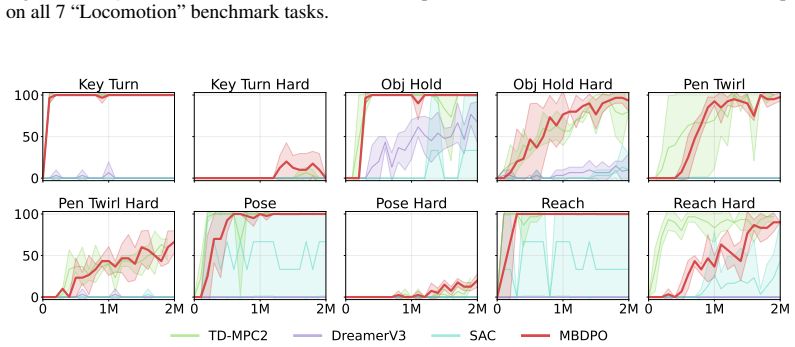
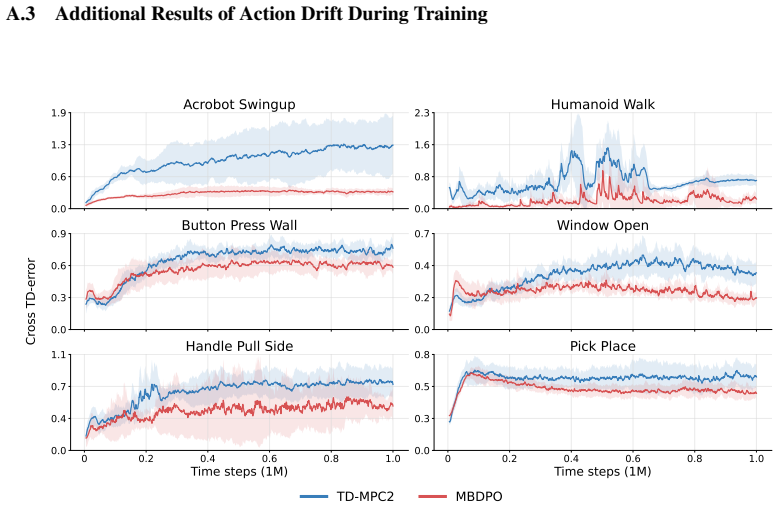
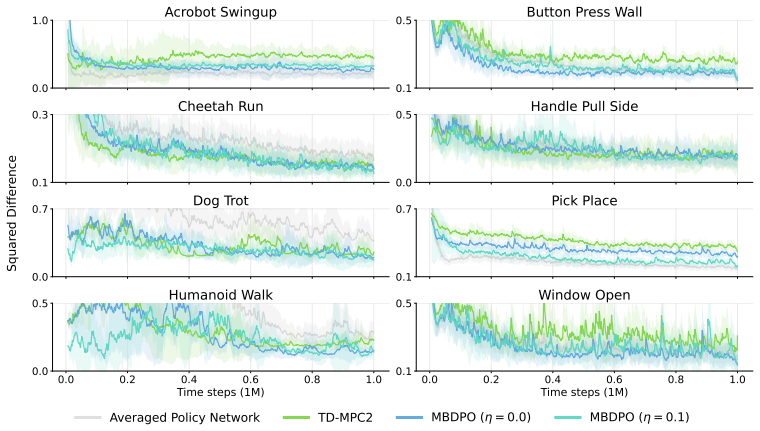
Scaling World-Model Reinforcement Learning Through Diffusion Policy Optimization
Pith reviewed 2026-06-29 22:43 UTC · model grok-4.3
The pith
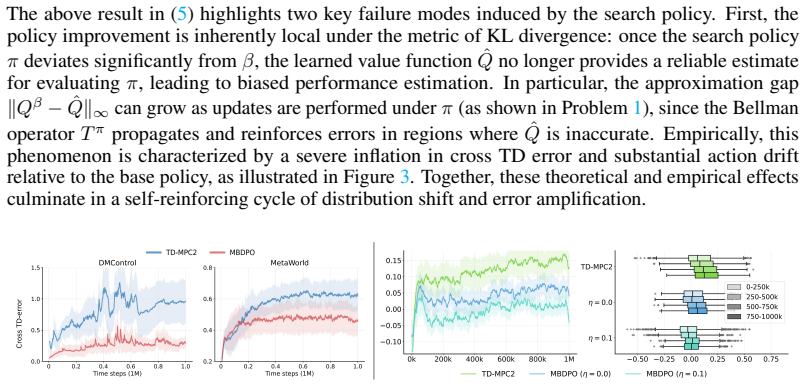
Reformulating policy optimization as a diffusion process over searched trajectories in latent world models removes the structural misalignment between search and value learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
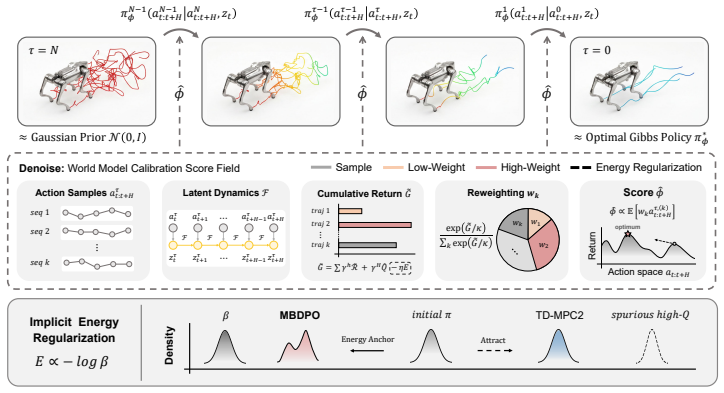
MBDPO unifies search and policy optimization by recasting the latter as a diffusion process over searched trajectories inside a latent world model; the collected data then yields an implicit energy function that anchors the policy, refines its score field, and eliminates the training inconsistency that previously prevented scalable policy learning from world models.
What carries the argument
Diffusion policy representations over searched trajectories in latent world models, from which an implicit energy function is extracted to anchor and refine the policy.
