentic problem solving,
X. Tang, T. Qin, T. Peng, Z. Zhou, D. Shao, T. Du, X. Wei, P. Xia, F. Wu, H. Zhu, G. Zhang, J. Liu, X. Wang, S. Hong, C. Wu, H. Cheng, C. Wang, and W. Zhou, “Agent KB: leveraging cross-domain experience for agentic problem solving,”CoRR, vol. abs/2507.06229, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2507.06229
-
[21]
EvolveR: Self-Evolving LLM Agents through an Experience-Driven Lifecycle
R. Wu, X. Wang, J. Mei, P. Cai, D. Fu, C. Yang, L. Wen, X. Yang, Y . Shen, Y . Wang, and B. Shi, “Evolver: Self-evolving LLM agents through an experience-driven lifecycle,”CoRR, vol. abs/2510.16079, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2510.16079
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.16079 2025
-
[22]
Memp: Exploring Agent Procedural Memory
R. Fang, Y . Liang, X. Wang, J. Wu, S. Qiao, P. Xie, F. Huang, H. Chen, and N. Zhang, “Memp: Exploring agent procedural memory,”CoRR, vol. abs/2508.06433, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2508.06433
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.06433 2025
-
[23]
CourtEval: A courtroom-based multi-agent evaluation framework,
S. Kumar, A. A. Nargund, and V . Sridhar, “CourtEval: A courtroom-based multi-agent evaluation framework,” inFindings of the Association for Computational Linguistics: ACL 2025, W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, Eds. Vienna, Austria: Association for Computational Linguistics, Jul. 2025, pp. 25 875–25 887. [Online]. Available: https://acl...
2025
-
[24]
R. You, H. Cai, C. Zhang, Q. Xu, M. Liu, T. Yu, Y . Li, and W. Li, “Agent-as-a-judge,” 2026. [Online]. Available: https://arxiv.org/abs/2601.05111 11 A XPU and Retrieval Implementation A.1 Example XPU Example XPU Entry { "id": "xpu_poetry_lock_conflict", "signals": { "keywords": ["poetry.lock", "pyproject.toml", "dependency conflict"], "regex": ["Because ...
-
[25]
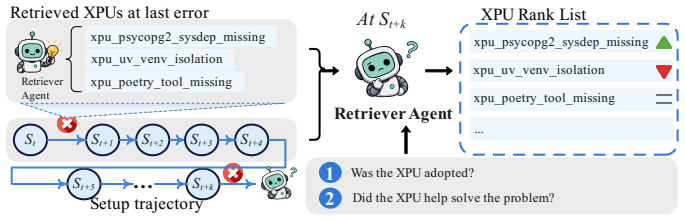
Anchor.At retrieval time, record the current trajectory length and the identifiers of the recom- mendedXPUentries, establishing a temporal reference point
-
[26]
Extract.On the next retrieval call, extract up to five subsequent steps from the main agent’s trajectory after the anchor point
-
[27]
Judge.An LLM judge determines whether each recommendedXPUcontributed to resolving the observed problem. The verdict issuccessif the advice was adopted and the problem was resolved or improved;failureif the advice was adopted but the problem persisted or worsened; andneutral if adoption or causal contribution cannot be determined
-
[28]
thought":
Update.The telemetry counters of each recommendedXPUare updated atomically according to the verdict: (successes,failures) += (1,0),ifv=success, (0,1),ifv=failure, (0,0),ifv=neutral. (4) B Agent Prompt Excerpts This appendix provides selected excerpts from the role-specific prompts used by SETUPX. We include only the parts that define each agent’s ro...
-
[29]
Exact match first: XPUs whose advice_nl directly addresses the current problem rank highest
-
[30]
If they are not, the XPU may still be effective
Telemetry as reference: pay attention to each XPU's historical hit / success / failure counts, but do not discard one merely because it has many failures — judge whether the previous failure scenarios are similar to the current one. If they are not, the XPU may still be effective
-
[31]
Drop the irrelevant: if an XPU's advice is completely unrelated to the current problem, do not pick it
-
[32]
%## Selection rules %1
Pick at most {k}. %## Selection rules %1. Exact match first: XPUs whose advice_nl directly solves the current problem rank first. %2. Telemetry as reference: pay attention to each XPU's historical hits / successes / failures, but do not exclude an XPU just because it has many failures. %3. Exclude irrelevant items outright: if an XPU's advice has nothing ...
-
[33]
Structure reconnaissance:`ls`the project root, locate pyproject.toml / setup.cfg / pytest.ini / tox.ini, etc
-
[34]
(pytest / unittest / tox, ...)
Locate the test suite: confirm the test directory and framework. (pytest / unittest / tox, ...)
-
[35]
Run the tests in the project's native way and collect results
-
[36]
Analyze failure causes and make a judgment
-
[37]
## Hard constraints (violation invalidates the verdict) - Install no packages
If the project has no tests at all, write a smoke test under /tmp/ to verify basic environment usability. ## Hard constraints (violation invalidates the verdict) - Install no packages. - Modify no environment configuration. - Modify no file under /workspace/repo. - write_file may only write into /tmp/. Prosecutor and Judge Prompt Excerpts You are the pros...
-
[38]
Checkpoint: Snapshot the current container via docker commit, pushing the image onto the LIFO stackS
-
[39]
import <module>
Adapt: The agent reads theXPU’sadvice_nl, leverages its full conversation context (recent history, observed versions, repository structure), and generates concrete commands tailored to the current repository. If the agent produces no command, the system falls back to rendering the XPU’satomsvia a type-awareAtom Rendering Enginethat maps 12 predefined atom...
2026
-
[40]
host repository is cloned but core dependencies are not installed;import fails immediately,
and Redis siblings providing persistence and cache. The latest source’s pyproject.toml requires Python >=3.14,<3.15 (the source already uses PEP 695 type aliases such as type ConfType = ...); the container’s default base image ships Python 3.11. SetupX+XPU trajectory (53 steps).The agent inspects the source and identifies the Python version constraint, th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.