If this is right
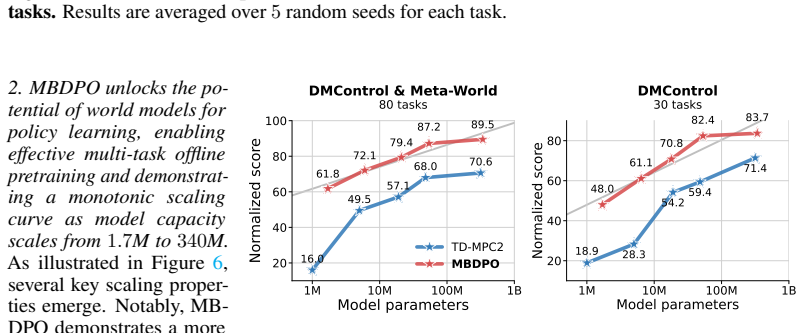
- Performance improves monotonically with model capacity during large-scale offline pretraining on world-model trajectories.
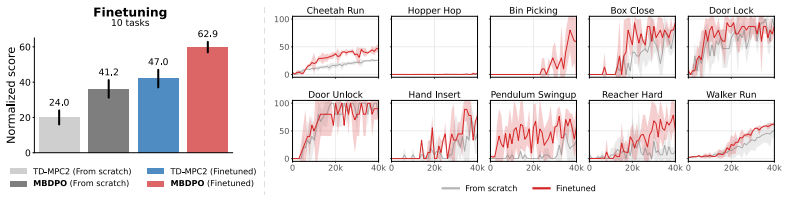
- The same framework supports effective learning in multi-task offline, online, and offline-to-online regimes without separate planners.
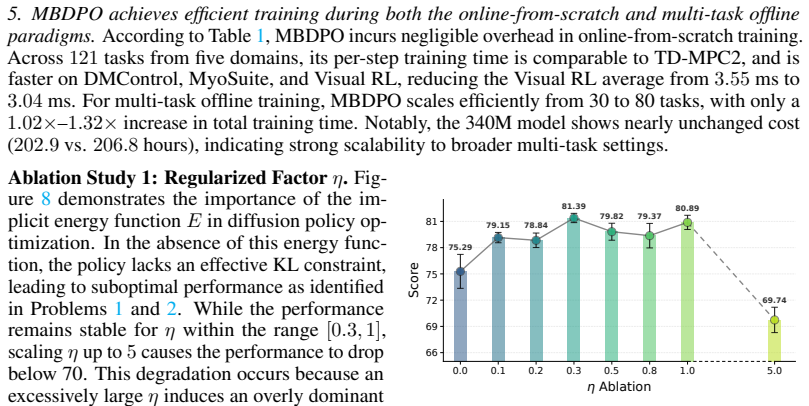
- Training inconsistency between search and value learning is reduced by anchoring the policy to an implicit energy function derived from the data.
- World models become viable for scalable policy learning once the diffusion process aligns search and optimization.
Where Pith is reading between the lines
- The same diffusion anchoring might be applied to other model-based methods that currently separate planning from value estimation.
- If the implicit energy function generalizes across tasks, it could reduce the need for task-specific reward engineering in pretraining.
- Long-horizon tasks may benefit most because the diffusion process operates directly on trajectories rather than step-wise value estimates.
Load-bearing premise
Reformulating policy optimization as diffusion over searched trajectories will produce an energy function that removes misalignment without introducing comparable new biases or errors.
What would settle it
An experiment in which increasing model capacity under MBDPO produces no further performance gains or introduces new inconsistencies visible in the learned score field or energy estimates.
Figures

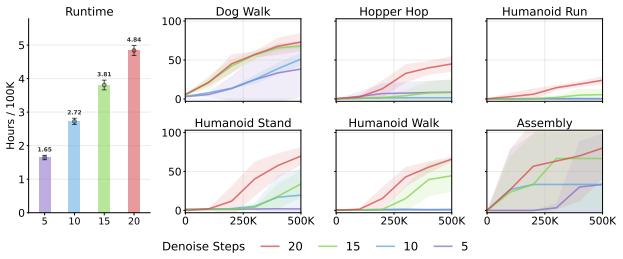
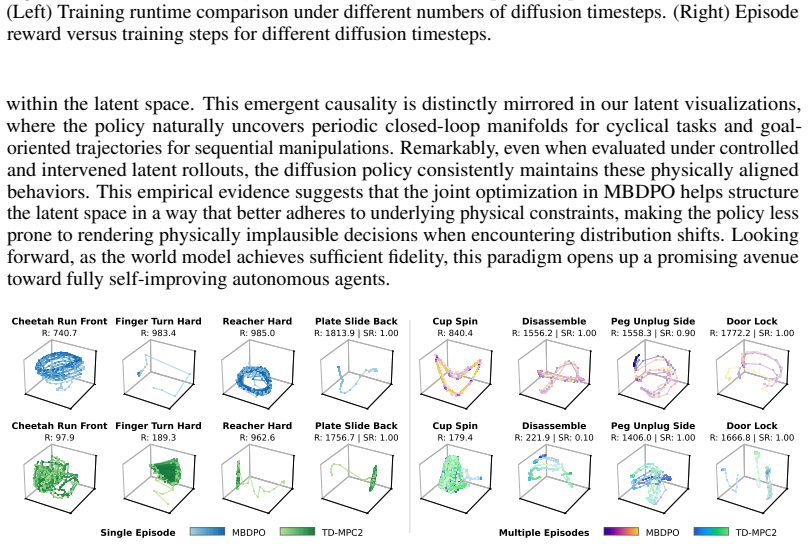




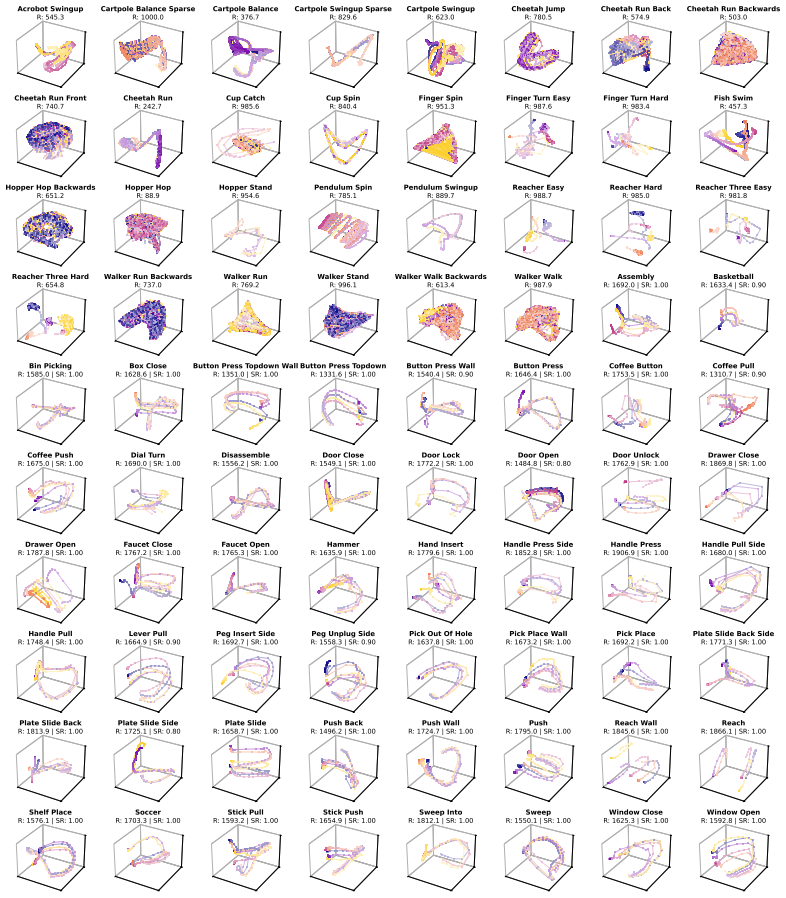
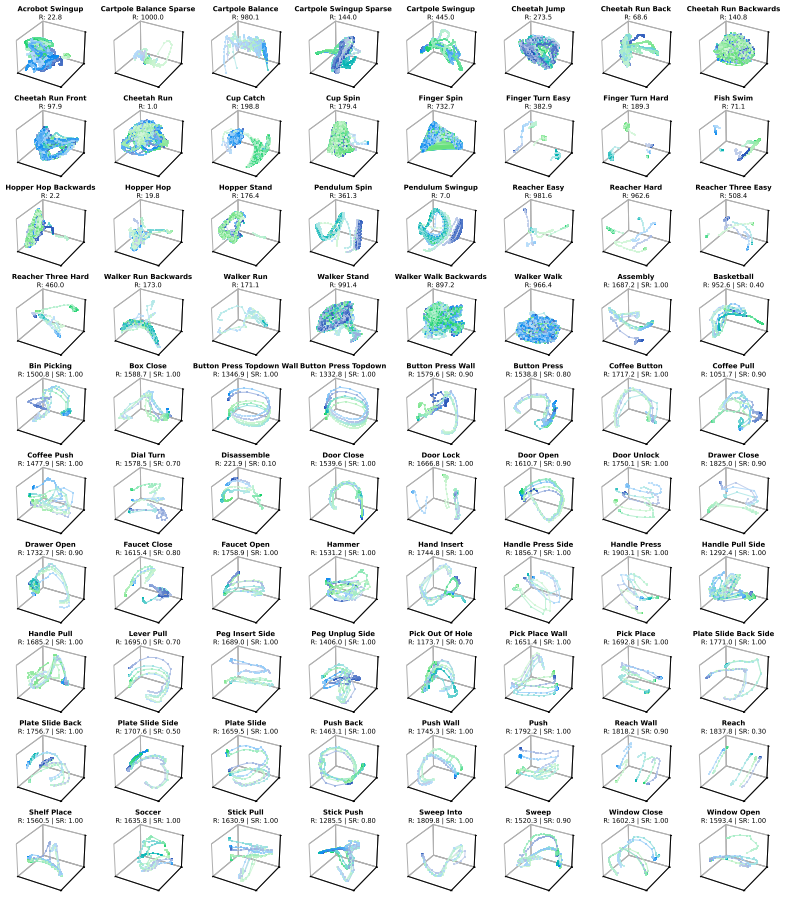
read the original abstract
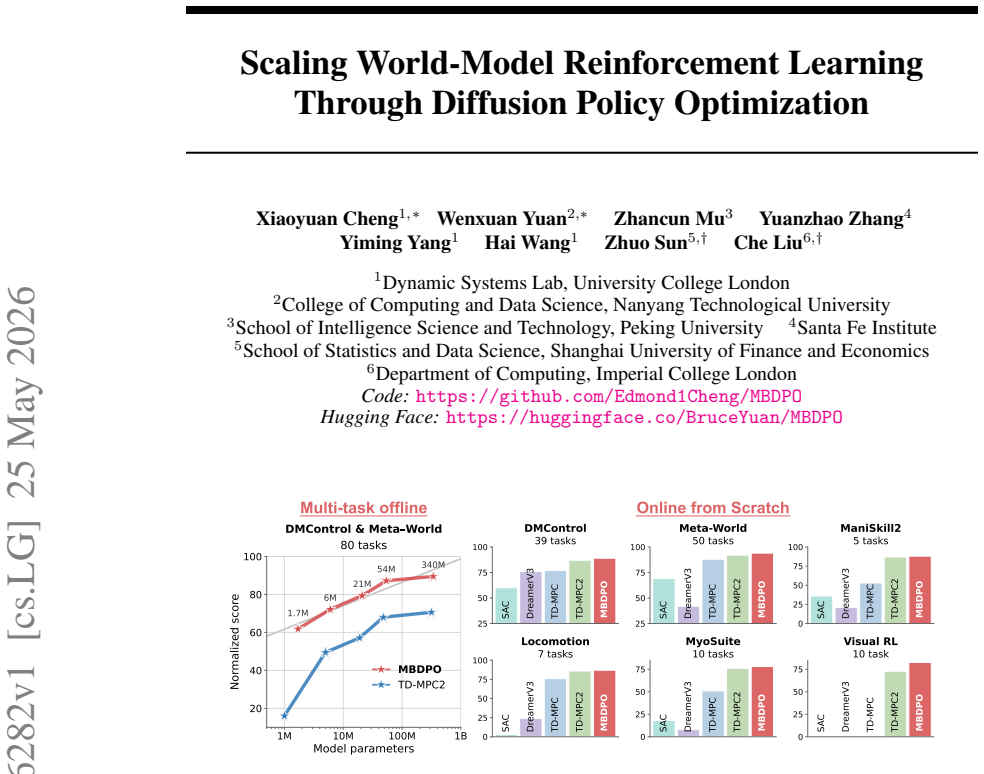
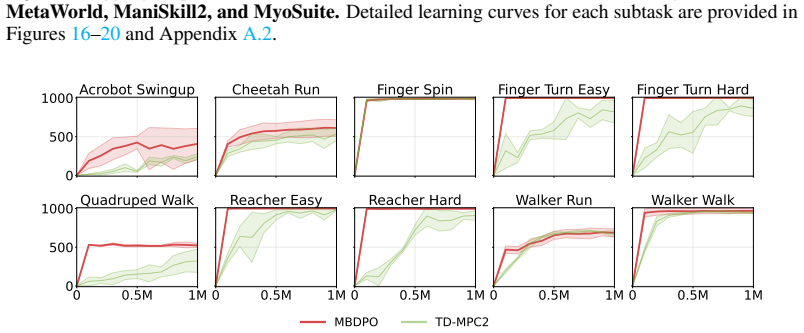
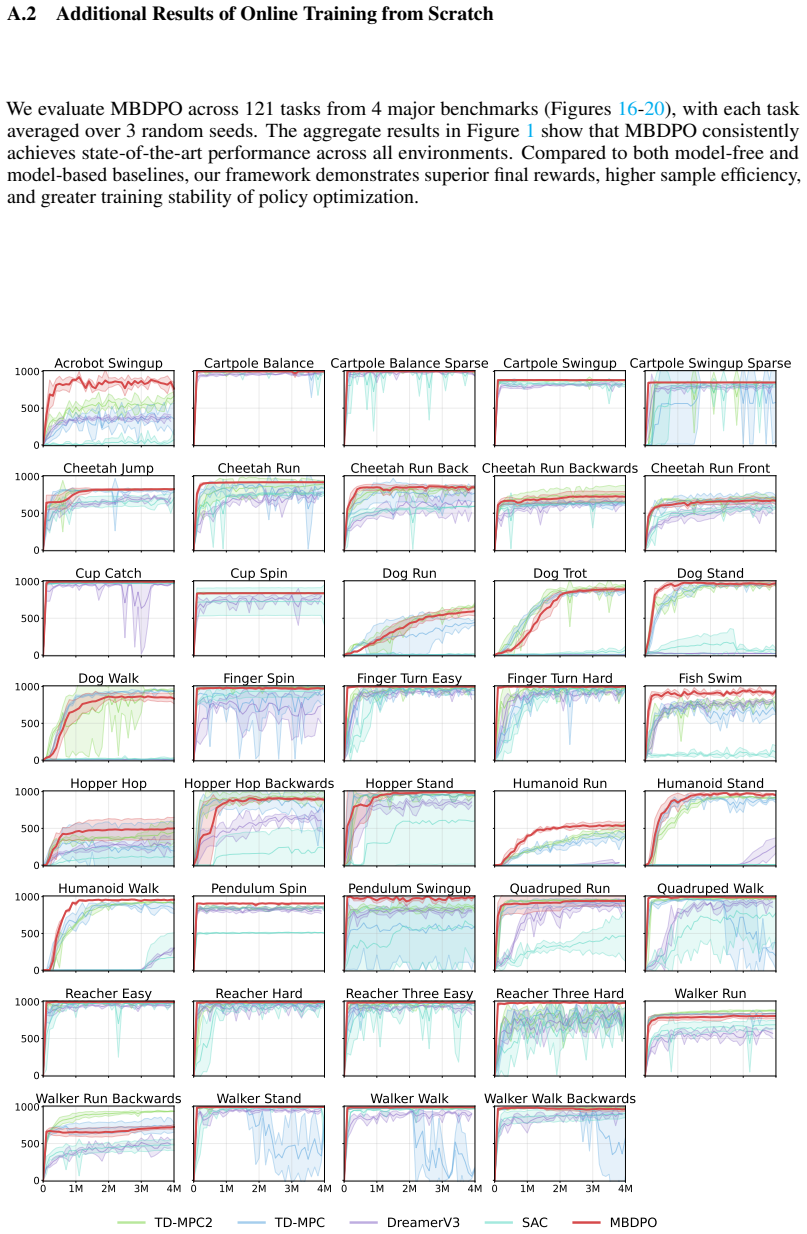
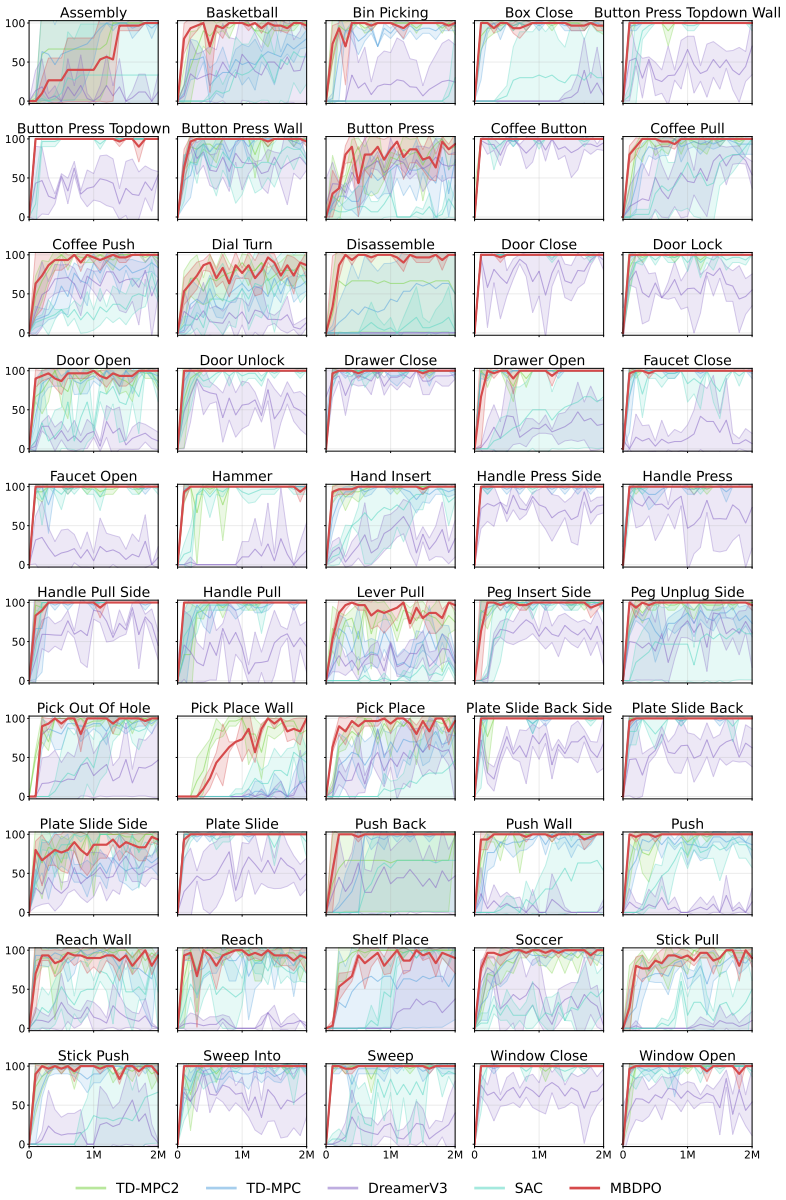
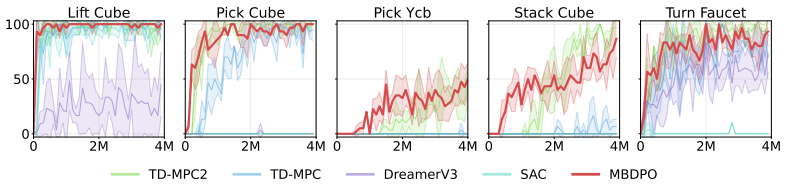
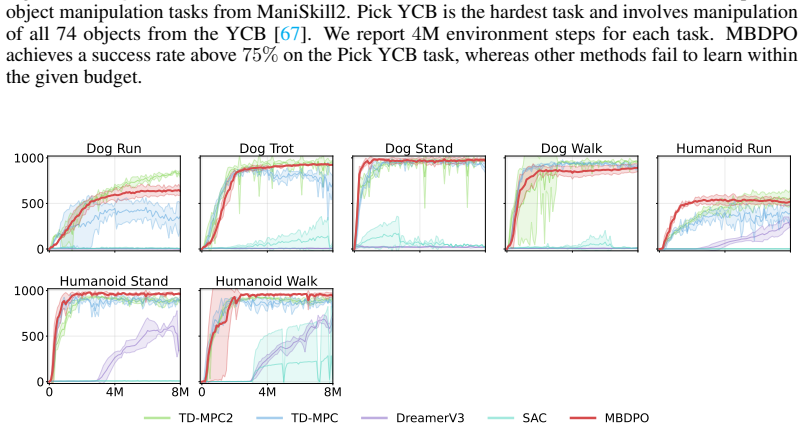
Model-based reinforcement learning (RL) can be effectively supported at scale through the use of world models. However, in practice, scaling such approaches remains fundamentally limited. A commonly recognized challenge is model bias and error compounding, which degrade long-horizon predictions. Beyond these issues, we identify a more critical yet underexplored bottleneck: a structural misalignment between search and value learning in existing world model approaches. In particular, policy improvement often relies on value functions induced by a separate, non-search policy, resulting in training inconsistency and ultimately suboptimal learning. To address this limitation, we propose Model-Based Diffusion Policy Optimization (MBDPO) in world models, a framework that unifies search and policy optimization through diffusion policy representations, thereby unlocking the potential of world models for scalable policy learning. Instead of constructing an explicit planner over a learned world model, we reformulate policy optimization as a diffusion process over searched trajectories in latent world models. In this view, we extract an implicit energy function from the collected dataset that anchors the policy, enabling MBDPO to refine the score field for policy optimization while mitigating misalignment. We evaluate MBDPO across a wide range of settings, including multi-task offline pretraining, online learning, and offline-to-online fine-tuning. In the offline regime, we further investigate its scaling behavior by pretraining on large-scale datasets, observing consistent and monotonic performance gains with increasing model capacity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript identifies a structural misalignment between search and value learning in world-model RL as a key bottleneck beyond model bias. It proposes Model-Based Diffusion Policy Optimization (MBDPO), which reformulates policy optimization as a diffusion process over searched trajectories in latent world models. This is claimed to extract an implicit energy function from the collected dataset that anchors the policy, unifies search and policy optimization, and mitigates training inconsistency. The approach is evaluated in multi-task offline pretraining, online learning, offline-to-online fine-tuning, and scaling experiments on large datasets showing monotonic gains with model capacity.
Significance. If the diffusion reformulation successfully extracts a usable implicit energy function without introducing comparable new errors or biases, the framework could meaningfully advance scalable model-based RL by addressing an underexplored inconsistency between search and value learning. The reported scaling behavior in the offline regime would be a notable strength if supported by rigorous ablations.
major comments (2)
- [Abstract] Abstract: the central claim that reformulating policy optimization as a diffusion process 'extracts an implicit energy function from the collected dataset that anchors the policy' is load-bearing for the unification argument, yet the abstract supplies no equations, score-field update rule, or description of how the energy function is obtained from trajectories; without this, it is impossible to verify whether the procedure avoids circularity or the exact form of the misalignment it claims to remove.
- [Abstract] Abstract: the evaluation claims 'consistent and monotonic performance gains with increasing model capacity' in the offline regime, but no table, figure, or quantitative scaling law is referenced; this leaves the scaling result uncheckable and prevents assessment of whether gains are attributable to the diffusion unification or to other factors such as dataset size.
minor comments (1)
- [Abstract] Abstract: the phrase 'structural misalignment between search and value learning' is introduced without a concise formal definition or reference to prior work quantifying the inconsistency; a short clarifying sentence would improve readability.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on the abstract. We address each point below and commit to revisions that enhance the clarity and verifiability of our claims without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that reformulating policy optimization as a diffusion process 'extracts an implicit energy function from the collected dataset that anchors the policy' is load-bearing for the unification argument, yet the abstract supplies no equations, score-field update rule, or description of how the energy function is obtained from trajectories; without this, it is impossible to verify whether the procedure avoids circularity or the exact form of the misalignment it claims to remove.
Authors: We agree that the abstract would be strengthened by including more technical specifics on this key aspect. In the revised version, we will add a brief explanation of how the implicit energy function is derived from the collected trajectories in the latent world model and how the score field is updated during policy optimization. This will help demonstrate that the procedure is non-circular and directly addresses the identified misalignment between search and value learning. The detailed equations and derivations are provided in the main body of the manuscript. revision: yes
-
Referee: [Abstract] Abstract: the evaluation claims 'consistent and monotonic performance gains with increasing model capacity' in the offline regime, but no table, figure, or quantitative scaling law is referenced; this leaves the scaling result uncheckable and prevents assessment of whether gains are attributable to the diffusion unification or to other factors such as dataset size.
Authors: We concur that referencing the supporting results would make the scaling claim more verifiable. We will update the abstract to reference the specific figure or table (such as the one presenting the large-scale offline pretraining experiments) that demonstrates the monotonic performance improvements with model capacity. This will enable readers to evaluate the scaling behavior and its relation to the diffusion-based unification. revision: yes
Circularity Check
No significant circularity identified
full rationale
The abstract and provided text describe MBDPO as a proposed reformulation of policy optimization into a diffusion process over searched trajectories to extract an implicit energy function. No equations, fitting procedures, self-citations, or derivations are shown that reduce a claimed prediction or result to its own inputs by construction. The central unification step is presented as a methodological framework choice whose validity is left to empirical validation, with no load-bearing self-referential steps or ansatzes smuggled via citation visible in the text. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
TD-MPC2: Scalable, Robust World Models for Continuous Control
Nicklas Hansen, Hao Su, and Xiaolong Wang. Td-mpc2: Scalable, robust world models for continuous control.arXiv preprint arXiv:2310.16828, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Model-based reinforcement learning with an approximate, learned model
Leonid Kuvayev Rich Sutton. Model-based reinforcement learning with an approximate, learned model. InProceedings of the ninth Yale workshop on adaptive and learning systems, volume 1996, pages 101–105, 1996
1996
-
[3]
MIT press Cambridge, 1998
Richard S Sutton, Andrew G Barto, et al.Reinforcement learning: An introduction, volume 1. MIT press Cambridge, 1998
1998
-
[4]
Quentin Garrido, Mahmoud Assran, Nicolas Ballas, Adrien Bardes, Laurent Najman, and Yann LeCun. Learning and leveraging world models in visual representation learning.arXiv preprint arXiv:2403.00504, 2024
-
[5]
DINO-WM: World Models on Pre-trained Visual Features enable Zero-shot Planning
Gaoyue Zhou, Hengkai Pan, Yann LeCun, and Lerrel Pinto. Dino-wm: World models on pre-trained visual features enable zero-shot planning.arXiv preprint arXiv:2411.04983, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Mastering diverse control tasks through world models.Nature, 640(8059):647–653, 2025
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse control tasks through world models.Nature, 640(8059):647–653, 2025
2025
-
[7]
Parallel stochastic gradient-based planning for world models.arXiv preprint arXiv:2602.00475, 2026
Michael Psenka, Michael Rabbat, Aditi Krishnapriyan, Yann LeCun, and Amir Bar. Parallel stochastic gradient-based planning for world models.arXiv preprint arXiv:2602.00475, 2026
-
[8]
Gradient-based planning with world models.arXiv preprint arXiv:2312.17227, 2023
Jyothir SV , Siddhartha Jalagam, Yann LeCun, and Vlad Sobal. Gradient-based planning with world models.arXiv preprint arXiv:2312.17227, 2023
-
[9]
Planning with an adaptive world model
Sebastian Thrun, Knut Möller, and Alexander Linden. Planning with an adaptive world model. Advances in neural information processing systems, 3, 1990
1990
-
[10]
Lin Guan, Karthik Valmeekam, Sarath Sreedharan, and Subbarao Kambhampati. Leveraging pre-trained large language models to construct and utilize world models for model-based task planning.Advances in Neural Information Processing Systems, 36:79081–79094, 2023
2023
-
[11]
Day- dreamer: World models for physical robot learning
Philipp Wu, Alejandro Escontrela, Danijar Hafner, Pieter Abbeel, and Ken Goldberg. Day- dreamer: World models for physical robot learning. InConference on robot learning, pages 2226–2240. PMLR, 2023
2023
-
[12]
Training Agents Inside of Scalable World Models
Danijar Hafner, Wilson Yan, and Timothy Lillicrap. Training agents inside of scalable world models.arXiv preprint arXiv:2509.24527, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
When to use parametric models in reinforcement learning?Advances in Neural Information Processing Systems, 32, 2019
Hado P Van Hasselt, Matteo Hessel, and John Aslanides. When to use parametric models in reinforcement learning?Advances in Neural Information Processing Systems, 32, 2019
2019
-
[14]
Towards general-purpose model-free reinforcement learning.arXiv preprint arXiv:2501.16142, 2025
Scott Fujimoto, Pierluca D’Oro, Amy Zhang, Yuandong Tian, and Michael Rabbat. Towards general-purpose model-free reinforcement learning.arXiv preprint arXiv:2501.16142, 2025
-
[15]
The Surprising Difficulty of Search in Model-Based Reinforcement Learning
Wei-Di Chang, Mikael Henaff, Brandon Amos, Gregory Dudek, and Scott Fujimoto. The surpris- ing difficulty of search in model-based reinforcement learning.arXiv preprint arXiv:2601.21306, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Moerland, Joost Broekens, Aske Plaat, and Catholijn M
Thomas M. Moerland, Joost Broekens, Aske Plaat, and Catholijn M. Jonker. Model-based reinforcement learning: A survey.Foundations and Trends in Machine Learning, 16(1):1–118, 2023
2023
-
[17]
Nathan Lambert, Kristofer Pister, and Roberto Calandra. Investigating compounding prediction errors in learned dynamics models.arXiv preprint arXiv:2203.09637, 2022
-
[18]
Neural network dynamics for model-based deep reinforcement learning with model-free fine-tuning
Anusha Nagabandi, Gregory Kahn, Ronald S Fearing, and Sergey Levine. Neural network dynamics for model-based deep reinforcement learning with model-free fine-tuning. In2018 IEEE international conference on robotics and automation (ICRA), pages 7559–7566. IEEE, 2018
2018
-
[19]
Learning latent dynamics for planning from pixels
Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson. Learning latent dynamics for planning from pixels. InInternational conference on machine learning, pages 2555–2565. PMLR, 2019
2019
-
[20]
Pilco: A model-based and data-efficient approach to policy search
Marc Deisenroth and Carl E Rasmussen. Pilco: A model-based and data-efficient approach to policy search. InProceedings of the 28th International Conference on machine learning (ICML-11), pages 465–472, 2011
2011
-
[21]
Efficient model-based reinforcement learning through optimistic policy search and planning.Advances in Neural Information Processing Systems, 33:14156–14170, 2020
Sebastian Curi, Felix Berkenkamp, and Andreas Krause. Efficient model-based reinforcement learning through optimistic policy search and planning.Advances in Neural Information Processing Systems, 33:14156–14170, 2020
2020
-
[22]
Model-based lifelong reinforcement learning with bayesian exploration.Advances in Neural Information Processing Systems, 35:32369–32382, 2022
Haotian Fu, Shangqun Yu, Michael Littman, and George Konidaris. Model-based lifelong reinforcement learning with bayesian exploration.Advances in Neural Information Processing Systems, 35:32369–32382, 2022
2022
-
[23]
When to trust your model: Model-based policy optimization.Advances in neural information processing systems, 32, 2019
Michael Janner, Justin Fu, Marvin Zhang, and Sergey Levine. When to trust your model: Model-based policy optimization.Advances in neural information processing systems, 32, 2019
2019
-
[24]
Horizon reduction makes rl scalable.arXiv preprint arXiv:2506.04168, 2025
Seohong Park, Kevin Frans, Deepinder Mann, Benjamin Eysenbach, Aviral Kumar, and Sergey Levine. Horizon reduction makes rl scalable.arXiv preprint arXiv:2506.04168, 2025
-
[25]
Do trans- former world models give better policy gradients?arXiv preprint arXiv:2402.05290, 2024
Michel Ma, Tianwei Ni, Clement Gehring, Pierluca D’Oro, and Pierre-Luc Bacon. Do trans- former world models give better policy gradients?arXiv preprint arXiv:2402.05290, 2024
-
[26]
Temporal difference flows.arXiv preprint arXiv:2503.09817, 2025
Jesse Farebrother, Matteo Pirotta, Andrea Tirinzoni, Rémi Munos, Alessandro Lazaric, and Ahmed Touati. Temporal difference flows.arXiv preprint arXiv:2503.09817, 2025
-
[27]
Temporal difference learning for model predictive control.arXiv preprint arXiv:2203.04955, 2022
Nicklas Hansen, Xiaolong Wang, and Hao Su. Temporal difference learning for model predictive control.arXiv preprint arXiv:2203.04955, 2022
-
[28]
Nicklas Hansen, Hao Su, and Xiaolong Wang. Learning massively multitask world models for continuous control.arXiv preprint arXiv:2511.19584, 2025
-
[29]
Bootstrapped model predictive control.arXiv preprint arXiv:2503.18871, 2025
Yuhang Wang, Hanwei Guo, Sizhe Wang, Long Qian, and Xuguang Lan. Bootstrapped model predictive control.arXiv preprint arXiv:2503.18871, 2025
-
[30]
Bootstrap off-policy with world model.arXiv preprint arXiv:2511.00423, 2025
Guojian Zhan, Likun Wang, Xiangteng Zhang, Jiaxin Gao, Masayoshi Tomizuka, and Shengbo Eben Li. Bootstrap off-policy with world model.arXiv preprint arXiv:2511.00423, 2025
-
[31]
Bisimulation metric for model predictive control
Yutaka Shimizu and Masayoshi Tomizuka. Bisimulation metric for model predictive control. arXiv preprint arXiv:2410.04553, 2024
-
[32]
Model Predictive Path Integral Control using Covariance Variable Importance Sampling
Grady Williams, Andrew Aldrich, and Evangelos Theodorou. Model predictive path integral control using covariance variable importance sampling.arXiv preprint arXiv:1509.01149, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[33]
Off-policy deep reinforcement learning without exploration
Scott Fujimoto, David Meger, and Doina Precup. Off-policy deep reinforcement learning without exploration. InInternational conference on machine learning, pages 2052–2062. PMLR, 2019
2052
-
[34]
Counterintuitive behavior of social systems.Theory and decision, 2(2):109– 140, 1971
Jay W Forrester. Counterintuitive behavior of social systems.Theory and decision, 2(2):109– 140, 1971
1971
-
[35]
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3):440, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[36]
Mastering Atari with Discrete World Models
Danijar Hafner, Timothy Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering atari with discrete world models.arXiv preprint arXiv:2010.02193, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[37]
3D-VLA: A 3D Vision-Language-Action Generative World Model
Haoyu Zhen, Xiaowen Qiu, Peihao Chen, Jincheng Yang, Xin Yan, Yilun Du, Yining Hong, and Chuang Gan. 3d-vla: A 3d vision-language-action generative world model.arXiv preprint arXiv:2403.09631, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
WorldVLA: Towards Autoregressive Action World Model
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, et al. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
GigaBrain Team, Boyuan Wang, Chaojun Ni, Guan Huang, Guosheng Zhao, Hao Li, Jie Li, Jindi Lv, Jingyu Liu, Lv Feng, et al. Gigabrain-0.5 m*: a vla that learns from world model-based reinforcement learning.arXiv preprint arXiv:2602.12099, 2026
-
[40]
${\pi}_{0.7}$: a Steerable Generalist Robotic Foundation Model with Emergent Capabilities
Physical Intelligence, Ali Amin Bo, Raichelle Aniceto, Ashwin Balakrishna, Greg Balke, Kevin Black, George Bokinsky, Shihao Cao, Thomas Charbonnier, et al. π0.7: A Steerable Generalist Robotic Foundation Model with Emergent Capabilities.arXiv preprint arXiv:2604.15483, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[41]
Jianhua Han, Meng Tian, Jiangtong Zhu, Fan He, Huixin Zhang, Sitong Guo, Dechang Zhu, Hao Tang, Pei Xu, Yuze Guo, et al. Percept-wam: Perception-enhanced world-awareness-action model for robust end-to-end autonomous driving.arXiv preprint arXiv:2511.19221, 2025
-
[42]
World action models are zero-shot policies, 2026
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, Ayaan Malik, Kyungmin Lee, William Liang, Nadun Ranawaka, Jiasheng Gu, Yinzhen Xu, Guanzhi Wang, Fengyuan Hu, Avnish Narayan, Johan Bjorck, Jing Wang, Gwanghyun Kim, Dantong Niu, Ruijie Zheng, Yuqi Xie, Jimmy Wu, Qi ...
2026
-
[43]
Causal World Modeling for Robot Control
Lin Li, Qihang Zhang, Yiming Luo, Shuai Yang, Ruilin Wang, Fei Han, Mingrui Yu, Zelin Gao, Nan Xue, Xing Zhu, et al. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
Planning with Diffusion for Flexible Behavior Synthesis
Michael Janner, Yilun Du, Joshua B Tenenbaum, and Sergey Levine. Planning with diffusion for flexible behavior synthesis.arXiv preprint arXiv:2205.09991, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[45]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[46]
Michael Psenka, Alejandro Escontrela, Pieter Abbeel, and Yi Ma. Learning a diffusion model policy from rewards via q-score matching.arXiv preprint arXiv:2312.11752, 2023
-
[47]
Maximum entropy reinforcement learning with diffusion policy.arXiv preprint arXiv:2502.11612, 2025
Xiaoyi Dong, Jian Cheng, and Xi Sheryl Zhang. Maximum entropy reinforcement learning with diffusion policy.arXiv preprint arXiv:2502.11612, 2025
-
[48]
How Does the Lagrangian Guide Safe Reinforcement Learning through Diffusion Models?
Xiaoyuan Cheng, Wenxuan Yuan, Boyang Li, Yuanchao Xu, Yiming Yang, Hao Liang, Bei Peng, Robert Loftin, Zhuo Sun, and Yukun Hu. How does the lagrangian guide safe reinforcement learning through diffusion models?arXiv preprint arXiv:2602.02924, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
Q-learning with Adjoint Matching
Qiyang Li and Sergey Levine. Q-learning with adjoint matching.arXiv preprint arXiv:2601.14234, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[50]
Model-based diffusion for trajectory optimization.Advances in Neural Information Processing Systems, 37:57914–57943, 2024
Chaoyi Pan, Zeji Yi, Guanya Shi, and Guannan Qu. Model-based diffusion for trajectory optimization.Advances in Neural Information Processing Systems, 37:57914–57943, 2024
2024
-
[51]
Full-order sampling-based mpc for torque-level locomotion control via diffusion-style annealing
Haoru Xue, Chaoyi Pan, Zeji Yi, Guannan Qu, and Guanya Shi. Full-order sampling-based mpc for torque-level locomotion control via diffusion-style annealing. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 4974–4981. IEEE, 2025
2025
-
[52]
Safe and stable control via lyapunov- guided diffusion models.arXiv preprint arXiv:2509.25375, 2025
Xiaoyuan Cheng, Xiaohang Tang, and Yiming Yang. Safe and stable control via lyapunov- guided diffusion models.arXiv preprint arXiv:2509.25375, 2025
-
[53]
Markov decision processes.Handbooks in operations research and management science, 2:331–434, 1990
Martin L Puterman. Markov decision processes.Handbooks in operations research and management science, 2:331–434, 1990
1990
-
[54]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[55]
Td-m(pc)2: Improving temporal difference mpc through policy constraint, 2025
Haotian Lin, Pengcheng Wang, Jeff Schneider, and Guanya Shi. Td-m(pc)2: Improving temporal difference mpc through policy constraint, 2025
2025
-
[56]
Sitan Chen, Sinho Chewi, Jerry Li, Yuanzhi Li, Adil Salim, and Anru R Zhang. Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions.arXiv preprint arXiv:2209.11215, 2022
-
[57]
Yuval Tassa, Yotam Doron, Alistair Muldal, Tom Erez, Yazhe Li, Diego de Las Casas, David Budden, Abbas Abdolmaleki, Josh Merel, Andrew Lefrancq, et al. Deepmind control suite. arXiv preprint arXiv:1801.00690, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[58]
Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning
Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. InConference on robot learning, pages 1094–1100. PMLR, 2020
2020
-
[59]
Jiayuan Gu, Fanbo Xiang, Xuanlin Li, Zhan Ling, Xiqiang Liu, Tongzhou Mu, Yihe Tang, Stone Tao, Xinyue Wei, Yunchao Yao, et al. Maniskill2: A unified benchmark for generalizable manipulation skills.arXiv preprint arXiv:2302.04659, 2023
-
[60]
Vittorio Caggiano, Huawei Wang, Guillaume Durandau, Massimo Sartori, and Vikash Kumar. Myosuite–a contact-rich simulation suite for musculoskeletal motor control.arXiv preprint arXiv:2205.13600, 2022
-
[61]
Soft Actor-Critic Algorithms and Applications
Tuomas Haarnoja, Aurick Zhou, Kristian Hartikainen, George Tucker, Sehoon Ha, Jie Tan, Vikash Kumar, Henry Zhu, Abhishek Gupta, Pieter Abbeel, et al. Soft actor-critic algorithms and applications.arXiv preprint arXiv:1812.05905, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[62]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[63]
Sample-efficient cross-entropy method for real-time planning
Cristina Pinneri, Shambhuraj Sawant, Sebastian Blaes, Jan Achterhold, Joerg Stueckler, Michal Rolinek, and Georg Martius. Sample-efficient cross-entropy method for real-time planning. In Conference on Robot Learning, pages 1049–1065. PMLR, 2021
2021
-
[64]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems.arXiv preprint arXiv:2005.01643, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[65]
Trust region policy optimization
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. InInternational conference on machine learning, pages 1889–1897. PMLR, 2015
2015
-
[66]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[67]
The ycb object and model set: Towards common benchmarks for manipulation research
Berk Calli, Arjun Singh, Aaron Walsman, Siddhartha Srinivasa, Pieter Abbeel, and Aaron M Dollar. The ycb object and model set: Towards common benchmarks for manipulation research. In2015 international conference on advanced robotics (ICAR), pages 510–517. IEEE, 2015
2015
-
[68]
Visualizing data using t-sne.Journal of machine learning research, 9(11), 2008
Laurens Van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of machine learning research, 9(11), 2008
2008
-
[69]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[70]
Courier Corporation, 2013
Richard Bellman.Stability theory of differential equations. Courier Corporation, 2013
2013
-
[71]
Model predictive path integral control: From theory to parallel computation.Journal of Guidance, Control, and Dynamics, 40(2):344–357, 2017
Grady Williams, Andrew Aldrich, and Evangelos A Theodorou. Model predictive path integral control: From theory to parallel computation.Journal of Guidance, Control, and Dynamics, 40(2):344–357, 2017
2017
-
[72]
Locomotion
Sridhar Mahadevan. Average reward reinforcement learning: Foundations, algorithms, and empirical results.Machine learning, 22(1):159–195, 1996. Notation Notation Meaning aaction elearnable task embedding sstate ttime step rreward function zlatent state Aspace of action Eimplicit energy function Eencoder of world model Eenv space of learnable task embeddin...
1996
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.